Este documento fornece informações sobre a otimização automática de cargas de trabalho do Spark. A otimização de uma carga de trabalho do Spark para desempenho e resiliência pode ser desafiante devido ao número de opções de configuração do Spark e à dificuldade de avaliar o impacto dessas opções numa carga de trabalho.A otimização automática sem servidor para o Apache Spark oferece uma alternativa à configuração manual da carga de trabalho, aplicando automaticamente as definições de configuração do Spark a uma carga de trabalho recorrente do Spark com base nas práticas recomendadas de otimização do Spark e numa análise das execuções da carga de trabalho. Google Cloud
Inscreva-se no Google Cloud ajuste automático sem servidor para o Apache Spark
Para se inscrever no acesso à versão de pré-visualização da otimização automática do Serverless para Apache Spark descrita nesta página, preencha e envie o formulário de inscrição Pedido de acesso à pré-visualização do Dataproc. Depois de o formulário ser aprovado, os projetos indicados no formulário têm acesso às funcionalidades de pré-visualização.
Vantagens
Google Cloud A otimização automática sem servidor para o Apache Spark pode oferecer as seguintes vantagens:
- Desempenho melhorado: ajuste da otimização para aumentar o desempenho
- Otimização mais rápida: configuração automática para evitar testes de configuração manual demorados
- Maior capacidade de recuperação: alocação automática de memória para evitar falhas relacionadas com a memória
Limitações
Google Cloud A otimização automática sem servidor para o Apache Spark tem as seguintes limitações:
- A otimização automática é calculada e aplicada à segunda e às execuções subsequentes de uma carga de trabalho. A primeira execução de uma carga de trabalho recorrente não é otimizada automaticamente porque a otimização automática do Google Cloud Serverless for Apache Spark usa o histórico da carga de trabalho para otimização.
- A redução da memória não é suportada.
- A otimização automática não é aplicada retroativamente a cargas de trabalho em execução, apenas a coortes de cargas de trabalho enviadas recentemente.
Coortes de ajuste automático
A otimização automática é aplicada a execuções recorrentes de uma carga de trabalho em lote, denominadas coortes.
O nome da coorte que especifica quando envia uma carga de trabalho
identifica-a como uma das execuções sucessivas da carga de trabalho recorrente.
Recomendamos que use nomes de coortes que descrevam o tipo de carga de trabalho ou que ajudem a identificar as execuções de uma carga de trabalho como parte de uma carga de trabalho recorrente. Por exemplo, especifique daily_sales_aggregation como o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.
Cenários de ajuste automático
Aplica a otimização automática do Serverless for Apache Spark à sua carga de trabalho ao selecionar um ou mais dos seguintes cenários de otimização automática: Google Cloud
MEMORY: ajuste automático da atribuição de memória do Spark para prever e evitar potenciais erros de falta de memória da carga de trabalho. Corrija uma carga de trabalho com falhas anteriores devido a um erro de falta de memória (OOM).SCALING: ajuste automaticamente as definições de configuração do escalamento automático do Spark.BROADCAST_HASH_JOIN: Ajustar automaticamente as definições de configuração do Spark para otimizar o desempenho da junção de transmissão SQL.
Preços
Google Cloud A otimização automática sem servidor para o Apache Spark é oferecida durante a pré-visualização sem custos adicionais. Aplicam-se os Google Cloud preços do Apache Spark sem servidor padrão.
Disponibilidade regional
Pode usar a Google Cloud capacidade sem servidor para a otimização automática do Apache Spark com lotes enviados nas regiões do Compute Engine disponíveis.
Use a Google Cloud capacidade sem servidor para a otimização automática do Apache Spark
Pode ativar a otimização automática sem servidor para o Apache Spark numa carga de trabalho através da consola, da CLI Google Cloud ou da API Dataproc. Google Cloud Google Cloud
Consola
Para ativar a otimização automática do Apache Spark sem servidor em cada envio de uma carga de trabalho em lote recorrente, siga estes passos: Google Cloud
Na Google Cloud consola, aceda à página Batches do Dataproc.
Para criar uma carga de trabalho em lote, clique em Criar.
Na secção Contentor, preencha os seguintes campos para a sua carga de trabalho do Spark:
Coorte: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, especifique
daily_sales_aggregationcomo o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.Cenários de ajuste automático: um ou mais cenários de ajuste automático a usar para otimizar a carga de trabalho, por exemplo,
BROADCAST_HASH_JOIN,MEMORYeSCALING. Pode alterar a seleção de cenários com cada envio de coortes em lote.
Preencha outras secções da página Criar lote, conforme necessário, e, de seguida, clique em Enviar. Para mais informações sobre estes campos, consulte o artigo Envie uma carga de trabalho em lote.
gcloud
Para ativar a Google Cloud otimização automática sem servidor para o Apache Spark em cada envio
de uma carga de trabalho em lote recorrente, execute o seguinte comando da CLI gcloud
gcloud dataproc batches submit
localmente numa janela de terminal ou no
Cloud Shell.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Substitua o seguinte:
- COMMAND: o tipo de carga de trabalho do Spark, como
Spark,PySpark,Spark-SqlouSpark-R. - REGION: a região onde a sua carga de trabalho vai ser executada.
COHORT: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, especifique
daily_sales_aggregationcomo o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.SCENARIOS: um ou mais cenários de ajuste automático separados por vírgulas a usar para otimizar a carga de trabalho, por exemplo,
--autotuning-scenarios=MEMORY,SCALING. Pode alterar a lista de cenários com cada envio de coorte de lote.
API
Para ativar a otimização automática do Google Cloud Serverless for Apache Spark em cada envio de uma carga de trabalho em lote recorrente, envie um pedido batches.create que inclua os seguintes campos:
RuntimeConfig.cohort: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, especifiquedaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.AutotuningConfig.scenarios: um ou mais cenários de ajuste automático a usar para otimizar a carga de trabalho, por exemplo,BROADCAST_HASH_JOIN,MEMORYeSCALING. Pode alterar a lista de cenários com cada envio de coorte de lote.
Exemplo:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Antes de experimentar este exemplo, siga as Javainstruções de configuração no início rápido do Serverless para Apache Spark com bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Java Serverless para Apache Spark.
Para se autenticar no Serverless para Apache Spark, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Para ativar a otimização automática sem servidor para o Apache Spark em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.createBatch com um CreateBatchRequest que inclua os seguintes campos: Google Cloud
Batch.RuntimeConfig.cohort: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.Batch.RuntimeConfig.AutotuningConfig.scenarios: um ou mais cenários de ajuste automático a usar para otimizar a carga de trabalho, comoBROADCAST_HASH_JOIN,MEMORYeSCALING. Pode alterar a lista de cenários com cada envio de coorte de lote. Para ver a lista completa de cenários, consulte o Javadoc de AutotuningConfig.Scenario.
Exemplo:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Para usar a API, tem de usar a versão google-cloud-dataproc da biblioteca cliente 4.43.0 ou posterior. Pode usar uma das seguintes configurações para adicionar a biblioteca ao seu projeto.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Antes de experimentar este exemplo, siga as Pythoninstruções de configuração no início rápido do Serverless para Apache Spark com bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Python Serverless para Apache Spark.
Para se autenticar no Serverless para Apache Spark, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Para ativar a otimização automática sem servidor para o Apache Spark em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.create_batch com um Batch que inclua os seguintes campos: Google Cloud
batch.runtime_config.cohort: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.batch.runtime_config.autotuning_config.scenarios: Um ou mais cenários de ajuste automático a usar para otimizar a carga de trabalho, comoBROADCAST_HASH_JOIN,MEMORYeSCALING. Pode alterar a lista de cenários com cada envio de coorte de lotes. Para ver a lista completa de cenários, consulte a referência de cenários.
Exemplo:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Para usar a API, tem de usar a versão google-cloud-dataproc da biblioteca cliente 5.10.1 ou posterior. Para o adicionar ao seu projeto, pode usar o seguinte requisito:
google-cloud-dataproc>=5.10.1
Airflow
Para ativar a otimização automática sem servidor para o Apache Spark em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.create_batch com um Batch que inclua os seguintes campos: Google Cloud
batch.runtime_config.cohort: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. A otimização automática é aplicada à segunda e às cargas de trabalho subsequentes enviadas com este nome de coorte. Por exemplo, pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho agendada que executa uma tarefa de agregação de vendas diária.batch.runtime_config.autotuning_config.scenarios: Um ou mais cenários de ajuste automático a usar para otimizar a carga de trabalho, por exemplo,BROADCAST_HASH_JOIN,MEMORY,SCALING. Pode alterar a lista de cenários com cada envio de coorte em lote. Para ver a lista completa de cenários, consulte a referência de cenários.
Exemplo:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Para usar a API, tem de usar a versão google-cloud-dataproc da biblioteca cliente 5.10.1 ou posterior. Pode usar o seguinte requisito do ambiente do Airflow:
google-cloud-dataproc>=5.10.1
Para atualizar o pacote no Cloud Composer, consulte o artigo Instale dependências do Python para o Cloud Composer .
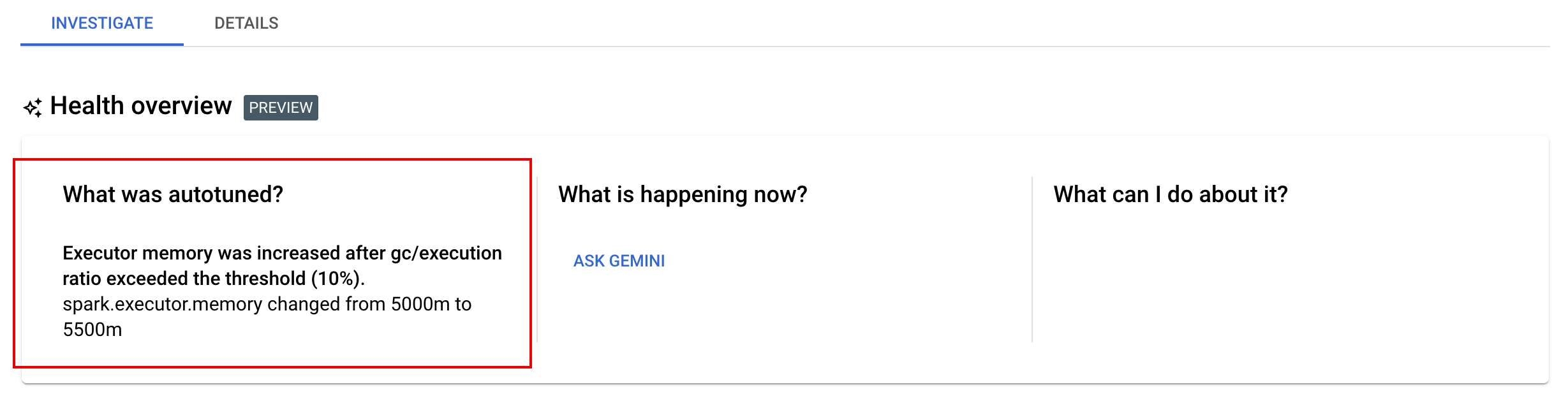
Veja alterações de otimização automática
Para ver as alterações de otimização automática do Serverless for Apache Spark a uma carga de trabalho em lote, execute o comando gcloud dataproc batches describe. Google Cloud
Exemplo: o resultado de gcloud dataproc batches describe é semelhante ao seguinte:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
Pode ver as alterações de ajuste automático mais recentes que foram aplicadas a uma carga de trabalho em execução, concluída ou com falhas na página Detalhes do lote na Google Cloud consola, no separador Investigar.