Este documento descreve as ferramentas e os ficheiros que pode usar para monitorizar e resolver problemas de cargas de trabalho em lote do Serverless para Apache Spark.
Resolva problemas de cargas de trabalho a partir da consola Google Cloud
Quando uma tarefa em lote falha ou tem um desempenho fraco, um primeiro passo recomendado é abrir a respetiva página Detalhes do lote a partir da página Lotes na Google Cloud consola.
Use o separador Resumo: o seu centro de resolução de problemas
O separador Resumo, que é selecionado por predefinição quando a página Detalhes do lote é aberta, apresenta métricas críticas e registos filtrados para ajudar a fazer uma avaliação inicial rápida do estado do lote. Após esta avaliação inicial, pode fazer uma análise mais detalhada através de ferramentas mais especializadas apresentadas na página Detalhes do lote, como a IU do Spark, o Explorador de registos e o Gemini Cloud Assist.
Destaques das métricas em lote
O separador Resumo na página Detalhes do lote inclui gráficos que apresentam valores importantes das métricas de carga de trabalho em lote. Os gráficos de métricas são preenchidos após a conclusão da análise e oferecem uma indicação visual de potenciais problemas, como contenção de recursos, distorção de dados ou pressão de memória.
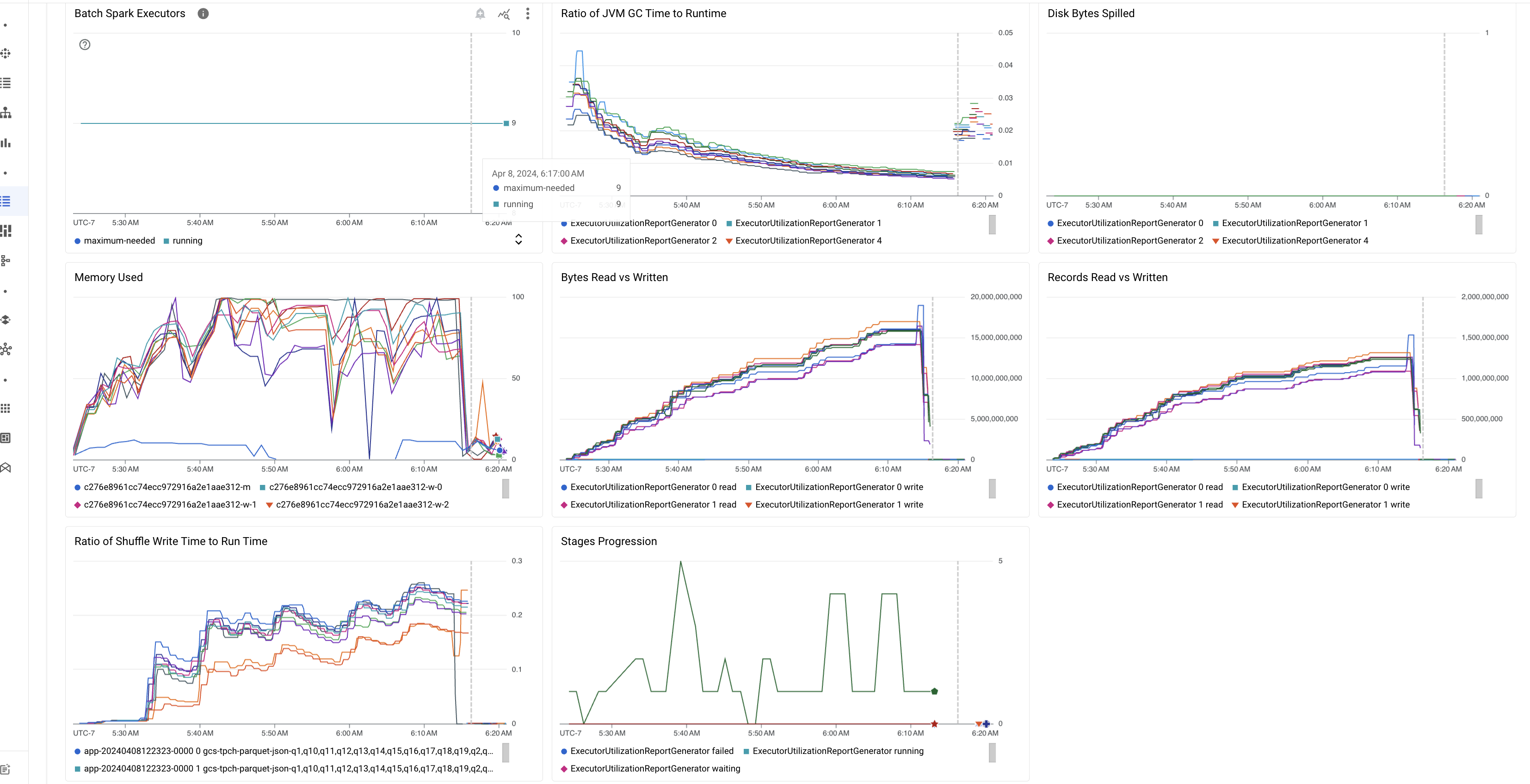
A tabela seguinte lista as métricas de carga de trabalho do Spark apresentadas na página Detalhes do lote na consola Google Cloud e descreve como os valores das métricas podem fornecer estatísticas sobre o estado e o desempenho da carga de trabalho.
| Métrica | O que mostra? |
|---|---|
| Métricas ao nível do executor | |
| Rácio entre o tempo de GC da JVM e o tempo de execução | Esta métrica mostra a proporção do tempo de GC (recolha de lixo) da JVM em relação ao tempo de execução por executor. As taxas elevadas podem indicar fugas de memória em tarefas executadas em executores específicos ou estruturas de dados ineficientes, o que pode levar a uma elevada rotatividade de objetos. |
| Bytes de disco derramados | Esta métrica mostra o número total de bytes de disco derramados em diferentes executores. Se um executor mostrar um elevado número de bytes derramados no disco, isto pode indicar uma distorção dos dados. Se a métrica aumentar ao longo do tempo, isso pode indicar que existem fases com pressão de memória ou fugas de memória. |
| Bytes lidos e escritos | Esta métrica mostra os bytes escritos em comparação com os bytes lidos por executor. As grandes discrepâncias nos bytes lidos ou escritos podem indicar cenários em que as junções replicadas levam à amplificação de dados em executores específicos. |
| Registos lidos e escritos | Esta métrica mostra os registos lidos e escritos por executor. Um grande número de registos lidos com um baixo número de registos escritos pode indicar um gargalo na lógica de processamento em executores específicos, o que leva à leitura de registos durante a espera. Os executores que atrasam consistentemente as leituras e as escritas podem indicar contenção de recursos nesses nós ou ineficiências de código específicas do executor. |
| Rácio entre o tempo de escrita aleatória e o tempo de execução | A métrica mostra a quantidade de tempo que o executor passou no tempo de execução da aleatorização em comparação com o tempo de execução geral. Se este valor for elevado para alguns executores, pode indicar uma distorção de dados ou uma serialização de dados ineficiente. Pode identificar fases com tempos de gravação de mistura longos na IU do Spark. Procure tarefas atípicas nessas fases que demorem mais do que o tempo médio a serem concluídas. Verifique se os executores com tempos de gravação aleatória elevados também apresentam uma atividade de I/O do disco elevada. A serialização mais eficiente e os passos de partição adicionais podem ajudar. Um número muito elevado de gravações de registos em comparação com as leituras de registos pode indicar uma duplicação de dados não intencional devido a junções ineficientes ou transformações incorretas. |
| Métricas ao nível da aplicação | |
| Progressão de palcos | Esta métrica mostra o número de fases com falhas, em espera e em execução. Um grande número de fases com falhas ou em espera pode indicar uma distorção dos dados. Verifique se existem partições de dados e depure o motivo da falha da fase através do separador Fases na IU do Spark. |
| Executores do Spark em lote | Esta métrica mostra o número de executores que podem ser necessários em comparação com o número de executores em execução. Uma grande diferença entre os executores necessários e os executores em execução pode indicar problemas de escalabilidade automática. |
| Métricas ao nível da VM | |
| Memória usada | Esta métrica mostra a percentagem de memória da MV em utilização. Se a percentagem principal for elevada, pode indicar que o controlador está sob pressão de memória. Para outros nós de VM, uma percentagem elevada pode indicar que os executores estão a ficar sem memória, o que pode levar a um excesso de dados no disco e a um tempo de execução da carga de trabalho mais lento. Use a IU do Spark para analisar executores e verificar se existem tempos de GC elevados e falhas de tarefas elevadas. Também depure o código Spark para a colocação em cache de conjuntos de dados grandes e a transmissão desnecessária de variáveis. |
Registos de tarefas
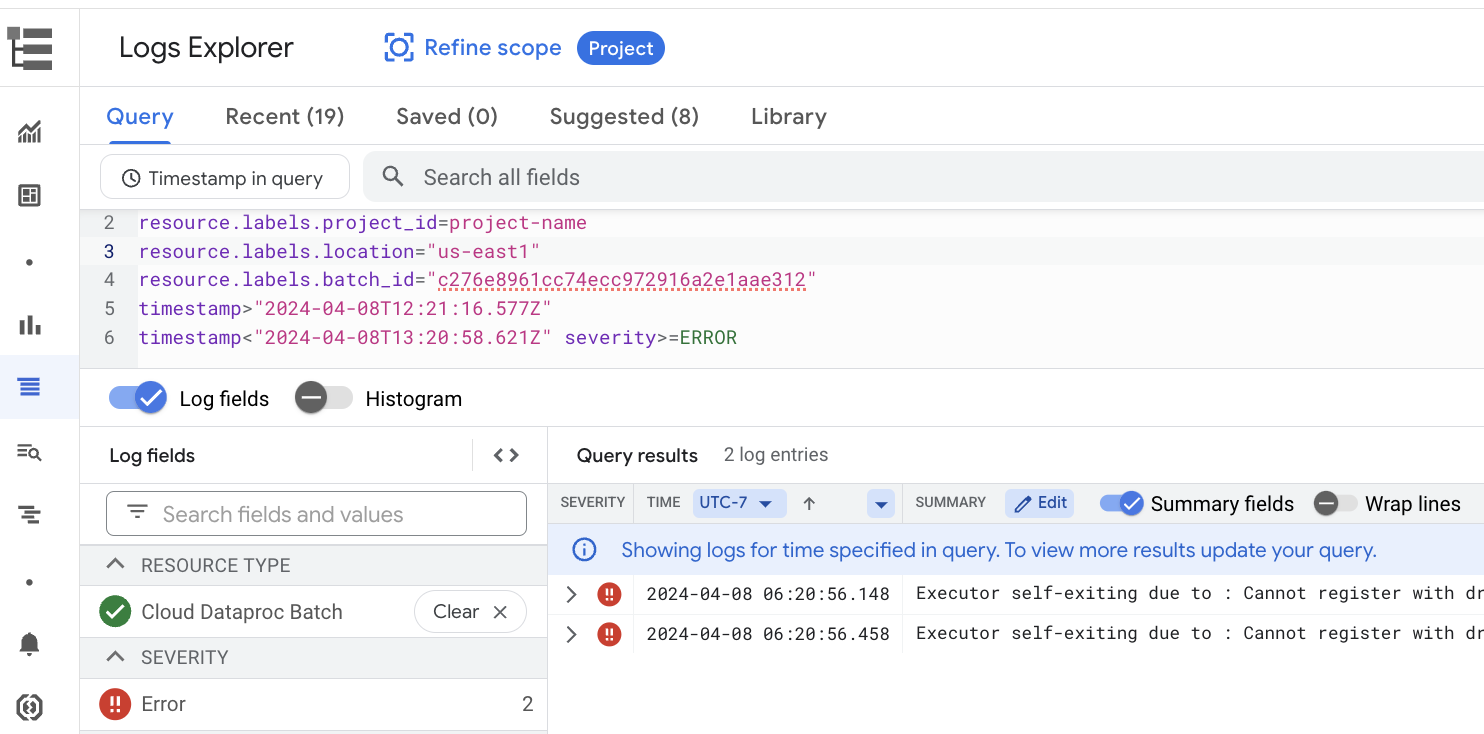
A página Detalhes do lote inclui uma secção Registos de tarefas que apresenta avisos e erros filtrados dos registos de tarefas (carga de trabalho em lote). Esta funcionalidade permite a identificação rápida de problemas críticos sem ter de analisar manualmente ficheiros de registo extensos. Pode selecionar uma Gravidade do registo (por exemplo, Error) no menu pendente e adicionar um Filtro de texto para restringir os resultados. Para fazer uma análise mais detalhada, clique no ícone Ver no Explorador de registos
para abrir os registos em lote selecionados no Explorador de registos.
Exemplo: o Explorador de registos é aberto depois de escolher Errors no seletor de gravidade na página Detalhes do lote na Google Cloud consola.
IU do Spark
A IU do Spark recolhe detalhes de execução do Apache Spark a partir do Serverless para cargas de trabalho em lote do Apache Spark. Não existe qualquer custo para a funcionalidade da IU do Spark, que está ativada por predefinição.
Os dados recolhidos pela funcionalidade da IU do Spark são retidos durante 90 dias. Pode usar esta interface Web para monitorizar e depurar cargas de trabalho do Spark sem ter de criar um servidor de histórico persistente.
Autorizações e funções da gestão de identidade e de acesso necessárias
São necessárias as seguintes autorizações para usar a funcionalidade da IU do Spark com cargas de trabalho em lote.
Autorização de recolha de dados:
dataproc.batches.sparkApplicationWrite. Esta autorização tem de ser concedida à conta de serviço que executa cargas de trabalho em lote. Esta autorização está incluída na funçãoDataproc Workerque é concedida automaticamente à conta de serviço predefinida do Compute Engine que o Serverless para Apache Spark usa por predefinição (consulte a conta de serviço do Serverless para Apache Spark). No entanto, se especificar uma conta de serviço personalizada para a sua carga de trabalho em lote, tem de adicionar a autorizaçãodataproc.batches.sparkApplicationWritea essa conta de serviço (normalmente, concedendo à conta de serviço a funçãoWorkerdo Dataproc).Autorização de acesso à IU do Spark:
dataproc.batches.sparkApplicationRead. Esta autorização tem de ser concedida a um utilizador para aceder à IU do Spark naGoogle Cloud consola. Esta autorização está incluída nas funçõesDataproc Viewer,Dataproc EditoreDataproc Administrator. Para abrir a IU do Spark na Google Cloud consola, tem de ter uma das seguintes funções ou uma função personalizada que inclua esta autorização.
Abra a IU do Spark
A página da IU do Spark está disponível nas Google Cloud cargas de trabalho em lote da consola.
Aceda à página Sessões interativas sem servidor para o Apache Spark.
Clique num ID do lote para abrir a página Detalhes do lote.
Clique em Ver IU do Spark no menu superior.
O botão Ver IU do Spark está desativado nos seguintes casos:
- Se uma autorização obrigatória não for concedida
- Se desmarcar a caixa de verificação Ativar IU do Spark na página Detalhes do lote
- Se definir a propriedade
spark.dataproc.appContext.enabledcomofalsequando envia uma carga de trabalho em lote
Investigações com tecnologia de IA com o Gemini Cloud Assist (pré-visualização)
Vista geral
A funcionalidade de pré-visualização do Gemini Cloud Assist Investigations usa as capacidades avançadas do Gemini para ajudar na criação e execução de cargas de trabalho em lote sem servidor para o Apache Spark. Esta funcionalidade analisa cargas de trabalho com falhas e de execução lenta para identificar as causas principais e recomendar correções. Cria uma análise persistente que pode rever, guardar e partilhar com o apoio técnico para facilitar a colaboração e acelerar a resolução de problemas. Google Cloud
Funcionalidades
Use esta funcionalidade para criar investigações a partir da Google Cloud consola:
- Adicione uma descrição de contexto de linguagem natural a um problema antes de criar uma investigação.
- Analise cargas de trabalho em lote lentas e com falhas.
- Aceda a estatísticas sobre as causas principais dos problemas com correções recomendadas.
- Criar Google Cloud registos de apoio técnico com o contexto completo da investigação em anexo.
Antes de começar
Para começar a usar a funcionalidade de investigação, no seu Google Cloud projeto, ative a API Gemini Cloud Assist.
Inicie uma investigação
Para iniciar uma investigação, efetue uma das seguintes ações:
Opção 1: na Google Cloud consola, aceda à página da lista de lotes. Para qualquer lote com o estado
Failed, é apresentado um botão INVESTIGAR na coluna Estatísticas do Gemini. Clique no botão para iniciar uma investigação.
Opção 2: abra a página de detalhes do lote da carga de trabalho em lote para investigar. Para cargas de trabalho em lote
SucceededeFailed, na secção Vista geral do estado do separador Resumo, é apresentado um botão INVESTIGAR no painel Estatísticas do Gemini. Clique no botão para iniciar uma investigação.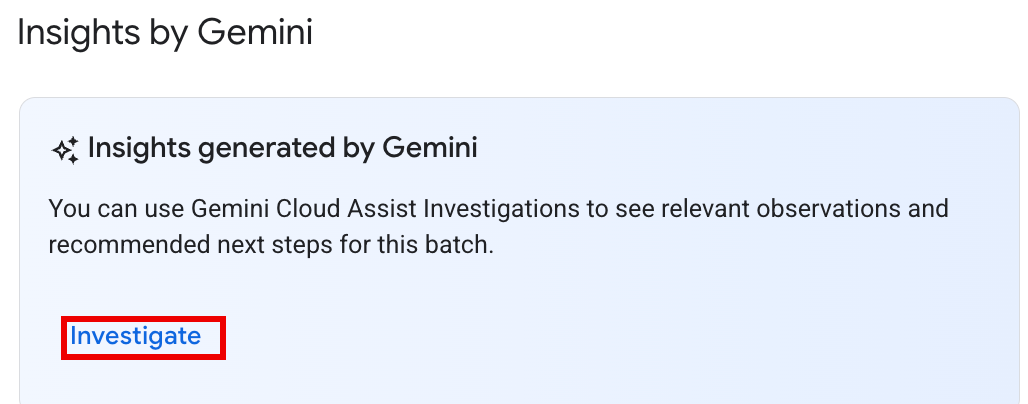
O texto do botão de investigação indica o estado da investigação:
- INVESTIGAR: não foi executada nenhuma investigação para este batch_details. Clique no botão para iniciar uma investigação.
- VER INVESTIGAÇÃO: foi concluída uma investigação. Clique no botão para ver os resultados.
- INVESTIGANDO: está em curso uma investigação.
Interprete os resultados da investigação
Quando uma investigação estiver concluída, é apresentada a página Detalhes da investigação. Esta página contém a análise completa do Gemini, que está organizada nas seguintes secções:
- Problema: uma secção reduzida que contém detalhes preenchidos automaticamente da carga de trabalho em lote que está a ser investigada.
- Observações relevantes: uma secção reduzida que apresenta os principais pontos de dados e anomalias que o Gemini encontrou durante a análise dos registos e das métricas.
- Hipóteses: esta é a secção principal, que é expandida por predefinição.
Apresenta uma lista de potenciais causas do problema observado. Cada hipótese
inclui:
- Vista geral: uma descrição da possível causa, como "Tempo de gravação aleatória elevado e potencial desvio de tarefas".
- Correções recomendadas: uma lista de passos acionáveis para resolver o potencial problema.
Tomar medidas
Depois de rever as hipóteses e as recomendações:
Aplique uma ou mais das correções sugeridas à configuração ou ao código da tarefa e, em seguida, volte a executar a tarefa.
Clique nos ícones de gosto ou não gosto na parte superior do painel para enviar feedback sobre a utilidade da investigação.
Reveja e encaminhe investigações
Pode rever os resultados de uma investigação executada anteriormente clicando no nome da investigação na página Investigações do Cloud Assist para abrir a página Detalhes da investigação.
Se precisar de mais assistência, pode abrir um Google Cloud registo de apoio técnico. Este processo fornece ao engenheiro de apoio técnico o contexto completo da investigação realizada anteriormente, incluindo as observações e as hipóteses geradas pelo Gemini. Esta partilha de contexto reduz significativamente a comunicação necessária com a equipa de apoio técnico e leva a uma resolução mais rápida do registo.
Para criar um registo de apoio ao cliente a partir de uma investigação:
Na página Detalhes da investigação, clique em Pedir apoio técnico.
Pré-visualize o estado e os preços
Não existe qualquer custo para as investigações do Gemini Cloud Assist durante a pré-visualização pública. A funcionalidade vai ser cobrada quando ficar disponível em geral (DG).
Para mais informações sobre os preços após a disponibilidade geral, consulte os preços do Gemini Cloud Assist.
Pré-visualização do Gemini (vai ser descontinuada a 22 de setembro de 2025)
A funcionalidade de pré-visualização Pedir ao Gemini oferecia acesso com um clique a estatísticas nas páginas Lotes e Detalhes do lote na Google Cloud consola através de um botão Pedir ao Gemini. Esta função gerou um resumo dos erros, das anomalias e das potenciais melhorias de desempenho com base nos registos e nas métricas da carga de trabalho.
Após a descontinuação da versão pré-visualização "Pedir ao Gemini" a 22 de setembro de 2025, os utilizadores podem continuar a receber assistência com tecnologia de IA através da funcionalidade de investigações do Gemini Cloud Assist.
Importante: para garantir uma assistência de IA de resolução de problemas ininterrupta, é altamente recomendável ativar as investigações do Gemini Cloud Assist antes de 22 de setembro de 2025.
Sem servidor para registos do Apache Spark
A registo está ativado por predefinição no Serverless para Apache Spark, e os registos de cargas de trabalho persistem após a conclusão de uma carga de trabalho. O Serverless for Apache Spark recolhe registos de cargas de trabalho no Cloud Logging.
Pode aceder aos registos do Serverless para Apache Spark no recurso Cloud Dataproc Batch no Explorador de registos.
Consulte registos do Apache Spark sem servidor
O explorador de registos na Google Cloud consola fornece um painel de consultas para ajudar a criar uma consulta para examinar os registos de cargas de trabalho em lote. Seguem-se os passos que pode seguir para criar uma consulta para examinar os registos da carga de trabalho em lote:
- O seu projeto atual está selecionado. Pode clicar em Refinar projeto de âmbito para selecionar um projeto diferente.
Defina uma consulta de registos em lote.
Use os menus de filtros para filtrar uma carga de trabalho em lote.
Em Todos os recursos, selecione o recurso Cloud Dataproc Batch.
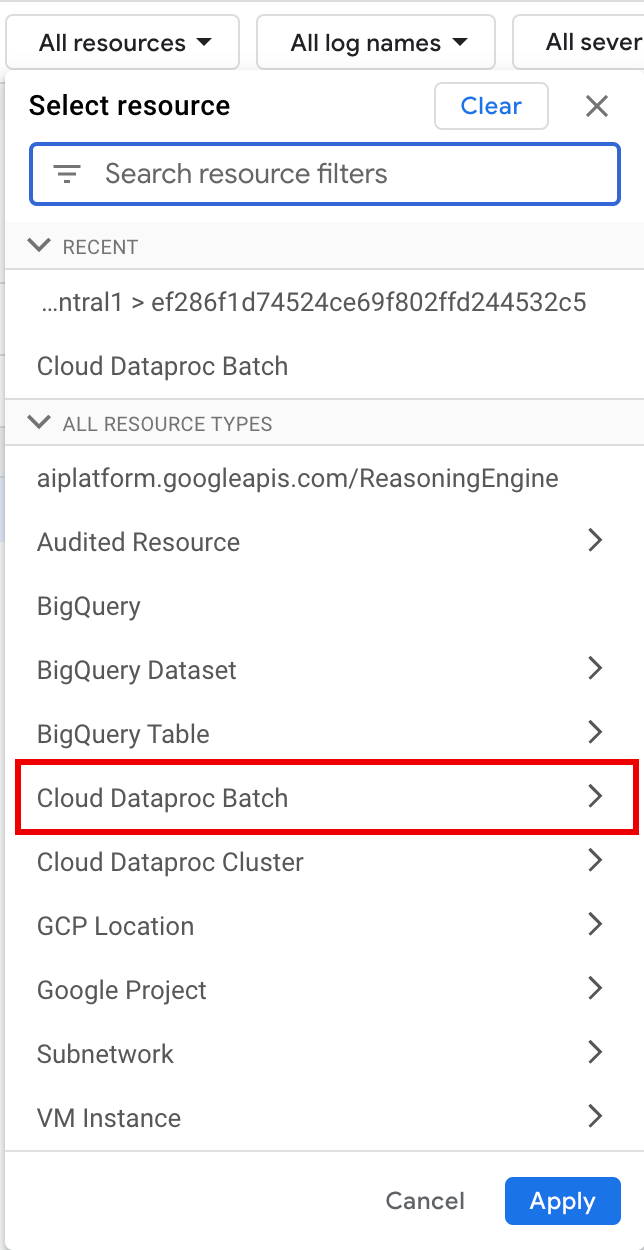
No painel Selecionar recurso, selecione o lote LOCATION e, de seguida, o ID DO LOTE. Estes parâmetros de lote estão listados na página Lotes do Dataproc na Google Cloud consola.
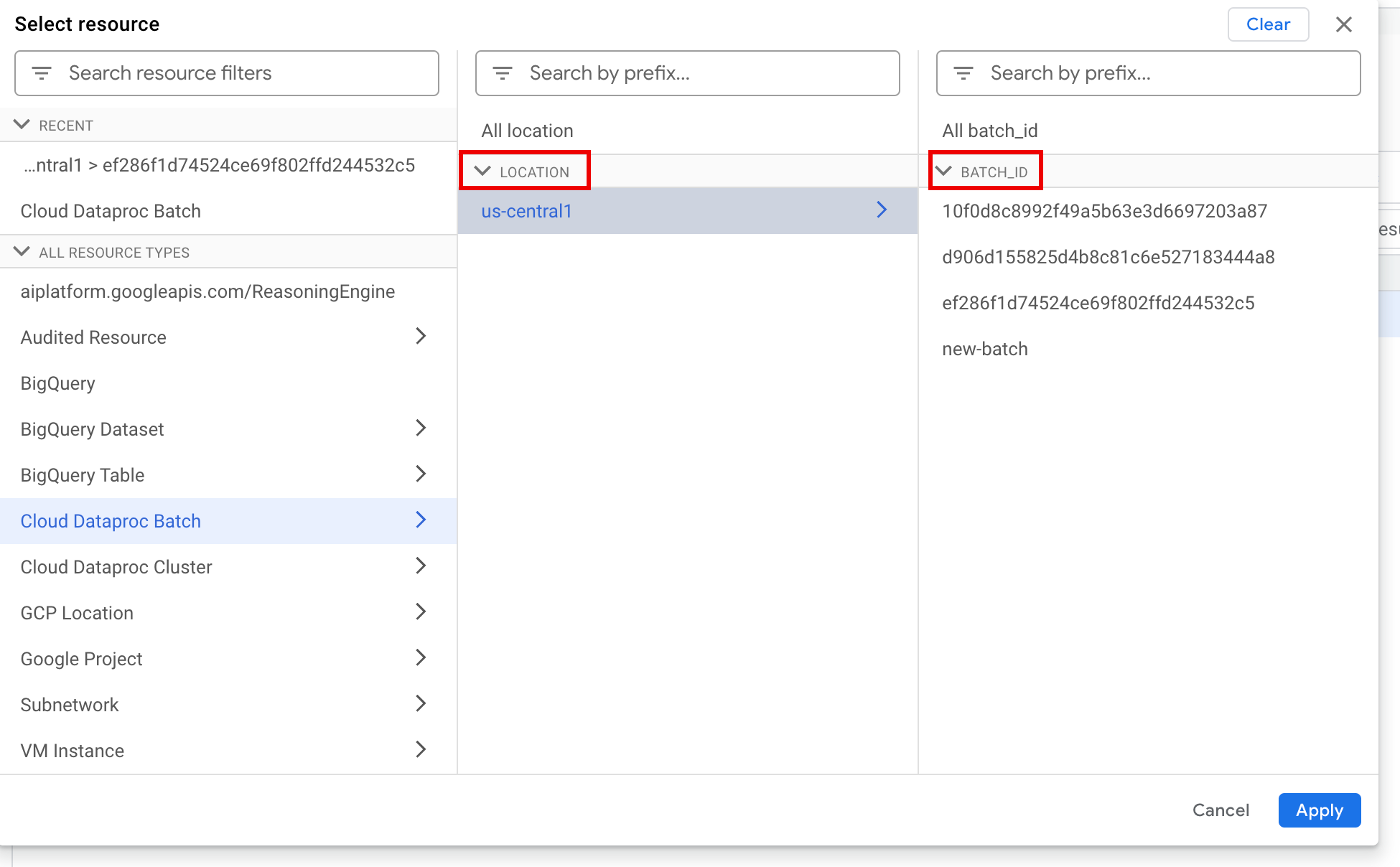
Clique em Aplicar.
Em Selecionar nomes de registos, introduza
dataproc.googleapis.comna caixa Pesquisar nomes de registos para limitar os tipos de registos a consultar. Selecione um ou mais dos nomes de ficheiros de registo apresentados.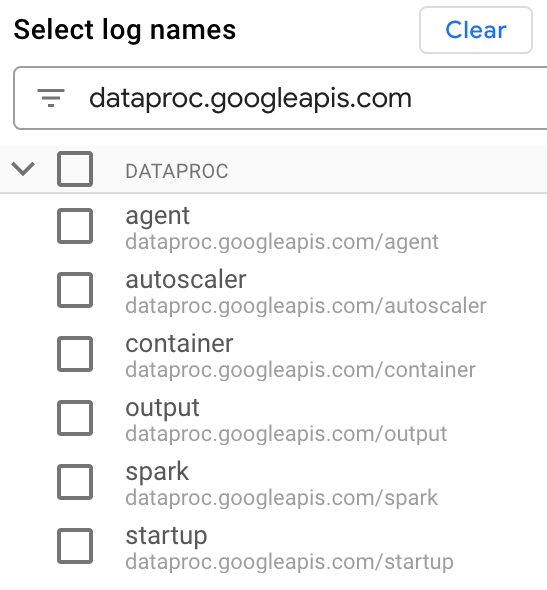
Use o editor de consultas para filtrar registos específicos da VM.
Especifique o tipo de recurso e o nome do recurso da VM, conforme mostrado no exemplo seguinte:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID: o UUID do lote está listado na página de detalhes do lote na consola, que é aberta quando clica no ID do lote na página Lotes. Google Cloud
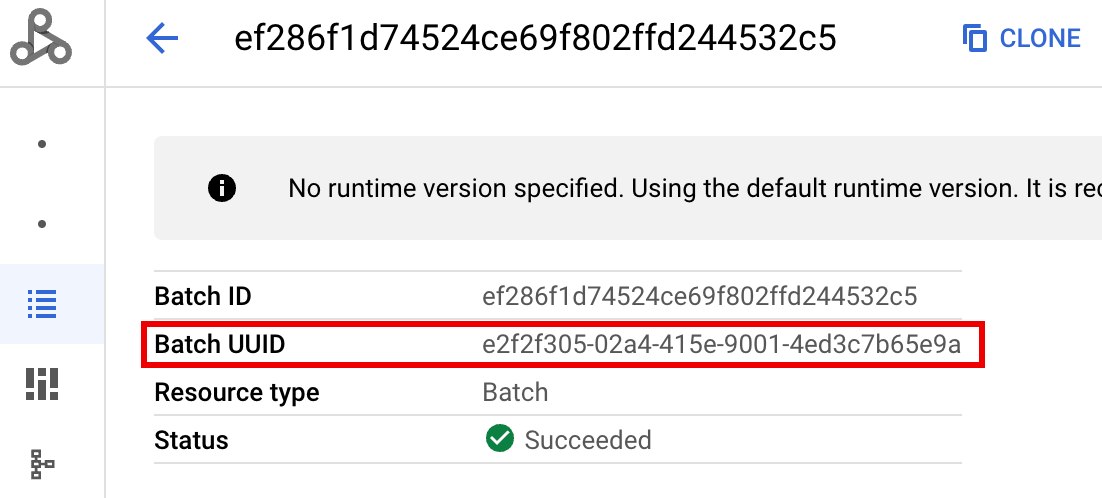
Os registos de lotes também indicam o UUID do lote no nome do recurso da VM. Segue-se um exemplo de um driver.log em lote:
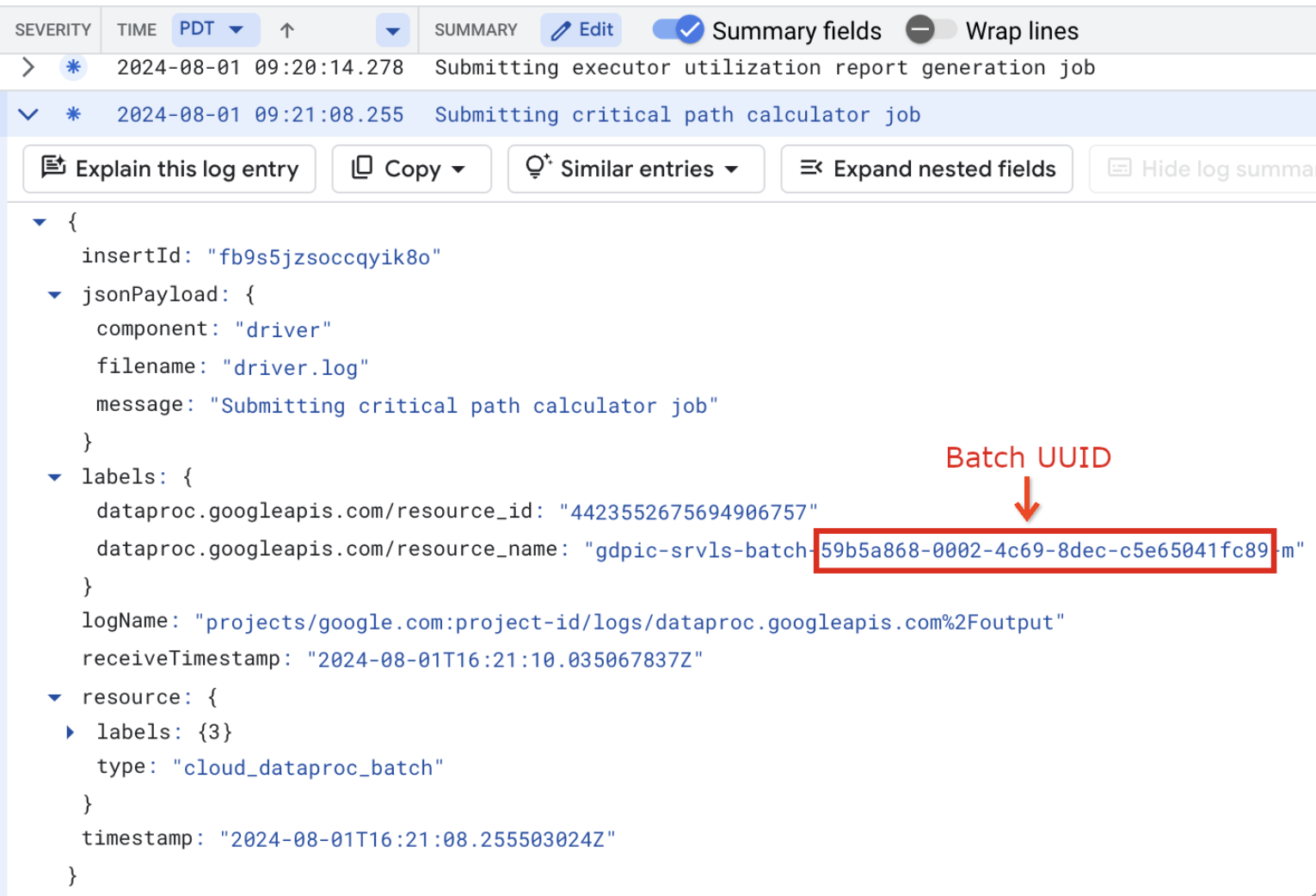
- BATCH_UUID: o UUID do lote está listado na página de detalhes do lote na consola, que é aberta quando clica no ID do lote na página Lotes. Google Cloud
Clique em Executar consulta.
Sem servidor para tipos de registos do Apache Spark e consultas de exemplo
A lista seguinte descreve os diferentes tipos de registos do Serverless para Apache Spark e fornece exemplos de consultas do Explorador de registos para cada tipo de registo.
dataproc.googleapis.com/output: este ficheiro de registo contém a saída da carga de trabalho em lote. O Serverless para Apache Spark transmite a saída em lote para o espaço de nomesoutpute define o nome do ficheiro comoJOB_ID.driver.log.Exemplo de consulta do Explorador de registos para registos de saída:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: o espaço de nomessparkagrega registos do Spark para daemons e executores em execução nas VMs principais e de trabalho do cluster do Dataproc. Cada entrada de registo inclui uma etiqueta de componentemaster,workerouexecutorpara identificar a origem do registo, da seguinte forma:executor: registos de executores de código do utilizador. Normalmente, trata-se de registos distribuídos.master: registos do mestre do gestor de recursos autónomo do Spark, que são semelhantes aos registos do YARN do Dataproc no Compute EngineResourceManager.worker: registos do trabalhador do gestor de recursos autónomo do Spark, que são semelhantes aos registos do YARN do Dataproc no Compute Engine.NodeManager
Exemplo de consulta do Explorador de registos para todos os registos no espaço de nomes
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Consulta de exemplo do Explorador de registos para registos de componentes autónomos do Spark no espaço de nomes
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: o espaço de nomesstartupinclui os registos de início do lote (cluster). Todos os registos de scripts de inicialização são incluídos. Os componentes são identificados por etiquetas, por exemplo:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: o espaço de nomesagentagrega os registos do agente do Dataproc. Cada entrada de registo inclui a etiqueta do nome do ficheiro que identifica a origem do registo.Exemplo de consulta do Explorador de registos para registos de agentes gerados por uma VM de trabalho especificada:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: o espaço de nomesautoscaleragrega os registos do escalador automático do Serverless para Apache Spark.Exemplo de consulta do Explorador de registos para registos de agentes gerados por uma VM de trabalho especificada:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Para mais informações, consulte os registos do Dataproc.
Para obter informações sobre os registos de auditoria do Serverless para Apache Spark, consulte o artigo Registo de auditoria do Dataproc.
Métricas de carga de trabalho
O Serverless para Apache Spark fornece métricas de lotes e do Spark que pode ver no Metrics Explorer ou na página Detalhes do lote na Google Cloud consola.
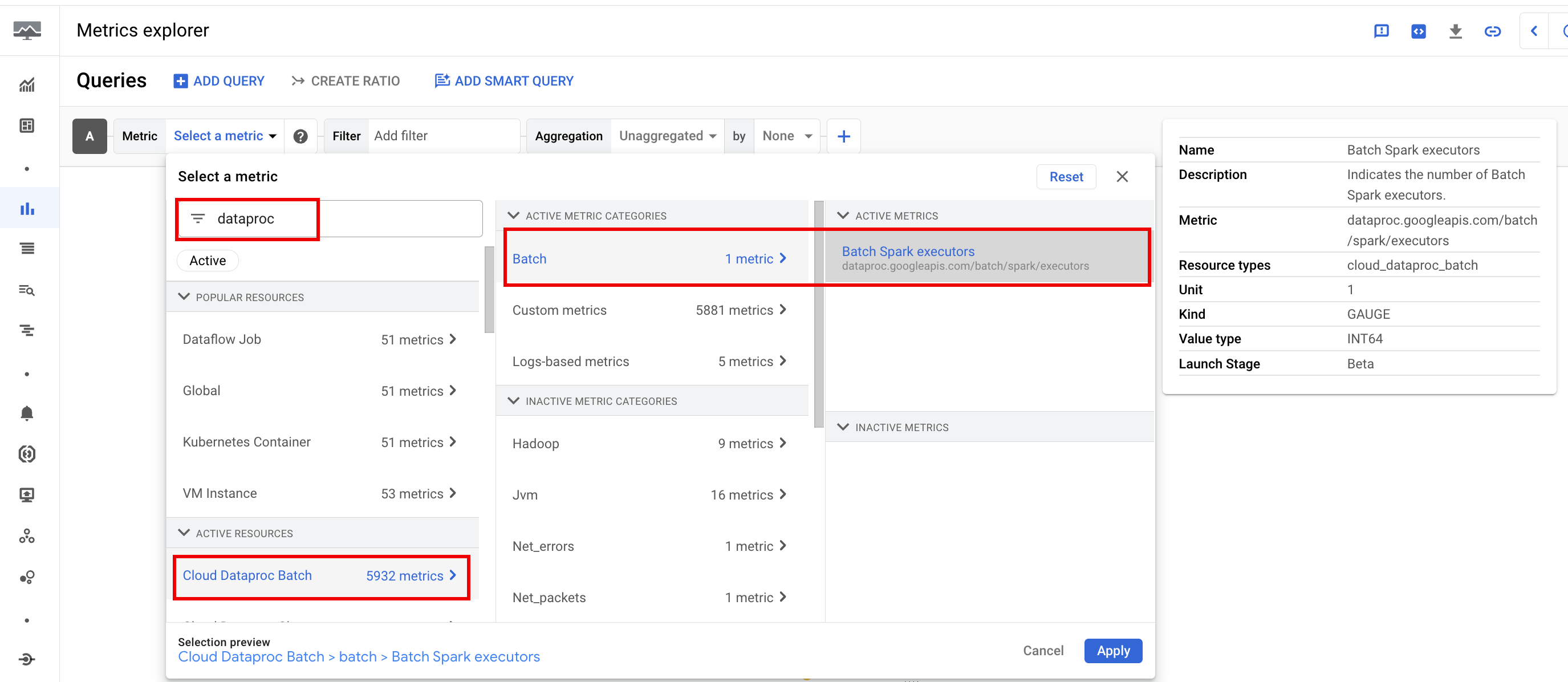
Métricas de lote
As métricas de recursos do Dataproc batch fornecem estatísticas sobre os recursos de processamento em lote, como o número de executores de processamento em lote. As métricas de lote têm o prefixo dataproc.googleapis.com/batch.
Métricas do Spark
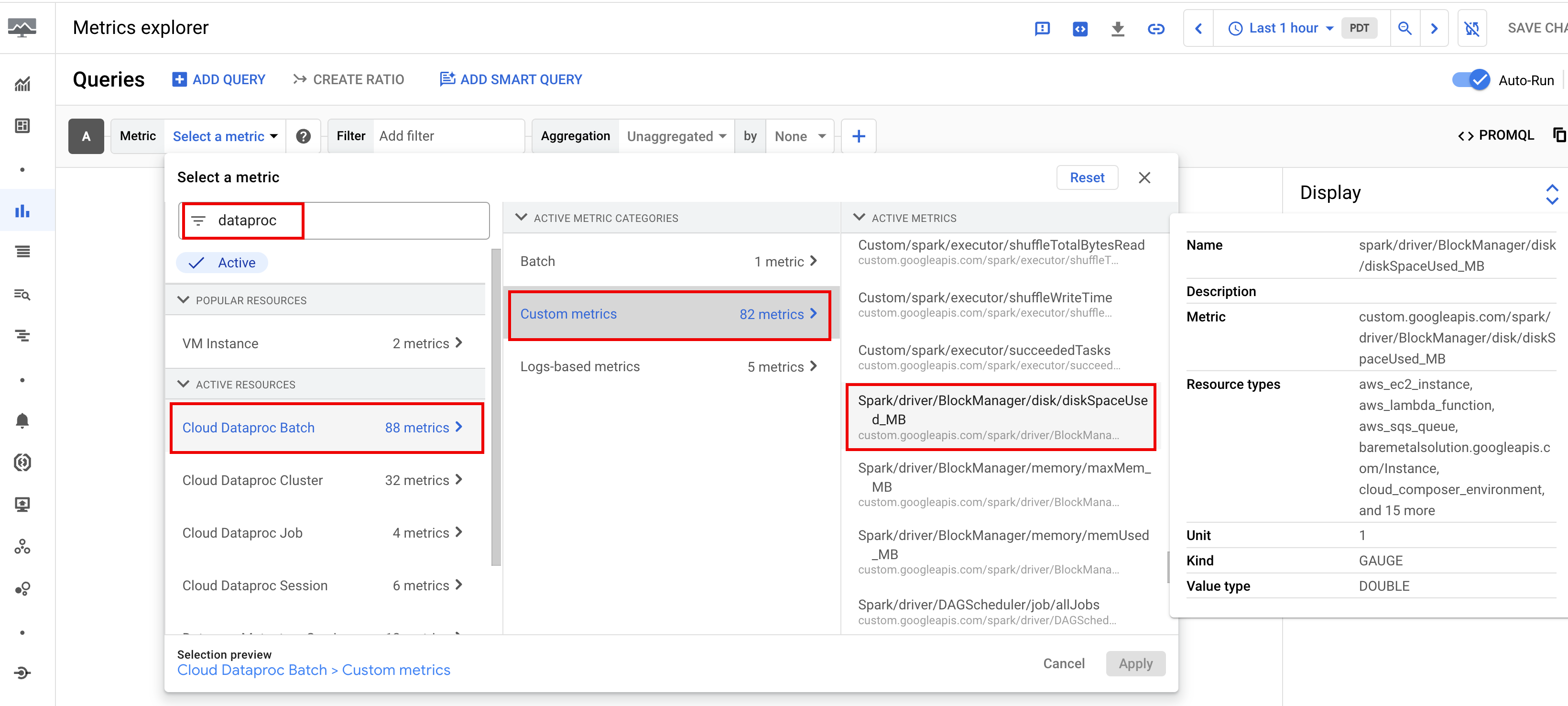
Por predefinição, o Serverless para Apache Spark ativa a recolha de métricas do Spark disponíveis, a menos que use propriedades de recolha de métricas do Spark para desativar ou substituir a recolha de uma ou mais métricas do Spark.
As métricas do Spark disponíveis
incluem métricas do controlador e do executor do Spark, bem como métricas do sistema. As métricas do Spark disponíveis têm o prefixo custom.googleapis.com/.
Configure alertas de métricas
Pode criar alertas de métricas do Dataproc para receber um aviso de problemas de carga de trabalho.
Crie gráficos
Pode criar gráficos que visualizam as métricas de carga de trabalho através do
Explorador de métricas na
Google Cloud consola. Por exemplo, pode criar um gráfico para apresentar disk:bytes_used e, em seguida, filtrar por batch_id.
Cloud Monitoring
A monitorização usa métricas e metadados de cargas de trabalho para fornecer estatísticas sobre o estado e o desempenho das cargas de trabalho sem servidor para o Apache Spark. As métricas de carga de trabalho incluem métricas do Spark, métricas de lotes e métricas de operações.
Pode usar o Cloud Monitoring na Google Cloud consola para explorar métricas, adicionar gráficos, criar painéis de controlo e criar alertas.
Crie painéis de controlo
Pode criar um painel de controlo para monitorizar cargas de trabalho através de métricas de vários projetos e diferentes produtos Google Cloud . Para mais informações, consulte o artigo Crie e faça a gestão de painéis de controlo personalizados.
Persistent History Server
O Serverless para Apache Spark cria os recursos de computação necessários para executar uma carga de trabalho, executa a carga de trabalho nesses recursos e, em seguida, elimina os recursos quando a carga de trabalho termina. As métricas e os eventos da carga de trabalho não persistem após a conclusão de uma carga de trabalho. No entanto, pode usar um servidor de histórico persistente (PHS) para reter o histórico de aplicações de cargas de trabalho (registos de eventos) no Cloud Storage.
Para usar um PHS com uma carga de trabalho em lote, faça o seguinte:
Crie um servidor de histórico persistente (PHS) do Dataproc.
Especifique o seu PHS quando enviar uma carga de trabalho.
Use o Component Gateway para estabelecer ligação ao PHS para ver detalhes da aplicação, fases do agendador, detalhes ao nível da tarefa e informações do ambiente e do executor.
Sintonização automática
- Ative a otimização automática para o Serverless for Apache Spark: pode ativar a otimização automática para o Serverless for Apache Spark quando envia cada carga de trabalho em lote do Spark recorrente através da Google Cloud consola, da CLI gcloud ou da API Dataproc.
Consola
Execute os passos seguintes para ativar a otimização automática em cada carga de trabalho em lote do Spark recorrente:
Na Google Cloud consola, aceda à página Batches do Dataproc.
Para criar uma carga de trabalho em lote, clique em Criar.
Na secção Recipiente, preencha o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A análise assistida pelo Gemini é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, especifique
TPCH-Query1como o nome da coorte para uma carga de trabalho agendada que executa uma consulta TPC-H diária.Preencha outras secções da página Criar lote, conforme necessário, e, de seguida, clique em Enviar. Para mais informações, consulte o artigo Envie uma carga de trabalho em lote.
gcloud
Execute o seguinte comando da CLI gcloud
gcloud dataproc batches submit
localmente numa janela de terminal ou no Cloud Shell
para ativar o ajuste automático em cada carga de trabalho em lote recorrente do Spark:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Substitua o seguinte:
- COMMAND: o tipo de carga de trabalho do Spark, como
Spark,PySpark,Spark-SqlouSpark-R. - REGION: a região onde a sua carga de trabalho vai ser executada.
- COHORT: o nome da coorte, que
identifica o lote como um de uma série de cargas de trabalho recorrentes.
A análise assistida pelo Gemini é aplicada à segunda e às cargas de trabalho subsequentes enviadas
com este nome de coorte. Por exemplo, especifique
TPCH Query 1como o nome da coorte para uma carga de trabalho agendada que executa uma consulta TPC-H diariamente.
API
Inclua o nome num pedido batches.create para ativar o ajuste automático em cada carga de trabalho recorrente do Spark.RuntimeConfig.cohort A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, especifique TPCH-Query1 como o nome da coorte para uma carga de trabalho agendada que executa uma consulta TPC-H diária.
Exemplo:
...
runtimeConfig:
cohort: TPCH-Query1
...