Ce document vous explique comment exécuter des charges de travail par lot Serverless pour Apache Spark SQL et PySpark afin de créer une table Apache Iceberg avec des métadonnées stockées dans BigLake Metastore. Pour savoir comment exécuter du code Spark, consultez Exécuter du code PySpark dans un notebook BigQuery et Exécuter une charge de travail Apache Spark.
Avant de commencer
Si ce n'est pas déjà fait, créez un projet Google Cloud et un bucket Cloud Storage.
Configurer votre projet
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Créez un bucket Cloud Storage dans votre projet.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Attribuez le rôle Éditeur de données BigQuery (
roles/bigquery.dataEditor) au compte de service Compute Engine par défaut,PROJECT_NUMBER-compute@developer.gserviceaccount.com. Pour savoir comment procéder, consultez Attribuer un rôle unique.Exemple de Google Cloud CLI :
gcloud projects add-iam-policy-binding PROJECT_ID \ --member PROJECT_NUMBER-compute@developer.gserviceaccount.com \ --role roles/bigquery.dataEditor
Remarques :
- PROJECT_ID et PROJECT_NUMBER sont listés dans la section Informations sur le projet du tableau de bord de la console Google Cloud .
Copiez les commandes SparkSQL suivantes en local ou dans Cloud Shell dans un fichier
iceberg-table.sql.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
Remplacez les éléments suivants :
- CATALOG_NAME : nom du catalogue Iceberg.
- BUCKET et WAREHOUSE_FOLDER : bucket et dossier Cloud Storage utilisés comme répertoire d'entrepôt Iceberg.
Exécutez la commande suivante en local ou dans Cloud Shell à partir du répertoire contenant
iceberg-table.sqlpour envoyer la charge de travail SparkSQL.gcloud dataproc batches submit spark-sql iceberg-table.sql \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"
Remarques :
- PROJECT_ID : ID de votre projet Google Cloud . Les ID de projet sont listés dans la section Informations sur le projet du tableau de bord de la console Google Cloud .
- REGION : Région Compute Engine disponible pour exécuter la charge de travail.
- BUCKET_NAME : nom du bucket Cloud Storage. Spark importe les dépendances de la charge de travail dans un dossier
/dependenciesde ce bucket avant d'exécuter la charge de travail par lot. Le WAREHOUSE_FOLDER se trouve dans ce bucket. --version: version 2.2 ou ultérieure de l'environnement d'exécution Serverless pour Apache Spark.- SUBNET_NAME : nom d'un sous-réseau VPC dans
REGION. Si vous omettez cet indicateur, Serverless pour Apache Spark sélectionne le sous-réseaudefaultdans la région de la session. Serverless pour Apache Spark active l'accès privé à Google sur le sous-réseau. Pour connaître les exigences en matière de connectivité réseau, consultez Configuration du réseauGoogle Cloud Serverless pour Apache Spark. - LOCATION : emplacement BigQuery compatible. L'emplacement par défaut est "US".
--propertiesPropriétés du catalogue
Afficher les métadonnées de la table dans BigQuery
Dans la console Google Cloud , accédez à la page BigQuery.
Affichez les métadonnées d'une table Iceberg.
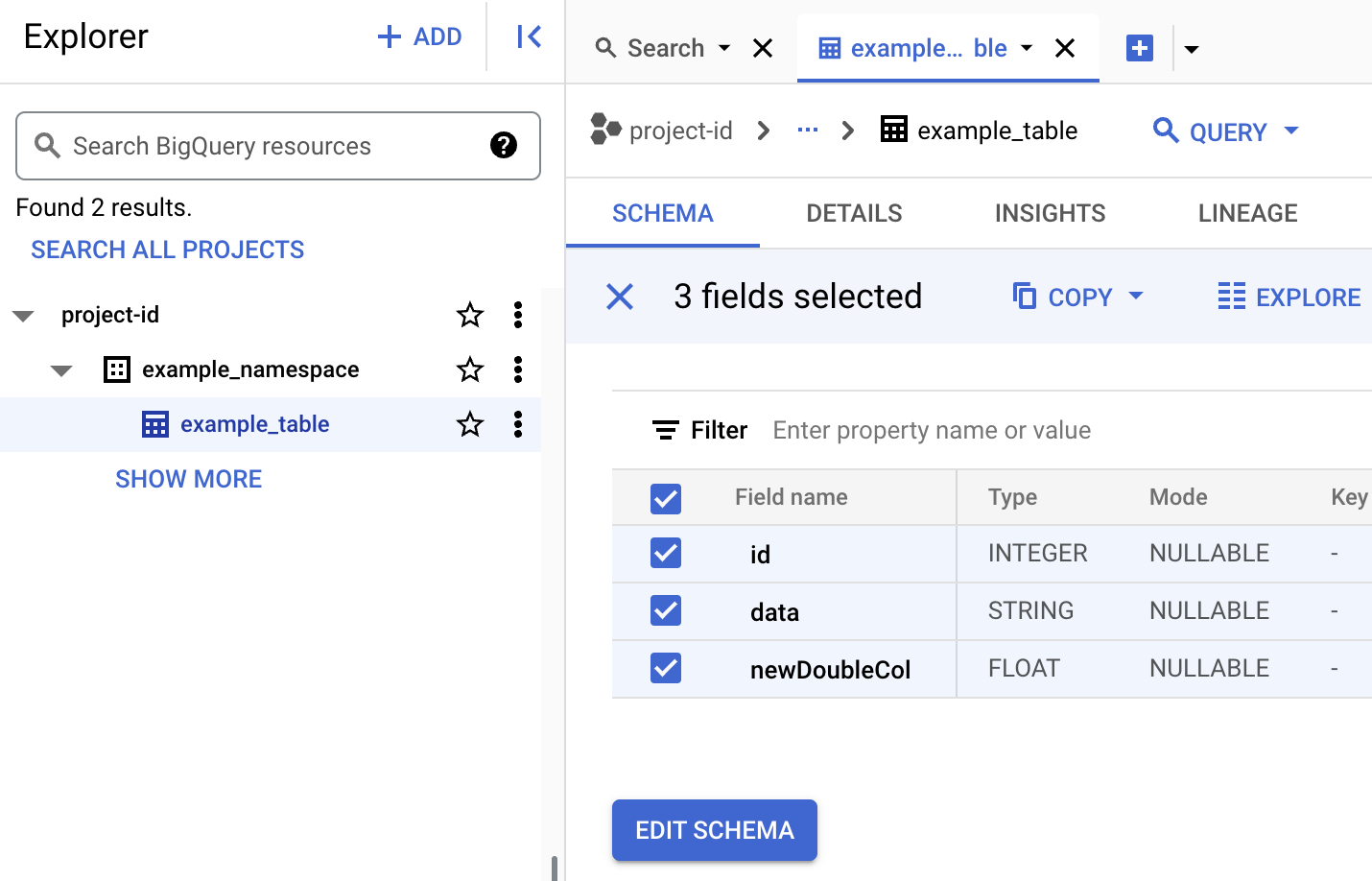
- Copiez le code PySpark suivant en local ou dans Cloud Shell dans un fichier
iceberg-table.py.from pyspark.sql import SparkSession spark = SparkSession.builder.appName("iceberg-table-example").getOrCreate() catalog = "CATALOG_NAME" namespace = "NAMESPACE" spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create table and display schema spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;") # Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');") # Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE example_iceberg_table;")
Remplacez les éléments suivants :
- CATALOG_NAME et NAMESPACE : le nom et l'espace de noms du catalogue Iceberg sont combinés pour identifier la table Iceberg (
catalog.namespace.table_name).
- CATALOG_NAME et NAMESPACE : le nom et l'espace de noms du catalogue Iceberg sont combinés pour identifier la table Iceberg (
-
Exécutez la commande suivante en local ou dans Cloud Shell à partir du répertoire contenant
iceberg-table.pypour envoyer la charge de travail PySpark.gcloud dataproc batches submit pyspark iceberg-table.py \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"Remarques :
- PROJECT_ID : ID de votre projet Google Cloud . Les ID de projet sont listés dans la section Informations sur le projet du tableau de bord de la console Google Cloud .
- REGION : Région Compute Engine disponible pour exécuter la charge de travail.
- BUCKET_NAME : nom du bucket Cloud Storage. Spark importe les dépendances de la charge de travail dans un dossier
/dependenciesde ce bucket avant d'exécuter la charge de travail par lot. --version: version 2.2 ou ultérieure de l'environnement d'exécution Serverless pour Apache Spark.- SUBNET_NAME : nom d'un sous-réseau VPC dans
REGION. Si vous omettez cet indicateur, Serverless pour Apache Spark sélectionne le sous-réseaudefaultdans la région de la session. Serverless pour Apache Spark active l'accès privé à Google sur le sous-réseau. Pour connaître les exigences de connectivité réseau, consultez Configuration du réseauGoogle Cloud Serverless pour Apache Spark. - LOCATION : emplacement BigQuery compatible. L'emplacement par défaut est "US".
- BUCKET et WAREHOUSE_FOLDER : bucket et dossier Cloud Storage utilisés comme répertoire de l'entrepôt Iceberg.
--properties: propriétés du catalogue.
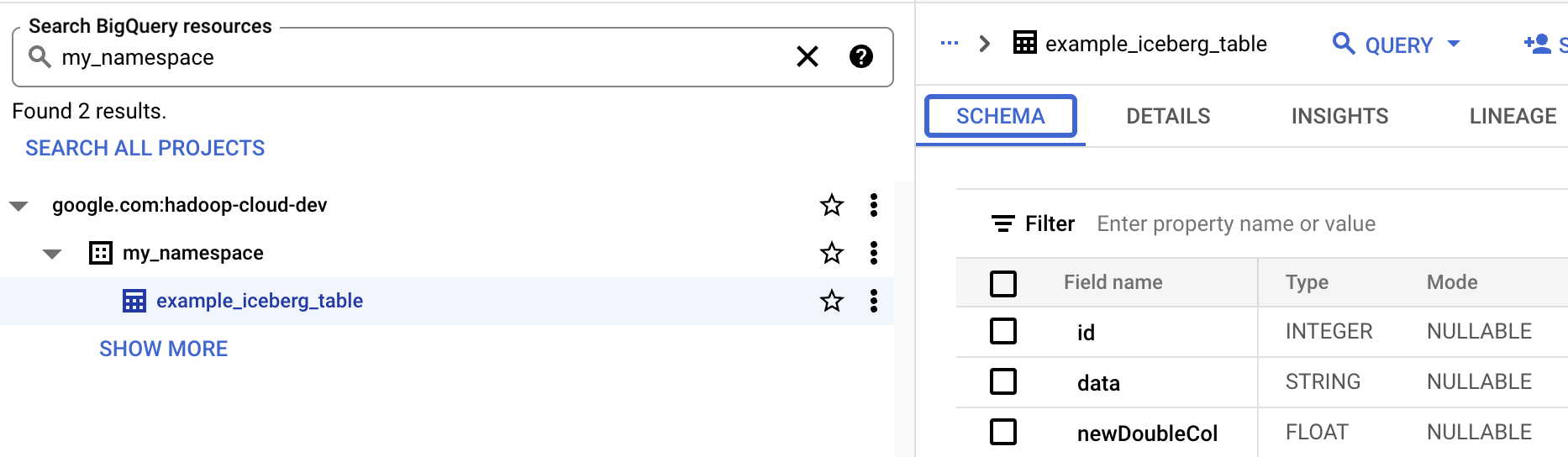
- Affichez le schéma de la table dans BigQuery.
- Dans la console Google Cloud , accédez à la page BigQuery. Accédez à BigQuery Studio.
- Affichez les métadonnées d'une table Iceberg.
Mappage des ressources OSS vers les ressources BigQuery
Notez le mappage suivant entre les termes de ressources Open Source et BigQuery :
Ressource OSS Ressource BigQuery Espace de noms, base de données Ensemble de données Table partitionnée ou non partitionnée Table Afficher Afficher Créer une table Iceberg
Cette section vous explique comment créer une table Iceberg avec des métadonnées dans le métastore BigLake à l'aide des charges de travail par lot SparkSQL et PySpark de Serverless pour Apache Spark.
Spark SQL
Exécuter une charge de travail Spark SQL pour créer une table Iceberg
Les étapes suivantes vous montrent comment exécuter une charge de travail par lot Spark SQL Serverless pour Apache Spark afin de créer une table Iceberg avec des métadonnées de table stockées dans BigLake Metastore.
PySpark
Les étapes suivantes vous montrent comment exécuter une charge de travail par lot PySpark Serverless pour Apache Spark afin de créer une table Iceberg avec des métadonnées de table stockées dans BigLake Metastore.