이 문서에서는 Apache Spark SQL 및 PySpark용 서버리스 일괄 워크로드를 실행하여 BigLake metastore에 저장된 메타데이터가 포함된 Apache Iceberg 테이블을 만드는 방법을 보여줍니다. Spark 코드를 실행하는 다른 방법에 대한 자세한 내용은 BigQuery 노트북에서 PySpark 코드 실행 및 Apache Spark 워크로드 실행을 참고하세요.
시작하기 전에
아직 만들지 않았다면 Google Cloud 프로젝트와 Cloud Storage 버킷을 만듭니다.
프로젝트 설정
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 프로젝트에 Cloud Storage 버킷을 만듭니다.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Compute Engine 기본 서비스 계정(
PROJECT_NUMBER-compute@developer.gserviceaccount.com)에 BigQuery 데이터 편집자(roles/bigquery.dataEditor) 역할을 부여합니다. 자세한 내용은 단일 역할 부여를 참고하세요.Google Cloud CLI 예시:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member PROJECT_NUMBER-compute@developer.gserviceaccount.com \ --role roles/bigquery.dataEditor
참고:
- PROJECT_ID 및 PROJECT_NUMBER는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
다음 Spark SQL 명령어를 로컬 또는 Cloud Shell에서
iceberg-table.sql파일에 복사합니다.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
다음을 바꿉니다.
- CATALOG_NAME: Iceberg 카탈로그 이름입니다.
- BUCKET 및 WAREHOUSE_FOLDER: Iceberg 웨어하우스 디렉터리로 사용되는 Cloud Storage 버킷 및 폴더입니다.
iceberg-table.sql이 포함된 디렉터리에서 로컬 또는 Cloud Shell에서 다음 명령어를 실행하여 Spark SQL 워크로드를 제출합니다.gcloud dataproc batches submit spark-sql iceberg-table.sql \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"
참고:
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- REGION: 워크로드를 실행하는 데 사용할 수 있는 Compute Engine 리전입니다.
- BUCKET_NAME: Cloud Storage 버킷 이름입니다. Spark는 일괄 워크로드를 실행하기 전에 이 버킷의
/dependencies폴더에 워크로드 종속 항목을 업로드합니다. WAREHOUSE_FOLDER는 이 버킷에 있습니다. --version: Apache Spark용 서버리스 런타임 버전 2.2 이상- SUBNET_NAME:
REGION의 VPC 서브넷 이름입니다. 이 플래그를 생략하면 Apache Spark용 서버리스가 세션 리전에서default서브넷을 선택합니다. Apache Spark용 서버리스는 서브넷에서 비공개 Google 액세스 (PGA)를 사용 설정합니다. 네트워크 연결 요구사항은 Google Cloud Apache Spark용 서버리스 네트워크 구성을 참고하세요. - LOCATION: 지원되는 BigQuery 위치입니다. 기본 위치는 'US'입니다.
--properties카탈로그 속성.
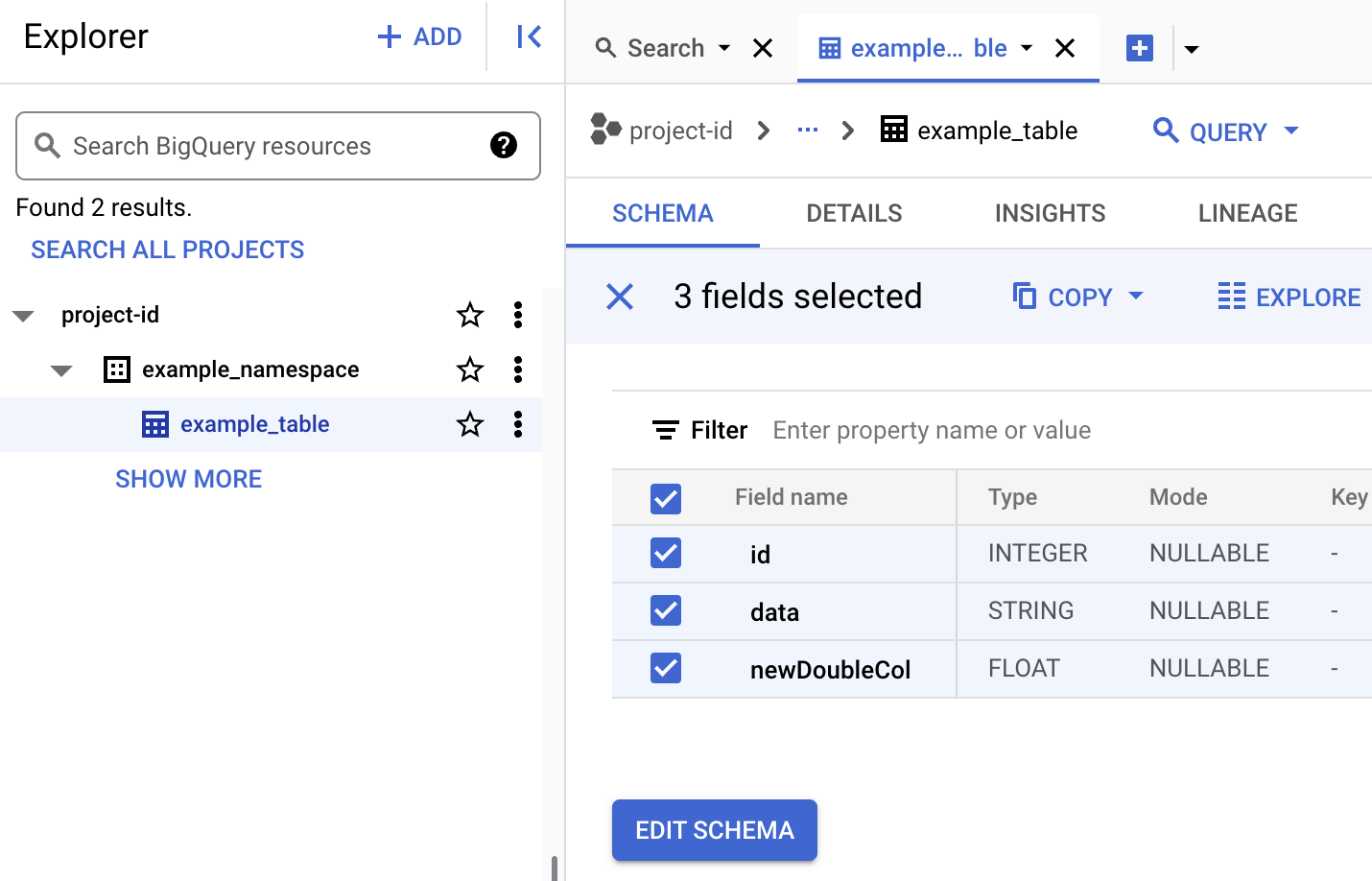
BigQuery에서 테이블 메타데이터를 확인합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
Iceberg 테이블 메타데이터를 확인합니다.
- 다음 PySpark 코드를 로컬 또는 Cloud Shell에서
iceberg-table.py파일에 복사합니다.from pyspark.sql import SparkSession spark = SparkSession.builder.appName("iceberg-table-example").getOrCreate() catalog = "CATALOG_NAME" namespace = "NAMESPACE" spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create table and display schema spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;") # Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');") # Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE example_iceberg_table;")
다음을 바꿉니다.
- CATALOG_NAME 및 NAMESPACE: Iceberg 카탈로그 이름과 네임스페이스가 결합되어 Iceberg 테이블 (
catalog.namespace.table_name)을 식별합니다.
- CATALOG_NAME 및 NAMESPACE: Iceberg 카탈로그 이름과 네임스페이스가 결합되어 Iceberg 테이블 (
-
iceberg-table.py가 포함된 디렉터리에서 로컬 또는 Cloud Shell에서 다음 명령어를 실행하여 PySpark 워크로드를 제출합니다.gcloud dataproc batches submit pyspark iceberg-table.py \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"참고:
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- REGION: 워크로드를 실행하는 데 사용할 수 있는 Compute Engine 리전입니다.
- BUCKET_NAME: Cloud Storage 버킷 이름입니다. Spark는 일괄 워크로드를 실행하기 전에 이 버킷의
/dependencies폴더에 워크로드 종속 항목을 업로드합니다. --version: Apache Spark용 서버리스 런타임 버전 2.2 이상- SUBNET_NAME:
REGION의 VPC 서브넷 이름입니다. 이 플래그를 생략하면 Apache Spark용 서버리스가 세션 리전에서default서브넷을 선택합니다. Apache Spark용 서버리스는 서브넷에서 비공개 Google 액세스 (PGA)를 사용 설정합니다. 네트워크 연결 요구사항은 Google Cloud Apache Spark용 서버리스 네트워크 구성을 참고하세요. - LOCATION: 지원되는 BigQuery 위치입니다. 기본 위치는 'US'입니다.
- BUCKET 및 WAREHOUSE_FOLDER: Iceberg 웨어하우스 디렉터리로 사용되는 Cloud Storage 버킷 및 폴더입니다.
--properties: 카탈로그 속성입니다.
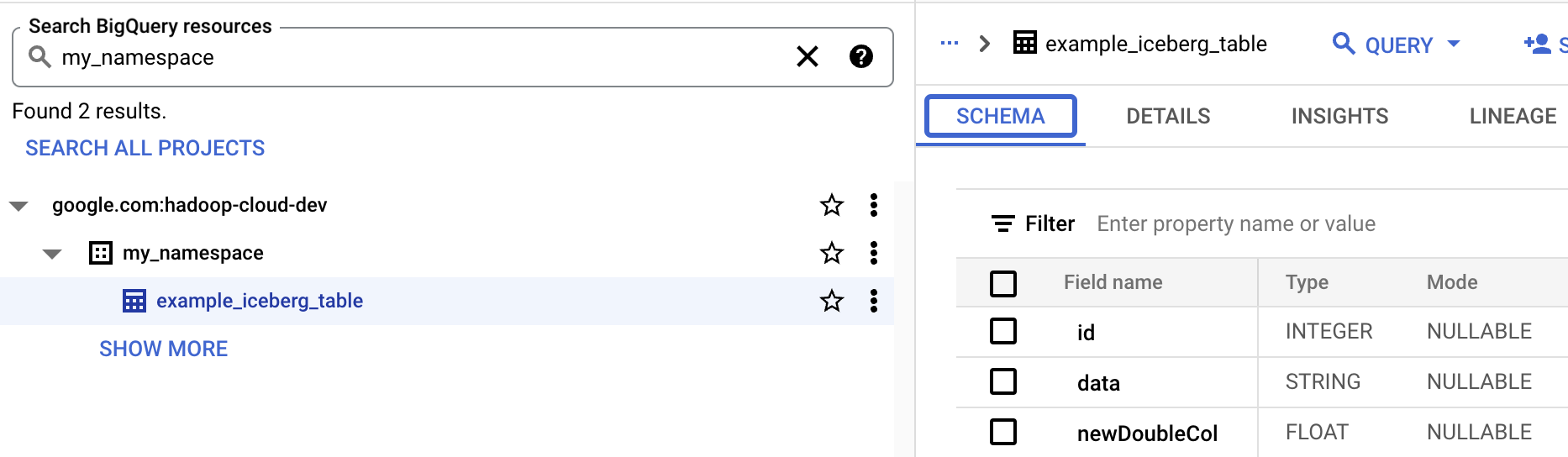
- BigQuery에서 테이블 스키마를 봅니다.
- Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다. BigQuery Studio로 이동합니다.
- Iceberg 테이블 메타데이터를 확인합니다.
OSS 리소스와 BigQuery 리소스 매핑
오픈소스 리소스와 BigQuery 리소스 용어 간의 다음 매핑을 참고하세요.
OSS 리소스 BigQuery 리소스 네임스페이스, 데이터베이스 데이터 세트 파티션을 나누거나 나누지 않은 테이블 테이블 뷰 뷰 Iceberg 테이블 만들기
이 섹션에서는 Apache Spark용 서버리스 Spark SQL 및 PySpark 일괄 워크로드를 사용하여 BigLake metastore에 메타데이터가 포함된 Iceberg 테이블을 만드는 방법을 보여줍니다.
Spark SQL
Spark SQL 워크로드를 실행하여 Iceberg 테이블 만들기
다음 단계에서는 Apache Spark용 서버리스 Spark SQL 일괄 워크로드를 실행하여 BigLake metastore에 저장된 테이블 메타데이터가 포함된 Iceberg 테이블을 만드는 방법을 보여줍니다.
PySpark
다음 단계에서는 Apache Spark용 서버리스 PySpark 일괄 워크로드를 실행하여 BigLake metastore에 저장된 테이블 메타데이터가 포함된 Iceberg 테이블을 만드는 방법을 보여줍니다.