本文提供自動調整 Spark 工作負載的相關資訊。由於 Spark 設定選項眾多,且難以評估這些選項對工作負載的影響,因此要針對效能和復原能力最佳化 Spark 工作負載可能相當困難。 Google Cloud Serverless for Apache Spark 自動調校功能可根據 Spark 最佳化做法和工作負載執行分析,自動將 Spark 設定套用至週期性 Spark 工作負載,取代手動設定工作負載。
註冊使用 Google Cloud Serverless for Apache Spark 自動調校功能
如要註冊存取本頁面所述的 Serverless for Apache Spark 自動調校預先發布版,請填寫並提交 Dataproc 預先發布版存取要求註冊表單。表單通過核准後,表單中列出的專案即可使用預先發布版功能。
優點
Google Cloud Serverless for Apache Spark 自動調整功能可帶來下列好處:
- 提升效能:調整最佳化設定,提高效能
- 加快最佳化速度:自動設定可避免耗時的手動設定測試
- 提升韌性:自動分配記憶體,避免發生記憶體相關故障
限制
Google Cloud Serverless for Apache Spark 自動調整功能有以下限制:
- 系統會計算自動調整結果,並套用至工作負載的第二次及後續執行。由於 Google Cloud Serverless for Apache Spark 自動調度資源功能會使用工作負載記錄進行最佳化,因此系統不會自動調校首次執行的週期性工作負載。
- 不支援縮減記憶體。
- 自動調整功能不會追溯套用至執行中的工作負載,只會套用至新提交的工作負載群組。
自動微調同類群組
自動調校功能會套用至批次工作負載的週期性執行作業,稱為「同類群組」。
提交工作負載時指定的同類群組名稱,會將該工作負載識別為週期性工作負載的後續執行作業之一。建議您使用可說明工作負載類型的同類群組名稱,或有助於識別工作負載執行作業的名稱,做為週期性工作負載的一部分。舉例來說,如果排定的工作負載會執行每日銷售匯總工作,請將群組名稱指定為 daily_sales_aggregation。
自動調整情境
如要將 Google Cloud Serverless for Apache Spark 自動調校功能套用至工作負載,請選取一或多個下列自動調校情境:
MEMORY:自動微調 Spark 記憶體分配,預測及避免潛在的工作負載記憶體不足錯誤。修正先前因記憶體不足 (OOM) 錯誤而失敗的工作負載。SCALING:自動微調 Spark 自動調度資源設定。BROADCAST_HASH_JOIN:自動調整 Spark 設定,以最佳化 SQL 廣播聯結效能。
定價
Google Cloud 在預先發布期間,Serverless for Apache Spark 自動調校功能免費提供。系統將以Google Cloud 標準 Serverless for Apache Spark 價格計費。
區域可用性
您可以在支援的 Compute Engine 區域中提交批次,並使用 Google Cloud Serverless for Apache Spark 自動調校功能。
使用 Google Cloud Serverless for Apache Spark 自動調校功能
您可以使用 Google Cloud 控制台、Google Cloud CLI 或 Dataproc API,在工作負載上啟用 Serverless for Apache Spark 自動調整功能。 Google Cloud
控制台
如要在每次提交週期性批次工作負載時啟用 Google Cloud Serverless for Apache Spark 自動調校功能,請執行下列步驟:
在 Google Cloud 控制台中,前往 Dataproc 的「Batches」(批次) 頁面。
如要建立批次工作負載,請按一下「建立」。
在「Container」(容器) 區段中,填寫 Spark 工作負載的下列欄位:
視需要填寫「建立批次」頁面的其他部分,然後按一下「提交」。如要進一步瞭解這些欄位,請參閱「提交批次工作負載」。
gcloud
如要在每次提交週期性批次工作負載時啟用 Google Cloud Serverless for Apache Spark 自動調校功能,請在本機終端機視窗或 Cloud Shell 中執行下列 gcloud CLI gcloud dataproc batches submit 指令。
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
更改下列內容:
- COMMAND:Spark 工作負載類型,例如
Spark、PySpark、Spark-Sql或Spark-R。 - REGION:工作負載執行的區域。
COHORT:同類群組名稱,用於將批次識別為一系列週期性工作負載之一。自動調整功能會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,如果排定的工作負載會執行每日銷售量匯總工作,請將
daily_sales_aggregation指定為同類群組名稱。SCENARIOS:以半形逗號分隔的一或多個自動調整情境,可用於最佳化工作負載,例如
--autotuning-scenarios=MEMORY,SCALING。每次提交批次同類群組時,您都可以變更情境清單。
API
如要在每次提交週期性批次工作負載時啟用 Google Cloud Serverless for Apache Spark 自動調校功能,請提交 batches.create 要求,並加入下列欄位:
RuntimeConfig.cohort:同類群組名稱,可將批次識別為一系列週期性工作負載之一。自動調整功能會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,如果排定的工作負載會執行每日銷售匯總工作,請將群組名稱指定為daily_sales_aggregation。AutotuningConfig.scenarios:一或多個自動調整情境,用於最佳化工作負載,例如BROADCAST_HASH_JOIN、MEMORY和SCALING。 每次提交批次同類群組時,您都可以變更情境清單。
範例:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
在試用這個範例之前,請先按照Java使用用戶端程式庫的 Apache Spark 無伺服器快速入門導覽課程中的設定說明操作。詳情請參閱 Serverless for Apache Spark Java API 參考說明文件。
如要向 Serverless for Apache Spark 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
如要在每次提交週期性批次工作負載時啟用 Google Cloud Serverless for Apache Spark 自動調校功能,請使用包含下列欄位的 CreateBatchRequest,呼叫 BatchControllerClient.createBatch:
Batch.RuntimeConfig.cohort:同類群組名稱,用於將批次識別為一系列週期性工作負載之一。自動調整功能會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,您可能會將daily_sales_aggregation指定為排定工作負載的同類群組名稱,該工作負載會執行每日銷售匯總工作。Batch.RuntimeConfig.AutotuningConfig.scenarios:一或多個自動調整情境,用於最佳化工作負載,例如BROADCAST_HASH_JOIN、MEMORY、SCALING。每次提交批次群組時,您都可以變更情境清單。 如需完整情境清單,請參閱 AutotuningConfig.Scenario Javadoc。
範例:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
如要使用 API,請務必使用 google-cloud-dataproc 用戶端程式庫 4.43.0 以上版本。您可以使用下列其中一種設定,將程式庫新增至專案。
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
在試用這個範例之前,請先按照Python使用用戶端程式庫的 Apache Spark 無伺服器快速入門導覽課程中的設定說明操作。詳情請參閱 Serverless for Apache Spark Python API 參考說明文件。
如要向 Serverless for Apache Spark 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
如要在每次提交週期性批次工作負載時啟用 Google Cloud Serverless for Apache Spark 自動調校功能,請使用包含下列欄位的 Batch,呼叫 BatchControllerClient.create_batch:
batch.runtime_config.cohort:同類群組名稱,用於將批次識別為一系列週期性工作負載之一。自動調整功能會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,您可能會將daily_sales_aggregation指定為排定工作負載的同類群組名稱,該工作負載會執行每日銷售匯總工作。batch.runtime_config.autotuning_config.scenarios:用於最佳化工作負載的一或多個自動調整情境,例如BROADCAST_HASH_JOIN、MEMORY、SCALING。您可以在每次提交批次同類群組時變更情境清單。如需完整情境清單,請參閱情境參考資料。
範例:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
如要使用 API,請務必使用 google-cloud-dataproc 用戶端程式庫 5.10.1 以上版本。如要將其新增至專案,請使用下列需求條件:
google-cloud-dataproc>=5.10.1
Airflow
如要在每次提交週期性批次工作負載時啟用 Google Cloud Serverless for Apache Spark 自動調校功能,請使用包含下列欄位的 Batch,呼叫 BatchControllerClient.create_batch:
batch.runtime_config.cohort:同類群組名稱,用於將批次識別為一系列週期性工作負載之一。自動調整功能會套用至以這個同類群組名稱提交的第二個和後續工作負載。舉例來說,您可能會將daily_sales_aggregation指定為排定工作負載的同類群組名稱,該工作負載會執行每日銷售匯總工作。batch.runtime_config.autotuning_config.scenarios:一或多個自動調整情境,用於最佳化工作負載,例如BROADCAST_HASH_JOIN、MEMORY、SCALING。您可以在每次提交批次同類群組時變更情境清單。如需完整情境清單,請參閱情境參考資料。
範例:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
如要使用 API,請務必使用 google-cloud-dataproc 用戶端程式庫 5.10.1 以上版本。您可以使用下列 Airflow 環境需求:
google-cloud-dataproc>=5.10.1
如要在 Cloud Composer 中更新套件,請參閱「為 Cloud Composer 安裝 Python 依附元件 」。
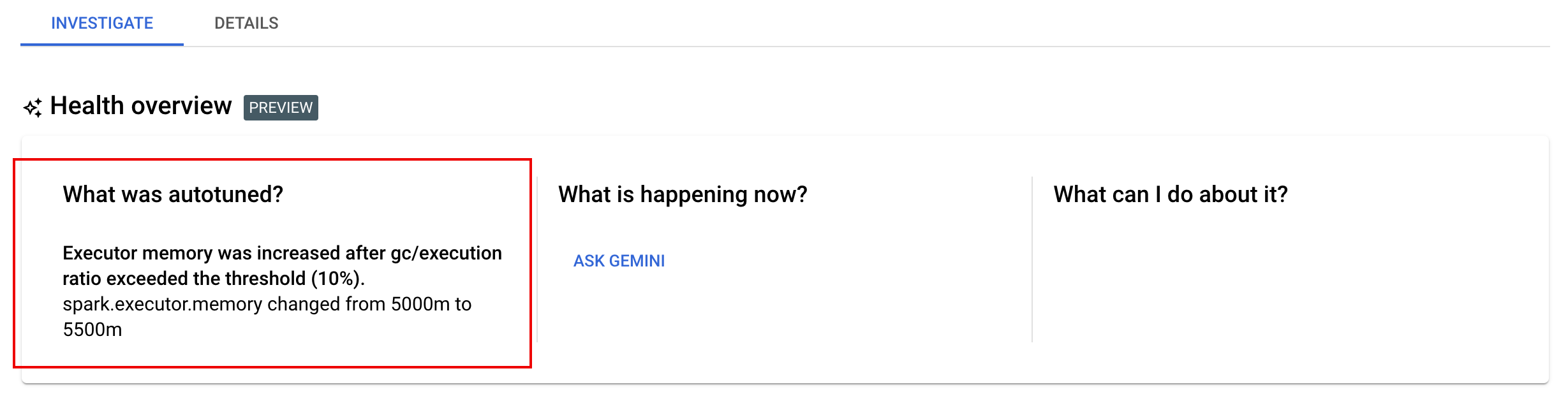
查看自動調整變更
如要查看 Google Cloud Serverless for Apache Spark 對批次工作負載的自動調整變更,請執行 gcloud dataproc batches describe 指令。
範例:gcloud dataproc batches describe 輸出內容會與下列內容相似:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
如要查看套用至執行中、已完成或失敗工作負載的最新自動調整變更,請前往 Google Cloud 控制台的「批次詳細資料」頁面,然後點選「調查」分頁。