La réponse à une requête de traitement contient un objet Document qui fournit toutes les informations connues sur le document traité, y compris toutes les informations structurées que Document AI a pu extraire.
Cette page explique la mise en page de l'objet Document en fournissant des exemples de documents, puis en mappant les aspects des résultats de l'OCR aux éléments spécifiques du JSON de l'objet Document.
Elle fournit également des exemples de code pour les bibliothèques clientes et le SDK Document AI Toolbox.
Ces exemples de code utilisent le traitement en ligne, mais l'analyse de l'objet Document fonctionne de la même manière pour le traitement par lot.
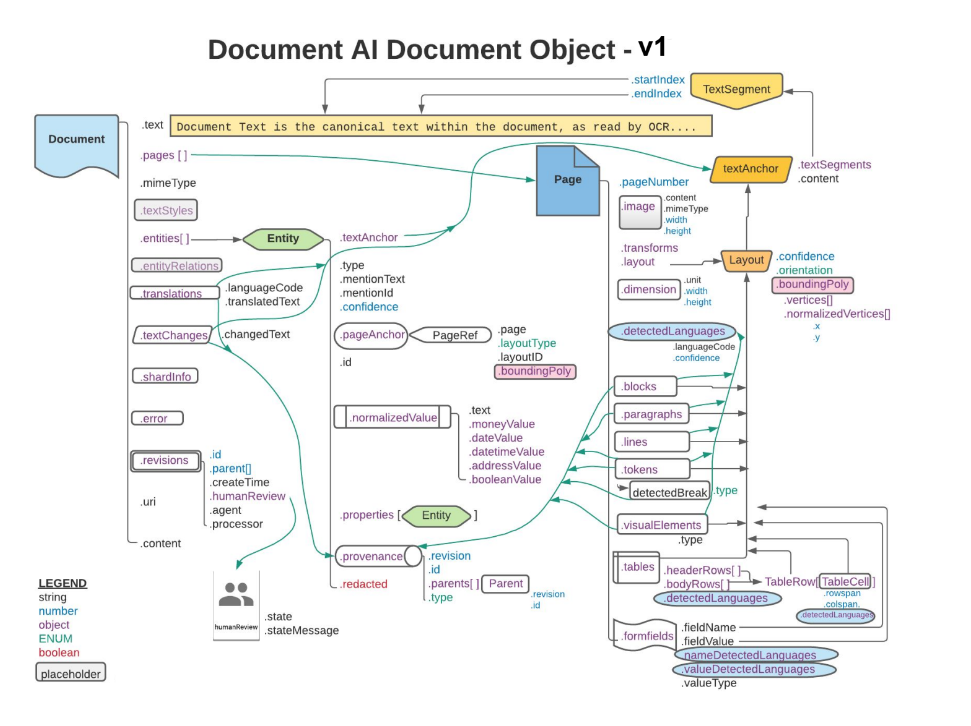
Les rectangles et les flèches orange et bleus indiquent qu'au moins un champ des objets connectés est .layout ou detectedLanguage, respectivement. Le schéma utilise la notation en patte de corbeau.
Utilisez un utilitaire de visualisation ou de modification JSON spécialement conçu pour développer ou réduire des éléments. Il est inefficace d'examiner le code JSON brut dans un utilitaire de texte brut.
Texte, mise en page et niveaux de qualité
Voici un exemple de document texte :

Voici l'objet document complet tel qu'il est renvoyé par le processeur Enterprise Document OCR :
Cette sortie OCR est également toujours incluse dans la sortie du processeur Document AI, car l'OCR est exécutée par les processeurs. Il utilise les données OCR existantes. C'est pourquoi vous pouvez saisir ces données JSON à l'aide de l'option de document intégré dans les processeurs Document AI.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Voici quelques-uns des champs importants :
Texte brut
Le champ text contient le texte reconnu par Document AI.
Ce texte ne contient aucune structure de mise en page autre que des espaces, des tabulations et des sauts de ligne. Il s'agit du seul champ qui stocke les informations textuelles d'un document et sert de source de référence pour le texte du document. D'autres champs peuvent faire référence à des parties du champ de texte par position (startIndex et endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Taille de la page et langues
Chaque page de l'objet document correspond à une page physique du document exemple. L'exemple de sortie JSON contient une seule page, car il s'agit d'une seule image PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- Le champ
pages[].detectedLanguages[]contient les langues détectées sur une page donnée, ainsi que le score de confiance.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
Données OCR
Document AI OCR détecte le texte avec différents niveaux de précision ou d'organisation sur la page, comme les blocs de texte, les paragraphes, les jetons et les symboles (le niveau de symbole est facultatif, s'il est configuré pour générer des données au niveau du symbole). Ce sont tous des membres de l'objet de page.
Chaque élément possède un layout correspondant qui décrit sa position et son texte. Les éléments visuels non textuels (tels que les cases à cocher) sont également au niveau de la page.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
Le texte brut est référencé dans l'objet textAnchor, qui est indexé dans la chaîne de texte principale avec startIndex et endIndex.
Pour
boundingPoly, l'origine(0,0)correspond au coin supérieur gauche de la page. Les valeurs X positives sont à droite et les valeurs Y positives sont en bas.L'objet
verticesutilise les mêmes coordonnées que l'image d'origine, tandis quenormalizedVerticesse trouve dans la plage[0,1]. Il existe une matrice de transformation qui indique les mesures de redressement et d'autres attributs de la normalisation de l'image.
- Pour dessiner le
boundingPoly, tracez des segments de ligne d'un sommet à l'autre. Fermez ensuite le polygone en traçant un segment de ligne du dernier sommet au premier. L'élément orientation de la mise en page indique si le texte a été mis en rotation par rapport à la page.
Pour vous aider à visualiser la structure du document, les images suivantes dessinent des polygones de sélection pour page.paragraphs, page.lines et page.tokens.
Paragraphes

Lignes

Jetons

Blocs

Le processeur Enterprise Document OCR peut évaluer la qualité d'un document en fonction de sa lisibilité.
- Vous devez définir le champ
processOptions.ocrConfig.enableImageQualityScoressurtruepour obtenir ces données dans la réponse de l'API.
Cette évaluation de la qualité est un niveau de qualité compris entre [0, 1], où 1 signifie une qualité parfaite.
Le niveau de qualité est renvoyé dans le champ Page.imageQualityScores.
Tous les défauts détectés sont listés sous la forme quality/defect_* et triés par ordre décroissant de niveau de confiance.
Voici un PDF trop sombre et flou pour être lu confortablement :
Voici les informations sur la qualité des documents renvoyées par le processeur Enterprise Document OCR :
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Exemples de code
Les exemples de code suivants montrent comment envoyer une demande de traitement, puis lire et imprimer les champs dans le terminal :
Java
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Java.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Node.js.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Formulaires et tableaux
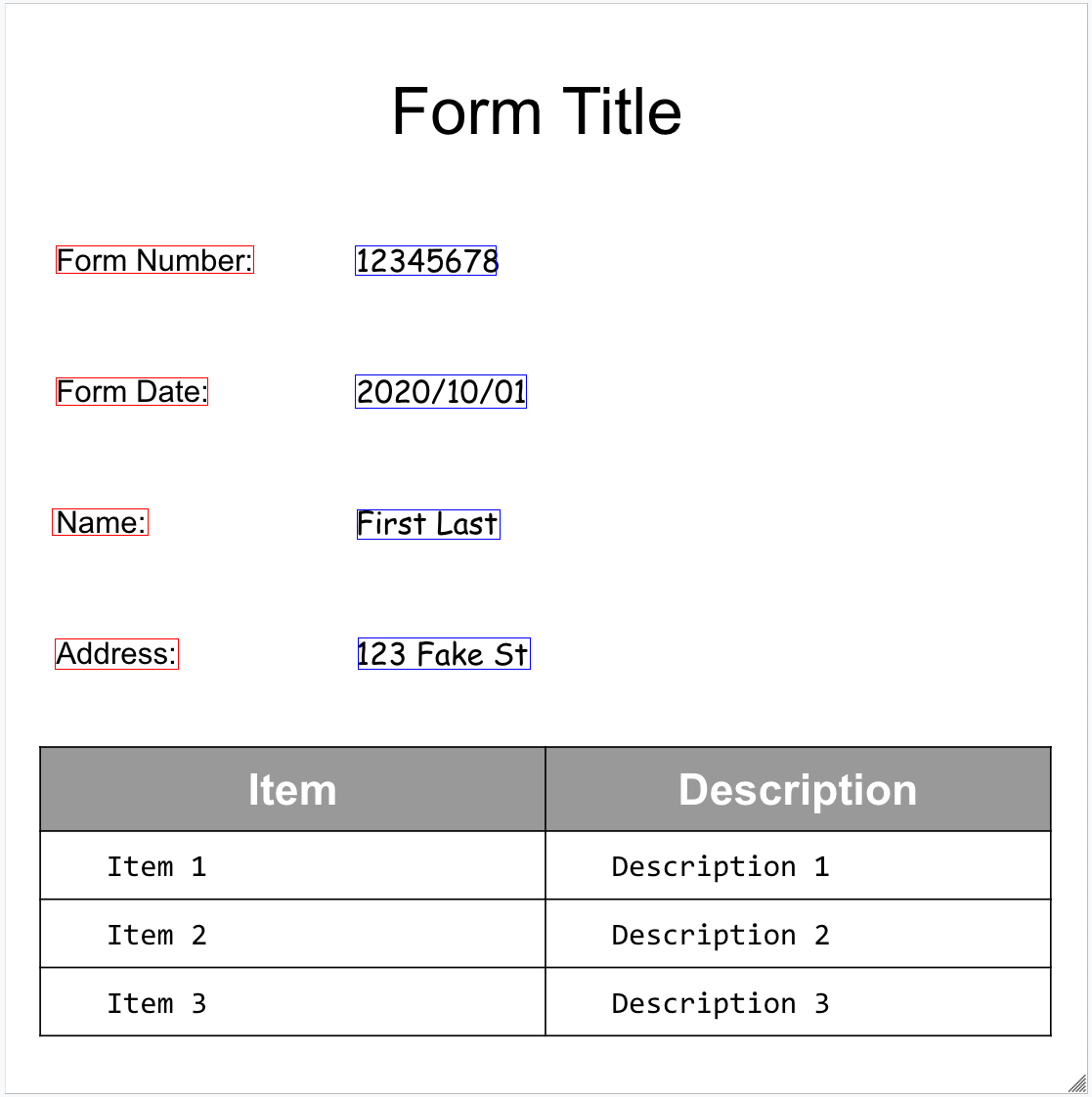
Voici un exemple de formulaire :
Voici l'objet document complet tel qu'il est renvoyé par l'analyseur de formulaires :
Voici quelques-uns des champs importants :
Le Form Parser est capable de détecter FormFields sur la page. Chaque champ de formulaire possède un nom et une valeur. Elles sont également appelées paires clé-valeur. Notez que les paires clé/valeur sont différentes des entités (schéma) dans les autres extracteurs :
Les noms des entités sont configurés. Les clés des paires clé/valeur sont littéralement le texte clé du document.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
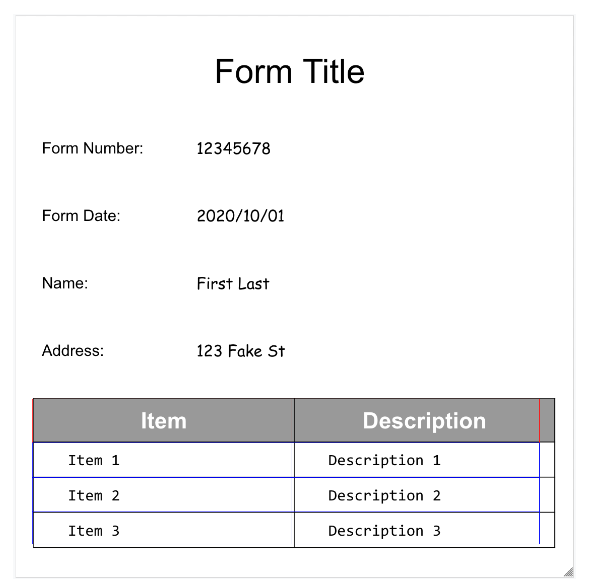
- Document AI peut également détecter les
Tablessur la page.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
L'extraction de tableaux dans l'analyseur de formulaires ne reconnaît que les tableaux conventionnels, c'est-à-dire ceux sans cellules qui s'étendent sur plusieurs lignes ou colonnes. Par conséquent, rowSpan et colSpan sont toujours égaux à 1.
À partir de la version
pretrained-form-parser-v2.0-2022-11-10du processeur, l'analyseur de formulaires peut également reconnaître les entités génériques. Pour en savoir plus, consultez Analyseur de formulaires.Pour vous aider à visualiser la structure du document, les images suivantes dessinent des polygones de délimitation pour
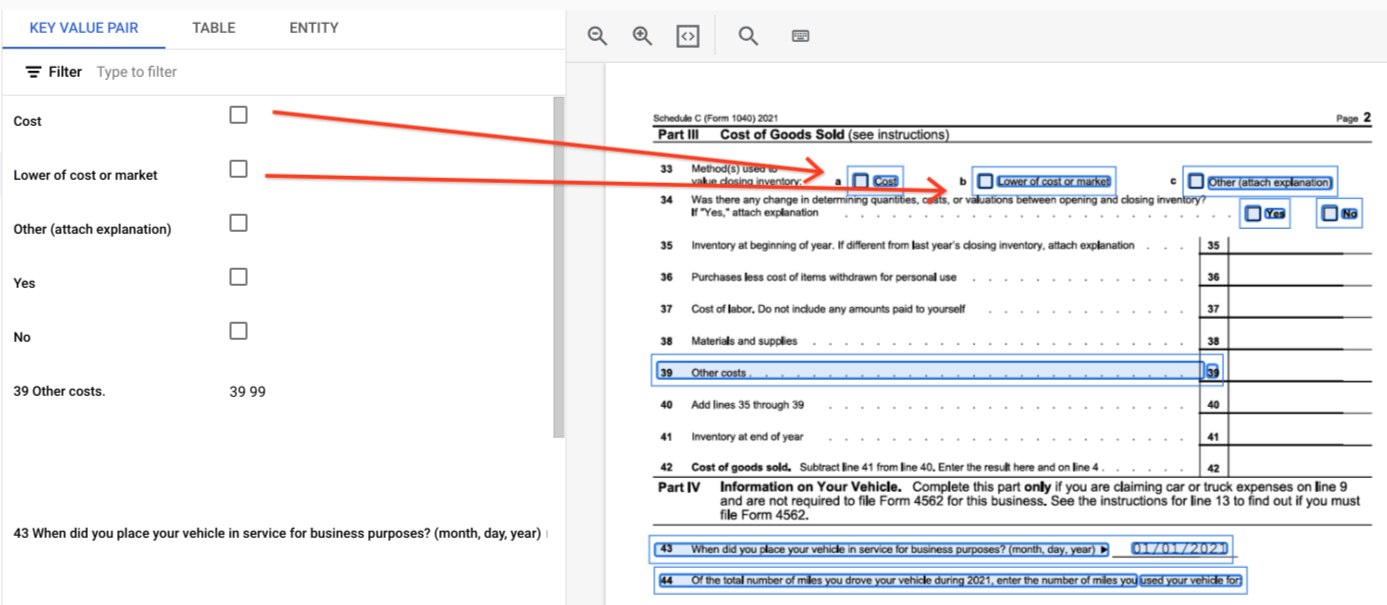
page.formFieldsetpage.tables.Cases à cocher dans les tableaux. Le Form Parser est capable de numériser les cases à cocher des images et des PDF en tant que paires clé/valeur. Exemple de numérisation de case à cocher sous forme de paire clé/valeur.
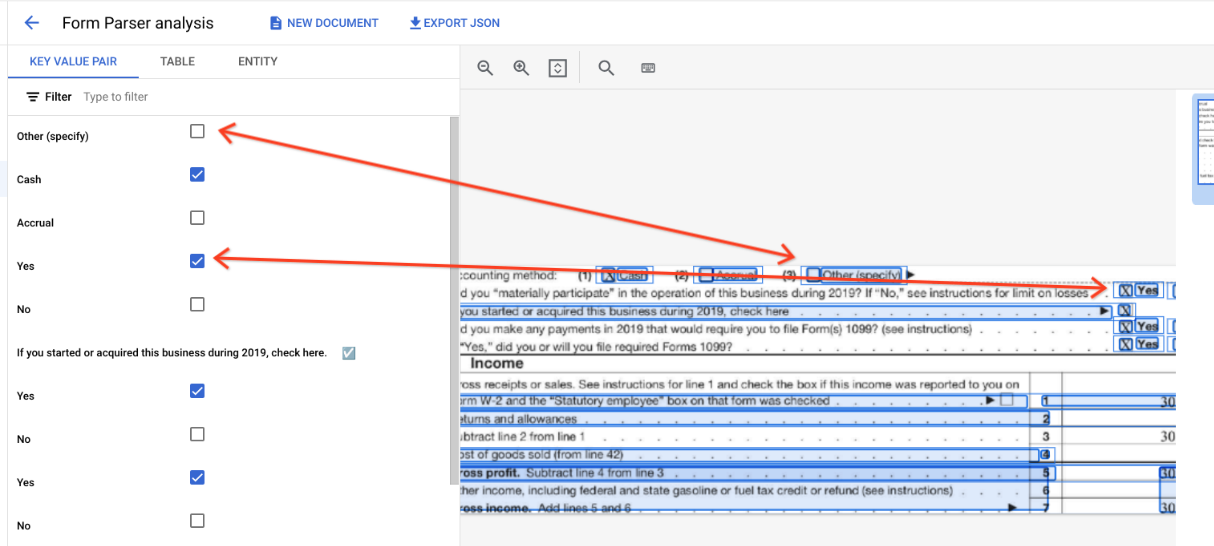
En dehors des tableaux, les cases à cocher sont représentées sous forme d'éléments visuels dans l'analyseur de formulaires. Mise en évidence des cases à cocher dans l'UI et du caractère Unicode ✓ dans le fichier JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
Dans les tableaux, les cases à cocher s'affichent sous forme de caractères Unicode, comme ✓ (coché) ou ☐ (décoché).
Les cases à cocher cochées ont la valeur filled_checkbox :
under pages > x > formFields > x > fieldValue > valueType.. Les cases à cocher non cochées ont la valeur unfilled_checkbox.
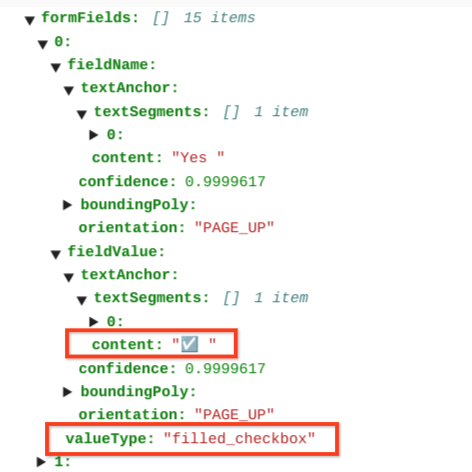
Les champs de contenu affichent la valeur du contenu de la case à cocher, comme indiqué par le symbole ✓ au chemin d'accès pages>formFields>x>fieldValue>textAnchor>content.
Pour vous aider à visualiser la structure du document, les images suivantes dessinent des polygones de délimitation pour page.formFields et page.tables.
Champs de formulaire
Tables
Exemples de code
Les exemples de code suivants montrent comment envoyer une demande de traitement, puis lire et imprimer les champs dans le terminal :
Java
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Java.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Node.js.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez le Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Entités, entités imbriquées et valeurs normalisées
De nombreux processeurs spécialisés extraient des données structurées ancrées dans un schéma bien défini. Par exemple, l'analyseur de factures détecte des champs spécifiques tels que invoice_date et supplier_name. Voici un exemple de facture :
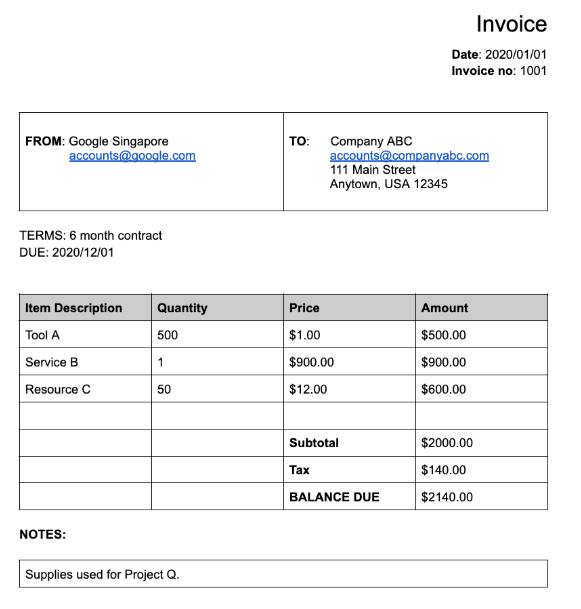
Voici l'objet de document complet tel qu'il est renvoyé par l'analyseur de factures :
Voici quelques-unes des parties importantes de l'objet document :
Champs détectés :
Entitiescontient les champs que le processeur a pu détecter, par exempleinvoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }Pour certains champs, le processeur normalise également la valeur. Dans cet exemple, la date a été normalisée et est passée de
2020/01/01à2020-01-01.Normalisation : pour de nombreux champs spécifiques acceptés, le processeur normalise également la valeur et renvoie également un
entity. Le champnormalizedValueest ajouté au champ brut extrait obtenu viatextAnchorde chaque entité. Elle normalise donc le texte littéral, en divisant souvent la valeur textuelle en sous-champs. Par exemple, une date comme le 1er septembre 2024 serait représentée comme suit :
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
Dans cet exemple, la date a été normalisée de 2020/01/01 à 2020-01-01, un format standardisé permettant de réduire le post-traitement et de permettre la conversion au format choisi.
Les adresses sont également souvent normalisées, ce qui décompose les éléments de l'adresse en champs individuels. Les nombres sont normalisés en utilisant un nombre entier ou à virgule flottante comme normalizedValue.
- Enrichissement : certains processeurs et champs sont également compatibles avec l'enrichissement.
Par exemple, le
supplier_named'origine dans le documentGoogle Singaporea été normalisé par rapport à Enterprise Knowledge Graph pour devenirGoogle Asia Pacific, Singapore. Notez également que, comme Enterprise Knowledge Graph contient des informations sur Google, Document AI déduitsupplier_addressmême si ce n'était pas présent dans l'exemple de document.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Champs imbriqués : vous pouvez créer des schémas (champs) imbriqués en déclarant d'abord une entité comme parent, puis en créant des entités enfants sous le parent. La réponse d'analyse pour le parent inclut les champs enfants dans l'élément
propertiesdu champ parent. Dans l'exemple suivant,line_itemest un champ parent qui comporte deux champs enfants :line_item/descriptionetline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
Les analyseurs suivants le respectent :
- Extraire (extracteur personnalisé)
- Ancienne version
- Analyseur de relevés bancaires
- Analyseur de dépenses
- Analyseur de factures
- Analyseur de bulletins de salaire
- Analyseur de formulaires W2
Exemples de code
Les exemples de code suivants montrent comment envoyer une requête de traitement, puis lire et imprimer les champs d'un processeur spécialisé dans le terminal :
Java
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Java.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Node.js.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Extracteur de documents personnalisé
L'extracteur de document personnalisé peut extraire des entités personnalisées à partir de documents pour lesquels aucun processeur pré-entraîné n'est disponible. Pour ce faire, vous pouvez entraîner un modèle personnalisé ou utiliser des modèles de fondation d'IA générative pour extraire des entités nommées sans aucun entraînement. Pour en savoir plus, consultez Créer un extracteur de documents personnalisé dans la console.
- Si vous entraînez un modèle personnalisé, le processeur peut être utilisé exactement de la même manière qu'un processeur d'extraction d'entités pré-entraîné.
- Si vous utilisez un modèle de fondation, vous pouvez créer une version du processeur pour extraire des entités spécifiques pour chaque requête ou le configurer pour chaque requête.
Pour en savoir plus sur la structure de sortie, consultez Entités, entités imbriquées et valeurs normalisées.
Exemples de code
Si vous utilisez un modèle personnalisé ou si vous avez créé une version de processeur à l'aide d'un modèle de fondation, utilisez les exemples de code d'extraction d'entités.
L'exemple de code suivant montre comment configurer des entités spécifiques pour un extracteur de documents personnalisés de modèle de base sur une base par requête et comment imprimer les entités extraites :
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Synthèse
Le processeur de synthèse utilise des modèles de fondation d'IA générative pour résumer le texte extrait d'un document. Vous pouvez personnaliser la longueur et le format de la réponse de différentes manières :
- Longueur
BRIEF: un bref résumé d'une ou deux phrasesMODERATE: un résumé d'un paragrapheCOMPREHENSIVE: l'option la plus longue disponible
- Format
Vous pouvez créer une version de processeur pour une longueur et un format spécifiques, ou la configurer pour chaque requête.
Le texte résumé apparaît dans Document.entities.normalizedValue.text. Vous trouverez un exemple complet de fichier JSON de sortie dans Exemple de sortie du processeur.
Pour en savoir plus, consultez Créer un résumeur de documents dans la console.
Exemples de code
L'exemple de code suivant montre comment configurer une longueur et un format spécifiques dans une requête de traitement, puis comment imprimer le texte résumé :
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Fractionnement et classification
Voici un PDF composite de 10 pages contenant différents types de documents et de formulaires :
Voici l'objet document complet tel qu'il est renvoyé par le classificateur et séparateur de documents de prêt :
Chaque document détecté par le séparateur est représenté par un entity. Exemple :
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorindique que ce document comporte deux pages. Notez quepageRefs[].pageest basé sur zéro et correspond à l'index du champdocument.pages[].Entity.typeindique que ce document est un formulaire 1040 Schedule SE. Pour obtenir la liste complète des types de documents pouvant être identifiés, consultez Types de documents identifiés dans la documentation du processeur.
Pour en savoir plus, consultez Comportement des séparateurs de documents.
Exemples de code
Les séparateurs identifient les limites des pages, mais ne divisent pas le document d'entrée pour vous. Vous pouvez utiliser la boîte à outils Document AI pour diviser physiquement un fichier PDF en utilisant les limites de page. Les exemples de code suivants impriment les plages de pages sans fractionner le PDF :
Java
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Java.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Node.js.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Document traité.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Boîte à outils Document AI
Document AI Toolbox est un SDK pour Python qui fournit des fonctions utilitaires permettant de gérer, de manipuler et d'extraire des informations de la réponse du document.
Il crée un objet de document "encapsulé" à partir d'une réponse de document traité provenant de fichiers JSON dans Cloud Storage, de fichiers JSON locaux ou d'une sortie directement à partir de la méthode process_document().
Il peut effectuer les actions suivantes :
- Combiner les fichiers JSON
Documentfragmentés du traitement par lot en un seul document "encapsulé". - Exporter les partitions en tant que
Documentunifié. -
Obtenez le résultat
Documentà partir de : - Accédez au texte de
Pages,Lines,Paragraphs,FormFieldsetTablessans gérer les informationsLayout. - Recherchez un
Pagescontenant une chaîne cible ou correspondant à une expression régulière. - Recherchez
FormFieldspar nom. - Recherchez
Entitiespar type. - Convertissez
Tablesen DataFrame Pandas ou en CSV. - Insérez
EntitiesetFormFieldsdans une table BigQuery. - Divisez un fichier PDF en fonction de la sortie d'un processeur Splitter/Classifier.
- Extrais l'image
Entitiesdes cadres de délimitation deDocument. -
Convertissez
Documentsvers et depuis les formats couramment utilisés :- API Cloud Vision
AnnotateFileResponse - hOCR
- Formats de traitement des documents tiers
- API Cloud Vision
- Créez des lots de documents à traiter à partir d'un dossier Cloud Storage.
Exemples de code
Les exemples de code suivants montrent comment utiliser Document AI Toolbox.