Document AI génère des métriques d'évaluation, telles que la précision et le rappel, pour vous aider à déterminer les performances prédictives de vos processeurs.
Ces métriques d'évaluation sont générées en comparant les entités renvoyées par le processeur (les prédictions) avec les annotations des documents de test. Si votre processeur ne dispose pas d'un ensemble de test, vous devez d'abord créer un ensemble de données et libeller les documents de test.
les étapes pour exécuter une évaluation.
Une évaluation est automatiquement exécutée chaque fois que vous entraînez ou surentraînez une version de processeur.
Vous pouvez également exécuter une évaluation manuellement. Cette étape est nécessaire pour générer des métriques mises à jour après avoir modifié l'ensemble de test ou si vous évaluez une version de processeur préentraînée.
UI Web
Dans la console Google Cloud , accédez à la page Processeurs et sélectionnez votre processeur.
Dans l'onglet Évaluer et tester, sélectionnez la version du processeur à évaluer, puis cliquez sur Exécuter une nouvelle évaluation.
Une fois l'entraînement terminé, la page contient des métriques d'évaluation pour tous les libellés et pour chacun d'eux.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Obtenir les résultats d'une évaluation
UI Web
Dans la console Google Cloud , accédez à la page Processeurs et sélectionnez votre processeur.
Dans l'onglet Évaluer et tester, sélectionnez la version du processeur pour afficher l'évaluation.
Une fois l'entraînement terminé, la page contient des métriques d'évaluation pour tous les libellés et pour chacun d'eux.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Lister toutes les évaluations pour une version de processeur
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Métriques d'évaluation pour tous les libellés
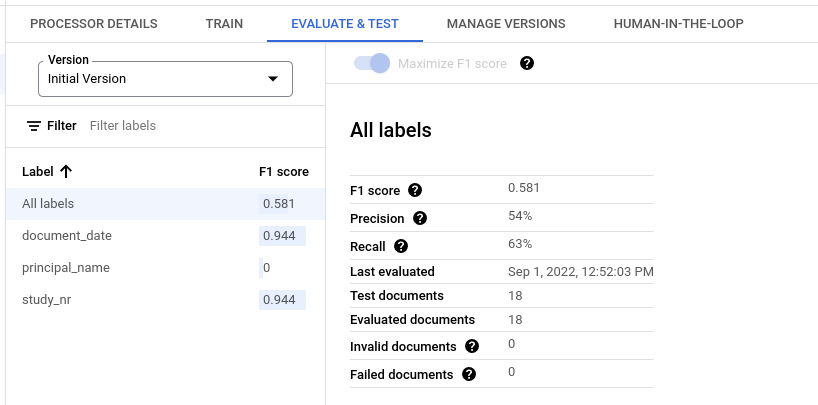
Les métriques pour Toutes les étiquettes sont calculées en fonction du nombre de vrais positifs, de faux positifs et de faux négatifs dans l'ensemble de données pour toutes les étiquettes. Elles sont donc pondérées par le nombre de fois où chaque étiquette apparaît dans l'ensemble de données. Pour obtenir la définition de ces termes, consultez Métriques d'évaluation pour les libellés individuels.
Précision : proportion de prédictions correspondant aux annotations de l'ensemble de test. Définie comme
True Positives / (True Positives + False Positives)Rappel : proportion des annotations de l'ensemble de test qui ont été correctement prédites. Définie comme
True Positives / (True Positives + False Negatives)Score F1 : moyenne harmonique de la précision et du rappel, qui combine ces deux valeurs en une seule métrique, en leur accordant la même importance. Définie comme
2 * (Precision * Recall) / (Precision + Recall)
Métriques d'évaluation pour les libellés individuels
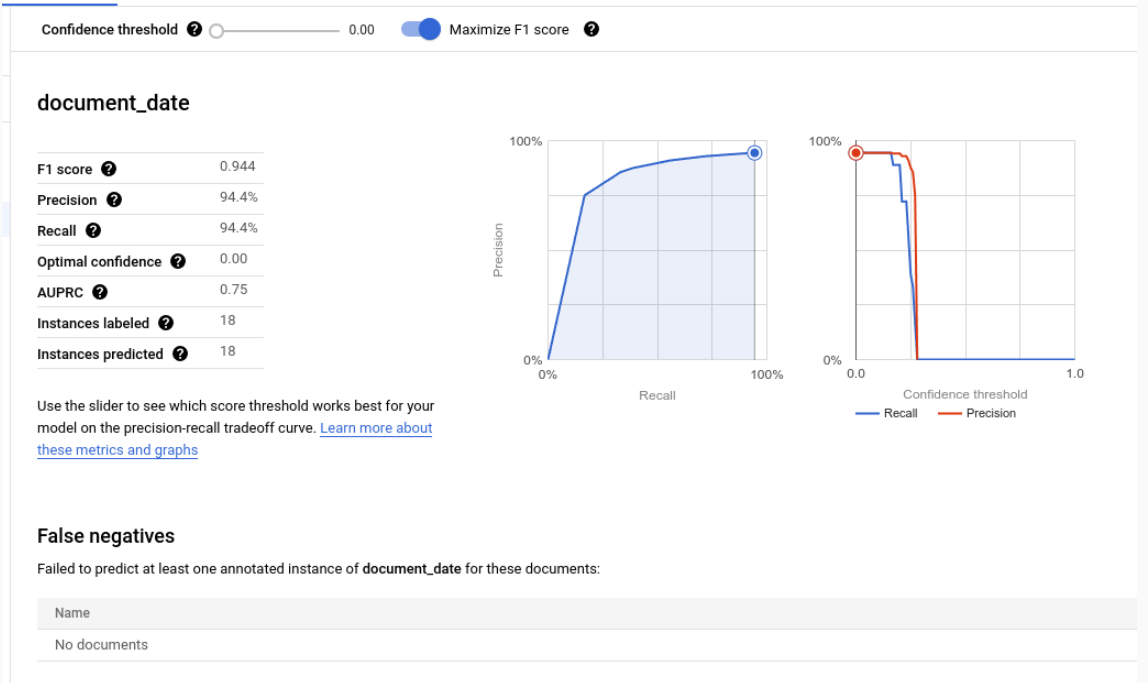
Vrais positifs : entités prédites qui correspondent à une annotation dans le document de test. Pour en savoir plus, consultez la section Comportement de la mise en correspondance.
Faux positifs : entités prédites qui ne correspondent à aucune annotation dans le document de test.
Faux négatifs : annotations du document de test qui ne correspondent à aucune des entités prédites.
- Faux négatifs (sous le seuil) : annotations dans le document de test qui auraient correspondu à une entité prédite, mais dont la niveau de confiance est inférieure au seuil de confiance spécifié.
Seuil de confiance
La logique d'évaluation ignore toutes les prédictions dont le niveau de confiance est inférieur au seuil de confiance spécifié, même si la prédiction est correcte. Document AI fournit une liste des faux négatifs (en dessous du seuil), qui sont les annotations qui auraient une correspondance si le seuil de confiance était plus bas.
Document AI calcule automatiquement le seuil optimal, qui maximise le score F1, et définit par défaut le seuil de confiance sur cette valeur optimale.
Vous pouvez choisir votre propre seuil de confiance en déplaçant le curseur. En général, un seuil de confiance plus élevé entraîne les conséquences suivantes :
- une précision plus élevée, car les prédictions sont plus susceptibles d'être correctes.
- un rappel plus faible, car il y a moins de prédictions.
Entités tabulaires
Les métriques d'un libellé parent ne sont pas calculées en faisant la moyenne directe des métriques enfants. Elles sont plutôt calculées en appliquant le seuil de confiance du parent à tous ses libellés enfants et en agrégeant les résultats.
Le seuil optimal pour le parent est la valeur du seuil de confiance qui, lorsqu'elle est appliquée à tous les enfants, génère le score F1 maximal pour le parent.
Comportement de mise en correspondance
Une entité prédite correspond à une annotation si :
- le type de l'entité prédite (
entity.type) correspond au nom du libellé de l'annotation. - la valeur de l'entité prédite (
entity.mention_textouentity.normalized_value.text) correspond à la valeur textuelle de l'annotation, sous réserve de la correspondance approximative si elle est activée.
Notez que seuls le type et la valeur du texte sont utilisés pour la mise en correspondance. Les autres informations, telles que les ancres de texte et les cadres de sélection (à l'exception des entités tabulaires décrites ci-dessous), ne sont pas utilisées.
Libellés à occurrence unique ou multiple
Les libellés à occurrence unique ont une valeur par document (par exemple, l'ID de facture), même si cette valeur est annotée plusieurs fois dans le même document (par exemple, l'ID de facture apparaît sur chaque page du même document). Même si les annotations multiples ont un texte différent, elles sont considérées comme égales. En d'autres termes, si une entité prédite correspond à l'une des annotations, elle est considérée comme une correspondance. Les annotations supplémentaires sont considérées comme des mentions en double et ne contribuent pas au nombre de vrais positifs, de faux positifs ni de faux négatifs.
Les libellés à occurrences multiples peuvent avoir plusieurs valeurs différentes. Ainsi, chaque entité et annotation prédites sont prises en compte et mises en correspondance séparément. Si un document contient N annotations pour un libellé à occurrences multiples, il peut y avoir N correspondances avec les entités prédites. Chaque entité et annotation prédites sont comptabilisées indépendamment comme un vrai positif, un faux positif ou un faux négatif.
Correspondance partielle
Le bouton Correspondance approximative vous permet de renforcer ou d'assouplir certaines règles de correspondance pour diminuer ou augmenter le nombre de correspondances.
Par exemple, sans la correspondance approximative, la chaîne ABC ne correspond pas à abc en raison de la casse. Mais avec la correspondance partielle, elles correspondent.
Lorsque la correspondance partielle est activée, les règles sont modifiées comme suit :
Normalisation des espaces blancs : supprime les espaces blancs de début et de fin, et condense les espaces blancs intermédiaires consécutifs (y compris les retours à la ligne) en un seul espace.
Suppression de la ponctuation de début et de fin : supprime les caractères de ponctuation de début et de fin suivants :
!,.:;-"?|.Correspondance insensible à la casse : convertit tous les caractères en minuscules.
Normalisation des montants : pour les libellés dont le type de données est
money, supprimez les symboles monétaires au début et à la fin.
Entités tabulaires
Les entités et les annotations parentes n'ont pas de valeurs de texte et sont mises en correspondance en fonction des cadres de sélection combinés de leurs enfants. S'il n'y a qu'un seul parent prédit et un seul parent annoté, ils sont automatiquement mis en correspondance, quelles que soient les boîtes englobantes.
Une fois les parents mis en correspondance, leurs enfants le sont comme s'il s'agissait d'entités non tabulaires. Si les parents ne sont pas associés, Document AI n'essaiera pas d'associer leurs enfants. Cela signifie que les entités enfants peuvent être considérées comme incorrectes, même avec le même contenu textuel, si leurs entités parentes ne correspondent pas.
Les entités parent / enfant sont une fonctionnalité en version preview et ne sont compatibles qu'avec les tableaux comportant un seul niveau d'imbrication.
Exporter les métriques d'évaluation
Dans la console Google Cloud , accédez à la page Processeurs et sélectionnez votre processeur.
Dans l'onglet Évaluer et tester, cliquez sur Télécharger les métriques pour télécharger les métriques d'évaluation au format JSON.