Mit dem Training und der Extraktion benutzerdefinierter Modelle können Sie Ihr eigenes Modell erstellen, das speziell für Ihre Dokumente entwickelt wurde, ohne generative KI zu verwenden. Diese Option ist ideal, wenn Sie keine generative KI verwenden und alle Aspekte des trainierten Modells selbst steuern möchten.
Dataset-Konfiguration
Zum Trainieren, Aktualisieren oder Bewerten einer Prozessorversion ist ein Dokument-Dataset erforderlich. Document AI-Prozessoren lernen aus Beispielen, genau wie Menschen. Das Dataset trägt zur Stabilität des Prozessors in Bezug auf die Leistung bei.Trainings-Dataset
Um das Modell und seine Genauigkeit zu verbessern, trainieren Sie ein Dataset mit Ihren Dokumenten. Das Modell besteht aus Dokumenten mit Ground Truth. Sie benötigen mindestens drei Dokumente, um ein neues Modell zu trainieren.Test-Dataset
Das Test-Dataset wird vom Modell verwendet, um einen F1-Wert (Genauigkeit) zu generieren. Es besteht aus Dokumenten mit Grundwahrheit. Um zu sehen, wie oft das Modell richtig liegt, wird die Ground Truth verwendet, um die Vorhersagen des Modells (extrahierte Felder aus dem Modell) mit den richtigen Antworten zu vergleichen. Das Test-Dataset sollte mindestens drei Dokumente enthalten.Vorbereitung
Falls noch nicht geschehen, aktivieren Sie die Abrechnung und die Document AI API.
Benutzerdefiniertes Modell erstellen und bewerten
Erstellen Sie zuerst einen benutzerdefinierten Prozessor und bewerten Sie ihn dann.
Erstellen Sie einen Prozessor und definieren Sie die Felder, die Sie extrahieren möchten. Das ist wichtig, da es sich auf die Qualität der Extraktion auswirkt.
Dataset-Speicherort festlegen: Wählen Sie den Standardordner Von Google verwaltet aus. Dies kann kurz nach der Erstellung des Prozessors automatisch erfolgen.
Rufen Sie den Tab Erstellen auf und wählen Sie Dokumente importieren aus. Das automatische Labeling muss aktiviert sein (siehe Automatisches Labeling mit dem Basismodell). Sie benötigen mindestens 10 Dokumente im Trainings-Dataset und 10 Dokumente im Test-Dataset, um ein benutzerdefiniertes Modell zu trainieren.
Modell trainieren:
- Wählen Sie Neue Version trainieren aus und geben Sie einen Namen für die Prozessorversion ein.
- Gehen Sie zu Erweiterte Optionen einblenden und wählen Sie die Option Modellbasiert aus.
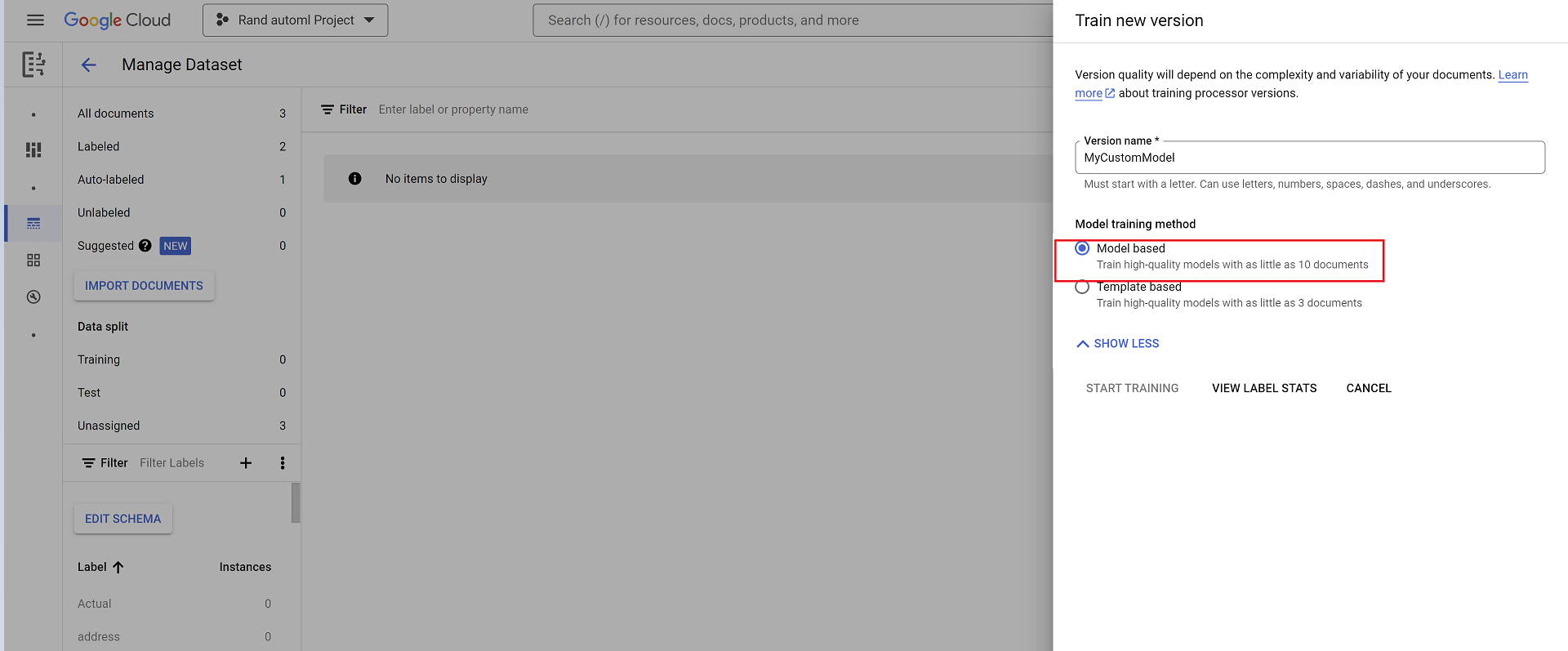
Bewertung:
- Rufen Sie Bewerten und testen auf, wählen Sie die gerade trainierte Version aus und klicken Sie dann auf Vollständige Bewertung ansehen.
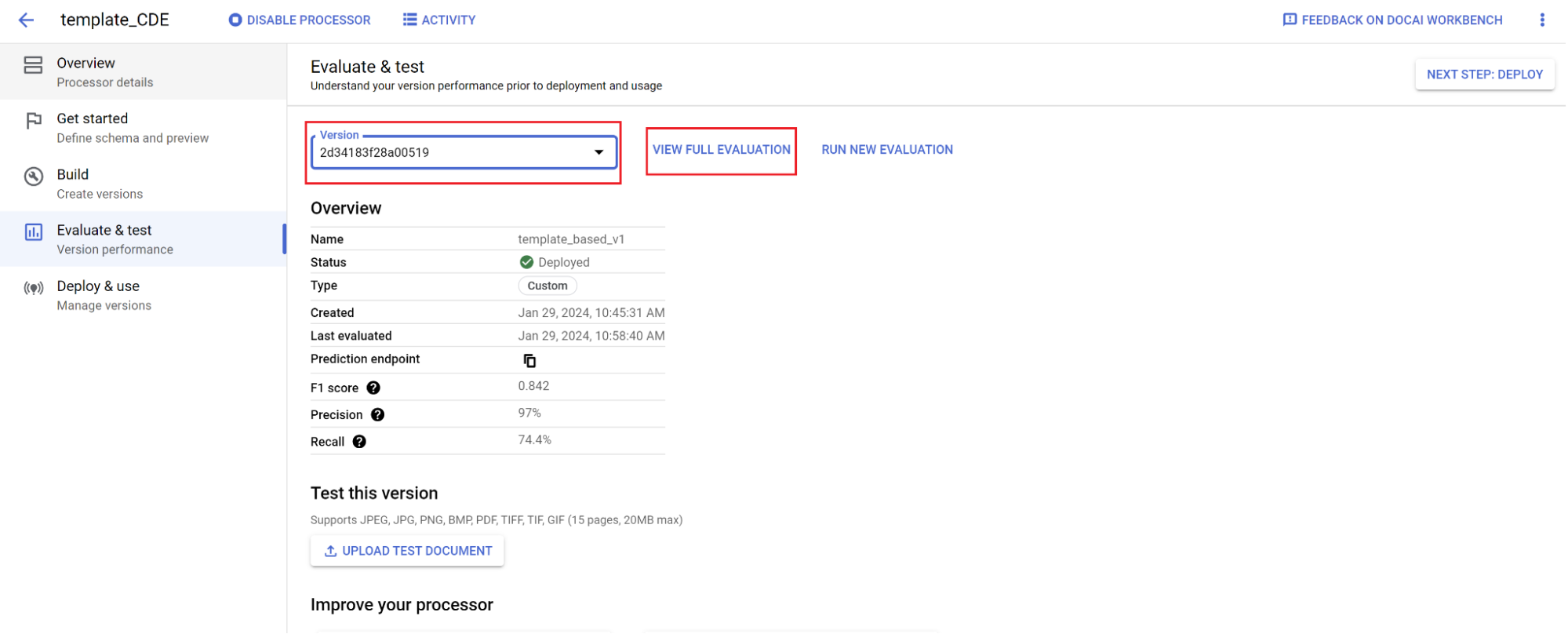
- Sie sehen jetzt Messwerte wie F1-Wert, Genauigkeit und Trefferquote für das gesamte Dokument und jedes Feld.
- Entscheiden Sie, ob die Leistung Ihren Produktionszielen entspricht. Wenn nicht, sollten Sie die Trainings- und Testsätze neu bewerten und in der Regel Dokumente hinzufügen, die nicht gut geparst werden.
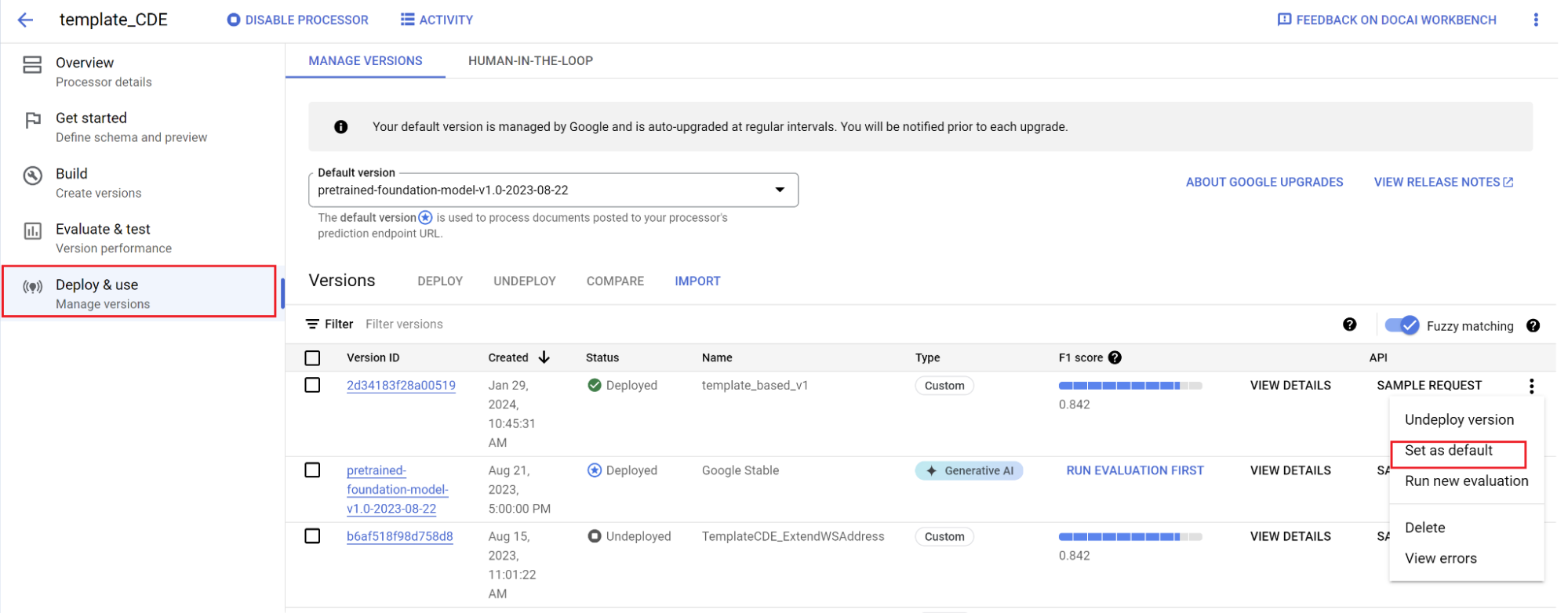
Legen Sie eine neue Version als Standard fest.
- Rufen Sie Versionen verwalten auf.
- Rufen Sie das -Menü auf und wählen Sie Als Standard festlegen aus.
Ihr Modell wurde jetzt bereitgestellt und für Dokumente, die an diesen Prozessor gesendet werden, wird jetzt Ihre benutzerdefinierte Version verwendet. Sie möchten die Leistung des Modells bewerten, um festzustellen, ob es weiter trainiert werden muss.
Bewertungsreferenz
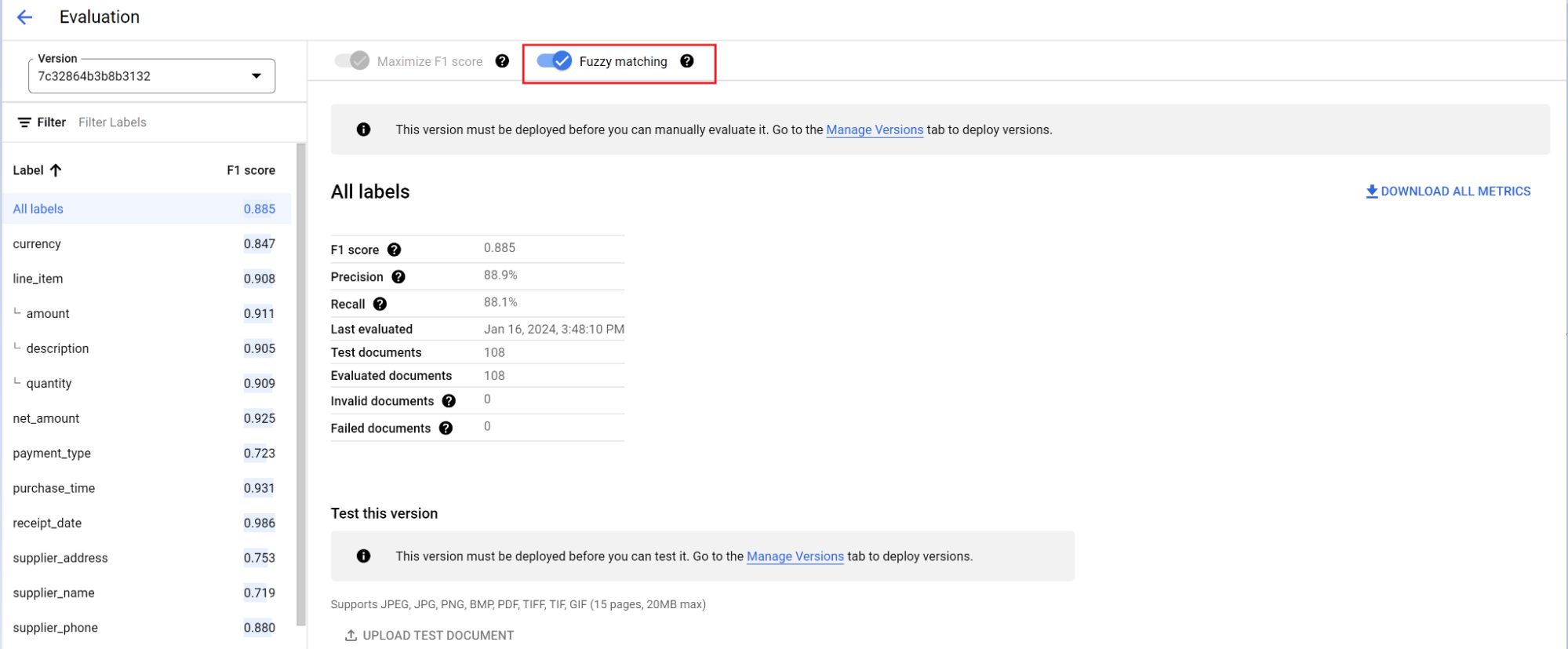
Die Auswertungs-Engine kann sowohl genaue als auch unscharfe Übereinstimmungen erkennen. Bei einer genauen Übereinstimmung muss der extrahierte Wert genau mit der Ground Truth übereinstimmen. Andernfalls wird er als Fehler gezählt.
Extraktionen mit unscharfem Abgleich, die geringfügige Unterschiede wie unterschiedliche Groß- und Kleinschreibung aufwiesen, werden weiterhin als Übereinstimmung gezählt. Dies kann auf dem Bildschirm Bewertung geändert werden.
Automatisches Labeling mit dem Foundation Model
Mit dem Basismodell lassen sich Felder für eine Vielzahl von Dokumenttypen präzise extrahieren. Sie können jedoch auch zusätzliche Trainingsdaten bereitstellen, um die Genauigkeit des Modells für bestimmte Dokumentstrukturen zu verbessern.
Document AI verwendet die von Ihnen definierten Labelnamen und vorherige Annotationen, um Dokumente in großem Umfang automatisch zu labeln.
- Nachdem Sie einen benutzerdefinierten Prozessor erstellt haben, rufen Sie den Tab Erste Schritte auf.
- Wählen Sie Neues Feld erstellen aus.
- Geben Sie einen aussagekräftigen Namen ein und füllen Sie das Beschreibungsfeld aus. Mithilfe der Property-Beschreibung können Sie für jede Entität zusätzlichen Kontext, Statistiken und Vorwissen angeben, um die Accuracy und Leistung der Extraktion zu verbessern.
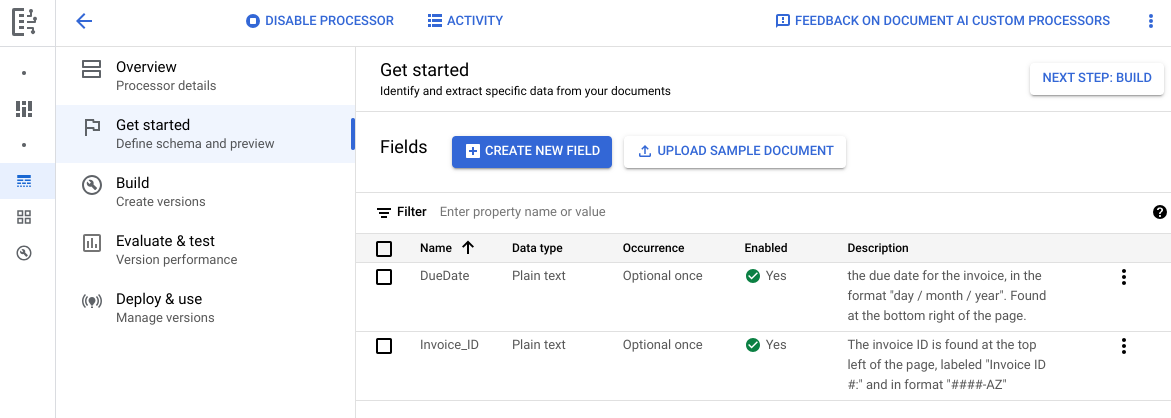
Rufen Sie den Tab Erstellen auf und wählen Sie Dokumente importieren aus.
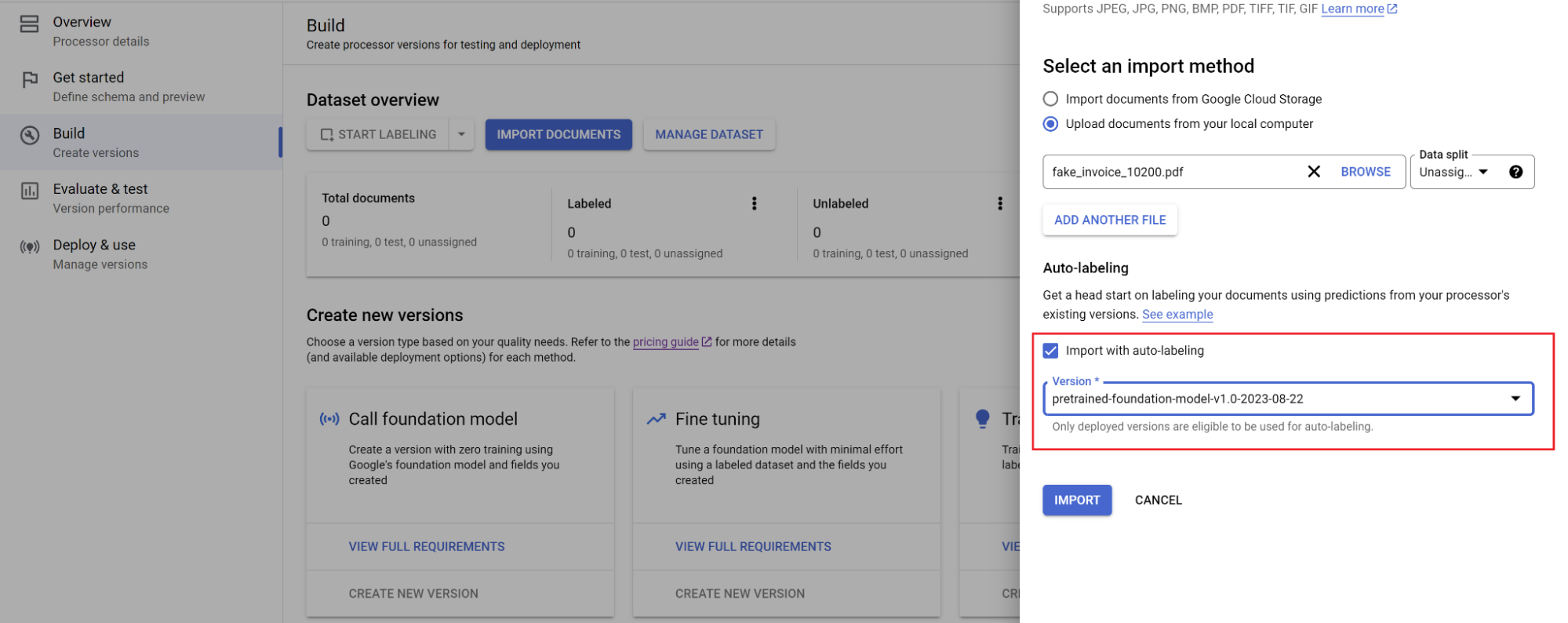
Wählen Sie den Pfad der Dokumente und das Set aus, in das die Dokumente importiert werden sollen. Klicken Sie das Kästchen für automatisches Labeling an und wählen Sie das Basismodell aus.
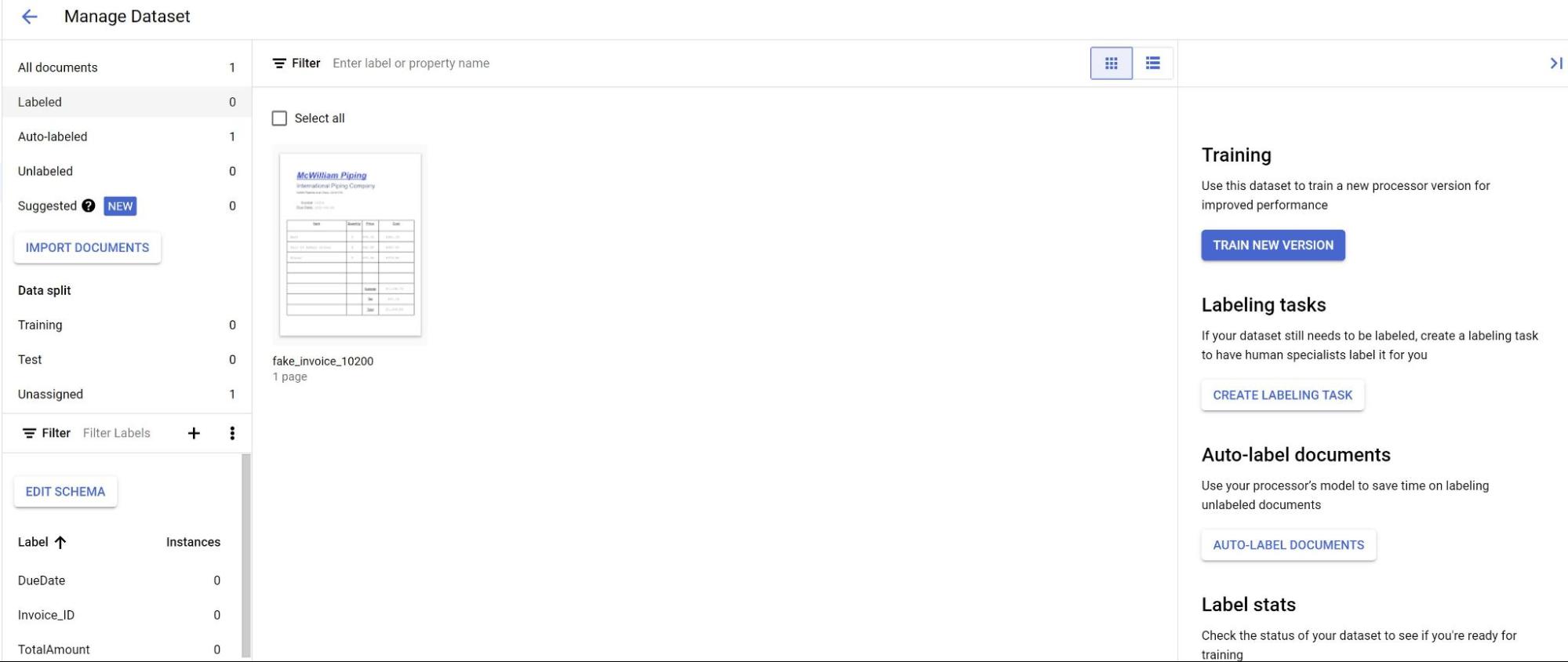
Wählen Sie auf dem Tab Erstellen die Option Dataset verwalten aus. Sie sollten jetzt Ihre importierten Dokumente sehen. Wählen Sie eines Ihrer Dokumente aus.
Die Vorhersagen des Modells werden jetzt lila hervorgehoben.
- Prüfen Sie jedes vom Modell vorhergesagte Label und stellen Sie sicher, dass es korrekt ist. Falls Felder fehlen, fügen Sie diese ebenfalls hinzu.
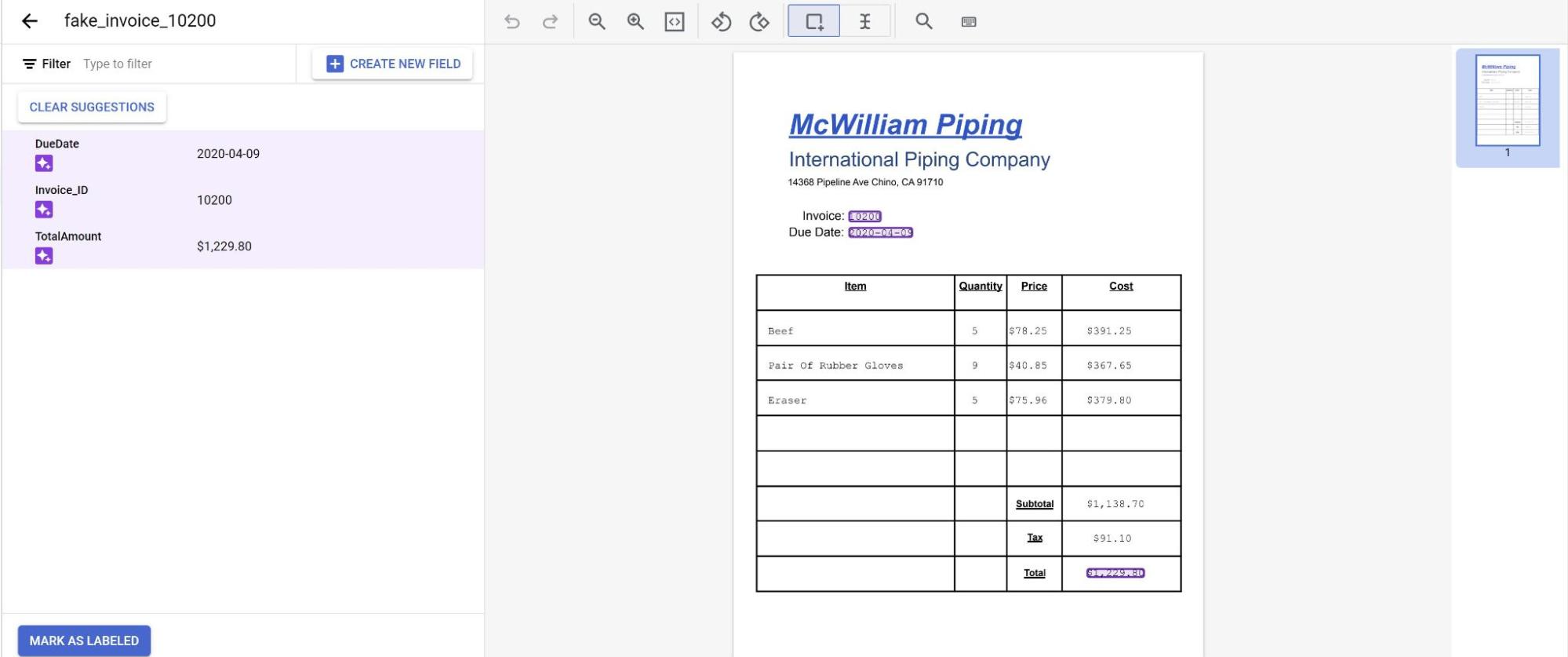
- Nachdem das Dokument überprüft wurde, wählen Sie Als „Mit Label versehen“ markieren aus. Das Dokument kann jetzt vom Modell verwendet werden. Achten Sie darauf, dass sich das Dokument entweder im Test- oder im Training-Set befindet.