Optimiser les performances et la résilience d'une charge de travail Spark peut s'avérer difficile en raison des le nombre d'options de configuration Spark et la difficulté d'évaluer la façon dont ces options sur une charge de travail. Le réglage automatique sans serveur de Dataproc offre une alternative à la configuration manuelle des charges de travail en appliquant automatiquement les paramètres de configuration Spark à une charge de travail Spark récurrente, en fonction des bonnes pratiques d'optimisation Spark une analyse des exécutions de charge de travail.
S'inscrire à l'autotuning Dataproc sans serveur
Pour vous inscrire à l'version preview de l'autotuning Dataproc sans serveur décrite sur cette page, remplissez et envoyez le formulaire d'inscription à la version preview de Gemini dans BigQuery. Une fois le formulaire approuvé, les projets listés dans celui-ci ont accès aux fonctionnalités en version preview.
Avantages
L'autotuning Dataproc sans serveur peut présenter les avantages suivants :
- Amélioration des performances : réglage de l'optimisation pour améliorer les performances
- Optimisation plus rapide: configuration automatique pour éviter les tâches manuelles fastidieuses. test de configuration
- Résilience accrue: allocation de mémoire automatique pour éviter les problèmes de mémoire échecs
Limites
Le réglage automatique de Dataproc sans serveur présente les limites suivantes:
- L'ajustement automatique est calculé et appliqué à la deuxième exécution et aux exécutions suivantes d'une charge de travail. La première exécution d'une charge de travail récurrente n'est pas réglé automatiquement, car le réglage automatique de Dataproc sans serveur utilise la charge de travail pour l'optimisation.
- La réduction de la mémoire n'est pas prise en charge.
- Le réglage automatique n'est pas appliqué rétroactivement aux charges de travail en cours d'exécution, mais uniquement de charges de travail envoyées.
Cohortes avec réglage automatique
Le réglage automatique est appliqué aux exécutions récurrentes d'une charge de travail par lot, appelées cohortes.
Le nom de la cohorte que vous spécifiez lorsque vous envoyez une charge de travail l'identifie comme l'une des exécutions successives de la charge de travail récurrente.
Nous vous recommandons d'utiliser des noms de cohorte qui décrivent le type de charge de travail ou qui aident à identifier les exécutions d'une charge de travail dans le cadre d'une charge de travail récurrente. Par exemple, spécifiez daily_sales_aggregation comme
nom de cohorte pour une charge de travail planifiée qui exécute une tâche quotidienne d'agrégation des ventes.
Scénarios de réglage automatique
Vous appliquez l'ajustement automatique Dataproc sans serveur à votre charge de travail en sélectionnant un ou plusieurs des scénarios d'ajustement automatique suivants :
MEMORY: ajuste automatiquement l'allocation de mémoire Spark pour prédire et éviter les erreurs de mémoire saturée potentielles liées à la charge de travail. Résoudre une charge de travail qui a précédemment échoué en raison d'une erreur de mémoire insuffisante (OOM).SCALING: ajuste automatiquement les paramètres de configuration de l'autoscaling Spark.BROADCAST_HASH_JOIN: réglage automatique des paramètres de configuration Spark pour optimiser la jointure de diffusion SQL des performances.
Tarifs
L'ajustement automatique Dataproc sans serveur est proposé pendant la version bêta sans frais supplémentaires. La tarification standard de Dataproc sans serveur s'applique.
Disponibilité en fonction des régions
Vous pouvez utiliser le réglage automatique de Dataproc sans serveur avec les lots envoyés régions Compute Engine disponibles.
Utiliser l'autotuning Dataproc sans serveur
Vous pouvez activer l'ajustement automatique Dataproc sans serveur sur une charge de travail à l'aide de la console Google Cloud, de la Google Cloud CLI ou de l'API Dataproc.
Console
Pour activer l'ajustement automatique de Dataproc sans serveur à chaque envoi d'une charge de travail par lot récurrente, procédez comme suit :
Dans la console Google Cloud, accédez à la page Lots de Dataproc.
Pour créer une charge de travail par lot, cliquez sur Créer.
Dans la section Container (Conteneur), renseignez les champs suivants pour votre charge de travail Spark :
Cohort (Cohorte) : nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. L'ajustement automatique est appliqué au deuxième et aux suivants des charges de travail envoyées avec ce nom de cohorte. Par exemple, spécifiez
daily_sales_aggregationcomme nom de cohorte pour une charge de travail planifiée qui exécute une tâche d'agrégation des ventes quotidienne.Scénarios de réglage automatique:un ou plusieurs scénarios de réglage automatique à utiliser optimiser la charge de travail (par exemple,
BROADCAST_HASH_JOIN,MEMORYetSCALING). Vous pouvez modifier la sélection du scénario à chaque envoi de cohorte par lot.
Remplissez les autres sections de la page Créer un lot selon vos besoins, puis cliquez sur Envoyer. Pour en savoir plus sur ces champs, consultez Envoyez une charge de travail par lot.
gcloud
Pour activer le réglage automatique de Dataproc sans serveur à chaque envoi
d'une charge de travail par lot récurrente, exécutez la gcloud CLI suivante
gcloud dataproc batches submit
localement dans une fenêtre de terminal ou dans
Cloud Shell :
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Remplacez les éléments suivants :
- COMMAND : type de charge de travail Spark, tel que
Spark,PySpark,Spark-SqlouSpark-R. - REGION : région dans laquelle votre charge de travail sera exécutée.
COHORT : nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. L'ajustement automatique est appliqué à la deuxième charge de travail et aux suivantes envoyées avec ce nom de cohorte. Par exemple, spécifiez
daily_sales_aggregationcomme nom de cohorte pour une charge de travail planifiée qui exécute une tâche quotidienne d'agrégation des ventes.SCENARIOS : un ou plusieurs scénarios d'auto-tuning séparés par une virgule à utiliser pour optimiser la charge de travail, par exemple
--autotuning-scenarios=MEMORY,SCALING. Vous pouvez modifier la liste des scénarios à chaque envoi de cohorte par lot.
API
Pour activer l'ajustement automatique de Dataproc sans serveur à chaque envoi d'une charge de travail par lot récurrente, envoyez une requête batches.create qui inclut les champs suivants :
RuntimeConfig.cohort: nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. Le réglage automatique s'applique à la deuxième charge de travail et aux charges de travail suivantes envoyées avec ce nom de cohorte. Par exemple, spécifiezdaily_sales_aggregationcomme nom de cohorte pour une charge de travail planifiée qui exécute une tâche quotidienne d'agrégation des ventes.AutotuningConfig.scenarios: un ou plusieurs scénarios de réglage automatique à utiliser pour optimiser la charge de travail (par exemple,BROADCAST_HASH_JOIN,MEMORYetSCALING). Vous pouvez modifier la liste des scénarios à chaque envoi de cohorte par lot.
Exemple :
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de Dataproc sans serveur à l'aide des bibliothèques clientes. Pour en savoir plus, consultez les API Java Dataproc sans serveur documentation de référence.
Pour vous authentifier auprès de Dataproc sans serveur, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Pour activer l'ajustement automatique de Dataproc sans serveur à chaque envoi d'une charge de travail par lot récurrente, appelez BatchControllerClient.createBatch avec une CreateBatchRequest qui inclut les champs suivants :
Batch.RuntimeConfig.cohort: nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. L'ajustement automatique est appliqué au deuxième et aux suivants des charges de travail envoyées avec ce nom de cohorte. Par exemple, vous pouvez spécifierdaily_sales_aggregationcomme nom de cohorte pour une charge de travail planifiée qui exécute une tâche quotidienne d'agrégation des ventes.Batch.RuntimeConfig.AutotuningConfig.scenarios: un ou plusieurs scénarios d'auto-tuning à utiliser pour optimiser la charge de travail, par exempleBROADCAST_HASH_JOIN,MEMORYouSCALING. Vous pouvez modifier la liste des scénarios à chaque envoi de cohorte par lot. Pour obtenir la liste complète des scénarios, consultez la documentation Javadoc AutotuningConfig.Scenario.
Exemple :
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Pour utiliser l'API, vous devez utiliser la version 4.43.0 ou ultérieure de la bibliothèque cliente google-cloud-dataproc. Vous pouvez utiliser l'une des configurations suivantes pour ajouter la bibliothèque à votre projet.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de Dataproc sans serveur à l'aide des bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API Python Dataproc sans serveur.
Pour vous authentifier auprès de Dataproc sans serveur, configurez les identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Pour activer l'ajustement automatique de Dataproc sans serveur à chaque envoi d'une charge de travail par lot récurrente, appelez BatchControllerClient.create_batch avec un Batch qui inclut les champs suivants :
batch.runtime_config.cohort: nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. L'ajustement automatique est appliqué au deuxième et aux suivants des charges de travail envoyées avec ce nom de cohorte. Par exemple, vous pouvez spécifierdaily_sales_aggregationcomme nom de cohorte pour une charge de travail planifiée qui exécute une tâche quotidienne d'agrégation des ventes.batch.runtime_config.autotuning_config.scenarios: un ou plusieurs scénarios d'auto-tuning à utiliser pour optimiser la charge de travail, par exempleBROADCAST_HASH_JOIN,MEMORYouSCALING. Vous pouvez modifier la liste des scénarios à chaque envoi de cohorte par lot. Pour obtenir la liste complète des scénarios, consultez la Scénario référence.
Exemple :
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Pour utiliser l'API, vous devez utiliser la bibliothèque cliente google-cloud-dataproc version 5.10.1.
ou version ultérieure. Pour l'ajouter à votre projet, vous pouvez utiliser l'exigence suivante :
google-cloud-dataproc>=5.10.1
Airflow
Pour activer le réglage automatique de Dataproc sans serveur à chaque envoi d'un lot récurrent charge de travail, appelez BatchControllerClient.create_batch à l'aide d'une requête Batch comprenant les champs suivants:
batch.runtime_config.cohort: nom de la cohorte, qui identifie le lot comme faisant partie d'une série de charges de travail récurrentes. L'ajustement automatique est appliqué au deuxième et aux suivants des charges de travail envoyées avec ce nom de cohorte. Par exemple, vous pouvez spécifierdaily_sales_aggregationcomme nom de cohorte pour une charge de travail planifiée qui exécute une tâche quotidienne d'agrégation des ventes.batch.runtime_config.autotuning_config.scenarios: un ou plusieurs scénarios d'auto-tuning à utiliser pour optimiser la charge de travail, par exempleBROADCAST_HASH_JOIN,MEMORY,SCALING. Vous pouvez modifier la liste des scénarios à chaque envoi de cohorte par lot. Pour obtenir la liste complète des scénarios, consultez la documentation de référence sur les scénarios.
Exemple :
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Pour utiliser l'API, vous devez utiliser la version 5.10.1 ou ultérieure de la bibliothèque cliente google-cloud-dataproc. Vous pouvez utiliser l'exigence d'environnement Airflow suivante :
google-cloud-dataproc>=5.10.1
Pour mettre à jour le package dans Cloud Composer, consultez Installez des dépendances Python pour Cloud Composer .
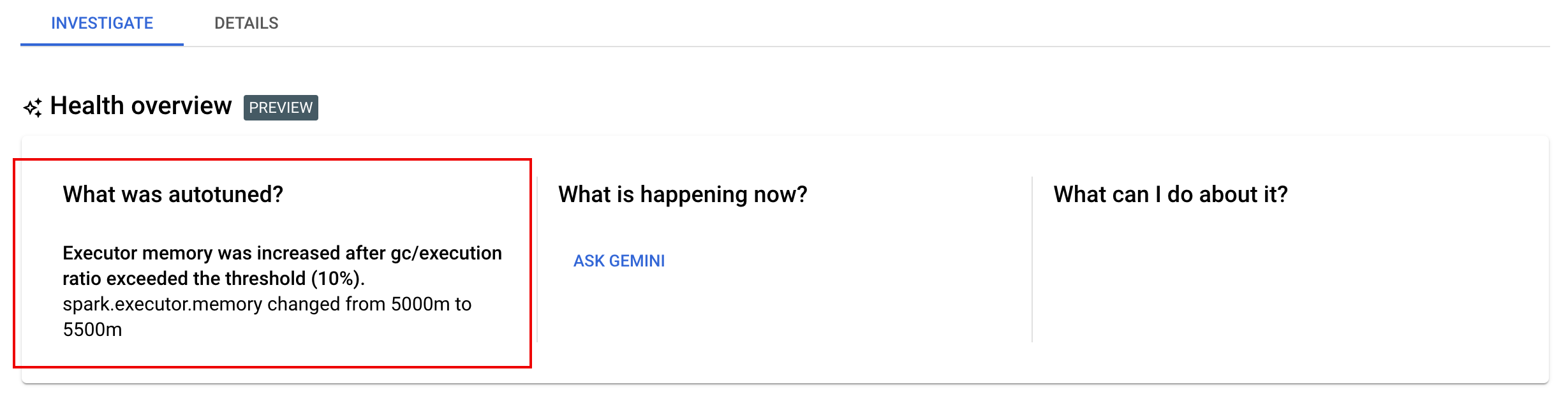
Afficher les modifications apportées au réglage automatique
Pour afficher les modifications apportées par l'autotuning Dataproc sans serveur à une charge de travail par lot, exécutez la commande gcloud dataproc batches describe.
Exemple: Le résultat de gcloud dataproc batches describe est semblable à celui-ci:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
Vous pouvez afficher les dernières modifications appliquées au réglage automatique à une charge de travail en cours d'exécution, terminée ou en échec page Détails du lot de la console Google Cloud dans l'onglet Enquêter.