Dokumen ini memberikan informasi tentang penyesuaian otomatis beban kerja Spark. Mengoptimalkan workload Spark untuk performa dan ketahanan dapat menjadi tantangan karena jumlah opsi konfigurasi Spark dan kesulitan dalam menilai pengaruh opsi tersebut terhadap workload. Penyesuaian otomatis Dataproc Serverless memberikan alternatif ke konfigurasi workload manual dengan menerapkan setelan konfigurasi Spark secara otomatis ke workload Spark berulang berdasarkan praktik terbaik pengoptimalan Spark dan analisis pengoperasian workload.
Mendaftar ke penyesuaian otomatis Dataproc Serverless
Untuk mendaftar guna mendapatkan akses ke rilis pratinjau penyesuaian otomatis Dataproc Serverless yang dijelaskan di halaman ini, lengkapi dan kirimkan formulir pendaftaran Gemini di Pratinjau BigQuery. Setelah formulir disetujui, project yang tercantum dalam formulir akan memiliki akses ke fitur pratinjau.
Manfaat
Penyesuaian otomatis Dataproc Serverless dapat memberikan manfaat berikut:
- Performa yang lebih baik: Penyesuaian pengoptimalan untuk meningkatkan performa
- Pengoptimalan yang lebih cepat: Konfigurasi otomatis untuk menghindari pengujian konfigurasi manual yang memakan waktu
- Peningkatan ketahanan: Alokasi memori otomatis untuk menghindari kegagalan terkait memori
Batasan
Penyesuaian otomatis Dataproc Serverless memiliki batasan berikut:
- Penyesuaian otomatis dihitung dan diterapkan ke operasi kedua dan selanjutnya dari beban kerja. Pengaktifan pertama workload berulang tidak dioptimalkan secara otomatis karena pengoptimalan otomatis Dataproc Serverless menggunakan histori workload untuk pengoptimalan.
- Penyingkasan memori tidak didukung.
- Penyesuaian otomatis tidak diterapkan secara surut ke workload yang sedang berjalan, hanya ke kelompok workload yang baru dikirim.
Kohor penyesuaian otomatis
Penyesuaian otomatis diterapkan ke eksekusi berulang beban kerja batch, yang disebut kohor.
Nama kelompok yang Anda tentukan saat mengirimkan workload
mengidentifikasinya sebagai salah satu operasi berulang dari workload berulang.
Sebaiknya gunakan nama kelompok yang mendeskripsikan jenis
workload atau yang membantu mengidentifikasi operasi workload sebagai bagian
dari workload berulang. Misalnya, tentukan daily_sales_aggregation sebagai
nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.
Skenario penyesuaian otomatis
Anda menerapkan penyesuaian otomatis Dataproc Serverless ke workload dengan memilih satu atau beberapa skenario penyesuaian otomatis berikut:
MEMORY: Menyesuaikan otomatis alokasi memori Spark untuk memprediksi dan menghindari potensi error kehabisan memori beban kerja. Memperbaiki beban kerja yang sebelumnya gagal karena error memori habis (OOM).SCALING: Menyesuaikan setelan konfigurasi penskalaan otomatis Spark secara otomatis.BROADCAST_HASH_JOIN: Menyesuaikan setelan konfigurasi Spark secara otomatis untuk mengoptimalkan performa join siaran SQL.
Harga
Penyesuaian otomatis Dataproc Serverless ditawarkan selama pratinjau tanpa biaya tambahan. Harga Dataproc Serverless standar berlaku.
Ketersediaan regional
Anda dapat menggunakan penyesuaian otomatis Dataproc Serverless dengan batch yang dikirimkan di region Compute Engine yang tersedia.
Menggunakan penyesuaian otomatis Dataproc Serverless
Anda dapat mengaktifkan penyesuaian otomatis Dataproc Serverless pada beban kerja menggunakan konsol Google Cloud, Google Cloud CLI, atau Dataproc API.
Konsol
Untuk mengaktifkan penyesuaian otomatis Dataproc Serverless pada setiap pengiriman workload batch berulang, lakukan langkah-langkah berikut:
Di konsol Google Cloud, buka halaman Batches Dataproc.
Untuk membuat beban kerja batch, klik Buat.
Di bagian Container, isi kolom berikut untuk workload Spark Anda:
Kohor: nama kohor, yang mengidentifikasi batch sebagai salah satu dari serangkaian workload berulang. Penyesuaian otomatis diterapkan ke beban kerja kedua dan berikutnya yang dikirimkan dengan nama kelompok ini. Misalnya, tentukan
daily_sales_aggregationsebagai nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.Skenario penyesuaian otomatis: satu atau beberapa skenario penyesuaian otomatis yang akan digunakan untuk mengoptimalkan beban kerja, misalnya,
BROADCAST_HASH_JOIN,MEMORY, danSCALING. Anda dapat mengubah pilihan skenario dengan setiap pengiriman kelompok batch.
Isi bagian lain di halaman Create batch sesuai kebutuhan, lalu klik Submit. Untuk informasi selengkapnya tentang kolom ini, lihat Mengirimkan workload batch.
gcloud
Untuk mengaktifkan penyesuaian otomatis Dataproc Serverless pada setiap pengiriman workload batch berulang, jalankan perintah gcloud dataproc batches submit gcloud CLI berikut secara lokal di jendela terminal atau di Cloud Shell.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Ganti kode berikut:
- COMMAND: jenis beban kerja Spark, seperti
Spark,PySpark,Spark-Sql, atauSpark-R. - REGION: region tempat workload Anda akan berjalan.
COHORT: nama kohor, yang mengidentifikasi batch sebagai salah satu dari serangkaian beban kerja berulang. Penyesuaian otomatis diterapkan ke beban kerja kedua dan berikutnya yang dikirimkan dengan nama kelompok ini. Misalnya, tentukan
daily_sales_aggregationsebagai nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.SCENARIOS: satu atau beberapa skenario penyesuaian otomatis yang dipisahkan koma untuk digunakan guna mengoptimalkan beban kerja, misalnya,
--autotuning-scenarios=MEMORY,SCALING. Anda dapat mengubah daftar skenario dengan setiap pengiriman kelompok batch.
API
Untuk mengaktifkan penyesuaian otomatis Dataproc Serverless pada setiap pengiriman workload batch berulang, kirim permintaan batches.create yang menyertakan kolom berikut:
RuntimeConfig.cohort: nama kohor, yang mengidentifikasi batch sebagai salah satu dari serangkaian beban kerja berulang. Penyesuaian otomatis diterapkan ke workload kedua dan berikutnya yang dikirimkan dengan nama kelompok ini. Misalnya, tentukandaily_sales_aggregationsebagai nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.AutotuningConfig.scenarios: satu atau beberapa skenario penyesuaian otomatis yang akan digunakan untuk mengoptimalkan beban kerja, misalnya,BROADCAST_HASH_JOIN,MEMORY, danSCALING. Anda dapat mengubah daftar skenario dengan setiap pengiriman kelompok batch.
Contoh:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Java di panduan memulai Dataproc Serverless menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Java Dataproc Serverless.
Untuk melakukan autentikasi ke Dataproc Serverless, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Untuk mengaktifkan penyesuaian otomatis Dataproc Serverless pada setiap pengiriman workload batch berulang, panggil BatchControllerClient.createBatch dengan CreateBatchRequest yang menyertakan kolom berikut:
Batch.RuntimeConfig.cohort: Nama kohor, yang mengidentifikasi batch sebagai salah satu dari serangkaian beban kerja berulang. Penyesuaian otomatis diterapkan ke workload kedua dan berikutnya yang dikirimkan dengan nama kelompok ini. Misalnya, Anda dapat menentukandaily_sales_aggregationsebagai nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.Batch.RuntimeConfig.AutotuningConfig.scenarios: Satu atau beberapa skenario penyesuaian otomatis yang akan digunakan untuk mengoptimalkan beban kerja, seperti,BROADCAST_HASH_JOIN,MEMORY,SCALING. Anda dapat mengubah daftar skenario dengan setiap pengiriman kelompok batch. Untuk mengetahui daftar lengkap skenario, lihat Javadoc AutotuningConfig.Scenario.
Contoh:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Untuk menggunakan API, Anda harus menggunakan library klien google-cloud-dataproc versi 4.43.0
atau yang lebih baru. Anda dapat menggunakan salah satu konfigurasi berikut untuk menambahkan library ke
project.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di panduan memulai Dataproc Serverless menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Dataproc Serverless.
Untuk melakukan autentikasi ke Dataproc Serverless, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Untuk mengaktifkan penyesuaian otomatis Dataproc Serverless pada setiap pengiriman workload batch berulang, panggil BatchControllerClient.create_batch dengan Batch yang menyertakan kolom berikut:
batch.runtime_config.cohort: Nama kohor, yang mengidentifikasi batch sebagai salah satu dari serangkaian beban kerja berulang. Penyesuaian otomatis diterapkan ke workload kedua dan berikutnya yang dikirimkan dengan nama kelompok ini. Misalnya, Anda dapat menentukandaily_sales_aggregationsebagai nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.batch.runtime_config.autotuning_config.scenarios: Satu atau beberapa skenario penyesuaian otomatis yang akan digunakan untuk mengoptimalkan beban kerja, seperti,BROADCAST_HASH_JOIN,MEMORY,SCALING. Anda dapat mengubah daftar skenario dengan setiap pengiriman kelompok batch. Untuk mengetahui daftar lengkap skenario, lihat referensi Skenario.
Contoh:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Untuk menggunakan API, Anda harus menggunakan library klien google-cloud-dataproc versi 5.10.1
atau yang lebih baru. Untuk menambahkannya ke project, Anda dapat menggunakan persyaratan berikut:
google-cloud-dataproc>=5.10.1
Airflow
Untuk mengaktifkan penyesuaian otomatis Dataproc Serverless pada setiap pengiriman workload batch berulang, panggil BatchControllerClient.create_batch dengan Batch yang menyertakan kolom berikut:
batch.runtime_config.cohort: Nama kohor, yang mengidentifikasi batch sebagai salah satu dari serangkaian beban kerja berulang. Penyesuaian otomatis diterapkan ke workload kedua dan berikutnya yang dikirimkan dengan nama kelompok ini. Misalnya, Anda dapat menentukandaily_sales_aggregationsebagai nama kelompok untuk beban kerja terjadwal yang menjalankan tugas agregasi penjualan harian.batch.runtime_config.autotuning_config.scenarios: Satu atau beberapa skenario penyesuaian otomatis yang akan digunakan untuk mengoptimalkan beban kerja, misalnya,BROADCAST_HASH_JOIN,MEMORY,SCALING. Anda dapat mengubah daftar skenario dengan setiap pengiriman kelompok batch. Untuk mengetahui daftar lengkap skenario, lihat referensi Skenario.
Contoh:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Untuk menggunakan API, Anda harus menggunakan library klien google-cloud-dataproc versi 5.10.1
atau yang lebih baru. Anda dapat menggunakan persyaratan lingkungan Airflow berikut:
google-cloud-dataproc>=5.10.1
Untuk mengupdate paket di Cloud Composer, lihat Menginstal dependensi Python untuk Cloud Composer .
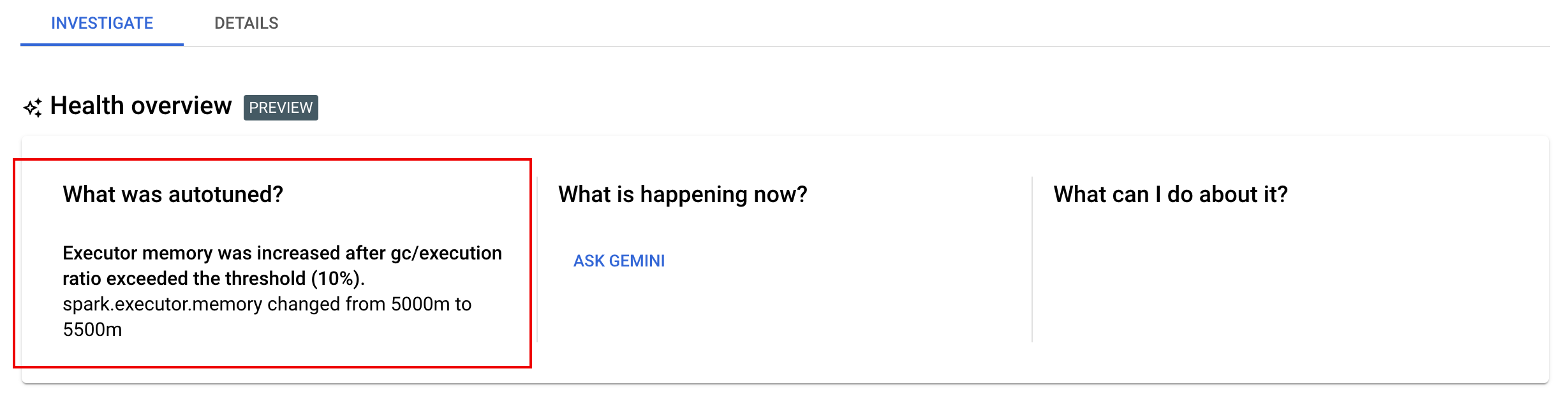
Melihat perubahan penyesuaian otomatis
Untuk melihat perubahan penyesuaian otomatis Dataproc Serverless pada workload batch, jalankan perintah gcloud dataproc batches describe.
Contoh: Output gcloud dataproc batches describe mirip dengan berikut ini:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
Anda dapat melihat perubahan autotuning terbaru yang diterapkan ke beban kerja yang sedang berjalan, selesai, atau gagal di halaman Detail batch di konsol Google Cloud, di tab Investigasi.