Otimizar uma carga de trabalho do Spark para desempenho e resiliência pode ser desafiador devido ao número de opções de configuração do Spark e à dificuldade de avaliar como essas opções afetam uma carga de trabalho. O ajuste automático do Dataproc Serverless oferece uma alternativa à configuração manual de cargas de trabalho, aplicando automaticamente as configurações do Spark a uma carga de trabalho recorrente do Spark com base nas práticas recomendadas de otimização do Spark e em uma análise das execuções de carga de trabalho.
Inscreva-se para o ajuste automático do Dataproc sem servidor
Como se inscrever para acessar o ajuste automático do Dataproc sem servidor prévia descrita nesta página, preencher e enviar Prévia do Gemini no BigQuery formulário de inscrição. Depois que o formulário é aprovado, os projetos listados nele têm acesso aos recursos de pré-lançamento.
Vantagens
O ajuste automático do Dataproc sem servidor oferece os seguintes benefícios:
- Performance aprimorada: ajuste de otimização para melhorar o desempenho.
- Otimização mais rápida: configuração automática para evitar o trabalho manual demorado teste de configuração
- Maior resiliência: alocação automática de memória para evitar falhas relacionadas à memória.
Limitações
O ajuste automático do Dataproc sem servidor tem as seguintes limitações:
- O ajuste automático é calculado e aplicado à segunda execução e à sequência seguinte de um carga de trabalho do Google Cloud. A primeira execução de uma carga de trabalho recorrente não é ajustado automaticamente porque o ajuste automático do Dataproc sem servidor usa carga de trabalho histórico para otimização.
- Não é possível reduzir a memória.
- O ajuste automático não é aplicado retroativamente a cargas de trabalho em execução, apenas a coortes de carga de trabalho recém-enviadas.
Coortes de ajuste automático
O ajuste automático é aplicado a execuções recorrentes de uma carga de trabalho em lote, chamada de coortes.
O nome da coorte especificado ao enviar uma carga de trabalho
identifica-a como uma das execuções sucessivas da carga de trabalho recorrente.
Recomendamos que você use nomes de coorte que descrevam o tipo de
carga de trabalho ou que ajudem a identificar as execuções de uma carga de trabalho como parte
de uma carga de trabalho recorrente. Por exemplo, especifique daily_sales_aggregation como o
nome da coorte de uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.
Cenários de ajuste automático
Para aplicar a autoajuste do Dataproc sem servidor à sua carga de trabalho, selecione um ou mais dos seguintes cenários de autoajuste:
MEMORY: ajustar automaticamente a alocação de memória do Spark para prever e evitar potencial por falta de memória da carga de trabalho. Corrigir uma carga de trabalho que falhou anteriormente para um erro de falta de memória (OOM, na sigla em inglês).SCALING: Autotune Spark para configurações de escalonamento automático.BROADCAST_HASH_JOIN: ajustar automaticamente as configurações do Spark para otimizar a união de transmissão SQL desempenho.
Preços
A autoajuste do Dataproc sem servidor é oferecida durante a visualização sem custo extra. Padrão São aplicáveis os preços do Dataproc sem servidor.
Disponibilidade regional
É possível usar a autoconfiguração do Dataproc sem servidor com lotes enviados em regiões disponíveis do Compute Engine.
Usar a autoajuste sem servidor do Dataproc
É possível ativar o ajuste automático do Dataproc Serverless em uma carga de trabalho usando o console do Google Cloud, a CLI do Google Cloud ou a API Dataproc.
Console
Ativar o ajuste automático do Dataproc sem servidor em cada envio de uma carga de trabalho em lote recorrente, siga estas etapas:
No console do Google Cloud, acesse a página Lotes do Dataproc.
Para criar uma carga de trabalho em lote, clique em Criar.
Na seção Contêiner, preencha campos a seguir para sua carga de trabalho do Spark:
Coorte:o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda carga de trabalho e às subsequentes enviadas a este nome de coorte. Por exemplo, especifique
daily_sales_aggregationcomo o nome da coorte de uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.Cenários de ajuste automático: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, por exemplo,
BROADCAST_HASH_JOIN,MEMORYeSCALING. Você pode mudar a seleção de cenário a cada envio de coorte de lote.
Preencha outras seções da página Criar lote conforme necessário e clique em Envie. Para mais informações sobre esses campos, consulte Envie uma carga de trabalho em lote.
gcloud
Ativar o ajuste automático do Dataproc sem servidor em cada envio
de uma carga de trabalho recorrente em lote, execute a seguinte CLI gcloud
gcloud dataproc batches submit
localmente em uma janela de terminal ou
Cloud Shell:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Substitua:
- COMMAND: o tipo de carga de trabalho do Spark, como
Spark,PySpark.Spark-SqlouSpark-R. - REGION: o região onde a carga de trabalho será executada.
COHORT: o nome da coorte, que identifica o lote como um de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda carga de trabalho e às subsequentes enviadas a este nome de coorte. Por exemplo, especifique
daily_sales_aggregationcomo o nome da coorte de uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.SCENARIOS: um ou mais cenários de autoajuste separados por vírgulas para usar e otimizar a carga de trabalho, por exemplo,
--autotuning-scenarios=MEMORY,SCALING. Você pode mudar a lista de cenários com cada envio de coortes em lote.
API
Ativar o ajuste automático do Dataproc sem servidor em cada envio de uma carga de trabalho em lote recorrente, envie um batches.create que inclua os seguintes campos:
RuntimeConfig.cohort: o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda carga de trabalho e às subsequentes enviadas a este nome de coorte. Por exemplo, especifiquedaily_sales_aggregationcomo o nome da coorte de uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.AutotuningConfig.scenarios: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, por exemplo,BROADCAST_HASH_JOIN,MEMORYeSCALING. É possível mudar a lista de cenários com cada envio de coorte de lote.
Exemplo:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Antes de testar este exemplo, siga as instruções de configuração do Java na Guia de início rápido do Dataproc sem servidor usando bibliotecas de cliente. Para mais informações, consulte a API Dataproc sem servidor Java documentação de referência.
Para autenticar no Dataproc sem servidor, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Para ativar o ajuste automático do Dataproc Serverless em cada envio de uma carga de trabalho recorrente, chame BatchControllerClient.createBatch com uma CreateBatchRequest que inclua os seguintes campos:
Batch.RuntimeConfig.cohort: o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda carga de trabalho e às cargas de trabalho subsequentes enviadas com esse nome de coorte. Por exemplo, você pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.Batch.RuntimeConfig.AutotuningConfig.scenarios: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, comoBROADCAST_HASH_JOIN,MEMORYeSCALING. É possível alterar a lista de cenários a cada envio de coorte em lote. Para conferir a lista completa de cenários, consulte o Javadoc AutotuningConfig.Scenario.
Exemplo:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Para usar a API, você precisa usar a versão 4.43.0
ou mais recente da biblioteca de cliente google-cloud-dataproc. Use uma das configurações a seguir para adicionar a biblioteca ao
projeto.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Antes de testar este exemplo, siga as instruções de configuração do Python na Guia de início rápido do Dataproc sem servidor usando bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Python do Dataproc sem servidor.
Para autenticar no Dataproc sem servidor, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Ativar o ajuste automático do Dataproc sem servidor em cada envio de um lote recorrente carga de trabalho, chame BatchControllerClient.create_batch usando um Batch que inclua os seguintes campos:
batch.runtime_config.cohort: o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda carga de trabalho e às cargas de trabalho subsequentes enviadas com esse nome de coorte. Por exemplo, você pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.batch.runtime_config.autotuning_config.scenarios: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, comoBROADCAST_HASH_JOIN,MEMORYeSCALING. É possível alterar a lista de cenários a cada envio de coorte em lote. Para acessar a lista completa de cenários, consulte a Cenário de referência.
Exemplo:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Para usar a API, utilize a versão 5.10.1 da biblioteca de cliente da google-cloud-dataproc
ou mais tarde. Para adicioná-lo ao seu projeto, você pode usar o seguinte requisito:
google-cloud-dataproc>=5.10.1
Airflow
Para ativar o ajuste automático do Dataproc Serverless em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.create_batch com um Batch que inclua os seguintes campos:
batch.runtime_config.cohort: o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda carga de trabalho e às cargas de trabalho subsequentes enviadas com esse nome de coorte. Por exemplo, você pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.batch.runtime_config.autotuning_config.scenarios: um ou mais cenários de autoajuste a serem usados para otimizar a carga de trabalho, por exemplo,BROADCAST_HASH_JOIN,MEMORY,SCALING. É possível mudar a lista de cenários com cada envio de coorte de lote. Para acessar a lista completa de cenários, consulte a Cenário de referência.
Exemplo:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Para usar a API, utilize a versão 5.10.1 da biblioteca de cliente da google-cloud-dataproc
ou mais tarde. Use o seguinte requisito de ambiente do Airflow:
google-cloud-dataproc>=5.10.1
Para atualizar o pacote no Cloud Composer, consulte Instale as dependências do Python para o Cloud Composer .
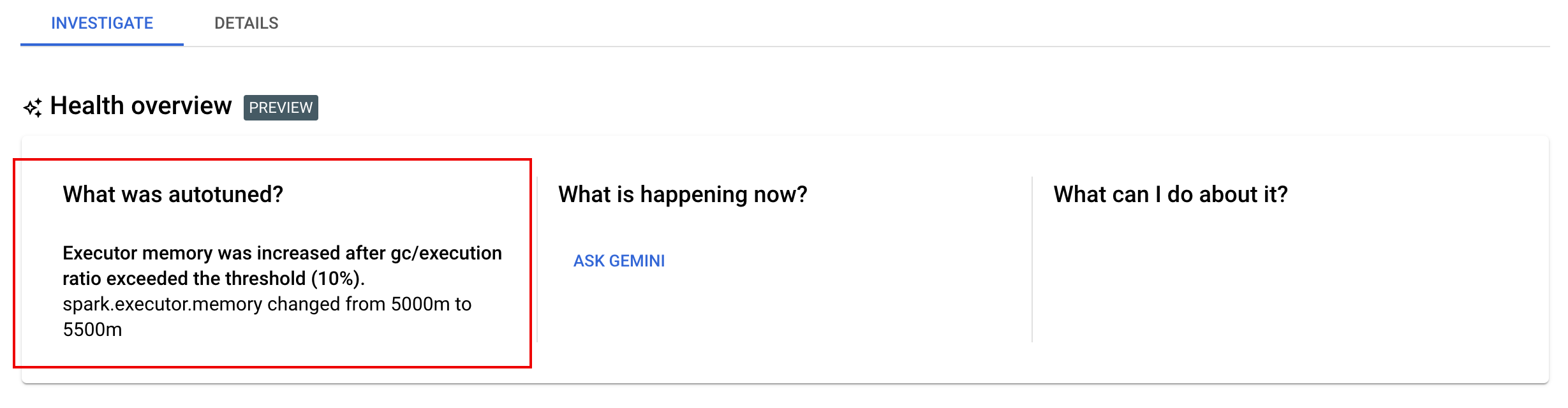
Conferir mudanças de ajuste automático
Para conferir as mudanças de ajuste automático do Dataproc Serverless em uma carga de trabalho em lote,
execute o comando
gcloud dataproc batches describe.
Exemplo: a saída gcloud dataproc batches describe é semelhante a esta:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
Você pode conferir as alterações mais recentes do ajuste automático que foram aplicadas para uma carga de trabalho em execução, concluída ou com falha página Detalhes do lote no console do Google Cloud; na guia Investigar.