O
Neste documento, descrevemos como instalar e usar a extensão JupyterLab em uma máquina ou VM autogerenciada que tenha acesso aos Serviços do Google. Também descrevemos como desenvolver e implantar código de notebook do Spark sem servidor.
Instale a extensão em minutos para aproveitar os seguintes recursos:
- Inicie notebooks do Spark sem servidor e do BigQuery para desenvolver código rapidamente
- Procurar e visualizar conjuntos de dados do BigQuery no JupyterLab
- Editar arquivos do Cloud Storage no JupyterLab
- Programar um notebook no Composer
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init Faça o download e instale a versão 3.11 ou mais recente do Python em
python.org/downloads.- Verifique a instalação do Python 3.11 ou mais recente.
python3 --version
- Verifique a instalação do Python 3.11 ou mais recente.
Virtualize o ambiente Python.
pip3 install pipenv
- Crie uma pasta de instalação.
mkdir jupyter
- Mude para a pasta de instalação.
cd jupyter
- Crie um ambiente virtual.
pipenv shell
- Crie uma pasta de instalação.
Instale o JupyterLab no ambiente virtual.
pipenv install jupyterlab
Instale a extensão do JupyterLab.
pipenv install bigquery-jupyter-plugin
jupyter lab
A página Acesso rápido do JupyterLab é aberta no navegador. Ela contém uma seção Jobs e sessões do Dataproc. Ele também pode conter seções de Notebooks sem servidor para Apache Spark e Notebooks de cluster do Dataproc se você tiver acesso a notebooks sem servidor do Dataproc ou clusters do Dataproc com o componente opcional Jupyter em execução no seu projeto.
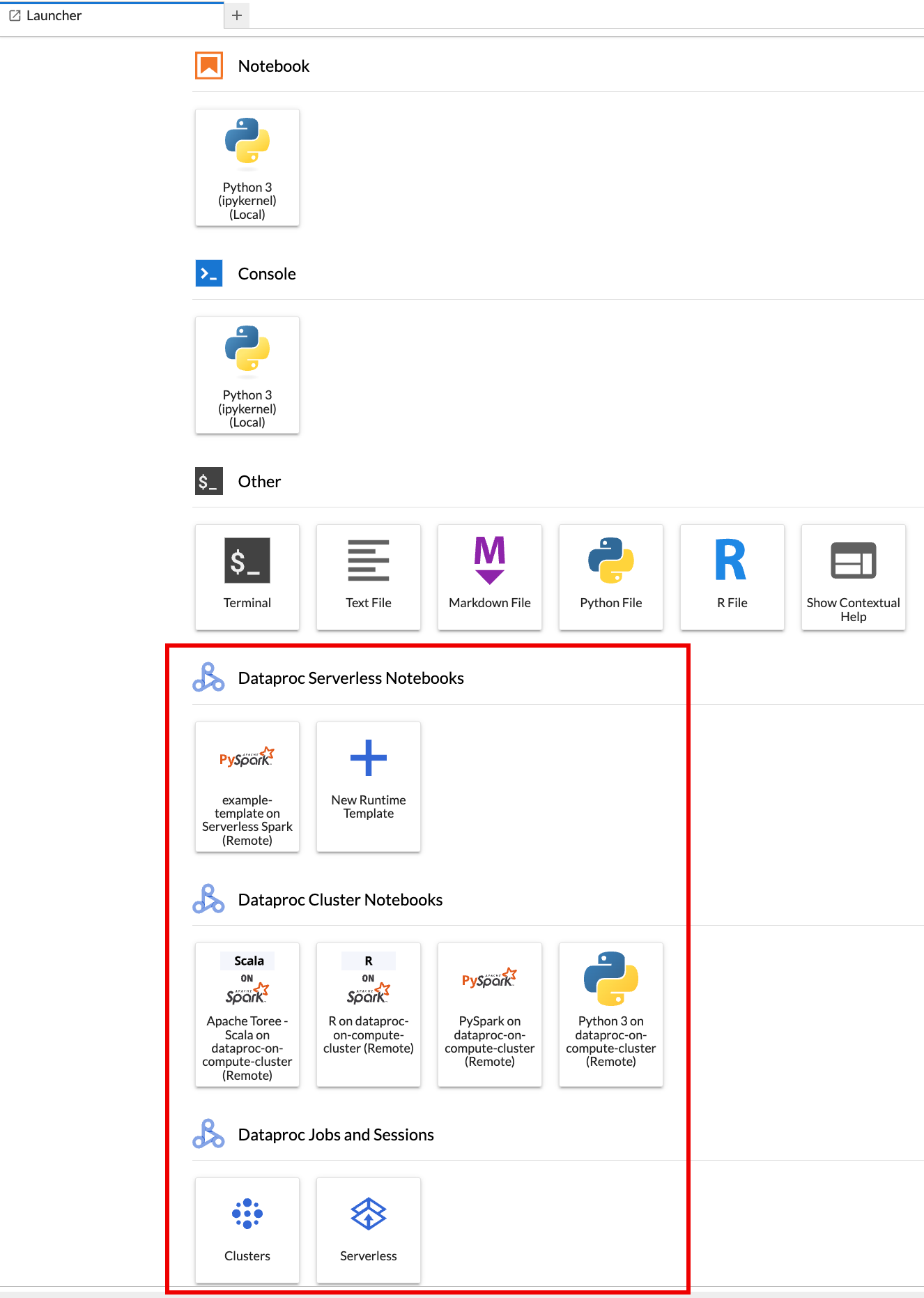
Por padrão, sua sessão interativa do Serverless para Apache Spark é executada no projeto e na região definidos quando você executou
gcloud initem Antes de começar. É possível mudar as configurações de projeto e região das sessões em JupyterLab Configurações > Google Cloud Configurações > Google Cloud Configurações do projeto.É necessário reiniciar a extensão para que as mudanças entrem em vigor.
Clique no card
New runtime templatena seção Notebooks sem servidor para Apache Spark da página Acesso rápido do JupyterLab.
Preencha o formulário Modelo de ambiente de execução.
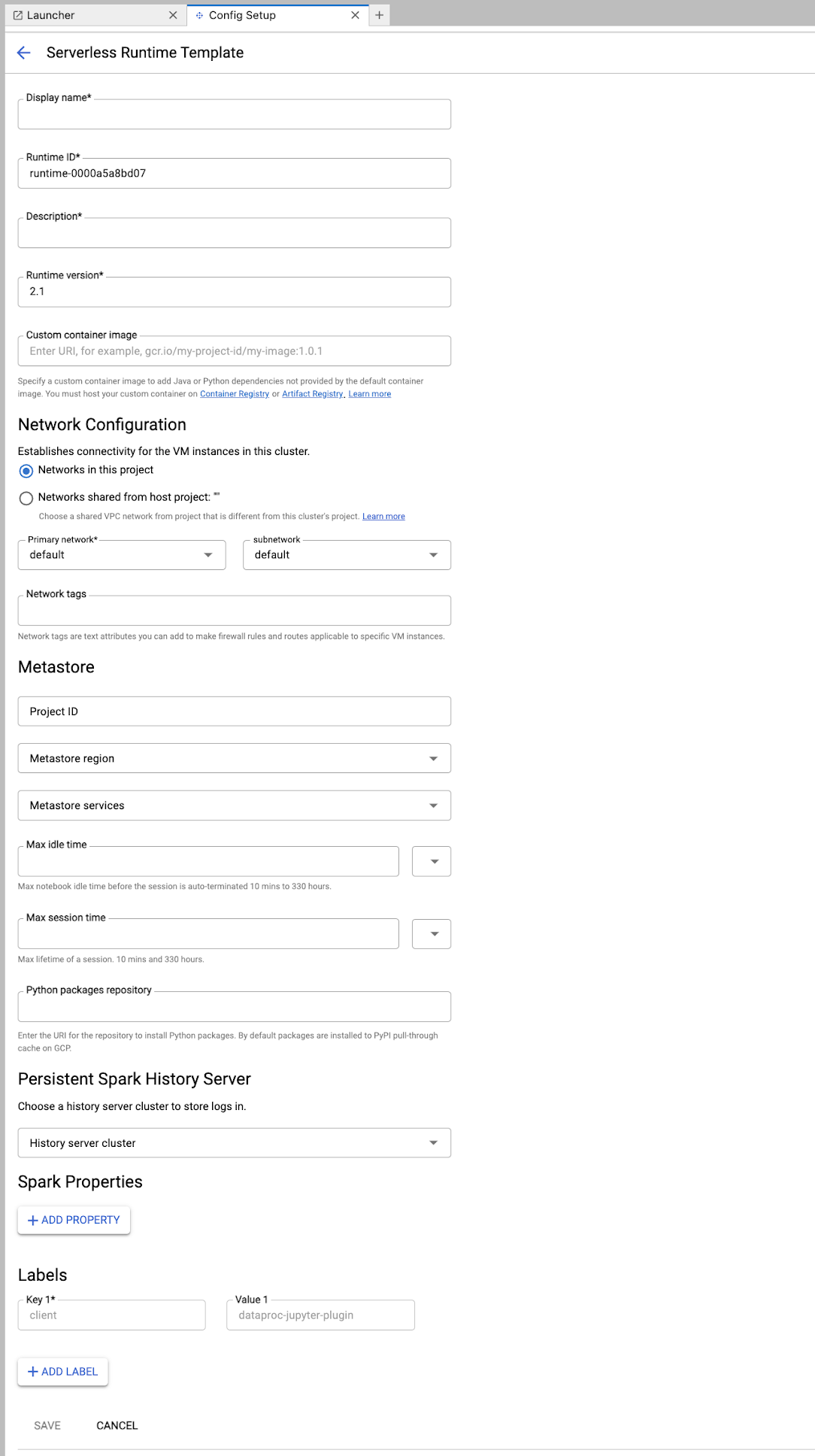
Informações do modelo:
- Nome de exibição, ID do ambiente de execução e Descrição: aceite ou preencha um nome de exibição, um ID do ambiente de execução e uma descrição do modelo.
Configuração de execução: selecione Conta de usuário para executar notebooks com a identidade do usuário em vez da identidade da conta de serviço do Dataproc.
- Conta de serviço: se você não especificar uma conta de serviço, a conta de serviço padrão do Compute Engine será usada.
- Versão do ambiente de execução: confirme ou selecione a versão do ambiente de execução.
- Imagem de contêiner personalizada: especifique opcionalmente o URI de uma imagem de contêiner personalizada.
- Bucket de staging: é possível especificar o nome de um bucket de staging do Cloud Storage para uso pelo Serverless para Apache Spark.
- Repositório de pacotes Python: por padrão, os pacotes Python são baixados e instalados do cache de pull-through do PyPI quando os usuários executam comandos de instalação
pipnos notebooks. É possível especificar o repositório de artefatos particulares da sua organização para pacotes Python como o repositório padrão de pacotes Python.
Criptografia: aceite o Google-owned and Google-managed encryption key padrão ou selecione Chave de criptografia gerenciada pelo cliente (CMEK). Se for CMEK, selecione ou forneça as informações da chave.
Configuração de rede: selecione uma sub-rede no projeto ou compartilhada de um projeto host. É possível mudar o projeto em JupyterLab Configurações > Google Cloud Configurações > Google Cloud Configurações do projeto. É possível especificar tags de rede para aplicar à rede especificada. O Serverless para Apache Spark ativa o Acesso privado do Google (PGA) na sub-rede especificada. Para requisitos de conectividade de rede, consulte Google Cloud Configuração de rede do Serverless para Apache Spark.
Configuração da sessão: você pode preencher esses campos para limitar a duração das sessões criadas com o modelo.
- Tempo máximo de inatividade:o tempo máximo de inatividade antes que a sessão seja encerrada. Intervalo permitido: de 10 minutos a 336 horas (14 dias).
- Tempo máximo da sessão:o ciclo de vida máximo de uma sessão antes de ela ser encerrada. Intervalo permitido: de 10 minutos a 336 horas (14 dias).
Metastore: para usar um serviço do metastore do Dataproc com suas sessões, selecione o ID do projeto e o serviço do metastore.
Servidor de histórico permanente: você pode selecionar um servidor de histórico permanente do Spark disponível para acessar os registros de sessão durante e depois das sessões.
Propriedades do Spark:é possível selecionar e adicionar propriedades de alocação de recursos, escalonamento automático ou GPU do Spark. Clique em Adicionar propriedade para incluir outras propriedades do Spark. Para mais informações, consulte Propriedades do Spark.
Rótulos:clique em Adicionar rótulo para cada rótulo que será definido nas sessões criadas com o modelo.
Clique em Salvar para criar o modelo.
Para ver ou excluir um modelo de ambiente de execução.
- Clique em Configurações > Google Cloud Configurações.
A seção Configurações do Dataproc > Modelos de ambiente de execução sem servidor mostra a lista de modelos de ambiente de execução.
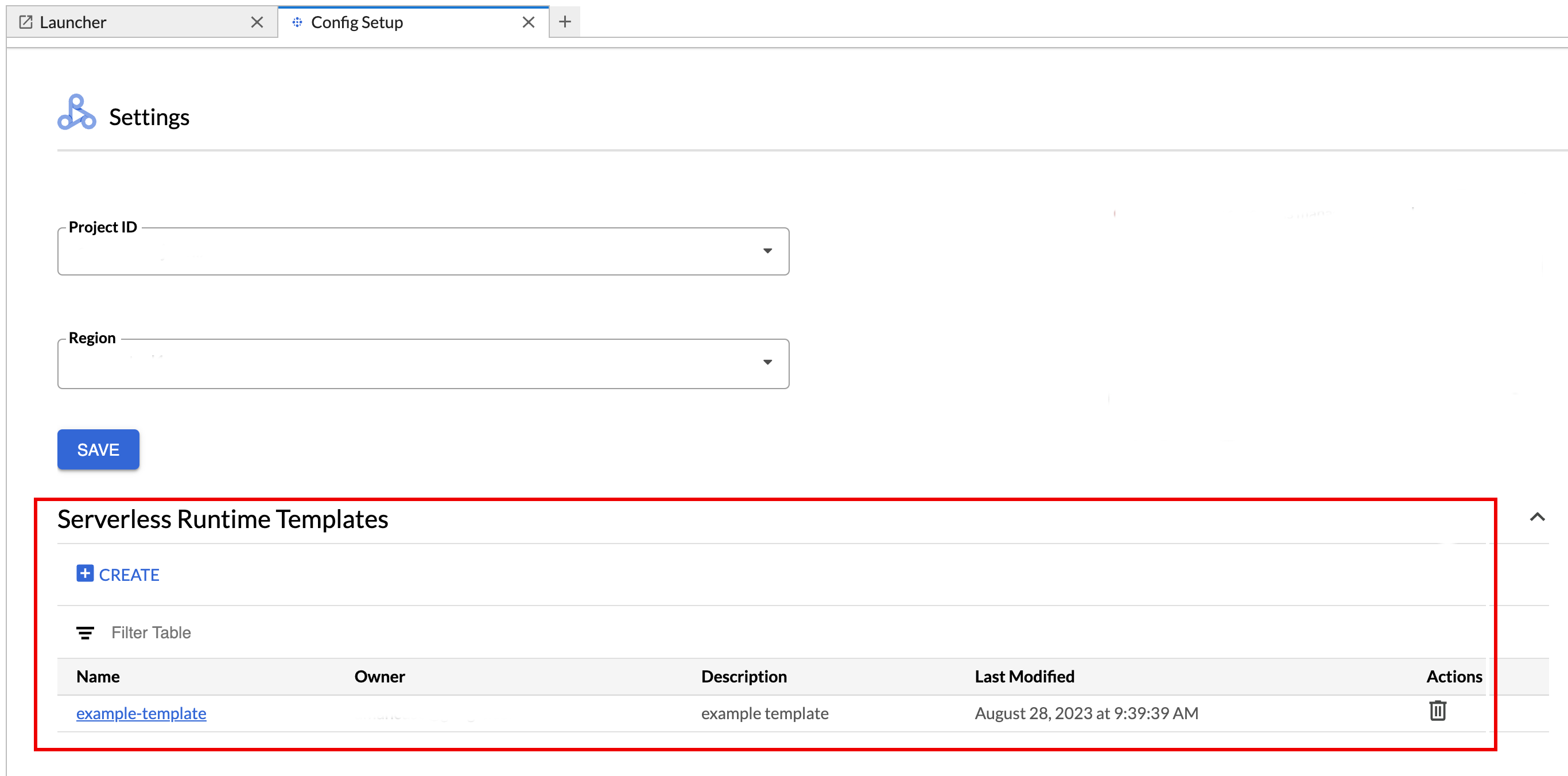
- Clique no nome de um modelo para conferir os detalhes dele.
- É possível excluir um modelo no menu Ação dele.
Abra e recarregue a página Acesso rápido do JupyterLab para ver o card do modelo de notebook salvo na página Acesso rápido do JupyterLab.

Crie um arquivo YAML com a configuração do modelo de ambiente de execução.
YAML simples
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
YAML complexo
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Crie um modelo de sessão (tempo de execução) com base no arquivo YAML executando o seguinte comando gcloud beta dataproc session-templates import localmente ou no Cloud Shell:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Consulte gcloud beta dataproc session-templates para comandos que descrevem, listam, exportam e excluem modelos de sessão.
Inicie um notebook do Jupyter no Serverless para Apache Spark.
Inicie um notebook do Jupyter em um cluster do Dataproc no Compute Engine.
Clique em um card para criar uma sessão do Serverless para Apache Spark e iniciar um notebook. Quando a criação da sessão for concluída e o kernel do notebook estiver pronto para uso, o status dele mudará de
StartingparaIdle (Ready).Escrever e testar o código do notebook.
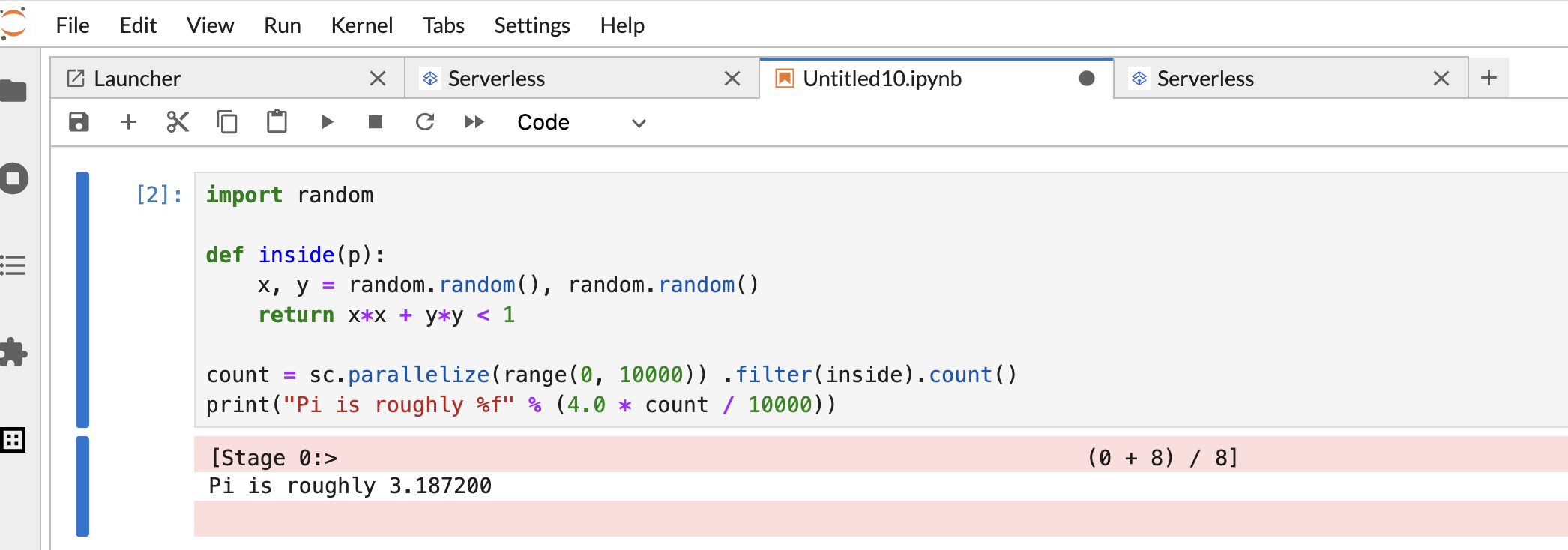
Copie e cole o seguinte código PySpark
Pi estimationna célula do notebook PySpark e pressione Shift+Return para executar o código.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Resultado do notebook:
Depois de criar e usar um notebook, você pode encerrar a sessão dele clicando em Desligar kernel na guia Kernel.
- Para reutilizar a sessão, crie um notebook escolhendo Notebook no menu Arquivo>>Novo. Depois que o novo notebook for criado, escolha a sessão atual na caixa de diálogo de seleção do kernel. O novo notebook vai reutilizar a sessão e manter o contexto dela do notebook anterior.
Se você não encerrar a sessão, o Dataproc a encerrará quando o temporizador de inatividade dela expirar. Você pode configurar o tempo de inatividade da sessão na configuração do modelo de ambiente de execução. O tempo de inatividade de sessão padrão é de uma hora.
Clique em um card na seção Notebook do cluster do Dataproc.
Quando o status do kernel mudar de
StartingparaIdle (Ready), você poderá começar a escrever e executar o código do notebook.Depois de criar e usar um notebook, você pode encerrar a sessão dele clicando em Desligar kernel na guia Kernel.
Para acessar o navegador do Cloud Storage, clique no ícone dele na barra lateral da página Launcher do JupyterLab e clique duas vezes em uma pasta para conferir o conteúdo dela.
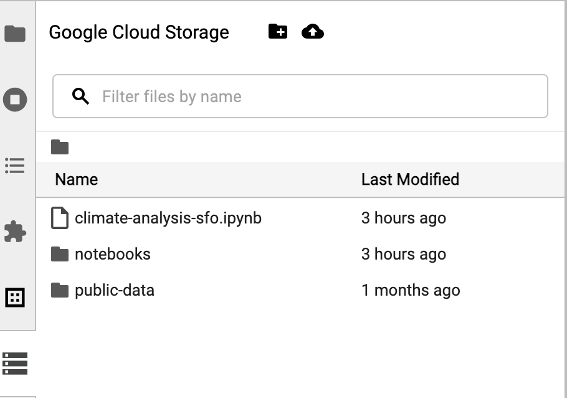
Clique nos tipos de arquivo compatíveis com o Jupyter para abrir e editar. Quando você salva as mudanças nos arquivos, elas são gravadas no Cloud Storage.
Para criar uma pasta do Cloud Storage, clique no ícone de nova pasta e insira o nome dela.
Para fazer upload de arquivos em um bucket ou pasta do Cloud Storage, clique no ícone de upload e selecione os arquivos.
Clique em um card do PySpark na seção Notebooks sem servidor para Apache Spark ou Notebook do cluster do Dataproc na página Acesso rápido do JupyterLab para abrir um notebook do PySpark.
Clique em um card de kernel Python na seção Notebook do cluster do Dataproc na página Acesso rápido do JupyterLab para abrir um notebook Python.
Clique no card do Apache Toree na seção Notebook do cluster do Dataproc na página Launcher do JupyterLab para abrir um notebook para desenvolvimento de código em Scala.

Figura 1. Card do kernel do Apache Toree na página de acesso rápido do JupyterLab. - Desenvolva e execute código do Spark em notebooks do Serverless para Apache Spark.
- Crie e gerencie modelos de tempo de execução (sessão) do Serverless para Apache Spark, sessões interativas e cargas de trabalho em lote.
- Desenvolver e executar notebooks do BigQuery.
- Navegue, inspecione e visualize conjuntos de dados do BigQuery.
- Faça o download e instale o VS Code.
- Abra o VS Code e, na barra de atividades, clique em Extensões.
Na barra de pesquisa, encontre a extensão Jupyter e clique em Instalar. A extensão do Jupyter da Microsoft é uma dependência obrigatória.
- Abra o VS Code e, na barra de atividades, clique em Extensões.
Use a barra de pesquisa para encontrar a extensão Google Cloud Code e clique em Instalar.

Se solicitado, reinicie o VS Code.
- Abra o VS Code e, na barra de atividades, clique em Google Cloud Code.
- Abra a seção Dataproc.
- Clique em Fazer login em Google Cloud. Você será redirecionado para fazer login com suas credenciais.
- Use a barra de tarefas superior do aplicativo para navegar até Código > Configurações > Configurações > Extensões.
- Encontre Google Cloud Código e clique no ícone Gerenciar para abrir o menu.
- Selecione Configurações.
- Nos campos Projeto e Região do Dataproc, insira o nome do projeto Google Cloud e da região que serão usados para desenvolver notebooks e gerenciar recursos do Serverless para Apache Spark.
- Abra o VS Code e, na barra de atividades, clique em Google Cloud Code.
- Abra a seção Notebooks e clique em Novo notebook do Spark sem servidor.
- Selecione ou crie um modelo de ambiente de execução (sessão) para usar na sessão do notebook.
Um novo arquivo
.ipynbcom um exemplo de código é criado e aberto no editor.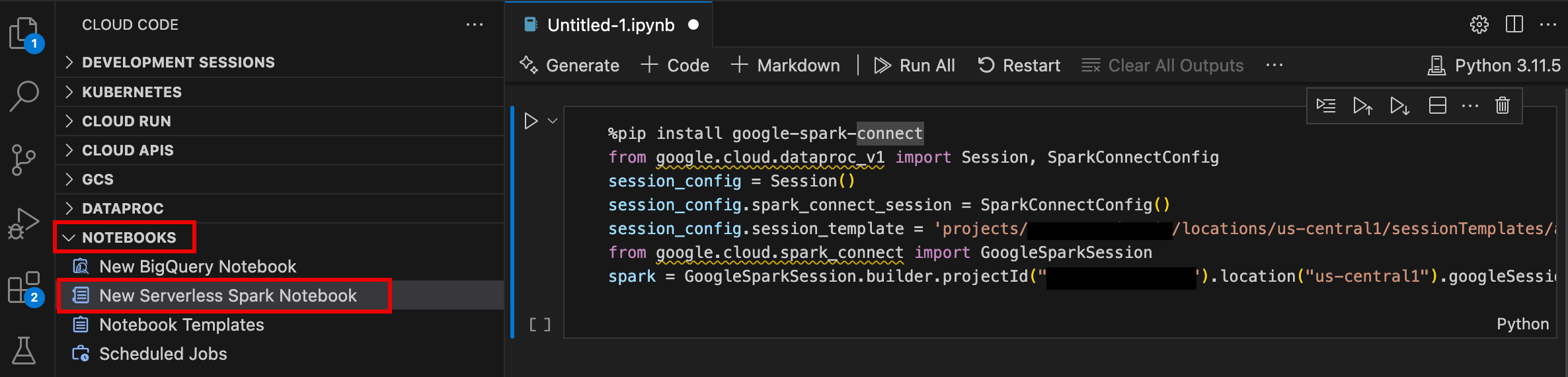
Agora é possível escrever e executar código no notebook do Serverless para Apache Spark.
- Abra o VS Code e, na barra de atividades, clique em Google Cloud Code.
Abra a seção Dataproc e clique nos seguintes nomes de recursos:
- Clusters: crie e gerencie clusters e jobs.
- Sem servidor: crie e gerencie cargas de trabalho em lote e sessões interativas.
- Modelos de ambiente de execução do Spark: crie e gerencie modelos de sessão.

Execute o código do notebook na infraestrutura Google Cloud Serverless para Apache Spark
Programar a execução de notebooks no Cloud Composer
Envie jobs em lote para a infraestrutura do Google Cloud Serverless para Apache Spark ou para seu cluster do Dataproc no Compute Engine.
Clique no botão Job Scheduler no canto superior direito do notebook.
Preencha o formulário Criar um job programado para fornecer as seguintes informações:
- Um nome exclusivo para o job de execução do notebook
- O ambiente do Cloud Composer a ser usado para implantar o notebook
- Parâmetros de entrada, se o notebook estiver parametrizado
- O cluster do Dataproc ou o modelo de ambiente de execução sem servidor a ser usado
para executar o notebook
- Se um cluster for selecionado, se ele será interrompido depois que o notebook terminar de ser executado nele.
- Contagem de tentativas e atraso na repetição em minutos se a execução do notebook falhar na primeira tentativa
- Notificações de execução a serem enviadas e a lista de destinatários. As notificações são enviadas usando uma configuração SMTP do Airflow.
- A programação de execução do notebook
Clique em Criar.
Depois que o notebook é programado, o nome do job aparece na lista de jobs programados no ambiente do Cloud Composer.

Clique no card Sem servidor na seção Jobs e sessões do Dataproc na página Acesso rápido do JupyterLab.
Clique na guia Lote e em Criar lote. Preencha os campos Informações do lote.
Clique em Enviar para enviar o job.
Clique no card Clusters na seção Jobs e sessões do Dataproc na página Acesso rápido do JupyterLab.
Clique na guia Jobs e em Enviar job.
Selecione um Cluster e preencha os campos Job.
Clique em Enviar para enviar o job.
- Clique no card Sem servidor.
- Clique na guia Sessões e em um ID de sessão para abrir a página Detalhes da sessão. Nela, é possível conferir as propriedades da sessão, os registros Google Cloud no Explorador de registros e encerrar uma sessão. Observação: uma sessão exclusiva do Google Cloud Serverless para Apache Spark é criada para iniciar cada notebook do Google Cloud Serverless para Apache Spark.
- Clique na guia Lotes para conferir a lista de lotes do Google Cloud Serverless para Apache Spark no projeto e na região atuais. Clique em um ID do lote para conferir os detalhes.
- Clique no card Clusters. A guia Clusters é selecionada para listar clusters ativos do Dataproc no Compute Engine no projeto e na região atuais. Clique nos ícones na coluna Ações para iniciar, interromper ou reiniciar um cluster. Clique no nome de um cluster para ver os detalhes dele. Clique nos ícones na coluna Ações para clonar, interromper ou excluir um job.
- Clique no card Jobs para ver a lista de jobs no projeto atual. Clique em um ID do job para ver os detalhes.
Instalar a extensão do JupyterLab
É possível instalar e usar a extensão do JupyterLab em uma máquina ou VM que tenha acesso aos serviços do Google, como sua máquina local ou uma instância de VM do Compute Engine.
Para instalar a extensão, siga estas etapas:
Criar um modelo de ambiente de execução sem servidor para Apache Spark
Os modelos de ambiente de execução sem servidor para Apache Spark (também chamados de modelos de sessão) contêm definições de configuração para executar código do Spark em uma sessão. É possível criar e gerenciar modelos de execução usando o JupyterLab ou a CLI gcloud.
JupyterLab
gcloud
Iniciar e gerenciar notebooks
Depois de instalar a extensão do Dataproc JupyterLab, clique nos cards de modelo na página Acesso rápido do JupyterLab para:
Iniciar um notebook do Jupyter no Serverless para Apache Spark
A seção Notebooks sem servidor para Apache Spark na página do acesso rápido do JupyterLab mostra cards de modelo de notebook que correspondem a modelos de ambiente de execução sem servidor para Apache Spark (consulte Criar um modelo de ambiente de execução sem servidor para Apache Spark).

Iniciar um notebook em um cluster do Dataproc no Compute Engine
Se você criou um cluster Jupyter do Dataproc no Compute Engine, a página Launcher do JupyterLab contém uma seção Notebook do cluster do Dataproc com cards de kernel pré-instalados.
Para iniciar um notebook do Jupyter no cluster do Dataproc no Compute Engine:
Gerenciar arquivos de entrada e saída no Cloud Storage
A análise de dados exploratórios e a criação de modelos de ML geralmente envolvem entradas e saídas baseadas em arquivos. O Serverless para Apache Spark acessa esses arquivos no Cloud Storage.
Desenvolver código de notebook do Spark
Depois de instalar a extensão do Dataproc JupyterLab, é possível iniciar notebooks do Jupyter na página Launcher do JupyterLab para desenvolver código de aplicativo.
Desenvolvimento de código Python e PySpark
O Serverless para Apache Spark e os clusters do Dataproc no Compute Engine aceitam kernels do PySpark. O Dataproc no Compute Engine também é compatível com kernels Python.
Desenvolvimento de código SQL
Para abrir um notebook do PySpark e escrever e executar código SQL, na página Launcher do JupyterLab, na seção Notebooks sem servidor para Apache Spark ou Notebook do cluster do Dataproc, clique no card do kernel do PySpark.
Magic do Spark SQL:como o kernel do PySpark que inicia os
Notebooks sem servidor para Apache Spark
já vem com a magic do Spark SQL, em vez de usar spark.sql('SQL STATEMENT').show()
para encapsular sua instrução SQL, digite
%%sparksql magic na parte de cima de uma célula e digite sua instrução SQL nela.
SQL do BigQuery:o conector do BigQuery para Spark permite que o código do notebook carregue dados de tabelas do BigQuery, faça análises no Spark e grave os resultados em uma tabela do BigQuery.
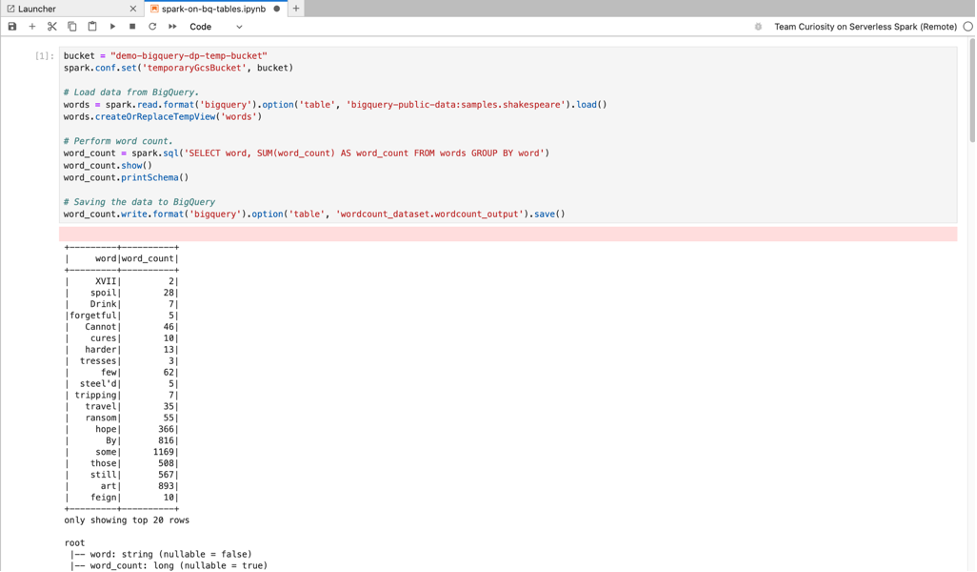
Os tempos de execução do Serverless para Apache Spark 2.2
e versões mais recentes incluem o
conector do BigQuery Spark.
Se você usar um ambiente de execução anterior para iniciar notebooks sem servidor para Apache Spark,
instale o conector do BigQuery para Spark adicionando a seguinte propriedade do Spark
ao seu modelo de ambiente de execução sem servidor para Apache Spark:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Desenvolvimento de código Scala
Os clusters do Dataproc no Compute Engine criados com versões de imagem 2.0 e mais recentes incluem o Apache Toree, um kernel Scala para a plataforma Jupyter Notebook que oferece acesso interativo ao Spark.
Desenvolver código com a extensão do Visual Studio Code
Com a extensão do Google Cloud Visual Studio Code (VS Code), é possível fazer o seguinte:
A extensão do Visual Studio Code é gratuita, mas você paga por todos os serviços, incluindo Dataproc, Serverless para Apache Spark e recursos do Cloud Storage que usar.Google Cloud
Usar o VS Code com o BigQuery: também é possível usar o VS Code com o BigQuery para fazer o seguinte:
Antes de começar
Instalar a extensão Google Cloud
O ícone Google Cloud Code agora está visível na barra de atividades do VS Code.
Configurar a extensão
Desenvolver notebooks do Serverless para Apache Spark
Criar e gerenciar recursos do Serverless para Apache Spark
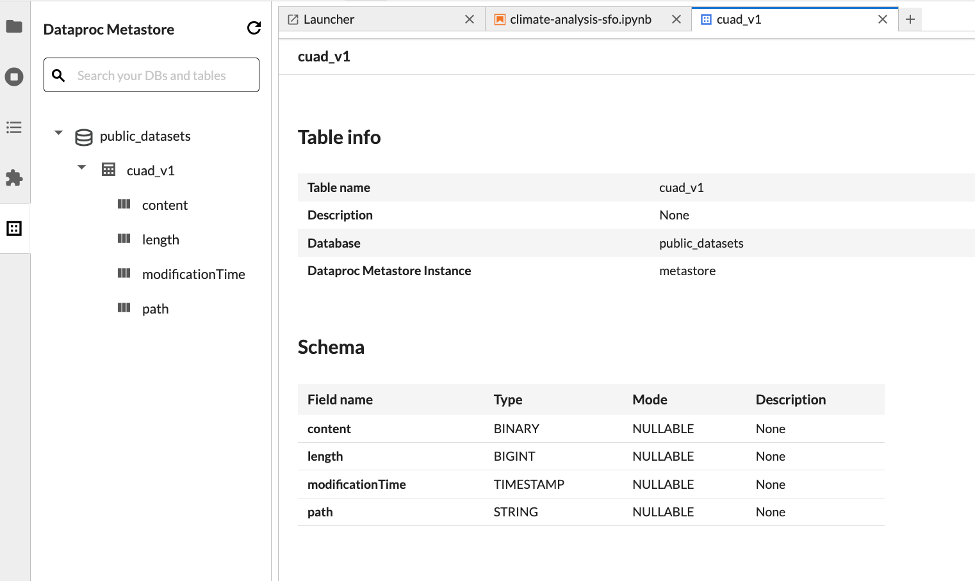
Explorador de conjunto de dados
Use o explorador de conjuntos de dados do JupyterLab para ver os conjuntos de dados do metastore do BigLake.
Para abrir o Explorador de conjunto de dados do JupyterLab, clique no ícone dele na barra lateral.
Você pode pesquisar um banco de dados, uma tabela ou uma coluna no explorador de conjuntos de dados. Clique no nome de um banco de dados, tabela ou coluna para ver os metadados associados.
Implantar o código
Depois de instalar a extensão do Dataproc JupyterLab, você pode usar o JupyterLab para:
Programar a execução de notebooks no Cloud Composer
Conclua as etapas a seguir para programar o código do notebook no Cloud Composer e executá-lo como um job em lote no Serverless para Apache Spark ou em um cluster do Dataproc no Compute Engine.
Enviar um job em lote para o Google Cloud Serverless para Apache Spark
Enviar um job em lote para um cluster do Dataproc no Compute Engine
Ver e gerenciar recursos
Depois de instalar a extensão Dataproc JupyterLab, é possível ver e gerenciar o Google Cloud Dataproc sem servidor para Apache Spark e Dataproc no Compute Engine na seção Jobs e sessões do Dataproc da página Launcher do JupyterLab.
Clique na seção Jobs e sessões do Dataproc para mostrar os cards Clusters e Sem servidor.
Para ver e gerenciar sessões do Google Cloud Serverless para Apache Spark:
Para ver e gerenciar lotes do Google Cloud Serverless para Apache Spark:
Para ver e gerenciar clusters do Dataproc no Compute Engine:
Para acessar e gerenciar jobs do Dataproc no Compute Engine: