泛化是一种获取可区分值并将其抽象为较普通、较不易区分的值的过程。泛化的目的是保留数据效用,同时降低数据的可标识性。
存在许多级别的泛化,具体取决于数据类型。您可以使用敏感数据保护风险分析中包含的技术,在数据集或实际人口中进行测量,了解需要多大程度的泛化。
敏感数据保护支持的一种常见泛化技术是分桶。通过分桶,您可以将记录分组到较小的存储分区中,以尽量降低攻击者将敏感信息与标识性信息相关联的风险。这样做可以保留含义和效用,但也会模糊参与者太少的个体值。
分桶场景 1
请考虑此数值分桶场景:数据库存储用户满意度分数,范围从 0 到 100。该数据库如下所示:
| user_id | 得分 |
|---|---|
| 1 | 100 |
| 2 | 100 |
| 3 | 92 |
| ... | ... |
扫描数据后,您会发现某些值很少被用户使用。 事实上,有一些分数只映射到一个用户。例如,大多数用户选择 0、25、50、75 或 100。但是,有五个用户选择了 95,只有一个用户选择了 92。您可以将这些值泛化到多个组中,并消除任何参与者太少的组,而不是保留原始数据。以这种方式泛化数据有助于防止重标识,具体取决于数据的使用方式。
您可以选择移除这些离群数据行,也可以尝试使用分桶保留其效用。在此示例中,我们根据以下项对所有值进行分桶:
- 0-25:“低”
- 26-75:“中”
- 76-100:“高”
敏感数据保护中的分桶是可用于去标识化的众多原初转换之一。以下 JSON 配置说明了如何在 DLP API 中实现此分桶场景。此 JSON 可以包含在对 content.deidentify 方法的请求中:
C#
如需了解如何安装和使用用于敏感数据保护的客户端库,请参阅敏感数据保护客户端库。
如需向敏感数据保护服务进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
using System;
using Google.Api.Gax.ResourceNames;
using Google.Cloud.Dlp.V2;
public class DeidentifyTableWithPrimitiveBucketing
{
public static Table DeidentifyData(
string projectId,
Table tableToInspect = null)
{
// Instantiate dlp client.
var dlp = DlpServiceClient.Create();
// Construct the table if null.
if (tableToInspect == null)
{
var row1 = new Value[]
{
new Value { IntegerValue = 1 },
new Value { IntegerValue = 95 }
};
var row2 = new Value[]
{
new Value { IntegerValue = 2 },
new Value { IntegerValue = 61 }
};
var row3 = new Value[]
{
new Value { IntegerValue = 3 },
new Value { IntegerValue = 22 }
};
tableToInspect = new Table
{
Headers =
{
new FieldId { Name = "user_id" },
new FieldId { Name = "score" }
},
Rows =
{
new Table.Types.Row { Values = { row1 } },
new Table.Types.Row { Values = { row2 } },
new Table.Types.Row { Values = { row3 } }
}
};
}
// Specify the table and construct the content item.
var contentItem = new ContentItem { Table = tableToInspect };
// Specify how the content should be de-identified.
var bucketingConfig = new BucketingConfig
{
Buckets =
{
new BucketingConfig.Types.Bucket
{
Min = new Value { IntegerValue = 0 },
Max = new Value { IntegerValue = 25 },
ReplacementValue = new Value { StringValue = "Low" }
},
new BucketingConfig.Types.Bucket
{
Min = new Value { IntegerValue = 25 },
Max = new Value { IntegerValue = 75 },
ReplacementValue = new Value { StringValue = "Medium" }
},
new BucketingConfig.Types.Bucket
{
Min = new Value { IntegerValue = 75 },
Max = new Value { IntegerValue = 100 },
ReplacementValue = new Value { StringValue = "High" }
}
}
};
// Specify the fields to be encrypted.
var fields = new FieldId[] { new FieldId { Name = "score" } };
// Associate the de-identification with the specified field.
var fieldTransformation = new FieldTransformation
{
PrimitiveTransformation = new PrimitiveTransformation
{
BucketingConfig = bucketingConfig
},
Fields = { fields }
};
// Construct the de-identify config.
var deidentifyConfig = new DeidentifyConfig
{
RecordTransformations = new RecordTransformations
{
FieldTransformations = { fieldTransformation }
}
};
// Construct the request.
var request = new DeidentifyContentRequest
{
ParentAsLocationName = new LocationName(projectId, "global"),
DeidentifyConfig = deidentifyConfig,
Item = contentItem,
};
// Call the API.
DeidentifyContentResponse response = dlp.DeidentifyContent(request);
// Inspect the response.
Console.WriteLine(response.Item.Table);
return response.Item.Table;
}
}
Go
如需了解如何安装和使用用于敏感数据保护的客户端库,请参阅敏感数据保护客户端库。
如需向敏感数据保护服务进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
import (
"context"
"fmt"
"io"
dlp "cloud.google.com/go/dlp/apiv2"
"cloud.google.com/go/dlp/apiv2/dlppb"
)
// deIdentifyTablePrimitiveBucketing bucket sensitive data by grouping numerical values into
// predefined ranges to generalize and protect user information.
func deIdentifyTablePrimitiveBucketing(w io.Writer, projectID string) error {
// projectId := "your-project-id"
row1 := &dlppb.Table_Row{
Values: []*dlppb.Value{
{Type: &dlppb.Value_StringValue{StringValue: "22"}},
{Type: &dlppb.Value_StringValue{StringValue: "Jane Austen"}},
{Type: &dlppb.Value_StringValue{StringValue: "21"}},
},
}
row2 := &dlppb.Table_Row{
Values: []*dlppb.Value{
{Type: &dlppb.Value_StringValue{StringValue: "101"}},
{Type: &dlppb.Value_StringValue{StringValue: "Charles Dickens"}},
{Type: &dlppb.Value_StringValue{StringValue: "95"}},
},
}
row3 := &dlppb.Table_Row{
Values: []*dlppb.Value{
{Type: &dlppb.Value_StringValue{StringValue: "55"}},
{Type: &dlppb.Value_StringValue{StringValue: "Mark Twain"}},
{Type: &dlppb.Value_StringValue{StringValue: "75"}},
},
}
tableToDeidentify := &dlppb.Table{
Headers: []*dlppb.FieldId{
{Name: "AGE"},
{Name: "PATIENT"},
{Name: "HAPPINESS SCORE"},
},
Rows: []*dlppb.Table_Row{
{Values: row1.Values},
{Values: row2.Values},
{Values: row3.Values},
},
}
ctx := context.Background()
// Initialize a client once and reuse it to send multiple requests. Clients
// are safe to use across goroutines. When the client is no longer needed,
// call the Close method to cleanup its resources.
client, err := dlp.NewClient(ctx)
if err != nil {
return err
}
// Closing the client safely cleans up background resources.
defer client.Close()
// Specify what content you want the service to de-identify.
contentItem := &dlppb.ContentItem{
DataItem: &dlppb.ContentItem_Table{
Table: tableToDeidentify,
},
}
// Specify how the content should be de-identified.
buckets := []*dlppb.BucketingConfig_Bucket{
{
Min: &dlppb.Value{
Type: &dlppb.Value_IntegerValue{
IntegerValue: 0,
},
},
Max: &dlppb.Value{
Type: &dlppb.Value_IntegerValue{
IntegerValue: 25,
},
},
ReplacementValue: &dlppb.Value{
Type: &dlppb.Value_StringValue{
StringValue: "low",
},
},
},
{
Min: &dlppb.Value{
Type: &dlppb.Value_IntegerValue{
IntegerValue: 25,
},
},
Max: &dlppb.Value{
Type: &dlppb.Value_IntegerValue{
IntegerValue: 75,
},
},
ReplacementValue: &dlppb.Value{
Type: &dlppb.Value_StringValue{
StringValue: "Medium",
},
},
},
{
Min: &dlppb.Value{
Type: &dlppb.Value_IntegerValue{
IntegerValue: 75,
},
},
Max: &dlppb.Value{
Type: &dlppb.Value_IntegerValue{
IntegerValue: 100,
},
},
ReplacementValue: &dlppb.Value{
Type: &dlppb.Value_StringValue{
StringValue: "High",
},
},
},
}
// Specify the BucketingConfig in primitive transformation.
primitiveTransformation := &dlppb.PrimitiveTransformation_BucketingConfig{
BucketingConfig: &dlppb.BucketingConfig{
Buckets: buckets,
},
}
// Specify the field of the table to be de-identified
feildId := &dlppb.FieldId{
Name: "HAPPINESS SCORE",
}
// Specify the field transformation which apply to input field(s) on which you want to transform.
fieldTransformation := &dlppb.FieldTransformation{
Transformation: &dlppb.FieldTransformation_PrimitiveTransformation{
PrimitiveTransformation: &dlppb.PrimitiveTransformation{
Transformation: primitiveTransformation,
},
},
Fields: []*dlppb.FieldId{
feildId,
},
}
// Specify the record transformation to transform the record by applying various field transformations
transformation := &dlppb.RecordTransformations{
FieldTransformations: []*dlppb.FieldTransformation{
fieldTransformation,
},
}
// Specify the deidentification config.
deidentifyConfig := &dlppb.DeidentifyConfig{
Transformation: &dlppb.DeidentifyConfig_RecordTransformations{
RecordTransformations: transformation,
},
}
// Construct the de-identification request to be sent by the client.
req := &dlppb.DeidentifyContentRequest{
Parent: fmt.Sprintf("projects/%s/locations/global", projectID),
DeidentifyConfig: deidentifyConfig,
Item: contentItem,
}
// Send the request.
resp, err := client.DeidentifyContent(ctx, req)
if err != nil {
return err
}
// Print the results.
fmt.Fprintf(w, "Table after de-identification : %v", resp.GetItem().GetTable())
return nil
}
Java
如需了解如何安装和使用用于敏感数据保护的客户端库,请参阅敏感数据保护客户端库。
如需向敏感数据保护服务进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
import com.google.cloud.dlp.v2.DlpServiceClient;
import com.google.privacy.dlp.v2.BucketingConfig;
import com.google.privacy.dlp.v2.ContentItem;
import com.google.privacy.dlp.v2.DeidentifyConfig;
import com.google.privacy.dlp.v2.DeidentifyContentRequest;
import com.google.privacy.dlp.v2.DeidentifyContentResponse;
import com.google.privacy.dlp.v2.FieldId;
import com.google.privacy.dlp.v2.FieldTransformation;
import com.google.privacy.dlp.v2.LocationName;
import com.google.privacy.dlp.v2.PrimitiveTransformation;
import com.google.privacy.dlp.v2.RecordTransformations;
import com.google.privacy.dlp.v2.Table;
import com.google.privacy.dlp.v2.Value;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class DeIdentifyTableWithBucketingConfig {
public static void main(String[] args) throws Exception {
// TODO(developer): Replace these variables before running the sample.
// The Google Cloud project id to use as a parent resource.
String projectId = "your-project-id";
// Specify the table to be considered for de-identification.
Table tableToDeIdentify =
Table.newBuilder()
.addHeaders(FieldId.newBuilder().setName("AGE").build())
.addHeaders(FieldId.newBuilder().setName("PATIENT").build())
.addHeaders(FieldId.newBuilder().setName("HAPPINESS SCORE").build())
.addRows(
Table.Row.newBuilder()
.addValues(Value.newBuilder().setStringValue("101").build())
.addValues(Value.newBuilder().setStringValue("Charles Dickens").build())
.addValues(Value.newBuilder().setIntegerValue(95).build())
.build())
.addRows(
Table.Row.newBuilder()
.addValues(Value.newBuilder().setStringValue("22").build())
.addValues(Value.newBuilder().setStringValue("Jane Austen").build())
.addValues(Value.newBuilder().setIntegerValue(21).build())
.build())
.addRows(
Table.Row.newBuilder()
.addValues(Value.newBuilder().setStringValue("55").build())
.addValues(Value.newBuilder().setStringValue("Mark Twain").build())
.addValues(Value.newBuilder().setIntegerValue(75).build())
.build())
.build();
deIdentifyTableBucketing(projectId, tableToDeIdentify);
}
// Performs data de-identification on a table by replacing the values within each bucket with
// predefined replacement values.
public static Table deIdentifyTableBucketing(String projectId, Table tableToDeIdentify)
throws IOException {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests. After completing all of your requests, call
// the "close" method on the client to safely clean up any remaining background resources.
try (DlpServiceClient dlp = DlpServiceClient.create()) {
// Specify what content you want the service to de-identify.
ContentItem contentItem = ContentItem.newBuilder().setTable(tableToDeIdentify).build();
List<BucketingConfig.Bucket> buckets = new ArrayList<>();
buckets.add(
BucketingConfig.Bucket.newBuilder()
.setMin(Value.newBuilder().setIntegerValue(0).build())
.setMax(Value.newBuilder().setIntegerValue(25).build())
.setReplacementValue(Value.newBuilder().setStringValue("low").build())
.build());
buckets.add(
BucketingConfig.Bucket.newBuilder()
.setMin(Value.newBuilder().setIntegerValue(25).build())
.setMax(Value.newBuilder().setIntegerValue(75).build())
.setReplacementValue(Value.newBuilder().setStringValue("Medium").build())
.build());
buckets.add(
BucketingConfig.Bucket.newBuilder()
.setMin(Value.newBuilder().setIntegerValue(75).build())
.setMax(Value.newBuilder().setIntegerValue(100).build())
.setReplacementValue(Value.newBuilder().setStringValue("High").build())
.build());
BucketingConfig bucketingConfig = BucketingConfig.newBuilder().addAllBuckets(buckets).build();
PrimitiveTransformation primitiveTransformation =
PrimitiveTransformation.newBuilder().setBucketingConfig(bucketingConfig).build();
// Specify the field of the table to be de-identified.
FieldId fieldId = FieldId.newBuilder().setName("HAPPINESS SCORE").build();
FieldTransformation fieldTransformation =
FieldTransformation.newBuilder()
.setPrimitiveTransformation(primitiveTransformation)
.addFields(fieldId)
.build();
RecordTransformations transformations =
RecordTransformations.newBuilder().addFieldTransformations(fieldTransformation).build();
DeidentifyConfig deidentifyConfig =
DeidentifyConfig.newBuilder().setRecordTransformations(transformations).build();
// Combine configurations into a request for the service.
DeidentifyContentRequest request =
DeidentifyContentRequest.newBuilder()
.setParent(LocationName.of(projectId, "global").toString())
.setItem(contentItem)
.setDeidentifyConfig(deidentifyConfig)
.build();
// Send the request and receive response from the service.
DeidentifyContentResponse response = dlp.deidentifyContent(request);
// Print the results.
System.out.println("Table after de-identification: " + response.getItem().getTable());
return response.getItem().getTable();
}
}
}Node.js
如需了解如何安装和使用用于敏感数据保护的客户端库,请参阅敏感数据保护客户端库。
如需向敏感数据保护服务进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
// Imports the Google Cloud client library
const DLP = require('@google-cloud/dlp');
// Instantiates a client
const dlp = new DLP.DlpServiceClient();
// The project ID to run the API call under
// const projectId = 'your-project-id';
// Construct the tabular data
const tablularData = {
headers: [{name: 'AGE'}, {name: 'PATIENT'}, {name: 'HAPPINESS SCORE'}],
rows: [
{
values: [
{stringValue: '101'},
{stringValue: 'Charles Dickens'},
{integerValue: 95},
],
},
{
values: [
{stringValue: '22'},
{stringValue: 'Jane Austen'},
{integerValue: 21},
],
},
{
values: [
{stringValue: '55'},
{stringValue: 'Mark Twain'},
{integerValue: 75},
],
},
],
};
async function deIdentifyTableBucketing() {
// Construct bucket confiugrations
const buckets = [
{
min: {integerValue: 0},
max: {integerValue: 25},
replacementValue: {stringValue: 'Low'},
},
{
min: {integerValue: 25},
max: {integerValue: 75},
replacementValue: {stringValue: 'Medium'},
},
{
min: {integerValue: 75},
max: {integerValue: 100},
replacementValue: {stringValue: 'High'},
},
];
const bucketingConfig = {
buckets: buckets,
};
// The list of fields to be transformed.
const fieldIds = [{name: 'HAPPINESS SCORE'}];
// Associate fields with bucketing configuration.
const fieldTransformations = [
{
primitiveTransformation: {bucketingConfig: bucketingConfig},
fields: fieldIds,
},
];
// Specify de-identify configuration using transformation object.
const deidentifyConfig = {
recordTransformations: {
fieldTransformations: fieldTransformations,
},
};
// Combine configurations into a request for the service.
const request = {
parent: `projects/${projectId}/locations/global`,
deidentifyConfig: deidentifyConfig,
item: {
table: tablularData,
},
};
// Send the request and receive response from the service.
const [response] = await dlp.deidentifyContent(request);
// Print the results.
console.log(
`Table after de-identification: ${JSON.stringify(
response.item.table,
null,
2
)}`
);
}
deIdentifyTableBucketing();PHP
如需了解如何安装和使用用于敏感数据保护的客户端库,请参阅敏感数据保护客户端库。
如需向敏感数据保护服务进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
use Google\Cloud\Dlp\V2\BucketingConfig;
use Google\Cloud\Dlp\V2\BucketingConfig\Bucket;
use Google\Cloud\Dlp\V2\Client\DlpServiceClient;
use Google\Cloud\Dlp\V2\ContentItem;
use Google\Cloud\Dlp\V2\DeidentifyConfig;
use Google\Cloud\Dlp\V2\DeidentifyContentRequest;
use Google\Cloud\Dlp\V2\FieldId;
use Google\Cloud\Dlp\V2\FieldTransformation;
use Google\Cloud\Dlp\V2\PrimitiveTransformation;
use Google\Cloud\Dlp\V2\RecordTransformations;
use Google\Cloud\Dlp\V2\Table;
use Google\Cloud\Dlp\V2\Table\Row;
use Google\Cloud\Dlp\V2\Value;
/**
* De-identify data using primitive bucketing.
* https://cloud.google.com/dlp/docs/concepts-bucketing#bucketing_scenario_1
*
* @param string $callingProjectId The Google Cloud project id to use as a parent resource.
* @param string $inputCsvFile The input file(csv) path to deidentify.
* @param string $outputCsvFile The oupt file path to save deidentify content.
*
*/
function deidentify_table_primitive_bucketing(
// TODO(developer): Replace sample parameters before running the code.
string $callingProjectId,
string $inputCsvFile = './test/data/table4.csv',
string $outputCsvFile = './test/data/deidentify_table_primitive_bucketing_output.csv'
): void {
// Instantiate a client.
$dlp = new DlpServiceClient();
// Read a CSV file.
$csvLines = file($inputCsvFile, FILE_IGNORE_NEW_LINES);
$csvHeaders = explode(',', $csvLines[0]);
$csvRows = array_slice($csvLines, 1);
// Convert CSV file into protobuf objects.
$tableHeaders = array_map(function ($csvHeader) {
return (new FieldId)->setName($csvHeader);
}, $csvHeaders);
$tableRows = array_map(function ($csvRow) {
$rowValues = array_map(function ($csvValue) {
return (new Value())
->setStringValue($csvValue);
}, explode(',', $csvRow));
return (new Row())
->setValues($rowValues);
}, $csvRows);
// Construct the table object.
$tableToDeIdentify = (new Table())
->setHeaders($tableHeaders)
->setRows($tableRows);
// Specify what content you want the service to de-identify.
$contentItem = (new ContentItem())
->setTable($tableToDeIdentify);
// Specify how the content should be de-identified.
$buckets = [
(new Bucket())
->setMin((new Value())
->setIntegerValue(0))
->setMax((new Value())
->setIntegerValue(25))
->setReplacementValue((new Value())
->setStringValue('LOW')),
(new Bucket())
->setMin((new Value())
->setIntegerValue(25))
->setMax((new Value())
->setIntegerValue(75))
->setReplacementValue((new Value())
->setStringValue('Medium')),
(new Bucket())
->setMin((new Value())
->setIntegerValue(75))
->setMax((new Value())
->setIntegerValue(100))
->setReplacementValue((new Value())
->setStringValue('High')),
];
$bucketingConfig = (new BucketingConfig())
->setBuckets($buckets);
$primitiveTransformation = (new PrimitiveTransformation())
->setBucketingConfig($bucketingConfig);
// Specify the field of the table to be de-identified.
$fieldId = (new FieldId())
->setName('score');
$fieldTransformation = (new FieldTransformation())
->setPrimitiveTransformation($primitiveTransformation)
->setFields([$fieldId]);
$recordTransformations = (new RecordTransformations())
->setFieldTransformations([$fieldTransformation]);
// Create the deidentification configuration object.
$deidentifyConfig = (new DeidentifyConfig())
->setRecordTransformations($recordTransformations);
$parent = "projects/$callingProjectId/locations/global";
// Send the request and receive response from the service.
$deidentifyContentRequest = (new DeidentifyContentRequest())
->setParent($parent)
->setDeidentifyConfig($deidentifyConfig)
->setItem($contentItem);
$response = $dlp->deidentifyContent($deidentifyContentRequest);
// Print the results.
$csvRef = fopen($outputCsvFile, 'w');
fputcsv($csvRef, $csvHeaders);
foreach ($response->getItem()->getTable()->getRows() as $tableRow) {
$values = array_map(function ($tableValue) {
return $tableValue->getStringValue();
}, iterator_to_array($tableRow->getValues()));
fputcsv($csvRef, $values);
};
printf('Table after deidentify (File Location): %s', $outputCsvFile);
}Python
如需了解如何安装和使用用于敏感数据保护的客户端库,请参阅敏感数据保护客户端库。
如需向敏感数据保护服务进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为本地开发环境设置身份验证。
import google.cloud.dlp
def deidentify_table_primitive_bucketing(
project: str,
) -> None:
"""Uses the Data Loss Prevention API to de-identify sensitive data in
a table by replacing them with generalized bucket labels.
Args:
project: The Google Cloud project id to use as a parent resource.
"""
# Instantiate a client.
dlp = google.cloud.dlp_v2.DlpServiceClient()
# Convert the project id into a full resource id.
parent = f"projects/{project}/locations/global"
# Dictionary representing table to de-identify.
# The table can also be taken as input to the function.
table_to_deid = {
"header": ["age", "patient", "happiness_score"],
"rows": [
["101", "Charles Dickens", "95"],
["22", "Jane Austen", "21"],
["90", "Mark Twain", "75"],
],
}
# Construct the `table`. For more details on the table schema, please see
# https://cloud.google.com/dlp/docs/reference/rest/v2/ContentItem#Table
headers = [{"name": val} for val in table_to_deid["header"]]
rows = []
for row in table_to_deid["rows"]:
rows.append({"values": [{"string_value": cell_val} for cell_val in row]})
table = {"headers": headers, "rows": rows}
# Construct the `item` for table to de-identify.
item = {"table": table}
# Construct generalised bucket configuration.
buckets_config = [
{
"min_": {"integer_value": 0},
"max_": {"integer_value": 25},
"replacement_value": {"string_value": "Low"},
},
{
"min_": {"integer_value": 25},
"max_": {"integer_value": 75},
"replacement_value": {"string_value": "Medium"},
},
{
"min_": {"integer_value": 75},
"max_": {"integer_value": 100},
"replacement_value": {"string_value": "High"},
},
]
# Construct de-identify configuration that groups values in a table field and replace those with bucket labels.
deidentify_config = {
"record_transformations": {
"field_transformations": [
{
"fields": [{"name": "happiness_score"}],
"primitive_transformation": {
"bucketing_config": {"buckets": buckets_config}
},
}
]
}
}
# Call the API to deidentify table data through primitive bucketing.
response = dlp.deidentify_content(
request={
"parent": parent,
"deidentify_config": deidentify_config,
"item": item,
}
)
# Print the results.
print(f"Table after de-identification: {response.item.table}")
REST
...
{
"primitiveTransformation":
{
"bucketingConfig":
{
"buckets":
[
{
"min":
{
"integerValue": "0"
},
"max":
{
"integerValue": "25"
},
"replacementValue":
{
"stringValue": "Low"
}
},
{
"min":
{
"integerValue": "26"
},
"max":
{
"integerValue": "75"
},
"replacementValue":
{
"stringValue": "Medium"
}
},
{
"min":
{
"integerValue": "76"
},
"max":
{
"integerValue": "100"
},
"replacementValue":
{
"stringValue": "High"
}
}
]
}
}
}
...
分桶场景 2
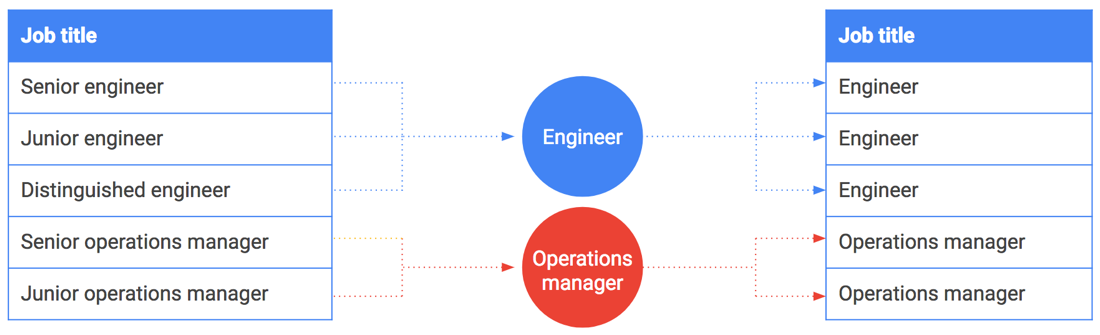
分桶也可用于字符串或枚举值。假设您想要分享薪资数据并包含职位。但是,某些职位(如 CEO 或杰出工程师)可以与一个人或一小群人联系起来。这些职位很容易与拥有这些职位的员工匹配。
分桶也可以用于这种情况。不要包括确切的职位,而是对它们进行泛化和分桶。例如,将“高级工程师”、“初级工程师”和“杰出工程师”泛化和分桶为“工程师”。下表说明了如何将特定职位分桶到职位系列中。
其他场景
在这些示例中,我们将对结构化数据应用转换。只要可以使用预定义或自定义的 infoType 对值进行分类,则分桶也可用于非结构化示例。以下是一些示例场景:
- 对日期进行分类并将其按年份分桶
- 对名称进行分类并根据首字母(A-M、N-Z)将其分桶到不同的组
资源
要详细了解泛化和分桶,请参阅对文本内容中的敏感数据进行去标识化。
如需 API 文档,请参阅:
projects.content.deidentify方法BucketingConfig转换:根据自定义范围对值进行分桶。FixedSizeBucketingConfig转换:根据固定大小范围对值进行分桶。