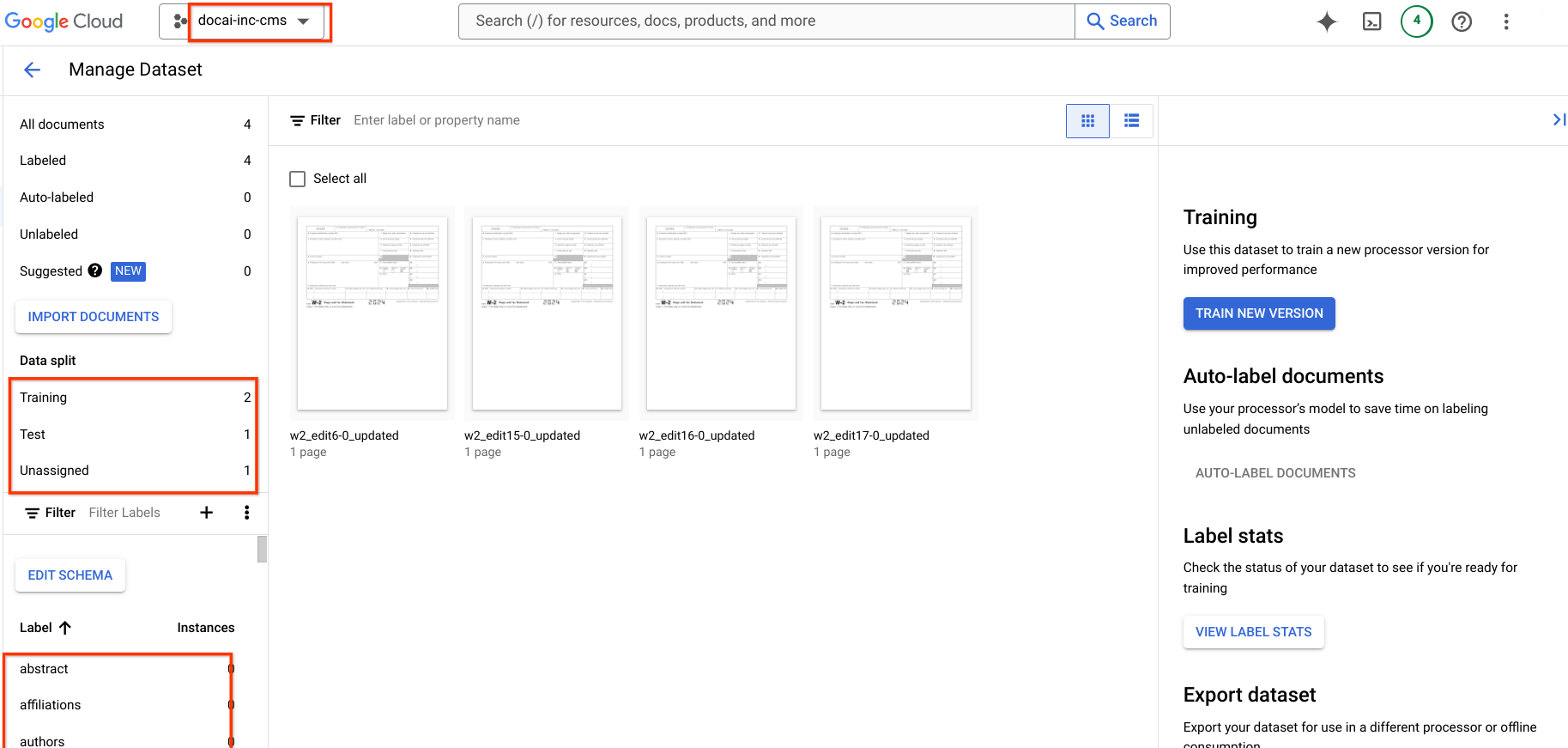
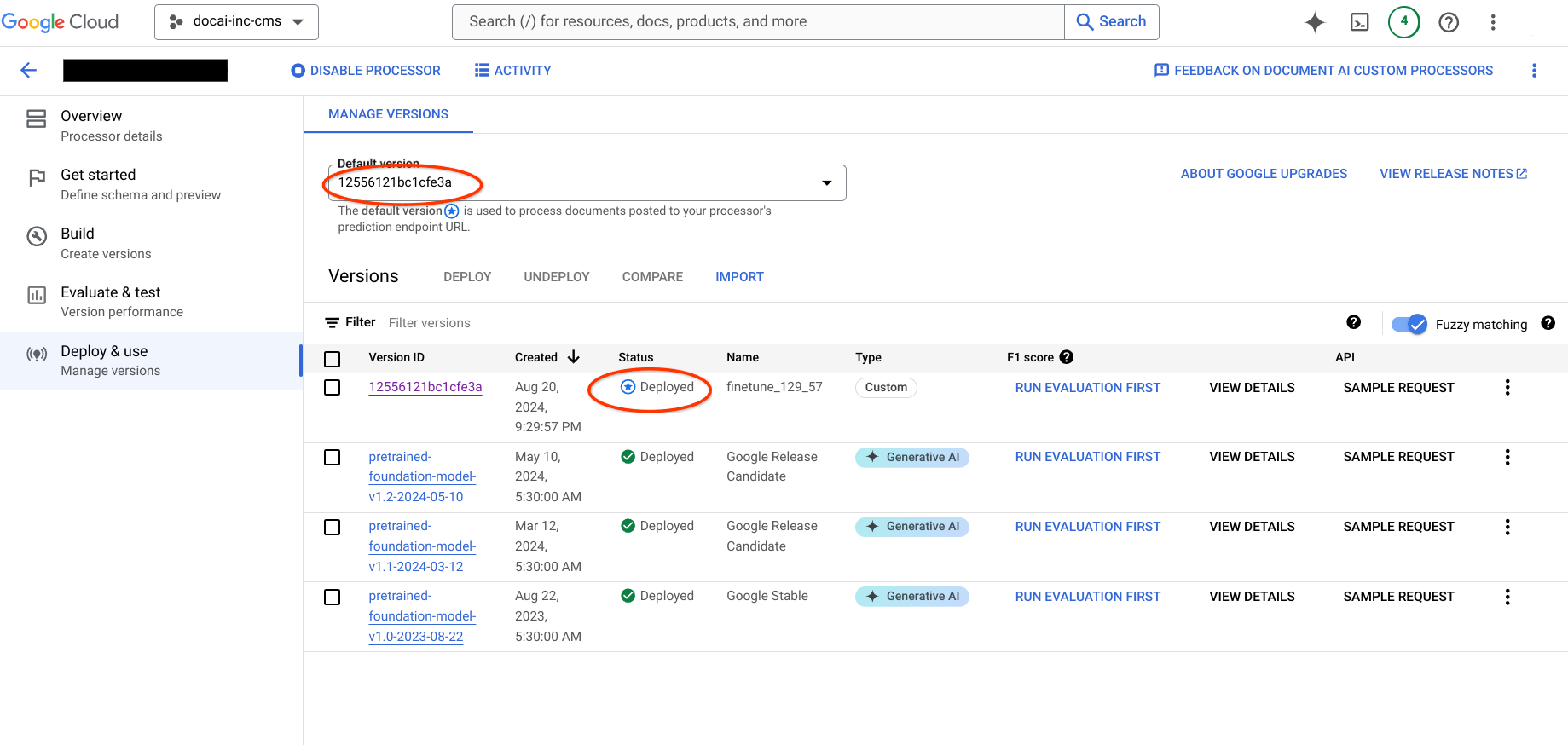
このページでは、Document AI のトレーニング済みプロセッサ バージョンを、データセット スキーマとサンプルとともに、ソース プロセッサから宛先プロセッサにコピーする手順について説明します。これらの手順では、プロセッサ バージョンのインポート、デプロイ、宛先プロジェクトでのデフォルト バージョンとしての設定のプロセスが自動化されます。
始める前に
- Google Cloud プロジェクト ID を取得します。
- Document AI プロセッサ ID を取得している。
- Cloud Storage を使用している。
- Python を使用する: Jupyter ノートブック(Vertex AI)。
- 移行元プロジェクトと移行先プロジェクトのサービス アカウントにアクセス権を付与する権限が必要です。
手順
手順は次のとおりです。
ステップ 1: Vertex AI Notebook に関連付けられているサービス アカウントを特定する
!gcloud config list account
出力:
[core]
account = example@automl-project.iam.gserviceaccount.com
Your active configuration is: [default]
ステップ 2: サービス アカウントに必要な権限を付与する
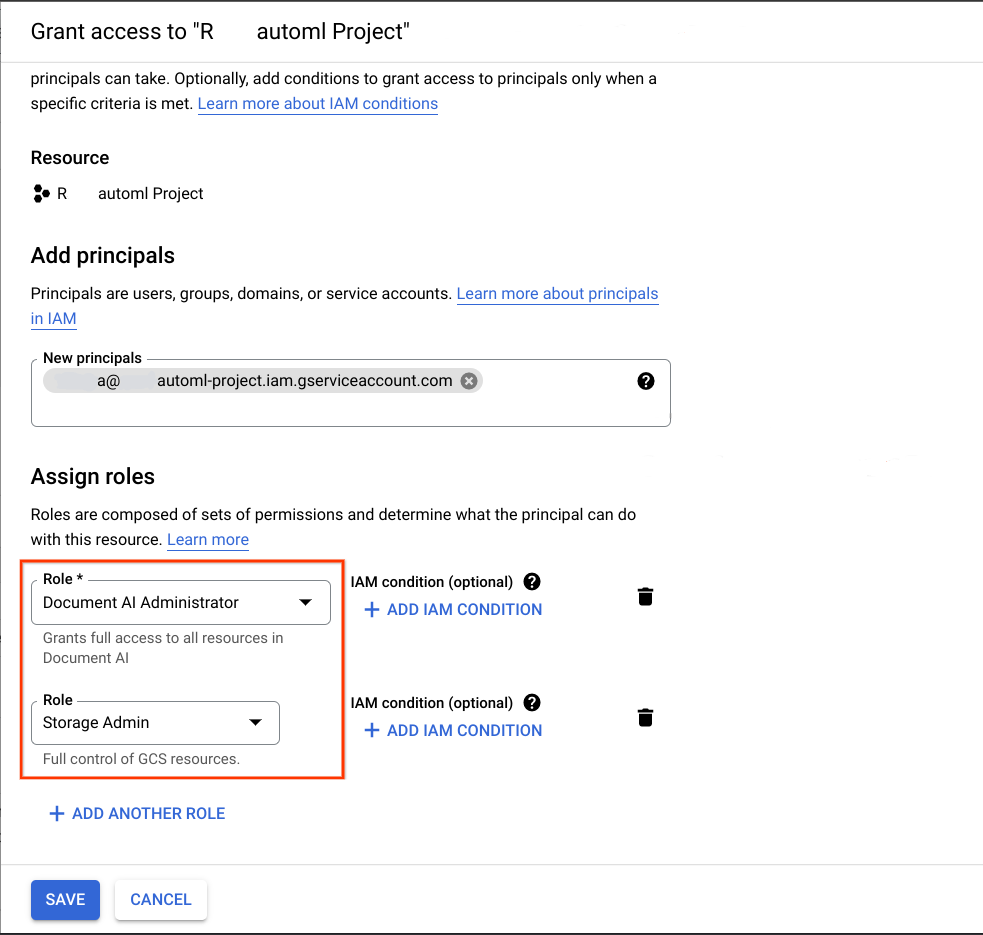
移行の宛先となる Google Cloud プロジェクトで、前の手順で取得したサービス アカウントをプリンシパルとして追加し、次の 2 つのロールを割り当てます。
- Document AI 管理者
- ストレージ管理者
詳細については、サービス アカウントへのロールの付与と顧客管理の暗号鍵(CMEK)をご覧ください。
移行を機能させるには、このノートブックの実行に使用されるサービス アカウントに次の権限が必要です。
- データセット バケットを作成する(存在しない場合は作成する)ための転送元プロジェクトと転送先プロジェクトの両方のロールと、すべてのオブジェクトに対する読み取り / 書き込み権限。
- プロセッサ バージョンをインポートするで説明されているように、ソース プロジェクトの Document AI 編集者ロール。
サービス アカウントとして認証と認可を行うことができるように、サービス アカウントの JSON キーをダウンロードします。詳細については、サービス アカウント キーをご覧ください。
次は:
- サービス アカウントに移動します。
- このタスクを実行するサービス アカウントを選択します。
- [鍵] タブに移動し、
Add Keyをクリックして [新しい鍵を作成] を選択します。 - キーのタイプ(JSON を推奨)を選択します。
Createをクリックして、特定のパスにダウンロードします。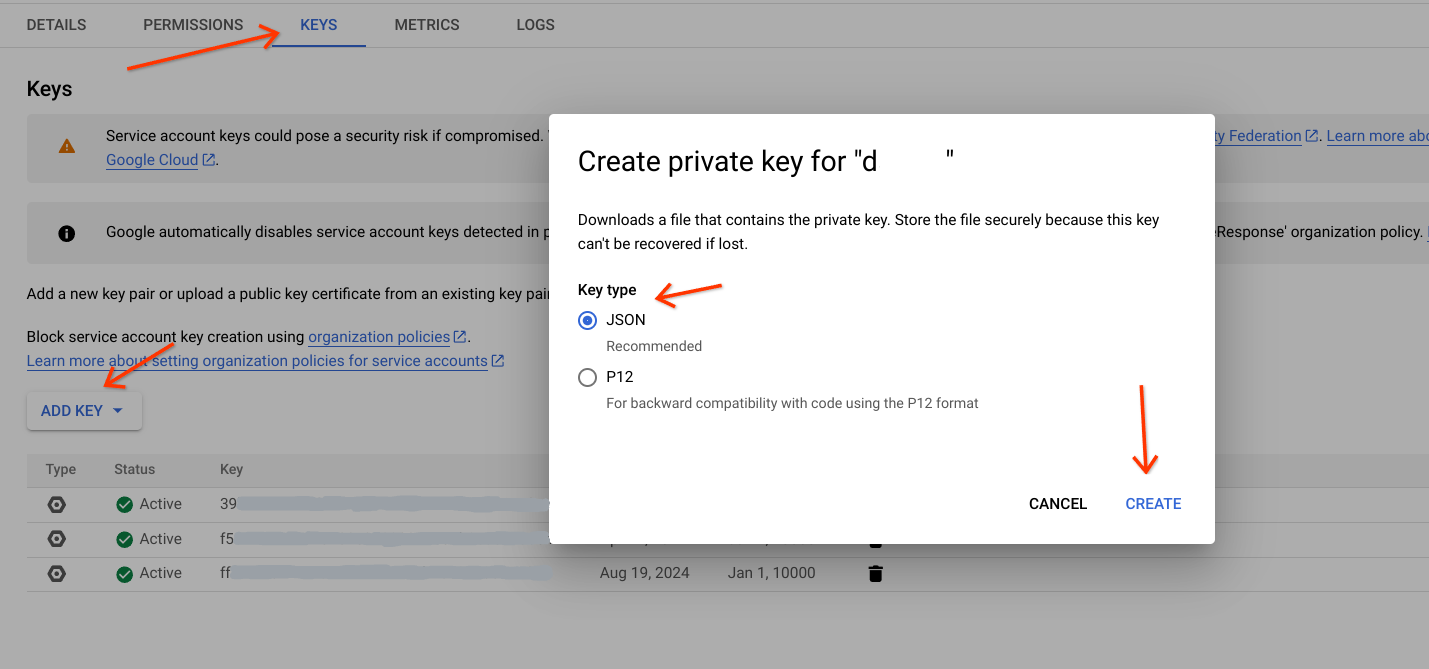
次のスニペットの
service_account_key変数のパスを更新します。
service_account_key='path_to_sa_key.json'
from google.oauth2 import service_account
from google.cloud import storage
# Authenticate the service account
credentials = service_account.Credentials.from_service_account_file(
service_account_key
)
# pass this credentials variable to all client initializations
# storage_client = storage.Client(credentials=credentials)
# docai_client = documentai.DocumentProcessorServiceClient(credentials=credentials)
ステップ 3: ライブラリをインポートする
import time
from pathlib import Path
from typing import Optional, Tuple
from google.cloud.documentai_v1beta3.services.document_service import pagers
from google.api_core.client_options import ClientOptions
from google.api_core.operation import Operation
from google.cloud import documentai_v1beta3 as documentai
from google.cloud import storage
from tqdm import tqdm
ステップ 4: 詳細を入力する
- source_project_id: ソース プロジェクト ID を指定します。
- source_location: ソース プロセッサのロケーション(
usまたはeu)を指定します。 - source_processor_id: Google Cloud Document AI プロセッサ ID を指定します。
- source_processor_version_to_import: トレーニング済みバージョンの Google Cloud Document AI プロセッサ バージョン ID を指定します。
- migrate_dataset: データセットをソース プロセッサから宛先プロセッサに移行する場合は、この値を
TrueまたはFalseとして指定します。移行する場合はTrue、移行しない場合はFalseを指定します。デフォルト値はFalseです。 - source_exported_gcs_path: JSON ファイルを保存する Cloud Storage パスを指定します。
- destination_project_id: 宛先プロジェクト ID を指定します。
- destination_processor_id: 宛先プロジェクトの
""またはprocessor_idのいずれかの Google Cloud Document AI プロセッサ ID を指定します。
source_project_id = "source-project-id"
source_location = "processor-location"
source_processor_id = "source-processor-id"
source_processor_version_to_import = "source-processor-version-id"
migrate_dataset = False # Either True or False
source_exported_gcs_path = (
"gs://bucket/path/to/export_dataset/"
)
destination_project_id = "< destination-project-id >"
# Give an empty string if you wish to create a new processor
destination_processor_id = ""
ステップ 5: コードを実行する
import time
from pathlib import Path
from typing import Optional, Tuple
from google.cloud.documentai_v1beta3.services.document_service import pagers
from google.api_core.client_options import ClientOptions
from google.api_core.operation import Operation
from google.cloud import documentai_v1beta3 as documentai
from google.cloud import storage
from tqdm import tqdm
source_project_id = "source-project-id"
source_location = "processor-location"
source_processor_id = "source-processor-id"
source_processor_version_to_import = "source-processor-version-id"
migrate_dataset = False # Either True or False
source_exported_gcs_path = (
"gs://bucket/path/to/export_dataset/"
)
destination_project_id = "< destination-project-id >"
# Give empty string if you wish to create a new processor
destination_processor_id = ""
exported_bucket_name = source_exported_gcs_path.split("/")[2]
exported_bucket_path_prefix = "/".join(source_exported_gcs_path.split("/")[3:])
destination_location = source_location
def sample_get_processor(project_id: str, processor_id: str, location: str)->Tuple[str, str]:
"""
This function returns Processor Display Name and Type of Processor from source project
Args:
project_id (str): Project ID
processor_id (str): Document AI Processor ID
location (str): Processor Location
Returns:
Tuple[str, str]: Returns Processor Display name and type
"""
client = documentai.DocumentProcessorServiceClient()
print(
f"Fetching processor({processor_id}) details from source project ({project_id})"
)
name = f"projects/{project_id}/locations/{location}/processors/{processor_id}"
request = documentai.GetProcessorRequest(
name=name,
)
response = client.get_processor(request=request)
print(f"Processor Name: {response.name}")
print(f"Processor Display Name: {response.display_name}")
print(f"Processor Type: {response.type_}")
return response.display_name, response.type_
def sample_create_processor(project_id: str, location: str, display_name: str, processor_type: str)->documentai.Processor:
"""It will create Processor in Destination project
Args:
project_id (str): Project ID
location (str): Location fo processor
display_name (str): Processor Display Name
processor_type (str): Google Cloud Document AI Processor type
Returns:
documentai.Processor: Returns details abouts newly created processor
"""
client = documentai.DocumentProcessorServiceClient()
request = documentai.CreateProcessorRequest(
parent=f"projects/{project_id}/locations/{location}",
processor={
"type_": processor_type,
"display_name": display_name,
},
)
print(f"Creating Processor in project: {project_id} in location: {location}")
print(f"Display Name: {display_name} & Processor Type: {processor_type}")
res = client.create_processor(request=request)
return res
def initialize_dataset(project_id: str, processor_id: str, location: str)-> Operation:
"""It will configure dataset for target processor in destination project
Args:
project_id (str): Project ID
processor_id (str): DocuemntAI Processor ID
location (str): Processor Location
Returns:
Operation: An object representing a long-running operation
"""
# opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentServiceClient() # client_options=opts
dataset = documentai.types.Dataset(
name=f"projects/{project_id}/locations/{location}/processors/{processor_id}/dataset",
state=3,
unmanaged_dataset_config={},
spanner_indexing_config={},
)
request = documentai.types.UpdateDatasetRequest(dataset=dataset)
print(
f"Configuring Dataset in project: {project_id} for processor: {processor_id}"
)
response = client.update_dataset(request=request)
return response
def get_dataset_schema(project_id: str, processor_id: str, location: str)->documentai.DatasetSchema:
"""It helps to fetch processor schema
Args:
project_id (str): Project ID
processor_id (str): DocumentAI Processor ID
location (str): Processor Location
Returns:
documentai.DatasetSchema: Return deails about Processor Dataset Schema
"""
# Create a client
processor_name = (
f"projects/{project_id}/locations/{location}/processors/{processor_id}"
)
client = documentai.DocumentServiceClient()
request = documentai.GetDatasetSchemaRequest(
name=processor_name + "/dataset/datasetSchema"
)
# Make the request
print(f"Fetching schema from source processor: {processor_id}")
response = client.get_dataset_schema(request=request)
return response
def upload_dataset_schema(schema: documentai.DatasetSchema)->documentai.DatasetSchema:
"""It helps to update the schema in destination processor
Args:
schema (documentai.DatasetSchema): Document AI Processor Schema details & Metadata
Returns:
documentai.DatasetSchema: Returns Dataset Schema object
"""
client = documentai.DocumentServiceClient()
request = documentai.UpdateDatasetSchemaRequest(dataset_schema=schema)
print("Updating Schema in destination processor")
res = client.update_dataset_schema(request=request)
return res
def store_document_as_json(document: str, bucket_name: str, file_name: str)->None:
"""It helps to upload data to Cloud Storage and stores as a blob
Args:
document (str): Processor response in json string format
bucket_name (str): Cloud Storage bucket name
file_name (str): Cloud Storage blob uri
"""
print(f"\tUploading file to Cloud Storage gs://{bucket_name}/{file_name}")
storage_client = storage.Client()
process_result_bucket = storage_client.get_bucket(bucket_name)
document_blob = storage.Blob(
name=str(Path(file_name)), bucket=process_result_bucket
)
document_blob.upload_from_string(document, content_type="application/json")
def list_documents(project_id: str, location: str, processor: str, page_size: Optional[int]=100, page_token: Optional[str]="")->pagers.ListDocumentsPager:
"""This function helps to list the samples present in processor dataset
Args:
project_id (str): Project ID
location (str): Processor Location
processor (str): DocumentAI Processor ID
page_size (Optional[int], optional): The maximum number of documents to return. Defaults to 100.
page_token (Optional[str], optional): A page token, received from a previous ListDocuments call. Defaults to "".
Returns:
pagers.ListDocumentsPager: Returns all details about documents present in Processor Dataset
"""
client = documentai.DocumentServiceClient()
dataset = (
f"projects/{project_id}/locations/{location}/processors/{processor}/dataset"
)
request = documentai.types.ListDocumentsRequest(
dataset=dataset,
page_token=page_token,
page_size=page_size,
return_total_size=True,
)
print(f"Listingll documents/Samples present in processor: {processor}")
operation = client.list_documents(request)
return operation
def get_document(project_id: str, location: str, processor: str, doc_id: documentai.DocumentId)->documentai.GetDocumentResponse:
"""It will fetch data for individual sample/document present in dataset
Args:
project_id (str): Project ID
location (str): Processor Location
processor (str): Document AI Processor ID
doc_id (documentai.DocumentId): Document identifier
Returns:
documentai.GetDocumentResponse: Returns data related to doc_id
"""
client = documentai.DocumentServiceClient()
dataset = (
f"projects/{project_id}/locations/{location}/processors/{processor}/dataset"
)
request = documentai.GetDocumentRequest(dataset=dataset, document_id=doc_id)
operation = client.get_document(request)
return operation
def import_documents(project_id: str, processor_id: str, location: str, gcs_path: str)->Operation:
"""It helps to import samples/docuemnts from Cloud Storage path to processor via API call
Args:
project_id (str): Project ID
processor_id (str): Document AI Processor ID
location (str): Processor Location
gcs_path (str): Cloud Storage path uri prefix
Returns:
Operation: An object representing a long-running operation
"""
client = documentai.DocumentServiceClient()
dataset = (
f"projects/{project_id}/locations/{location}/processors/{processor_id}/dataset"
)
request = documentai.ImportDocumentsRequest(
dataset=dataset,
batch_documents_import_configs=[
{
"dataset_split": "DATASET_SPLIT_TRAIN",
"batch_input_config": {
"gcs_prefix": {"gcs_uri_prefix": gcs_path + "train/"}
},
},
{
"dataset_split": "DATASET_SPLIT_TEST",
"batch_input_config": {
"gcs_prefix": {"gcs_uri_prefix": gcs_path + "test/"}
},
},
{
"dataset_split": "DATASET_SPLIT_UNASSIGNED",
"batch_input_config": {
"gcs_prefix": {"gcs_uri_prefix": gcs_path + "unassigned/"}
},
},
],
)
print(
f"Importing Documents/samples from {gcs_path} to corresponding tran_test_unassigned sections"
)
response = client.import_documents(request=request)
return response
def import_processor_version(source_processor_version_name: str, destination_processor_name: str)->Operation:
"""It helps to import processor version from source processor to destanation processor
Args:
source_processor_version_name (str): source processor name in this format projects/{project}/locations/{location}/processors/{processor}
destination_processor_name (str): destination processor name in this format projects/{project}/locations/{location}/processors/{processor}
Returns:
Operation: An object representing a long-running operation
"""
from google.cloud import documentai_v1beta3
# provide the source version(to copy) processor details in the following format
client = documentai_v1beta3.DocumentProcessorServiceClient()
# provide the new processor name in the parent variable in format 'projects/{project_number}/locations/{location}/processors/{new_processor_id}'
import google.cloud.documentai_v1beta3 as documentai
op_import_version_req = (
documentai.types.document_processor_service.ImportProcessorVersionRequest(
processor_version_source=source_processor_version_name,
parent=destination_processor_name,
)
)
print("Importing processor from source to destination")
print(f"\tSource: {source_processor_version_name}")
print(f"\tDestination: {destination_processor_name}")
# copying the processor
operation = client.import_processor_version(request=op_import_version_req)
print(operation.metadata)
print("Waitin for operation to complete...")
operation.result()
return operation
def deploy_and_set_default_processor_version(
project_id: str, location: str, processor_id: str, processor_version_id: str
)->None:
"""It helps to deploy to imported processor version and set it as default version
Args:
project_id (str): Project ID
location (str): Processor Location
processor_id (str): Document AI Processor ID
processor_version_id (str): Document AI Processor Version ID
"""
# Construct the resource name of the processor version
processor_name = (
f"projects/{project_id}/locations/{location}/processors/{processor_id}"
)
default_processor_version_name = f"projects/{project_id}/locations/{location}/processors/{processor_id}/processorVersions/{processor_version_id}"
# Initialize the Document AI client
client_options = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentProcessorServiceClient(client_options=client_options)
# Deploy the processor version
operation = client.deploy_processor_version(name=default_processor_version_name)
print(f"Deploying processor version: {operation.operation.name}")
print("Waiting for operation to complete...")
result = operation.result()
print("Processor version deployed")
# Set the deployed version as the default version
request = documentai.SetDefaultProcessorVersionRequest(
processor=processor_name,
default_processor_version=default_processor_version_name,
)
operation = client.set_default_processor_version(request=request)
print(f"Setting default processor version: {operation.operation.name}")
operation.result()
print(f"Default processor version set {default_processor_version_name}")
def main(destination_processor_id: str, migrate_dataset: bool = False)->None:
"""Entry function to perform Processor Migration from Source Project to Destination project
Args:
destination_processor_id (str): Either empty string or processor id in desination project
"""
# Checking processor id of destination project
if destination_processor_id == "":
# Fetching Processor Display Name and Type of Processor from source project
display_name, processor_type = sample_get_processor(
source_project_id, source_processor_id, source_location
)
# Creating Processor in Destination project
des_processor = sample_create_processor(
destination_project_id, destination_location, display_name, processor_type
)
print(des_processor)
destination_processor_id = des_processor.name.split("/")[-1]
# configuring dataset for target processor in destination project
r = initialize_dataset(
destination_project_id, destination_processor_id, destination_location
)
# fetching processor schema from source processor
exported_schema = get_dataset_schema(
source_project_id, source_processor_id, source_location
)
exported_schema.name = f"projects/{destination_project_id}/locations/{destination_location}/processors/{destination_processor_id}/dataset/datasetSchema"
# Copying schema from source processor to desination processor
import_schema = upload_dataset_schema(exported_schema)
if migrate_dataset == True: # to migrate dataset from source to destination processor
print("Migrating Dataset from source to destination processor")
# Fetching/listing the samples/JSONs present in source processor dataset
results = list_documents(source_project_id, source_location, source_processor_id)
document_list = results.document_metadata
while len(document_list) != results.total_size:
page_token = results.next_page_token
results = list_documents(
source_project_id,
source_location,
source_processor_id,
page_token=page_token,
)
document_list.extend(results.document_metadata)
print("Exporting Dataset...")
for doc in tqdm(document_list):
doc_id = doc.document_id
split_type = doc.dataset_type
if split_type == 3:
split = "unassigned"
elif split_type == 2:
split = "test"
elif split_type == 1:
split = "train"
else:
split = "unknown"
file_name = doc.display_name
# fetching/downloading data for individual sample/document present in dataset
res = get_document(
source_project_id, source_location, source_processor_id, doc_id
)
output_file_name = (
f"{exported_bucket_path_prefix.strip('/')}/{split}/{file_name}.json"
)
# Converting Document AI Proto object to JSON string
json_data = documentai.Document.to_json(res.document)
# Uploading JSON data to specified Cloud Storage path
store_document_as_json(json_data, exported_bucket_name, output_file_name)
print(f"Importing dataset to {destination_processor_id}")
gcs_path = source_exported_gcs_path.strip("/") + "/"
project = destination_project_id
location = destination_location
processor = destination_processor_id
# importing samples/docuemnts from Cloud Storage path to destination processor
res = import_documents(project, processor, location, gcs_path)
print(f"Waiting for {len(document_list)*1.5} seconds")
time.sleep(len(document_list) * 1.5)
else:
print("\tSkipping Dataset Migration actions like, exporting source dataset to Cloud Storage and importing dataset to destination processor")
# Checking for source processor version, if id provided then it will be imported to destination processor
if source_processor_version_to_import != "":
print(f"Importing Processor Version {source_processor_version_to_import}")
source_version = f"projects/{source_project_id}/locations/{source_location}/processors/{source_processor_id}/processorVersions/{source_processor_version_to_import}"
destination_version = f"projects/{destination_project_id}/locations/{destination_location}/processors/{destination_processor_id}"
# source_version = f"projects/{source_project_id}/locations/us/processors/a82fc086440d7ea1/processorVersions/f1eeed93aad5e317" # Data for testing
# Importing processor version from source processor to destanation processor
operation = import_processor_version(source_version, destination_version)
name = operation.metadata.common_metadata.resource
destination_processor_version_id = name.split("/")[-1]
# deploying newly imported processor version and set it as default version in desination project
deploy_and_set_default_processor_version(
destination_project_id,
destination_location,
destination_processor_id,
destination_processor_version_id,
)
main(destination_processor_id, migrate_dataset)
print("Process Completed!!!")
ステップ 6: 出力の詳細を確認する
移行先のプロジェクトに移動し、プロセッサの作成、データセットの可用性、新しいプロセッサ バージョンがデフォルト バージョンになっていることを確認します。