Cette page explique comment importer des métadonnées dans un service Dataproc Metastore.
La fonctionnalité d'importation de métadonnées vous permet d'alimenter un service Dataproc Metastore existant avec des métadonnées stockées dans un format de stockage portable.
Ces métadonnées portables sont généralement exportées depuis un autre service Dataproc Metastore ou depuis un métastore Hive (HMS) autogéré.
À propos de l'importation de métadonnées
Vous pouvez importer les formats de fichiers suivants dans Dataproc Metastore :
- Ensemble de fichiers Avro stockés dans un dossier.
- Un seul fichier de dump MySQL stocké dans un dossier Cloud Storage.
Les fichiers MySQL ou Avro que vous importez doivent être générés à partir d'une base de données relationnelle.
Si vos fichiers sont dans un format différent, comme PostgreSQL, vous devez les convertir au format Avro ou MySQL. Après la conversion, vous pouvez les importer dans Dataproc Metastore.
Avro
Les importations basées sur Avro ne sont compatibles qu'avec les versions Hive 2.3.6 et 3.1.2. Lorsque vous importez des fichiers Avro, Dataproc Metastore s'attend à trouver une série de fichiers <table-name>.avro pour chaque table de votre base de données.
Pour importer des fichiers Avro, votre service Dataproc Metastore peut utiliser le type de base de données MySQL ou Spanner.
MySQL
Les importations basées sur MySQL sont compatibles avec toutes les versions de Hive. Lors de l'importation de fichiers MySQL, Dataproc Metastore s'attend à recevoir un seul fichier SQL contenant toutes les informations sur vos tables. Les fichiers de vidage MySQL obtenus à partir d'un cluster Dataproc en langage SQL natif sont également compatibles.
Pour importer des fichiers MySQL, votre service Dataproc Metastore doit utiliser le type de base de données MySQL. Le type de base de données Spanner n'est pas compatible avec les importations MySQL.
Remarques concernant l'importation
L'importation écrase toutes les métadonnées existantes stockées dans un service Dataproc Metastore.
La fonctionnalité d'importation de métadonnées n'importe que les métadonnées. Les données créées par Apache Hive dans des tables internes ne sont pas répliquées dans l'importation.
L'importation ne transforme pas le contenu de la base de données et ne gère pas la migration des fichiers. Si vous déplacez vos données vers un autre emplacement, vous devez mettre à jour manuellement les emplacements et les schémas des données de la table dans votre service Dataproc Metastore.
L'importation ne restaure ni ne remplace les stratégies IAM précises.
Si vous utilisez VPC Service Controls, vous ne pouvez importer que des données d'un bucket Cloud Storage résidant dans le même périmètre de service que le service Dataproc Metastore.
Avant de commencer
- Activez Dataproc Metastore dans votre projet.
- Comprendre les exigences de mise en réseau spécifiques à votre projet.
- Créez un service Dataproc Metastore.
Rôles requis
Pour obtenir les autorisations nécessaires pour importer des métadonnées dans Dataproc Metastore, demandez à votre administrateur de vous accorder les rôles IAM suivants :
-
Pour importer des métadonnées :
-
Éditeur Dataproc Metastore (
roles/metastore.editor) sur le service de métadonnées. -
Administrateur Dataproc Metastore (
roles/metastore.admin) sur le projet.
-
Éditeur Dataproc Metastore (
-
Pour MySQL, afin d'utiliser l'objet Cloud Storage (fichier de dump SQL) pour l'importation :
accordez à votre compte utilisateur et à l'agent de service Dataproc Metastore le rôle Lecteur des objets Storage (
roles/storage.objectViewer) sur le bucket Cloud Storage contenant le vidage des métadonnées à importer. -
Pour Avro, afin d'utiliser le bucket Cloud Storage pour l'importation :
accordez à votre compte utilisateur et à l'agent de service Dataproc Metastore le rôle Lecteur des objets Storage (
roles/storage.objectViewer) sur le bucket Cloud Storage contenant le vidage des métadonnées à importer.
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Ces rôles prédéfinis contiennent les autorisations requises pour importer des métadonnées dans Dataproc Metastore. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour importer des métadonnées dans Dataproc Metastore :
-
Pour importer des métadonnées :
metastore.imports.createsur le service metastore. -
Pour MySQL, afin d'utiliser l'objet Cloud Storage (fichier de dump SQL) pour l'importation, accordez à votre compte utilisateur et à l'agent de service Dataproc Metastore :
storage.objects.getsur le bucket Cloud Storage contenant le vidage des métadonnées à importer. -
Pour Avro, afin d'utiliser le bucket Cloud Storage pour l'importation, accordez à votre compte utilisateur et à l'agent de service Dataproc Metastore :
storage.objects.getsur le bucket Cloud Storage contenant le vidage des métadonnées à importer.
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus sur les rôles et autorisations Dataproc Metastore spécifiques, consultez Présentation d'IAM Dataproc Metastore.Importer vos métadonnées
L'opération d'importation se déroule en deux étapes. Commencez par préparer vos fichiers d'importation, puis importez-les dans Dataproc Metastore.
Lorsque vous lancez une importation, Dataproc Metastore effectue une validation du schéma de métadonnées Hive. Cette validation vérifie les tables du fichier de vidage SQL et les noms de fichiers pour Avro. Si une table est manquante, l'importation échoue et affiche un message d'erreur décrivant la table manquante.
Pour vérifier la compatibilité des métadonnées Hive avant une importation, vous pouvez utiliser le kit Dataproc Metastore.
Préparer les fichiers d'importation avant l'importation
Avant de pouvoir importer vos fichiers dans Dataproc Metastore, vous devez copier vos fichiers de vidage de métadonnées dans Cloud Storage, par exemple dans votre bucket Cloud Storage d'artefacts.
Déplacer vos fichiers vers Cloud Storage
Créez un vidage de la base de données externe que vous souhaitez importer dans Dataproc Metastore.
Pour savoir comment créer un dump de base de données, consultez les pages suivantes :
Importez les fichiers dans Cloud Storage.
Assurez-vous de noter le chemin Cloud Storage dans lequel vous importez vos fichiers. Vous en aurez besoin plus tard pour effectuer l'importation.
Si vous importez des fichiers MySQL, importez le fichier SQL dans un bucket Cloud Storage.
Si vous importez des fichiers Avro, importez-les dans un dossier Cloud Storage.
- Votre importation Avro doit inclure un fichier Avro pour chaque table Hive, même si la table est vide.
- Les noms de fichiers Avro doivent respecter le format
<table-name>.avro.<table-name>doit être en majuscules. Par exemple,AUX_TABLE.avro.
Importer les fichiers dans Dataproc Metastore
Avant d'importer des métadonnées, consultez les points à prendre en compte pour l'importation.
Lorsqu'une importation est en cours, vous ne pouvez pas mettre à jour un service Dataproc Metastore (par exemple, en modifiant les paramètres de configuration). Toutefois, vous pouvez toujours l'utiliser pour des opérations normales, par exemple pour accéder à ses métadonnées à partir de clusters Dataproc ou autogérés associés.
Console
Dans la console Google Cloud , ouvrez la page Dataproc Metastore :
Sur la page Dataproc Metastore, cliquez sur le nom du service dans lequel vous souhaitez importer les métadonnées.
La page Service detail (Informations sur le service) s'affiche.
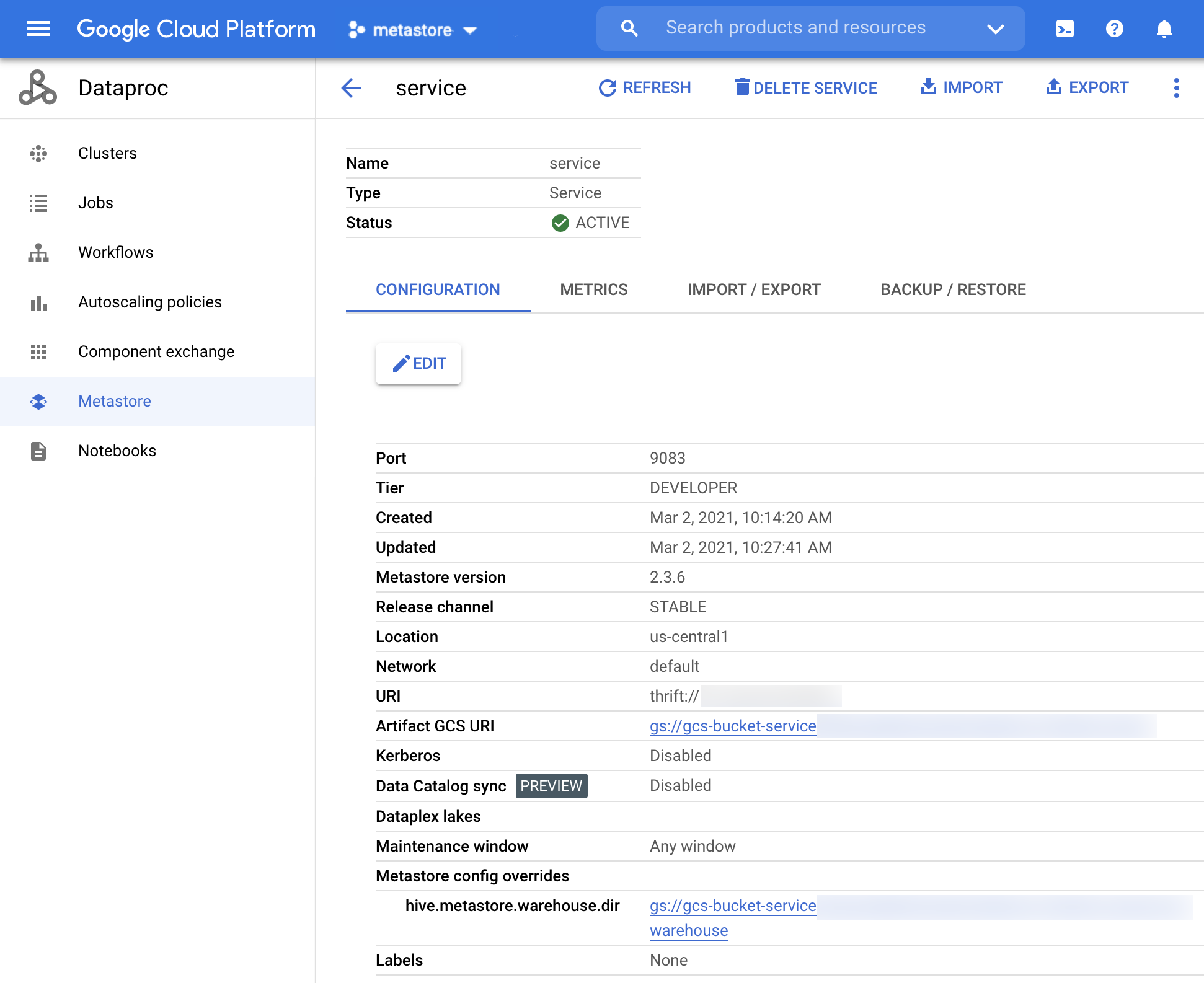
Figure 1 : Page "Détails du service" Dataproc Metastore. Dans la barre de navigation, cliquez sur Import (Importer).
La boîte de dialogue Importer s'ouvre.
Saisissez le nom de l'importation dans Import name.
Dans la section Destination, sélectionnez MySQL ou Avro.
Dans le champ URI de destination, cliquez sur Parcourir et sélectionnez l'URI Cloud Storage vers lequel vous souhaitez importer vos fichiers.
Vous pouvez également saisir manuellement l'emplacement de votre bucket dans le champ de texte prévu à cet effet. Utilisez le format
bucket/objectoubucket/folder/object.(Facultatif) Saisissez une Description de l'importation.
Vous pouvez modifier la description sur la page Informations sur le service.
Pour mettre à jour le service, cliquez sur Importer.
Une fois l'importation terminée, elle apparaît dans un tableau sur la page Informations sur le service, dans l'onglet Importation/Exportation.
gcloud CLI
Pour importer des métadonnées, exécutez la commande
gcloud metastore services import gcssuivante :gcloud metastore services import gcs SERVICE_ID \ --location=LOCATION \ --import-id=IMPORT_ID \ --description=DESCRIPTION \ --dump-type=DUMP_TYPE \ --database-dump=DATABASE_DUMP
Remplacez les éléments suivants :
SERVICE_ID: ID ou nom complet de votre service Dataproc Metastore.LOCATION: région Google Cloud dans laquelle réside votre service Dataproc Metastore.IMPORT_ID: ID ou nom complet de votre importation de métadonnées. Exemple :import1DESCRIPTION: description facultative de votre importation. Vous pourrez modifier cette adresse ultérieurement en utilisant la commandegcloud metastore services imports update IMPORT.DUMP_TYPE: type de la base de données externe que vous importez. Les valeurs acceptées incluentmysqletavro. La valeur par défaut estmysql.DATABASE_DUMP: chemin d'accès à Cloud Storage contenant les fichiers de base de données. Le chemin d'accès doit commencer pargs://. Pour Avro, indiquez le chemin d'accès au dossier dans lequel les fichiers Avro sont stockés (dossier Cloud Storage). Pour MySQL, indiquez le chemin d'accès au fichier MySQL (objet Cloud Storage).
Vérifiez que l'importation a réussi.
REST
Suivez les instructions de l'API pour importer des métadonnées dans un service à l'aide de l'explorateur d'API.
L'API vous permet de créer, de répertorier, de décrire et de mettre à jour des importations, mais vous ne pouvez pas les supprimer. Toutefois, la suppression d'un service Dataproc Metastore supprime toutes les importations imbriquées stockées.
Une fois l'importation réussie, Dataproc Metastore revient automatiquement à l'état actif. Si l'importation échoue, Dataproc Metastore revient à son état opérationnel précédent.
Afficher l'historique des importations
Pour afficher l'historique d'importation d'un service Dataproc Metastore dans la console Google Cloud , procédez comme suit :
- Dans la console Google Cloud , ouvrez la page Dataproc Metastore.
Dans la barre de navigation, cliquez sur Import/Export (Importer/Exporter).
Votre historique d'importation s'affiche dans le tableau Historique d'importation.
L'historique affiche les 25 dernières importations maximum.
La suppression d'un service Dataproc Metastore entraîne également la suppression de tout l'historique des importations associé.
Résoudre les problèmes courants
Voici quelques problèmes courants :
- L'importation échoue, car les versions Hive ne correspondent pas.
- L'agent de service ou le compte utilisateur ne dispose pas des autorisations nécessaires.
- La tâche échoue, car le fichier de base de données est trop volumineux.
Pour obtenir de l'aide sur la résolution des problèmes courants, consultez Scénarios d'erreur d'importation et d'exportation.