In diesem Dokument werden die Tools und Dateien beschrieben, die Sie zum Überwachen und Beheben von Fehlern bei Batch-Arbeitslasten von Serverless for Apache Spark verwenden können.
Fehlerbehebung bei Arbeitslasten über die Google Cloud Console
Wenn ein Batchjob fehlschlägt oder eine schlechte Leistung aufweist, sollten Sie als Erstes die Seite Batchdetails auf der Seite Batches in der Google Cloud Console öffnen.
Tab „Zusammenfassung“: Ihre zentrale Anlaufstelle für die Fehlerbehebung
Auf dem Tab Zusammenfassung, der standardmäßig geöffnet wird, wenn die Seite Batchdetails aufgerufen wird, sehen Sie wichtige Messwerte und gefilterte Logs, mit denen Sie den Batchstatus schnell einschätzen können. Nach dieser ersten Bewertung können Sie mit spezialisierten Tools auf der Seite Batchdetails eine detailliertere Analyse durchführen, z. B. mit der Spark-Benutzeroberfläche>, dem Logs Explorer und Gemini Cloud Assist.
Highlights von Batchmesswerten
Der Tab Zusammenfassung auf der Seite Batchdetails enthält Diagramme mit wichtigen Messwerten für Batcharbeitslasten. Die Messwertdiagramme werden nach Abschluss des Vorgangs gefüllt und bieten eine visuelle Darstellung potenzieller Probleme wie Ressourcenkonflikte, Datenabweichungen oder Speicherauslastung.
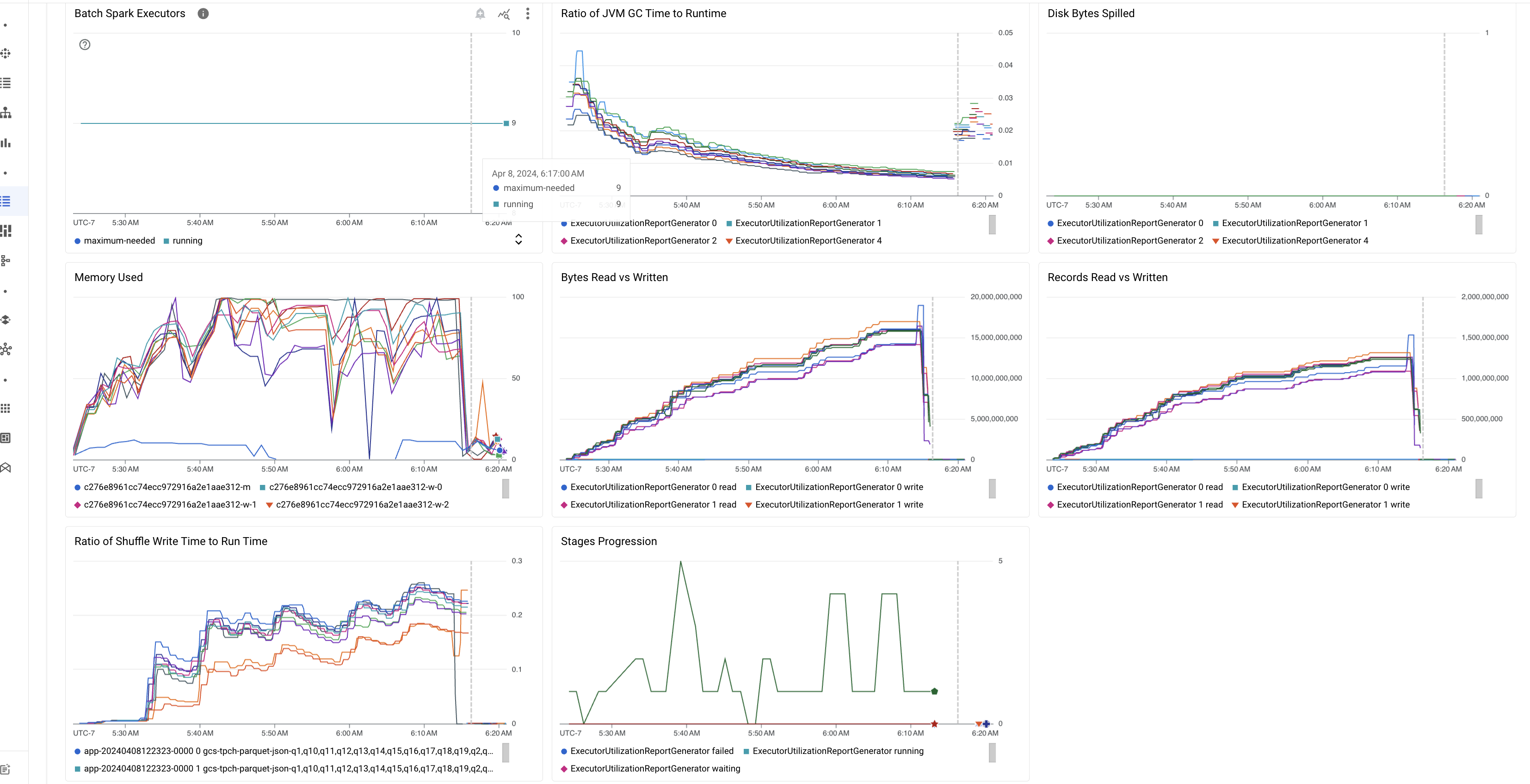
In der folgenden Tabelle sind die Spark-Arbeitslastmesswerte aufgeführt, die auf der Seite Batchdetails in der Google Cloud Console angezeigt werden. Außerdem wird beschrieben, wie Messwertwerte Aufschluss über den Arbeitslaststatus und die Leistung geben können.
| Messwert | Was wird angezeigt? |
|---|---|
| Messwerte auf Executor-Ebene | |
| Verhältnis von JVM-GC-Zeit zur Laufzeit | Dieser Messwert gibt das Verhältnis der JVM-GC-Zeit (Garbage Collection) zur Laufzeit pro Executor an. Hohe Raten können auf Speicherlecks in Aufgaben hinweisen, die auf bestimmten Executors ausgeführt werden, oder auf ineffiziente Datenstrukturen, die zu einem hohen Objekt-Churn führen können. |
| An Laufwerk übergebene Byte | Dieser Messwert gibt die Gesamtzahl der auf die Festplatte ausgelagerten Bytes für verschiedene Executors an. Wenn für einen Executor eine hohe Anzahl von auf die Festplatte ausgelagerten Byte angezeigt wird, kann dies auf eine Datenabweichung hindeuten. Wenn der Messwert im Laufe der Zeit steigt, kann dies auf Phasen mit Arbeitsspeicherdruck oder Arbeitsspeicherlecks hindeuten. |
| Gelesene und geschriebene Byte | Dieser Messwert zeigt die geschriebenen und gelesenen Bytes pro Executor. Große Abweichungen bei den gelesenen oder geschriebenen Bytes können darauf hindeuten, dass replizierte Joins zu einer Datenverstärkung auf bestimmten Executors führen. |
| Gelesene und geschriebene Datensätze | Dieser Messwert gibt die Anzahl der gelesenen und geschriebenen Datensätze pro Executor an. Eine große Anzahl gelesener Datensätze bei einer geringen Anzahl geschriebener Datensätze kann auf einen Engpass in der Verarbeitungslogik bestimmter Executors hinweisen, der dazu führt, dass Datensätze während des Wartens gelesen werden. Wenn Executors bei Lese- und Schreibvorgängen immer wieder hinterherhinken, kann das auf Ressourcenkonflikte auf diesen Knoten oder auf Executorspezifische Codeineffizienzen hinweisen. |
| Verhältnis von Shuffle-Schreibzeit zu Laufzeit | Der Messwert gibt an, wie viel Zeit der Executor im Vergleich zur Gesamtlaufzeit in der Shuffle-Laufzeit verbracht hat. Wenn dieser Wert für einige Executors hoch ist, kann das auf eine Datenabweichung oder eine ineffiziente Datenserialisierung hinweisen. In der Spark-Benutzeroberfläche können Sie Phasen mit langen Shuffle-Schreibzeiten identifizieren. Suchen Sie in diesen Phasen nach Ausreißeraufgaben, deren Ausführung länger als die durchschnittliche Zeit dauert. Prüfen Sie, ob bei den Executors mit hohen Shuffle-Schreibzeiten auch eine hohe Laufwerks-E/A-Aktivität zu beobachten ist. Eine effizientere Serialisierung und zusätzliche Partitionierungsschritte können helfen. Sehr große Schreibvorgänge im Vergleich zu Lesevorgängen können auf eine unbeabsichtigte Datenduplizierung aufgrund ineffizienter Joins oder falscher Transformationen hinweisen. |
| Messwerte auf Anwendungsebene | |
| Phasenfortschritt | Dieser Messwert gibt die Anzahl der Phasen in fehlgeschlagenen, wartenden und laufenden Phasen an. Eine große Anzahl fehlgeschlagener oder ausstehender Phasen kann auf eine Datenabweichung hinweisen. Prüfen Sie, ob Datenpartitionen vorhanden sind, und beheben Sie den Grund für den Fehler der Phase mithilfe des Tabs Stages in der Spark-UI. |
| Batch-Spark-Executors | Dieser Messwert gibt die Anzahl der Executors an, die möglicherweise erforderlich sind, im Vergleich zur Anzahl der ausgeführten Executors. Ein großer Unterschied zwischen erforderlichen und aktiven Executors kann auf Probleme mit der automatischen Skalierung hinweisen. |
| Messwerte auf VM-Ebene | |
| Verwendeter Arbeitsspeicher | Dieser Messwert gibt den Prozentsatz des verwendeten VM-Arbeitsspeichers an. Wenn der Master-Prozentsatz hoch ist, kann dies darauf hindeuten, dass der Treiber unter Arbeitsspeicherdruck steht. Bei anderen VM-Knoten kann ein hoher Prozentsatz darauf hindeuten, dass die Executors nicht mehr genügend Arbeitsspeicher haben. Dies kann zu einem hohen Disk-Spillage und einer langsameren Ausführung der Arbeitslast führen. Verwenden Sie die Spark-UI, um Executors zu analysieren und nach hoher GC-Zeit und vielen Taskfehlern zu suchen. Außerdem können Sie Spark-Code für das Caching großer Datasets und das unnötige Broadcasten von Variablen debuggen. |
Jobprotokolle
Die Seite Batchdetails enthält den Bereich Joblogs, in dem Warnungen und Fehler aus den Joblogs (Batcharbeitslast) aufgeführt sind. Mit dieser Funktion lassen sich kritische Probleme schnell erkennen, ohne dass umfangreiche Logdateien manuell analysiert werden müssen. Sie können im Drop-down-Menü einen Schweregrad für das Log auswählen (z. B. Error) und einen Textfilter hinzufügen, um die Ergebnisse einzugrenzen. Für eine detailliertere Analyse klicken Sie auf das Symbol Im Log-Explorer ansehen, um die ausgewählten Batchlogs im Log-Explorer zu öffnen.
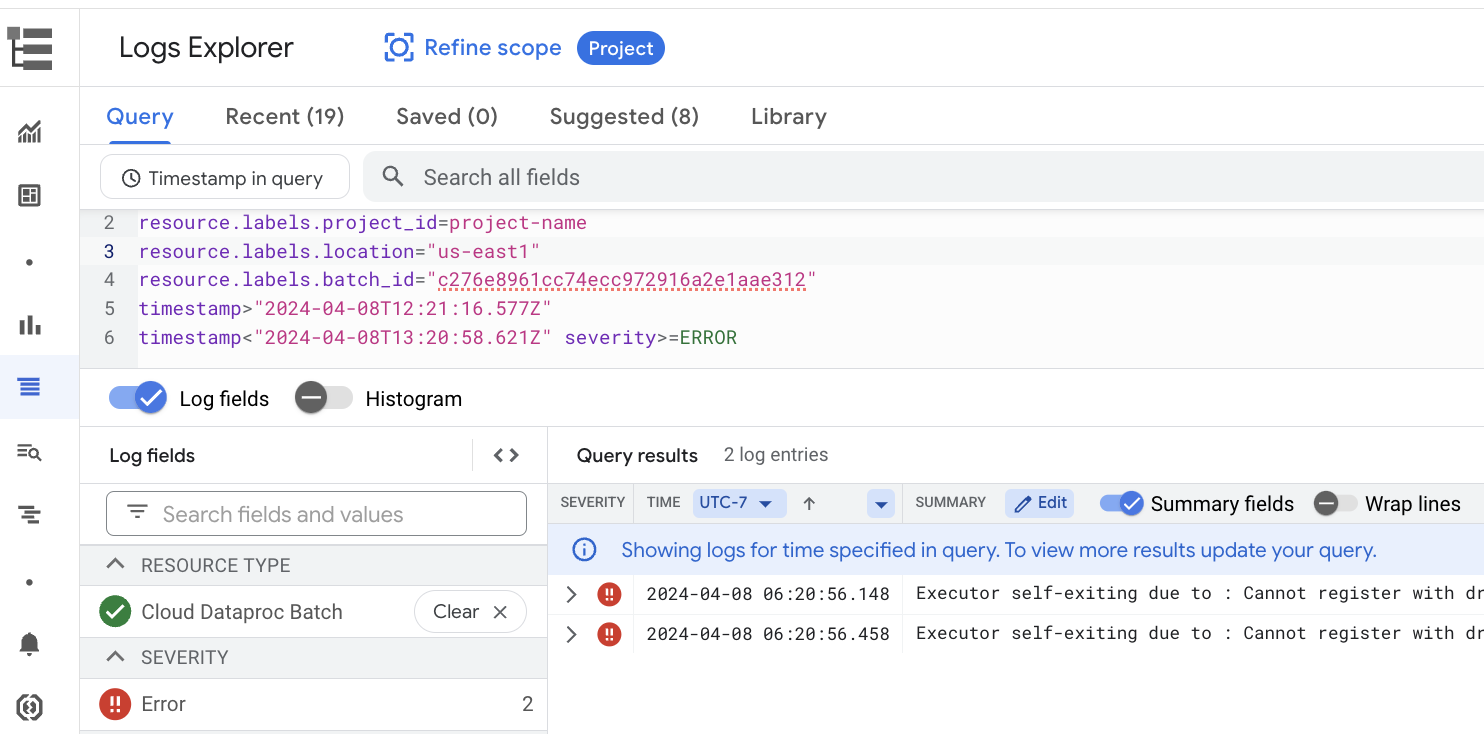
Beispiel: Der Log-Explorer wird geöffnet, nachdem Sie in der Google Cloud Console auf der Seite Batchdetails im Schweregrad-Selektor Errors ausgewählt haben.
Spark-UI
In der Spark-UI werden Apache Spark-Ausführungsdetails aus Serverless for Apache Spark-Batcharbeitslasten erfasst. Für die Spark-UI-Funktion, die standardmäßig aktiviert ist, fallen keine Gebühren an.
Von der Spark UI-Funktion erfasste Daten werden 90 Tage lang aufbewahrt. Mit dieser Weboberfläche können Sie Spark-Arbeitslasten überwachen und debuggen, ohne einen Persistent History Server erstellen zu müssen.
Erforderliche IAM-Berechtigungen und -Rollen (Identity and Access Management)
Die folgenden Berechtigungen sind erforderlich, um die Spark-UI-Funktion mit Batcharbeitslasten zu verwenden.
Berechtigung zur Datenerhebung:
dataproc.batches.sparkApplicationWrite. Diese Berechtigung muss dem Dienstkonto gewährt werden, mit dem Batcharbeitslasten ausgeführt werden. Diese Berechtigung ist in der RolleDataproc Workerenthalten, die dem Compute Engine-Standarddienstkonto, das standardmäßig von Serverless for Apache Spark verwendet wird, automatisch zugewiesen wird (siehe Dienstkonto für Serverless for Apache Spark). Wenn Sie jedoch ein benutzerdefiniertes Dienstkonto für Ihren Batch-Arbeitslast angeben, müssen Sie diesem Dienstkonto die Berechtigungdataproc.batches.sparkApplicationWritehinzufügen (in der Regel, indem Sie dem Dienstkonto die Dataproc-RolleWorkerzuweisen).Berechtigung für den Zugriff auf die Spark-UI:
dataproc.batches.sparkApplicationRead. Diese Berechtigung muss einem Nutzer gewährt werden, damit er in derGoogle Cloud -Konsole auf die Spark-UI zugreifen kann. Diese Berechtigung ist in den RollenDataproc Viewer,Dataproc EditorundDataproc Administratorenthalten. Wenn Sie die Spark-UI in der Google Cloud -Konsole öffnen möchten, benötigen Sie eine dieser Rollen oder eine benutzerdefinierte Rolle mit dieser Berechtigung.
Spark-UI öffnen
Die Seite „Spark UI“ ist in der Google Cloud Console für Batcharbeitslasten verfügbar.
Rufen Sie die Seite Serverless for Apache Spark interactive sessions auf.
Klicken Sie auf eine Batch-ID, um die Seite Batchdetails zu öffnen.
Klicken Sie im oberen Menü auf Spark-Benutzeroberfläche ansehen.
Die Schaltfläche Spark-UI ansehen ist in den folgenden Fällen deaktiviert:
- Wenn eine erforderliche Berechtigung nicht erteilt wird
- Wenn Sie das Häkchen bei Spark-UI aktivieren auf der Seite Batchdetails entfernen,
- Wenn Sie das Attribut
spark.dataproc.appContext.enabledauffalsesetzen, wenn Sie eine Batcharbeitslast einreichen
KI-basierte Untersuchungen mit Gemini Cloud Assist (Vorabversion)
Übersicht
Die Vorabversion der Funktion „Gemini Cloud Assist-Prüfungen“ nutzt die erweiterten Funktionen von Gemini, um Sie beim Erstellen und Ausführen von Serverless for Apache Spark-Batcharbeitslasten zu unterstützen. Mit dieser Funktion werden fehlgeschlagene und langsam ausgeführte Arbeitslasten analysiert, um Ursachen zu ermitteln und Korrekturen zu empfehlen. Es werden dauerhafte Analysen erstellt, die Sie sich ansehen, speichern und mit dem Google Cloud -Support teilen können, um die Zusammenarbeit zu erleichtern und die Problemlösung zu beschleunigen.
Features
Mit dieser Funktion können Sie Prüfungen über die Google Cloud -Konsole erstellen:
- Fügen Sie einem Problem eine Kontextbeschreibung in natürlicher Sprache hinzu, bevor Sie eine Untersuchung erstellen.
- Fehlerbehebung bei fehlgeschlagenen und langsamen Batcharbeitslasten
- Sie erhalten Informationen zu den Ursachen von Problemen und empfohlene Korrekturen.
- Erstellen Sie Google Cloud Supportanfragen mit dem vollständigen Kontext der Untersuchung.
Hinweise
Aktivieren Sie die Gemini Cloud Assist API in Ihrem Google Cloud -Projekt, um die Funktion „Prüfung“ zu verwenden.
Prüfungen starten
Führen Sie einen der folgenden Schritte aus, um eine Untersuchung zu starten:
Option 1: Rufen Sie in der Google Cloud Console die Seite „Batch-Liste“ auf. Für jeden Batch mit dem Status
Failedwird in der Spalte Statistiken von Gemini die Schaltfläche UNTERSUCHEN angezeigt. Klicken Sie auf die Schaltfläche, um eine Untersuchung zu starten.
Option 2: Öffnen Sie die Seite mit Batchdetails der Batcharbeitslast, die Sie untersuchen möchten. Sowohl für
Succeeded- als auch fürFailed-Batcharbeitslasten wird im Abschnitt Gesundheitsübersicht auf dem Tab Zusammenfassung im Bereich Insights by Gemini die Schaltfläche UNTERSUCHEN angezeigt. Klicken Sie auf die Schaltfläche, um eine Untersuchung zu starten.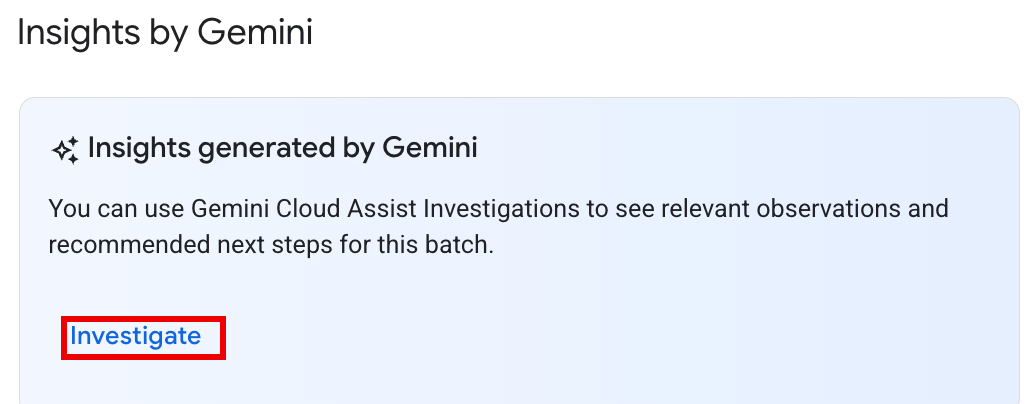
Der Text der Schaltfläche „Prüfen“ gibt den Status der Untersuchung an:
- UNTERSUCHEN:Für diese batch_details wurde keine Untersuchung durchgeführt. Klicken Sie auf die Schaltfläche, um eine Untersuchung zu starten.
- PRÜFUNG ANSEHEN:Eine Prüfung wurde abgeschlossen. Klicken Sie auf die Schaltfläche, um die Ergebnisse aufzurufen.
- WIRD UNTERSUCHT:Eine Untersuchung läuft.
Untersuchungsergebnisse interpretieren
Wenn eine Untersuchung abgeschlossen ist, wird die Seite Details zur Untersuchung geöffnet. Diese Seite enthält die vollständige Gemini-Analyse, die in die folgenden Abschnitte unterteilt ist:
- Problem: Ein minimierter Bereich mit automatisch ausgefüllten Details zur untersuchten Batcharbeitslast.
- Relevante Beobachtungen: Ein minimierter Abschnitt mit wichtigen Datenpunkten und Anomalien, die Gemini bei der Analyse von Logs und Messwerten gefunden hat.
- Hypothesen: Dies ist der primäre Bereich, der standardmäßig maximiert ist.
Es wird eine Liste mit möglichen Ursachen für das beobachtete Problem angezeigt. Jede Hypothese enthält Folgendes:
- Übersicht: Eine Beschreibung der möglichen Ursache, z. B. „Hohe Shuffle-Schreibzeit und potenzielle Aufgabenabweichung“.
- Empfohlene Korrekturen: Eine Liste mit umsetzbaren Schritten zur Behebung des potenziellen Problems.
Maßnahmen ergreifen
Nachdem Sie die Hypothesen und Empfehlungen geprüft haben:
Wenden Sie eine oder mehrere der vorgeschlagenen Korrekturen auf die Jobkonfiguration oder den Code an und führen Sie den Job dann noch einmal aus.
Sie können Feedback zur Nützlichkeit der Untersuchung geben, indem Sie oben im Bereich auf das Symbol „Mag ich“ oder „Mag ich nicht“ klicken.
Prüfungen prüfen und eskalieren
Die Ergebnisse einer zuvor ausgeführten Untersuchung können Sie auf der Seite Cloud Assist-Untersuchungen aufrufen. Klicken Sie dazu auf den Namen der Untersuchung, um die Seite Untersuchungsdetails zu öffnen.
Wenn Sie weitere Unterstützung benötigen, können Sie eine Supportanfrage für Google Cloud erstellen. So erhält der Supportmitarbeiter den vollständigen Kontext der zuvor durchgeführten Untersuchung, einschließlich der von Gemini generierten Beobachtungen und Hypothesen. Durch diesen Kontextaustausch wird die Kommunikation mit dem Supportteam erheblich reduziert und die Bearbeitung von Anfragen beschleunigt.
So erstellen Sie eine Supportanfrage aus einer Untersuchung:
Klicken Sie auf der Seite Untersuchungsdetails auf Support anfordern.
Status und Preise der Vorabversion
Für Gemini Cloud Assist-Prüfungen fallen während der öffentlichen Vorschau keine Gebühren an. Für die Funktion fallen Gebühren an, sobald sie allgemein verfügbar ist.
Weitere Informationen zu den Preisen nach der allgemeinen Verfügbarkeit finden Sie unter Preise für Gemini Cloud Assist.
Gemini Preview (wird am 22. September 2025 eingestellt)
Die Vorschaufunktion Gemini fragen bot über die Schaltfläche Gemini fragen mit nur einem Klick Zugriff auf Statistiken auf den Seiten Batches und Batchdetails in der Google Cloud Konsole. Diese Funktion hat eine Zusammenfassung von Fehlern, Anomalien und potenziellen Leistungsverbesserungen basierend auf Arbeitslastprotokollen und ‑messwerten erstellt.
Nachdem die Vorabversion von „Gemini fragen“ am 22. September 2025 eingestellt wurde, können Nutzer weiterhin KI-basierte Unterstützung über die Gemini Cloud Assist-Funktion „Untersuchungen“ erhalten.
Wichtig:Damit die KI-Unterstützung bei der Fehlerbehebung nicht unterbrochen wird, empfehlen wir dringend, Gemini Cloud Assist Investigations vor dem 22. September 2025 zu aktivieren.
Serverless for Apache Spark-Logs
Die Protokollierung ist in Serverless for Apache Spark standardmäßig aktiviert und Arbeitslastlogs bleiben nach Abschluss einer Arbeitslast erhalten. Serverless for Apache Spark erfasst Arbeitslastlogs in Cloud Logging.
Sie können auf Serverless for Apache Spark-Logs über die Ressource Cloud Dataproc Batch im Log-Explorer zugreifen.
Serverless for Apache Spark-Logs abfragen
Der Log-Explorer in der Google Cloud Console bietet einen Abfragebereich, mit dem Sie eine Abfrage erstellen können, um Batcharbeitslast-Logs zu untersuchen. So erstellen Sie eine Abfrage, um Batch-Arbeitslastprotokolle zu untersuchen:
- Ihr aktuelles Projekt ist ausgewählt. Sie können auf Projektbereich eingrenzen klicken, um ein anderes Projekt auszuwählen.
Batch-Protokollanfrage definieren
Verwenden Sie die Filtermenüs, um nach einer Batch-Arbeitslast zu filtern.
Wählen Sie unter Alle Ressourcen die Ressource Cloud Dataproc-Batch aus.
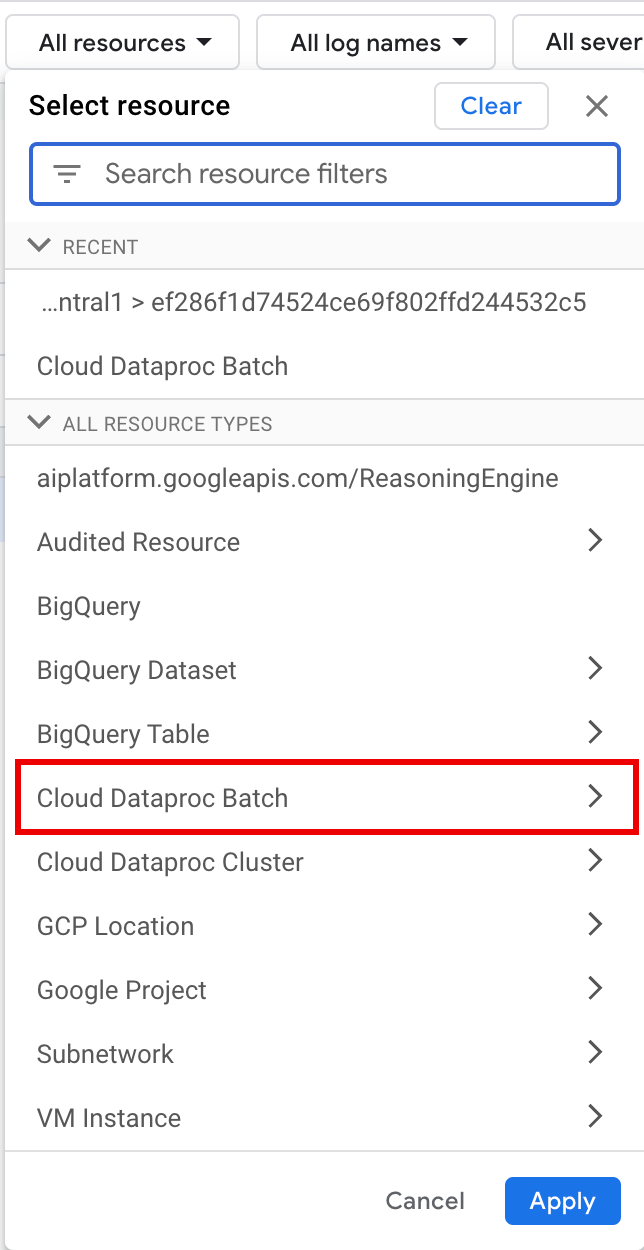
Wählen Sie im Bereich Ressource auswählen den Batch LOCATION und dann die BATCH ID aus. Diese Batchparameter werden in der Google Cloud Console auf der Dataproc-Seite Batches aufgeführt.
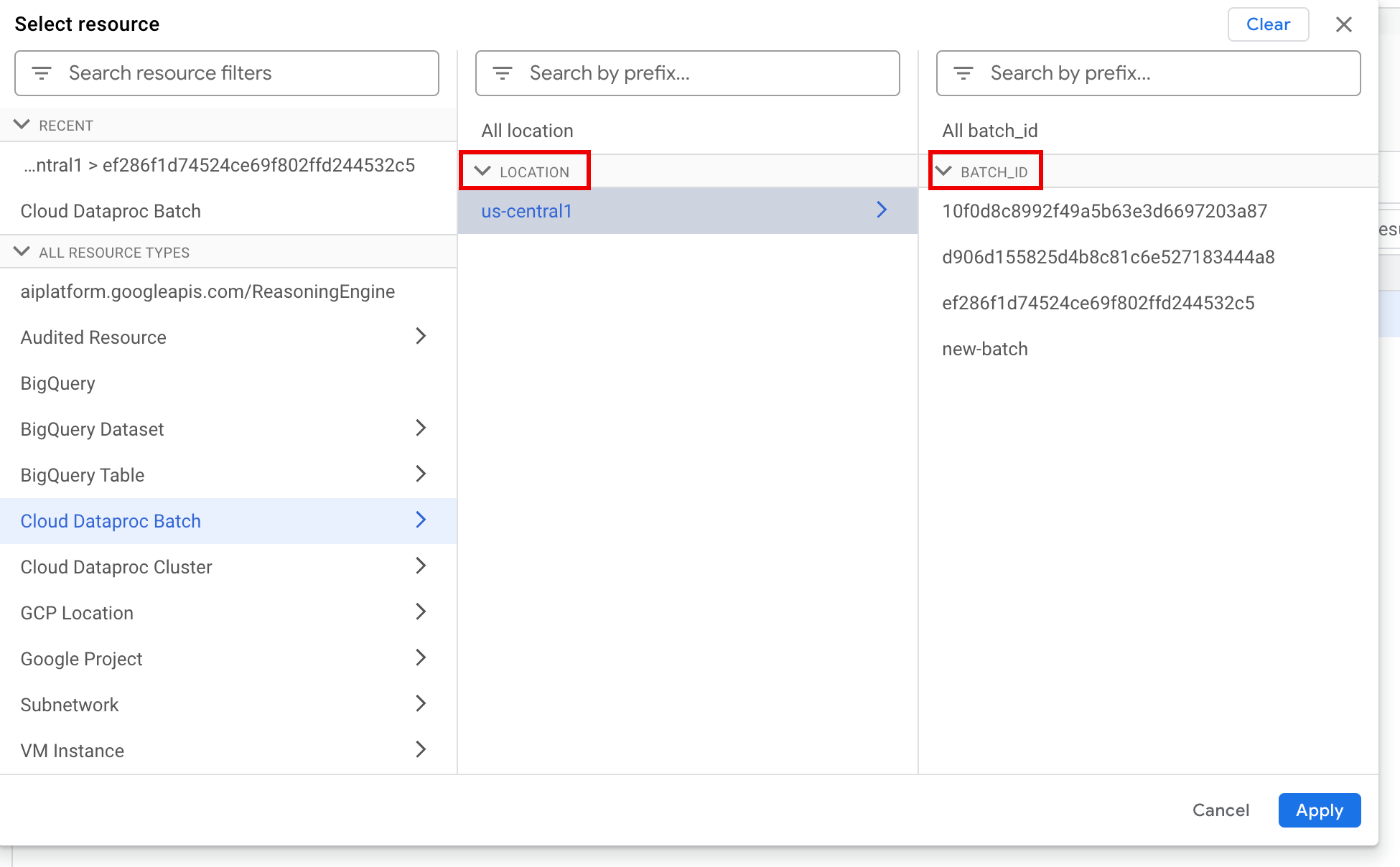
Klicken Sie auf Übernehmen.
Geben Sie unter Lognamen auswählen im Feld Lognamen durchsuchen
dataproc.googleapis.comein, um die abzufragenden Logtypen einzuschränken. Wählen Sie einen oder mehrere der aufgeführten Logdateinamen aus.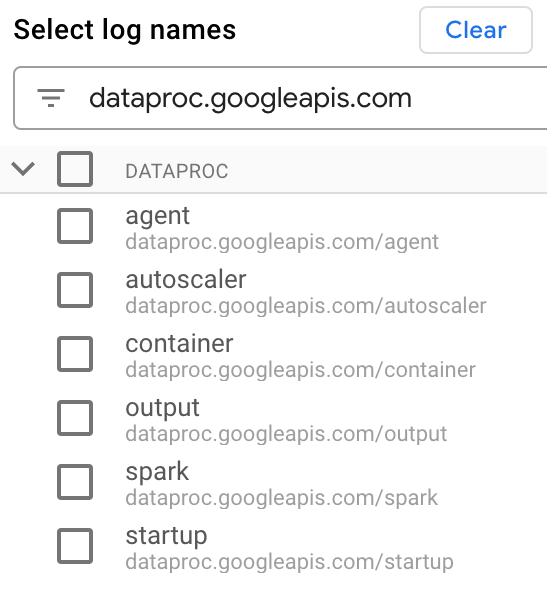
Verwenden Sie den Abfrageeditor, um nach VM-spezifischen Logs zu filtern.
Geben Sie den Ressourcentyp und den VM-Ressourcennamen wie im folgenden Beispiel an:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID:Die Batch-UUID wird auf der Seite „Batchdetails“ in der Google Cloud Console aufgeführt. Diese Seite wird geöffnet, wenn Sie auf der Seite Batches auf die Batch-ID klicken.
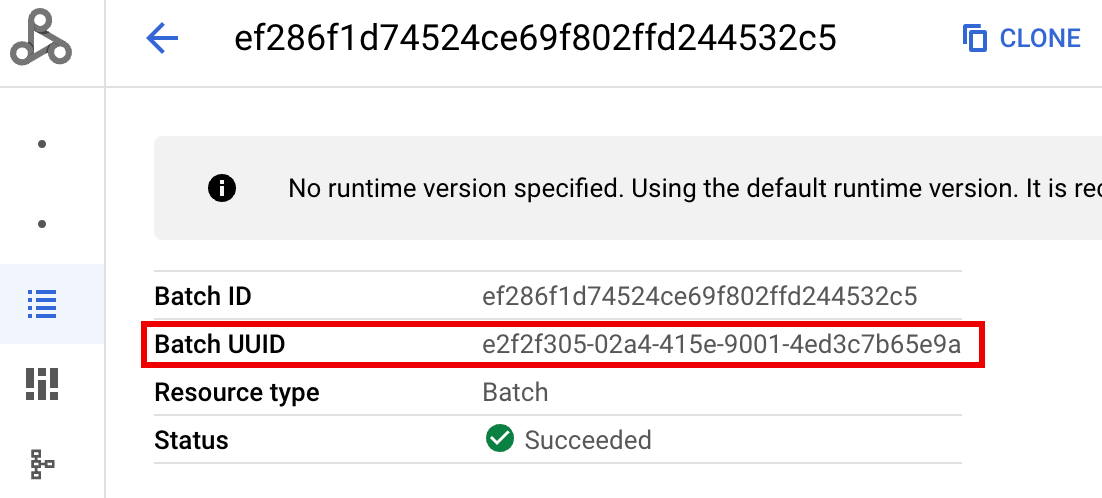
In den Batchlogs wird die Batch-UUID auch im VM-Ressourcennamen aufgeführt. Hier ein Beispiel aus einer batch-driver.log-Datei:
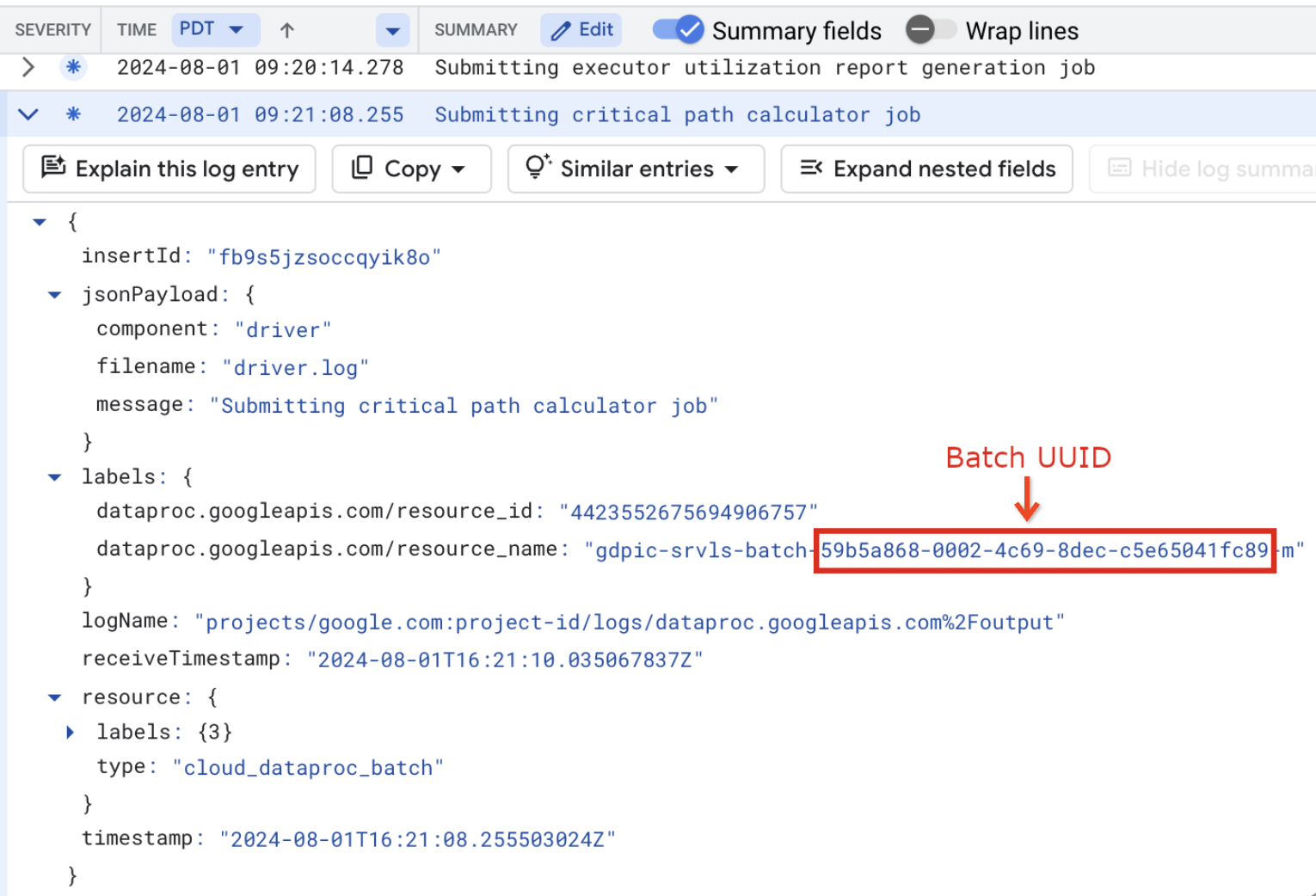
- BATCH_UUID:Die Batch-UUID wird auf der Seite „Batchdetails“ in der Google Cloud Console aufgeführt. Diese Seite wird geöffnet, wenn Sie auf der Seite Batches auf die Batch-ID klicken.
Klicken Sie auf Abfrage ausführen.
Serverless for Apache Spark-Logtypen und Beispielabfragen
In der folgenden Liste werden verschiedene Logtypen für Serverless for Apache Spark beschrieben und für jeden Logtyp werden Beispielabfragen für den Log-Explorer bereitgestellt.
dataproc.googleapis.com/output: Diese Logdatei enthält die Ausgabe von Batch-Workloads. Bei Serverless for Apache Spark wird die Batchausgabe in den Namespaceoutputgestreamt und der Dateiname aufJOB_ID.driver.logfestgelegt.Beispiel für eine Log-Explorer-Abfrage für Ausgabelogs:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: Im Namespacesparkwerden Spark-Logs für Daemons und Executors zusammengefasst, die auf Master- und Worker-VMs des Dataproc-Clusters ausgeführt werden. Jeder Logeintrag enthält ein Komponentenlabelmaster,workeroderexecutor, um die Logquelle zu identifizieren:executor: Protokolle von Ausführern von Nutzercode. In der Regel handelt es sich dabei um verteilte Logs.master: Logs vom Spark-Master des eigenständigen Ressourcenmanagers, die den YARN-ResourceManager-Logs von Dataproc in Compute Engine ähneln.worker: Logs vom Spark-Standalone-Ressourcenmanager-Worker, die den Dataproc-YARN-NodeManager-Logs in Compute Engine ähneln.
Beispiel für eine Logs-Explorer-Abfrage für alle Logs im Namespace
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Beispiel für eine Log-Explorer-Abfrage für Spark-Standalone-Komponentenlogs im Namespace
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: Der Namespacestartupenthält die Startlogs für Batch- (Cluster-)Jobs. Alle Initialisierungsskriptlogs sind enthalten. Komponenten werden anhand von Labels identifiziert, z. B.:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: Imagent-Namespace werden Dataproc-Agent-Logs zusammengefasst. Jeder Logeintrag enthält ein Dateinamenlabel, das die Logquelle identifiziert.Beispiel für eine Log-Explorer-Abfrage für Agent-Logs, die von einer bestimmten Worker-VM generiert wurden:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: Imautoscaler-Namespace werden Autoscaler-Logs für Serverless for Apache Spark zusammengefasst.Beispiel für eine Log-Explorer-Abfrage für Agent-Logs, die von einer bestimmten Worker-VM generiert wurden:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Weitere Informationen finden Sie unter Dataproc-Logs.
Informationen zu Audit-Logs für Serverless für Apache Spark finden Sie unter Dataproc-Audit-Logging.
Arbeitslastmesswerte
Serverless for Apache Spark bietet Batch- und Spark-Messwerte, die Sie in der Metrics Explorer oder auf der Seite Batchdetails in der Google Cloud Console aufrufen können.
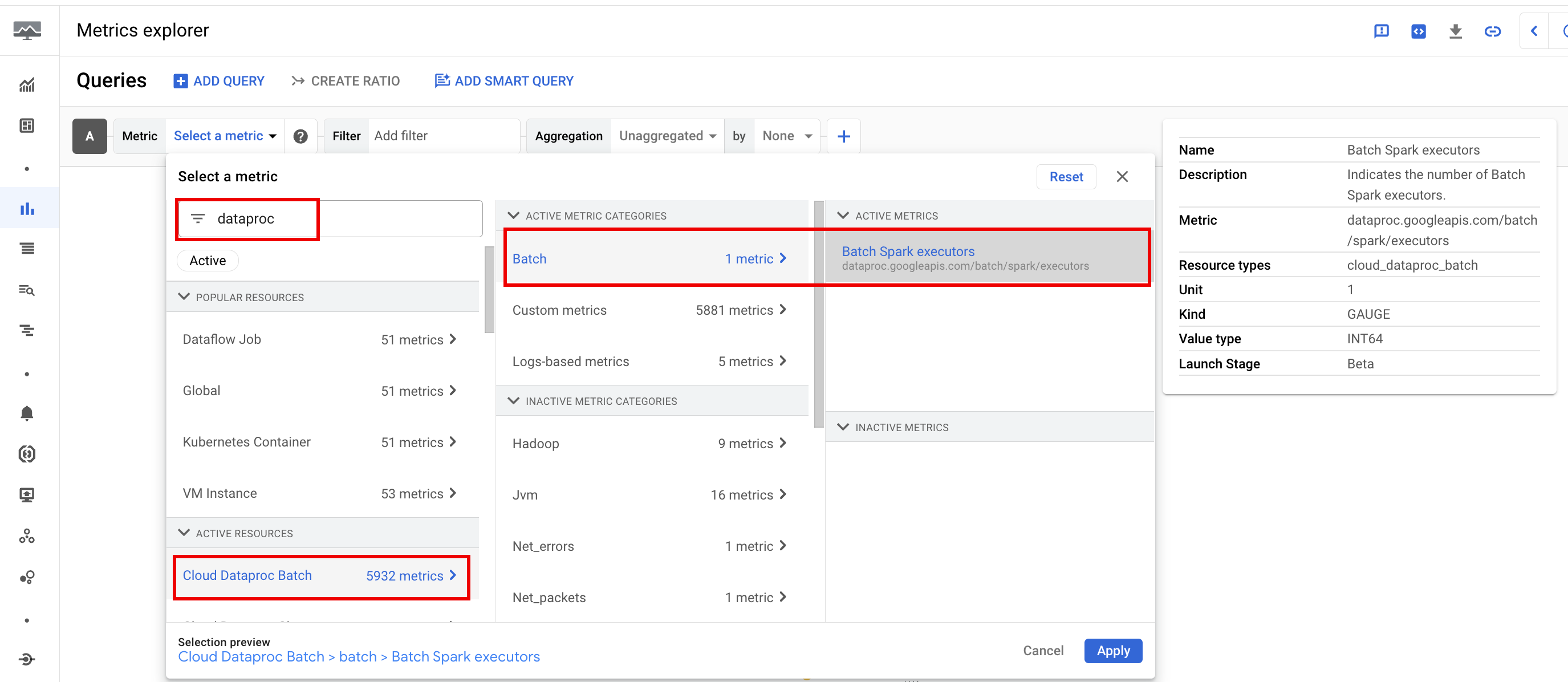
Batchmesswerte
Dataproc-batch-Ressourcenmesswerte geben Aufschluss über Batchressourcen wie die Anzahl der Batch-Executors. Batchmesswerte haben das Präfix dataproc.googleapis.com/batch.
Spark-Messwerte
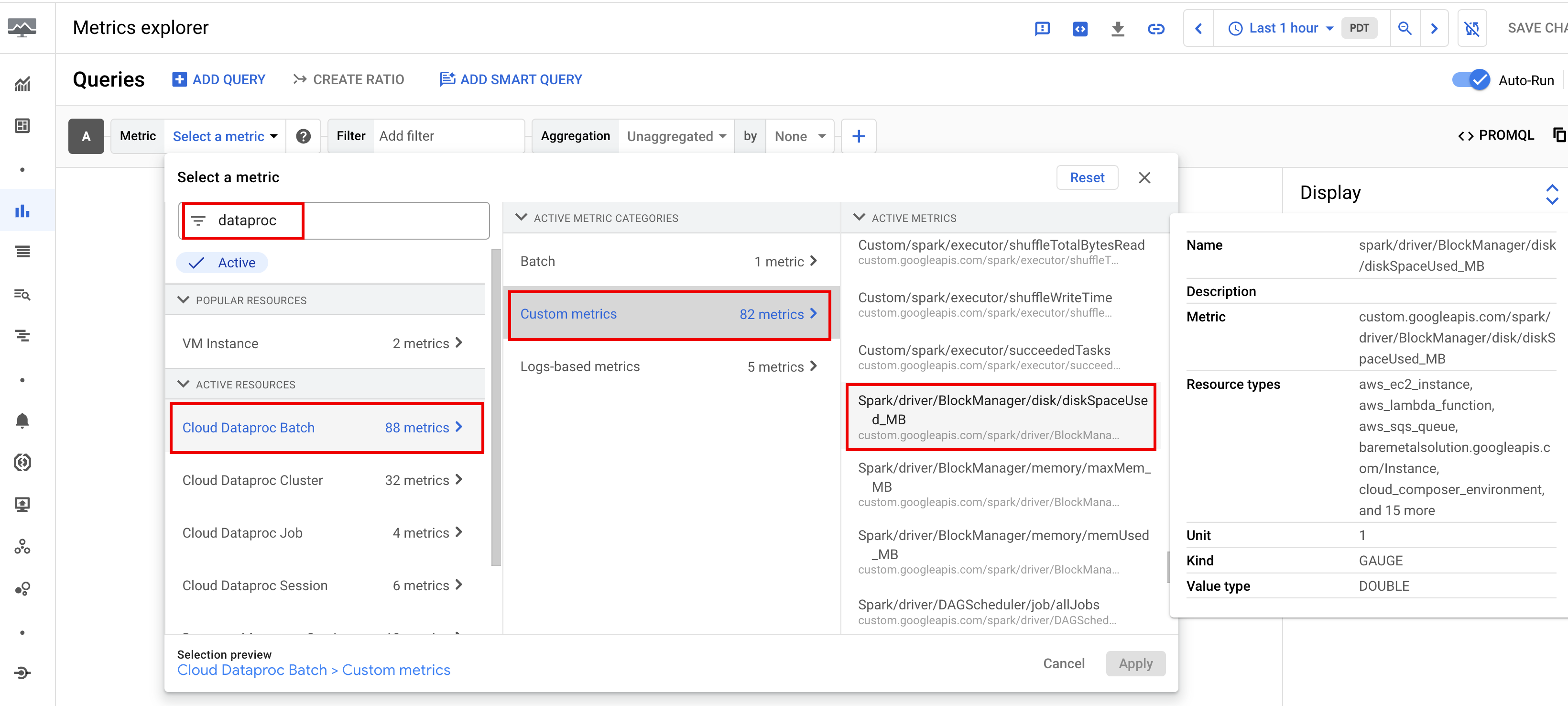
Standardmäßig werden mit Serverless for Apache Spark verfügbare Spark-Messwerte erfasst, sofern Sie nicht Eigenschaften für die Erfassung von Spark-Messwerten verwenden, um die Erfassung eines oder mehrerer Spark-Messwerte zu deaktivieren oder zu überschreiben.
Verfügbare Spark-Messwerte umfassen Spark-Treiber- und Executor-Messwerte sowie Systemmesswerte. Verfügbare Spark-Messwerte haben das Präfix custom.googleapis.com/.
Messwertbenachrichtigungen einrichten
Sie können Dataproc-Messwertbenachrichtigungen erstellen, um über Probleme mit Arbeitslasten informiert zu werden.
Diagramme erstellen
Mit dem Metrics Explorer in derGoogle Cloud -Konsole können Sie Diagramme erstellen, in denen Arbeitslastmesswerte visualisiert werden. Sie können beispielsweise ein Diagramm erstellen, in dem disk:bytes_used dargestellt wird, und dann nach batch_id filtern.
Cloud Monitoring
Monitoring verwendet Arbeitslastmetadaten und ‑messwerte, um Einblicke in den Zustand und die Leistung von Serverless for Apache Spark-Arbeitslasten zu geben. Zu den Arbeitslastmesswerten gehören Spark-Messwerte, Batchmesswerte und Vorgangsmesswerte.
Sie können Cloud Monitoring in der Google Cloud -Console verwenden, um Messwerte zu untersuchen, Diagramme hinzuzufügen, Dashboards zu erstellen und Benachrichtigungen zu erstellen.
Dashboards erstellen
Sie können ein Dashboard erstellen, um Arbeitslasten mithilfe von Messwerten aus mehreren Projekten und verschiedenen Google Cloud -Produkten zu überwachen. Weitere Informationen finden Sie unter Benutzerdefinierte Dashboards erstellen und verwalten.
Persistent History Server
Bei Serverless for Apache Spark werden die Rechenressourcen erstellt, die zum Ausführen einer Arbeitslast erforderlich sind. Die Arbeitslast wird auf diesen Ressourcen ausgeführt und die Ressourcen werden nach Abschluss der Arbeitslast gelöscht. Arbeitslastmesswerte und ‑ereignisse bleiben nach Abschluss einer Arbeitslast nicht erhalten. Sie können jedoch einen Persistent History Server (PHS) verwenden, um den Anwendungsverlauf von Arbeitslasten (Ereignisprotokolle) in Cloud Storage beizubehalten.
So verwenden Sie ein PHS mit einer Batch-Arbeitslast:
Geben Sie Ihr PHS an, wenn Sie eine Arbeitslast einreichen.
Verwenden Sie das Component Gateway, um eine Verbindung zum PHS herzustellen und Anwendungsdetails, Planungsphasen, Details auf Aufgabenebene sowie Informationen zu Umgebung und Executor aufzurufen.
Automatische Abstimmung
- Autotuning für Serverless for Apache Spark aktivieren:Sie können Autotuning für Serverless for Apache Spark aktivieren, wenn Sie jede wiederkehrende Spark-Batcharbeitslast über die Google Cloud Console, die gcloud CLI oder die Dataproc API senden.
Konsole
Führen Sie die folgenden Schritte aus, um die automatische Abstimmung für jeden wiederkehrenden Spark-Batch-Arbeitslast zu aktivieren:
Rufen Sie in der Google Cloud Console die Dataproc-Seite Batches auf.
Klicken Sie auf Erstellen, um einen Batch-Arbeitslast zu erstellen.
Geben Sie im Abschnitt Container den Namen der Kohorte ein, mit dem der Batch als eine von mehreren wiederkehrenden Arbeitslasten identifiziert wird. Die Gemini-basierte Analyse wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise
TPCH-Query1als Kohortennamen für eine geplante Arbeitslast an, die täglich eine TPC-H-Abfrage ausführt.Füllen Sie nach Bedarf die anderen Abschnitte der Seite Batch erstellen aus und klicken Sie dann auf Senden. Weitere Informationen finden Sie unter Batch-Arbeitslast einreichen.
gcloud
Führen Sie den folgenden gcloud CLI-Befehl gcloud dataproc batches submit lokal in einem Terminalfenster oder in Cloud Shell aus, um die automatische Optimierung für jede wiederkehrende Spark-Batcharbeitslast zu aktivieren:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Ersetzen Sie Folgendes:
- COMMAND: der Spark-Arbeitslasttyp, z. B.
Spark,PySpark,Spark-SqloderSpark-R. - REGION: die Region, in der Ihre Arbeitslast ausgeführt wird.
- COHORT: Der Kohortennamen, der den Batch als einen von einer Reihe wiederkehrender Arbeitslasten identifiziert.
Die Gemini-basierte Analyse wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise
TPCH Query 1als Kohortennamen für eine geplante Arbeitslast an, die täglich eine TPC-H-Abfrage ausführt.
API
Fügen Sie den Namen RuntimeConfig.cohort in eine batches.create-Anfrage ein, um die automatische Abstimmung für jede wiederkehrende Spark-Batcharbeitslast zu aktivieren. Die automatische Optimierung wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise TPCH-Query1 als Kohortennamen für eine geplante Arbeitslast an, die täglich eine TPC-H-Abfrage ausführt.
Beispiel:
...
runtimeConfig:
cohort: TPCH-Query1
...