Die Optimierung einer Spark-Arbeitslast im Hinblick auf Leistung und Robustheit kann aufgrund der Anzahl der Spark-Konfigurationsoptionen und die Schwierigkeit, die Leistung dieser Optionen auf eine Arbeitslast auswirken. Die serverlose automatische Abstimmung von Dataproc ist eine Alternative zur manuellen Arbeitslastkonfiguration durch automatisches Anwenden der Spark-Konfigurationseinstellungen auf eine wiederkehrende Spark-Arbeitslast basierend auf Best Practices für die Spark-Optimierung und einer Analyse der Arbeitslastausführungen.
Für die automatische Abstimmung von Dataproc Serverless registrieren
So registrieren Sie sich für den Zugriff auf die automatische Abstimmung von Dataproc Serverless der auf dieser Seite beschriebenen Vorabversion und senden Sie die Gemini in der BigQuery-Vorschau Anmeldeformular aus. Nach der Genehmigung des Formulars werden die im Formular aufgeführten Projekte Zugriff auf Vorschaufunktionen.
Vorteile
Die serverlose automatische Abstimmung von Dataproc bietet folgende Vorteile:
- Verbesserte Leistung: Durch Optimierung die Leistung steigern
- Schnellere Optimierung: Automatische Konfiguration, um zeitaufwendige manuelle Anpassungen zu vermeiden. Konfigurationstest
- Erhöhte Ausfallsicherheit: Automatische Arbeitsspeicherzuweisung zur Vermeidung arbeitsspeicherbezogener Fehler
Beschränkungen
Für die automatische Optimierung von Dataproc Serverless gelten die folgenden Einschränkungen:
- Die automatische Optimierung wird berechnet und auf die zweite und nachfolgende Ausführung einer Arbeitslast angewendet. Die erste Ausführung einer wiederkehrenden Arbeitslast wird nicht automatisch abgestimmt, da die automatische Abstimmung von Dataproc Serverless die Arbeitslast verwendet für die Optimierung.
- Das Verkleinern des Arbeitsspeichers wird nicht unterstützt.
- Die automatische Optimierung wird nicht rückwirkend auf laufende Arbeitslasten angewendet, sondern nur auf neu eingereichte Arbeitslastkohorten.
Kohorten für die automatische Optimierung
Die automatische Abstimmung wird auf wiederkehrende Ausführungen einer Batcharbeitslast angewendet, die als Kohorten bezeichnet wird.
Der Kohortenname, den Sie beim Senden einer Arbeitslast angeben
als eine der aufeinanderfolgenden Ausführungen der wiederkehrenden Arbeitslast identifiziert.
Wir empfehlen, Kohortennamen zu verwenden, die die Art der
oder auf andere Weise dabei helfen,
die Ausführungen einer Arbeitslast als Teil
einer wiederkehrenden Arbeitslast. Geben Sie beispielsweise daily_sales_aggregation als Kohortennamen für eine geplante Arbeitslast an, die eine tägliche Aufgabe zur Zusammenführung von Verkäufen ausführt.
Szenarien für die automatische Abstimmung
Sie können die automatische Optimierung von Dataproc Serverless auf Ihre Arbeitslast anwenden, indem Sie eines oder mehrere der folgenden Szenarien für die automatische Optimierung auswählen:
MEMORY: Spark-Arbeitsspeicherzuweisung automatisch abstimmen, um potenzielles Potenzial vorherzusagen und zu vermeiden aufgrund von unzureichendem Arbeitsspeicher durch die Arbeitslast. Zuvor fehlgeschlagene fällige Arbeitslast beheben zu einem OOM-Fehler führen.SCALING: Konfigurationseinstellungen für das Autoscaling von Spark automatisch abstimmen.BROADCAST_HASH_JOIN: Spark-Konfigurationseinstellungen automatisch anpassen, um den SQL-Broadcast-Join zu optimieren die Leistung.
Preise
Die serverlose automatische Abstimmung von Dataproc Serverless wird in der Vorabversion ohne zusätzliche Kosten angeboten. Standardzugriff Es gelten die Preise für Dataproc Serverless.
Regionale Verfügbarkeit
Sie können die automatische Optimierung von Dataproc Serverless für Batches verwenden, die in verfügbaren Compute Engine-Regionen eingereicht werden.
Automatische Abstimmung von Dataproc Serverless verwenden
Sie können die automatische Abstimmung von Dataproc Serverless auf einer mit der Google Cloud Console, der Google Cloud CLI oder Dataproc API
Console
So aktivieren Sie die automatische Abstimmung von Dataproc Serverless bei jeder Einreichung einer wiederkehrenden Batcharbeitslast sind, führen Sie die folgenden Schritte aus:
Rufen Sie in der Google Cloud Console die Dataproc-Seite Batches auf.
Klicken Sie zum Erstellen einer Batcharbeitslast auf Erstellen.
Geben Sie im Abschnitt Container folgende Felder für Ihre Spark-Arbeitslast ein:
Kohorte: Der Name der Kohorte. identifiziert den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten. Die automatische Abstimmung wird auf die zweite und nachfolgende Arbeitslasten angewendet, die gesendet werden mit diesem Kohortennamen. Geben Sie beispielsweise
daily_sales_aggregationals Kohortenname für eine geplante Arbeitslast, die eine tägliche Aufgabe zur Umsatzaggregation ausführt.Szenarien für die automatische Abstimmung:mindestens eins Szenarien für die automatische Abstimmung die Arbeitslast optimieren, z. B.
BROADCAST_HASH_JOIN,MEMORYundSCALING. Sie können die Szenarioauswahl bei jeder Einreichung einer Batch-Kohorte ändern.
Füllen Sie nach Bedarf die anderen Abschnitte der Seite Batch erstellen aus und klicken Sie dann auf Senden. Weitere Informationen zu diesen Feldern finden Sie unter Batcharbeitslast senden.
gcloud
So aktivieren Sie die automatische Abstimmung von Dataproc Serverless bei jeder Einreichung
einer wiederkehrenden Batcharbeitslast, führen Sie die folgende gcloud CLI aus:
gcloud dataproc batches submit
in einem Terminalfenster oder in
Cloud Shell:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Ersetzen Sie Folgendes:
- COMMAND: der Spark-Arbeitslasttyp, z. B.
Spark,PySparkSpark-SqloderSpark-R. - REGION: die Region wo die Arbeitslast ausgeführt wird.
COHORT: der Name der Kohorte, mit dem identifiziert den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten. Die automatische Abstimmung wird auf die zweite und nachfolgende Arbeitslasten angewendet, die gesendet werden mit diesem Kohortennamen. Geben Sie beispielsweise
daily_sales_aggregationals Kohortenname für eine geplante Arbeitslast, die eine tägliche Aufgabe zur Umsatzaggregation ausführt.SCENARIOS: ein oder mehrere durch Kommas getrennte Elemente Szenarien für die automatische Abstimmung, die Arbeitslast optimieren, z. B.
--autotuning-scenarios=MEMORY,SCALING. Sie können die Szenarioliste bei jeder Einreichung einer Batch-Kohorte ändern.
API
So aktivieren Sie die automatische Abstimmung von Dataproc Serverless bei jeder Einreichung einer wiederkehrenden Batch-Arbeitslast senden Sie eine batches.create-Datei. -Anfrage mit den folgenden Feldern:
RuntimeConfig.cohort: der Name der Kohorte, der identifiziert den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten. Die automatische Abstimmung wird auf die zweite und nachfolgende gesendete Arbeitslasten angewendet mit diesem Kohortennamen. Geben Sie beispielsweisedaily_sales_aggregationals Kohortenname für eine geplante Arbeitslast, die eine tägliche Aufgabe zur Umsatzaggregation ausführt.AutotuningConfig.scenarios: mindestens eins Szenarien für die automatische Abstimmung, die Arbeitslast optimieren, z. B.BROADCAST_HASH_JOIN,MEMORYundSCALING. Sie können die Szenarioliste bei jeder Einreichung einer Batch-Kohorte ändern.
Beispiel:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für Java in der Kurzanleitung zu Dataproc Serverless mit Clientbibliotheken. Weitere Informationen finden Sie in der Dataproc Serverless API Java Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei Dataproc Serverless zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Zum Aktivieren der serverlosen automatischen Abstimmung von Dataproc bei jeder Einreichung eines wiederkehrenden Batches BatchControllerClient.createBatch aufrufen. mit CreateBatchRequest enthält die folgenden Felder:
Batch.RuntimeConfig.cohort: Der Name der Kohorte. identifiziert den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten. Die automatische Abstimmung wird auf die zweite und nachfolgende gesendete Arbeitslasten angewendet mit diesem Kohortennamen. Beispielsweise können Siedaily_sales_aggregationals den Kohortenname für eine geplante Arbeitslast, die eine tägliche Aufgabe zur Umsatzaggregation ausführt.Batch.RuntimeConfig.AutotuningConfig.scenarios: Ein oder mehrere Autotuning-Szenarien, mit denen die Arbeitslast optimiert werden soll, z. B.BROADCAST_HASH_JOIN,MEMORYoderSCALING. Sie können die Szenarioliste bei jeder Einreichung einer Batchkohorte ändern. Eine vollständige Liste der Szenarien finden Sie in der AutotuningConfig.Scenario Javadoc.
Beispiel:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Wenn du die API nutzen möchtest, musst du die google-cloud-dataproc-Clientbibliothek Version 4.43.0 verwenden
oder später. Sie können eine der folgenden Konfigurationen verwenden, um die Bibliothek Ihrem Projekt hinzuzufügen.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Bevor Sie dieses Beispiel ausprobieren, folgen Sie der Einrichtungsanleitung für Python in der Kurzanleitung zu Dataproc Serverless mit Clientbibliotheken. Weitere Informationen finden Sie in der Dataproc Serverless API Python Referenzdokumentation.
Richten Sie Standardanmeldedaten für Anwendungen ein, um sich bei Dataproc Serverless zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Zum Aktivieren der serverlosen automatischen Abstimmung von Dataproc bei jeder Einreichung eines wiederkehrenden Batches BatchControllerClient.create_batch aufrufen. mit einem Batch enthält die folgenden Felder:
batch.runtime_config.cohort: Der Name der Kohorte. identifiziert den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten. Die automatische Optimierung wird auf die zweite und nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Sie können beispielsweisedaily_sales_aggregationals Kohortennamen für eine geplante Arbeitslast angeben, auf die eine tägliche Aufgabe zur Verkaufsaggregation angewendet wird.batch.runtime_config.autotuning_config.scenarios: mindestens eine Szenarien für die automatische Abstimmung, die Arbeitslast optimieren, z. B.BROADCAST_HASH_JOIN,MEMORY,SCALING. Sie können die Szenarioliste bei jeder Einreichung einer Batch-Kohorte ändern. Eine vollständige Liste der Szenarien finden Sie in der Szenario Referenz.
Beispiel:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Wenn du die API nutzen möchtest, musst du die google-cloud-dataproc-Clientbibliothek Version 5.10.1 verwenden
oder später. Wenn Sie sie Ihrem Projekt hinzufügen möchten, können Sie die folgende Anforderung verwenden:
google-cloud-dataproc>=5.10.1
Airflow
Zum Aktivieren der serverlosen automatischen Abstimmung von Dataproc bei jeder Einreichung eines wiederkehrenden Batches BatchControllerClient.create_batch aufrufen. mit einem Batch enthält die folgenden Felder:
batch.runtime_config.cohort: Der Name der Kohorte. identifiziert den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten. Die automatische Abstimmung wird auf die zweite und nachfolgende gesendete Arbeitslasten angewendet durch diesen Kohortennamen. Beispielsweise können Siedaily_sales_aggregationals den Kohortenname für eine geplante Arbeitslast, die eine tägliche Aufgabe zur Umsatzaggregation ausführt.batch.runtime_config.autotuning_config.scenarios: mindestens eine Szenarien für die automatische Abstimmung, die Arbeitslast optimieren, z. B.BROADCAST_HASH_JOIN,MEMORY,SCALING. Sie können die Szenarioliste bei jeder Einreichung einer Batch-Kohorte ändern. Eine vollständige Liste der Szenarien finden Sie in der Referenz zu Szenarien.
Beispiel:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Wenn Sie die API verwenden möchten, benötigen Sie die google-cloud-dataproc-Clientbibliothek Version 5.10.1 oder höher. Sie können die folgende Airflow-Umgebungsanforderung verwenden:
google-cloud-dataproc>=5.10.1
Informationen zum Aktualisieren des Pakets in Cloud Composer finden Sie unter Installieren Sie Python-Abhängigkeiten für Cloud Composer.
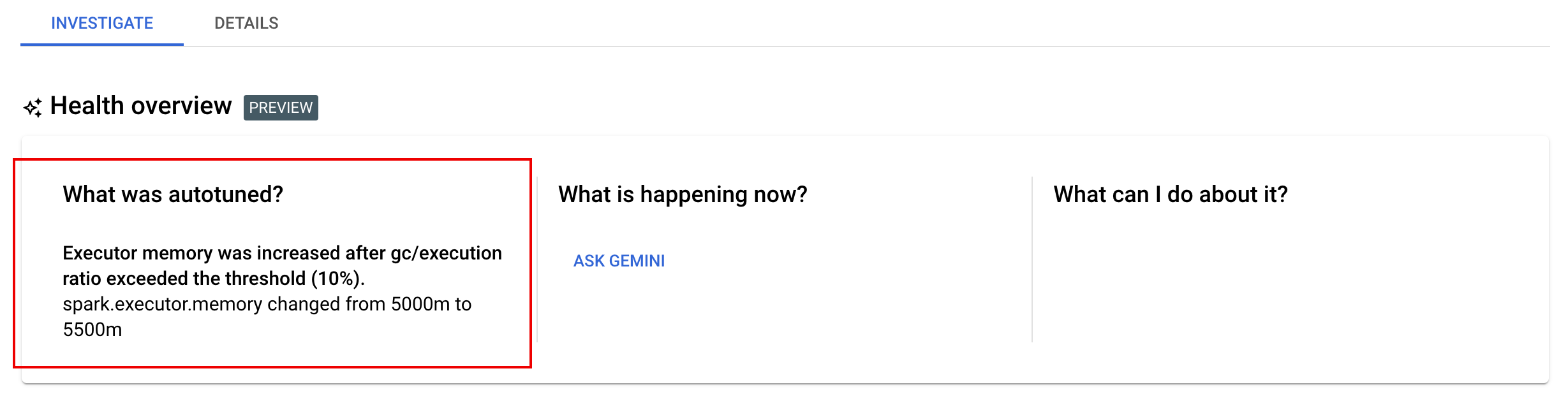
Änderungen an der automatischen Optimierung ansehen
So lassen Sie sich Änderungen der automatischen Abstimmung von Dataproc Serverless an einer Batcharbeitslast anzeigen:
den
gcloud dataproc batches describe
.
Beispiel: Die Ausgabe von gcloud dataproc batches describe sieht in etwa so aus:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
Sie können die letzten Änderungen der automatischen Abstimmung aufrufen, die angewendet wurden ausgeführte, abgeschlossene oder fehlgeschlagene Arbeitslast Seite Batchdetails in der Google Cloud Console auf dem Tab Untersuchen.