Este tutorial propõe uma estratégia de recuperação de desastres e continuidade de negócios birregional usando o metastore do Dataproc. Neste tutorial, usamos buckets birregionais para armazenar conjuntos de dados do Hive e exportações de metadados do Hive.
O metastore do Dataproc é um serviço de armazenamento virtual nativo, altamente disponível, com escalonamento automático e recuperação automática, além de simplificar o gerenciamento de metadados nativos do OSS. Nosso serviço gerenciado é baseado no Apache Hive Metastore e serve como um componente crítico para data lakes corporativos.
Este tutorial foi criado para clientes do Google Cloud que exigem alta disponibilidade para dados e metadados do Hive. Ele usa o Cloud Storage para armazenamento, o Dataproc para computação e o Metastore do Dataproc (DPMS), um serviço totalmente gerenciado do Hive Metastore no Google Cloud. O tutorial também apresenta duas maneiras diferentes de orquestrar failovers: uma usa o Cloud Run e o Cloud Scheduler, a outra usa o Cloud Composer.
A abordagem birregional usada no tutorial tem vantagens e desvantagens:
Vantagens
- Os buckets birregionais são geograficamente redundantes.
- Os intervalos birregionais têm um SLA de disponibilidade de 99,95%, em comparação com a disponibilidade de 99,9% dos intervalos de região única.
- Os buckets birregionais tem desempenho orimizado em duas regiões, enquanto os buckets de região única não têm um desempenho tão bom ao trabalhar com recursos em outras regiões.
Desvantagens
- As gravações de bucket birregionais não são replicadas imediatamente nas duas regiões.
- Os buckets birregionais têm custos de armazenamento mais altos do que os de uma única região.
Arquitetura de referência
Os diagramas de arquitetura a seguir mostram os componentes que serão usados neste tutorial. Nos dois diagramas, o X vermelho vermelho indica a falha da região principal:
 Figura 1: uso do Cloud Run e do Cloud Scheduler
Figura 1: uso do Cloud Run e do Cloud Scheduler
 Figura 2: como usar o Cloud Composer
Figura 2: como usar o Cloud Composer
Os componentes da solução e seus relacionamentos são:
- Dois buckets birregionais do Cloud Storage: você cria um bucket para os dados do Hive e outro para os backups periódicos dos metadados do Hive. Crie buckets birregionais para que usem as mesmas regiões que os clusters do Hadoop que acessam os dados.
- Um metastore do Hive usando DPMS: você cria esse metastore do Hive na sua região primária (região A). A configuração do metastore aponta para o bucket de dados do Hive. Um cluster do Hadoop que usa o Dataproc precisa estar na mesma região que a instância do DPMS à qual está anexado.
- Uma segunda instância do DPMS: crie uma segunda instância do DPMS na região de espera (região B) para se preparar para uma falha em toda a região. Em seguida, importe o arquivo de exportação
hive.sqlmais recente do bucket de exportação para o DPMS em espera. Você também cria um cluster do Dataproc em sua região de espera e o anexa à instância de DPMS em espera. Por fim, em um cenário de recuperação de desastres, você redireciona seus aplicativos cliente do cluster do Dataproc na região A para o cluster do Dataproc na região B. Uma implantação do Cloud Run: você cria uma implantação do Cloud Run na região A que exporta periodicamente os metadados DPMS para um bucket de backup de metadados usando o Cloud Scheduler (conforme mostrado na Figura 1). ). A exportação assume a forma de um arquivo SQL que contém um despejo completo dos metadados DPMS.
Se você já tem um ambiente do Cloud Composer, pode orquestrar as exportações e importações de metadados do DPMS executando um DAG do Airflow nesse ambiente (conforme mostrado na figura 2). Esse uso de um DAG do Airflow seria aplicado ao método do Cloud Run mencionado anteriormente.
Objetivos
- Configurar o armazenamento birregional para dados do Hive e backups do metastore do Hive.
- Implante um metastore do Dataproc e um cluster do Dataproc nas regiões A e B.
- Faça o failover da implantação para a região B.
- Retornar a implantação à região A.
- Criar backups automatizados do metastore do Hive.
- Orquestre exportações e importações de metadados por meio do Cloud Run.
- Faça a orquestração de exportações e importações por meio do Cloud Composer.
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na sua projeção de uso,
use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- No Cloud Shell, inicie uma instância do Cloud Shell.
Clone o repositório do GitHub do tutorial:
git clone https://github.com/GoogleCloudPlatform/metastore-disaster-recovery.gitAtive as seguintes APIs Google Cloud :
gcloud services enable dataproc.googleapis.com metastore.googleapis.comDefina algumas variáveis de ambiente:
export PROJECT=$(gcloud info --format='value(config.project)') export WAREHOUSE_BUCKET=${PROJECT}-warehouse export BACKUP_BUCKET=${PROJECT}-dpms-backups export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms2 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
Inicializar o ambiente
Como criar armazenamento para dados do Hive e backups do metastore do Hive
Nesta seção, você cria buckets do Cloud Storage para hospedar os dados e os backups do metastore do Hive.
Criar armazenamento de dados do Hive
No Cloud Shell, crie um bucket birregional para hospedar os dados do Hive:
gcloud storage buckets create gs://${WAREHOUSE_BUCKET} --location=NAM4Copie alguns dados de amostra para o bucket de dados do Hive:
gcloud storage cp gs://retail_csv gs://${WAREHOUSE_BUCKET}/retail --recursive
Criar armazenamento para backups de metadados
No Cloud Shell, crie um bucket birregional para hospedar os backups de metadados do DPMS:
gcloud storage buckets create gs://${BACKUP_BUCKET} --location=NAM4
Como implantar recursos de computação na região primária
Nesta seção, você implantará todos os recursos de computação na região primária, incluindo a instância do DPMS e o cluster do Dataproc. Também preencha o metastore do Dataproc com metadados de amostra.
Criar a instância do DPMS
No Cloud Shell, crie a instância DPMS:
gcloud metastore services create ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --hive-metastore-version=3.1.2Pode levar alguns minutos até que a execução desse comando seja concluída.
Defina o bucket de dados do Hive como o diretório de armazenamento padrão:
gcloud metastore services update ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}- warehouse"Pode levar alguns minutos até que a execução desse comando seja concluída.
Criar um cluster de Dataproc
No Cloud Shell, crie um cluster do Dataproc e anexe-o à instância do DPMS:
gcloud dataproc clusters create ${HADOOP_PRIMARY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_PRIMARY_REGION}/services/${DPMS_PRIMARY_INSTANCE} \ --region=${DPMS_PRIMARY_REGION} \ --image-version=2.0Especifique a imagem do cluster como versão 2.0, que é a versão mais recente disponível a partir de junho de 2021. É também a primeira versão que suporta o DPMS.
Preencher o metastore
No Cloud Shell, atualize a amostra
retail.hqlfornecida no repositório deste tutorial com o nome do bucket de dados do Hive:sed -i -- 's/${WAREHOUSE_BUCKET}/'"$WAREHOUSE_BUCKET"'/g' retail.hqlExecute as consultas contidas no arquivo
retail.hqlpara criar as definições da tabela no metastore:gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --file=retail.hqlVerifique se as definições de tabela foram criadas corretamente:
gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --execute=" desc departments; desc categories; desc products; desc order_items; desc orders; desc customers; select count(*) as num_departments from departments; select count(*) as num_categories from categories; select count(*) as num_products from products; select count(*) as num_order_items from order_items; select count(*) as num_orders from orders; select count(*) as num_customers from customers; "A saída será assim:
+------------------+------------+----------+ | col_name | data_type | comment | +------------------+------------+----------+ | department_id | int | | | department_name | string | | +------------------+------------+----------+
A saída também contém o número de elementos em cada tabela, por exemplo:
+----------------+ | num_customers | +----------------+ | 12435 | +----------------+
Como fazer failover para a região de espera
Esta seção fornece as etapas de failover da região primária (região A) para a região de espera (região B).
No Cloud Shell, exporte os metadados da instância principal do DPMS para o intervalo de backups:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}A saída será assim:
metadataManagementActivity: metadataExports: ‐ databaseDumpType: MYSQL destinationGcsUri: gs://qa01-300915-dpms-backups/hive-export-2021-05-04T22:21:53.288Z endTime: '2021-05-04T22:23:35.982214Z' startTime: '2021-05-04T22:21:53.308534Z' state: SUCCEEDEDObserve o valor no atributo
destinationGcsUri. Esse atributo armazena o backup que você criou.Crie uma nova instância do DPMS na região de espera:
gcloud metastore services create ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --hive-metastore-version=3.1.2Defina o bucket de dados do Hive como diretório de armazenamento padrão:
gcloud metastore services update ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse"Recupere o caminho do backup de metadados mais recente:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importe os metadados armazenados em backup para a nova instância do metastore do Dataproc:
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Crie um cluster do Dataproc na região de espera (região B):
gcloud dataproc clusters create ${HADOOP_STANDBY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_STANDBY_REGION}/services/${DPMS_STANDBY_INSTANCE} \ --region=${DPMS_STANDBY_REGION} \ --image-version=2.0Verifique se os metadados foram importados corretamente:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select count(*) as num_orders from orders;"A saída
num_ordersé mais importante para o tutorial. Ela é semelhante a esta:+-------------+ | num_orders | +-------------+ | 68883 | +-------------+O metastore principal do Dataproc se tornou o novo metastore em espera, e o metastore em espera se tornou o novo metastore principal.
Atualize as variáveis de ambiente com base nesses novos papéis:
export DPMS_PRIMARY_REGION=us-east1 export DPMS_STANDBY_REGION=us-central1] export DPMS_PRIMARY_INSTANCE=dpms2 export DPMS_STANDBY_INSTANCE=dpms1 export HADOOP_PRIMARY=dataproc-cluster2 export HADOOP_STANDBY=dataproc-cluster1Verifique se é possível gravar no novo metastore principal do Dataproc na região B:
gcloud dataproc jobs submit hive \ --cluster ${DPMS_PRIMARY_INSTANCE} \ --region ${DPMS_PRIMARY_REGION} \ --execute "create view completed_orders as select * from orders where order_status = 'COMPLETE';" gcloud dataproc jobs submit hive \ --cluster ${HADOOP_PRIMARY} \ --region ${DPMS_PRIMARY_REGION} \ --execute "select * from completed_orders limit 5;"A saída contém o seguinte:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
O failover foi concluído. Agora você precisa redirecionar seus aplicativos cliente para o novo cluster principal do Dataproc na região B atualizando os arquivos de configuração do cliente Hadoop.
Como retornar à região original
Esta seção fornece as etapas para retornar à região original (região A).
No Cloud Shell, exporte os metadados da instância do DPMS:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}Recupere o caminho do backup de metadados mais recente:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importe os metadados para a instância de DPMS em espera na região original (região A):
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Verifique se os metadados foram importados corretamente:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select * from completed_orders limit 5;"A saída inclui estes elementos:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
O metastore principal do Dataproc e o metastore em espera têm os papéis trocados novamente.
Atualize as variáveis de ambiente para esses novos papéis:
export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms12 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
O failback foi concluído. Agora você deve redirecionar seus aplicativos cliente para o novo cluster principal do Dataproc na região A atualizando os arquivos de configuração de cliente do Hadoop.
Como criar backups automatizados de metadados
Esta seção descreve dois métodos diferentes para automatizar suas exportações e importações de backup de metadados. O primeiro método, Opção 1: Cloud Run e Cloud Scheduler, usa o Cloud Run e o Cloud Scheduler. O segundo método, Opção 2: Cloud Composer, usa o Cloud Composer. Em ambos os exemplos, um job de exportação cria um backup dos metadados do DPMS principal na região A. Um job de importação preenche o DPMS em espera na região B a partir do backup.
Se você já tiver um cluster do Cloud Composer, considere a Opção 2: Cloud Composer, supondo que seu cluster tenha capacidade de computação suficiente. Caso contrário, vá para a opção 1: Cloud Run e Cloud Scheduler. Esta opção usa um modelo de pagamento por utilização e é mais econômica do que o Cloud Composer, que requer o uso de recursos de computação permanentes.
Opção 1: Cloud Run e Cloud Scheduler
Nesta seção, mostramos como usar o Cloud Run e o Cloud Scheduler para automatizar as exportações de importações de metadados DPMS.
Serviços do Cloud Run
Nesta seção, mostramos como criar dois serviços do Cloud Run para executar jobs de exportação e importação de metadados.
No Cloud Shell, ative as APIs Cloud Run, Cloud Scheduler, Cloud Build e App Engine:
gcloud services enable run.googleapis.com cloudscheduler.googleapis.com cloudbuild.googleapis.com appengine.googleapis.comVocê ativa a API App Engine porque o serviço Cloud Scheduler requer o App Engine.
Crie a imagem do Docker com o Dockerfile fornecido:
cd metastore-disaster-recovery gcloud builds submit --tag gcr.io/$PROJECT/dpms_drImplante a imagem do contêiner em um serviço do Cloud Run na região principal (região A). Essa implantação é responsável por criar os backups de metadados do metastore principal:
gcloud run deploy dpms-export \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_PRIMARY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION} \ --allow-unauthenticated \ --timeout=10mPor padrão, uma solicitação de serviço do Cloud Run expira após cinco minutos. Para garantir que todas as solicitações tenham tempo suficiente para serem concluídas, o exemplo de código anterior estende o valor de tempo limite para pelo menos 10 minutos.
Recupere o URL de implantação do serviço Cloud Run:
EXPORT_RUN_URL=$(gcloud run services describe dpms-export --platform managed --region ${DPMS_PRIMARY_REGION} --format ` "value(status.address.url)") echo ${EXPORT_RUN_URL}Crie um segundo serviço do Cloud Run na região de espera (região B). Esse serviço é responsável por importar os backups de metadados de
BACKUP_BUCKETpara o metastore de espera:gcloud run deploy dpms-import \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_STANDBY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE} \ --allow-unauthenticated \ --timeout=10mRecupere o URL de implantação do segundo serviço do Cloud Run:
IMPORT_RUN_URL=$(gcloud run services describe dpms-import --platform managed --region ${REGION_B} --format "value(status.address.url)") echo ${IMPORT_RUN_URL}
Programação de jobs
Esta seção mostra como usar o Cloud Scheduler para acionar os dois serviços do Cloud Run.
No Cloud Shell, crie um aplicativo do App Engine, que requer o Cloud Scheduler:
gcloud app create --region=${REGION_A}Crie um job do Cloud Scheduler para programar as exportações de metadados do metastore principal:
gcloud scheduler jobs create http dpms-export \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${EXPORT_RUN_URL}/export\
O job do Cloud Scheduler faz uma solicitação http ao serviço do CloudCloud Run a cada 15 minutos. O serviço do Cloud Run executa um aplicativo Flask em contêiner com uma função de exportação e importação. Quando a função de exportação é acionada, ela exporta os metadados para o Cloud Storage usando o comando gcloud metastore services export.
Em geral, se os jobs do Hadoop costumam gravar no metastore do Hive, recomendamos que você faça backup do metastore com frequência. Uma boa programação de backup estaria no intervalo de cada 15 a 60 minutos.
Acione uma execução de teste do serviço do Cloud Run:
gcloud scheduler jobs run dpms-exportVerifique se o Cloud Scheduler acionou corretamente a operação de exportação do DPMS:
gcloud metastore operations list --location ${REGION_A}A saída será assim:
OPERATION_NAME LOCATION TYPE TARGET DONE CREATE_TIME DURATION ... operation-a520936204508-5v23bx4y23f60-920f0a0f-9c2b56b5 us-central1 update dpms1 True 2021-05-13T20:05:04 2M23S
Se o valor de
DONEforFalse, a exportação ainda está em andamento. Para confirmar que a operação foi concluída, execute novamente o comandogcloud metastore operations list --location ${REGION_A}até que o valor se torneTrue.Saiba mais sobre os comandos
gcloud metastore operationsna documentação de referência.(Opcional) Crie um job do Cloud Scheduler para programar as importações no metastore em espera:
gcloud scheduler jobs create http dpms-import \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${IMPORT_RUN_URL}/import
Esta etapa depende dos seus requisitos de objetivo de tempo de recuperação (RTO, na sigla em inglês).
Se você quiser uma espera ativa para minimizar o tempo de failover, programe esse job de importação. Ele atualiza seu DPMS em espera a cada 15 minutos.
Se uma espera passiva for suficiente para suas necessidades de RTO, pule esta etapa e também exclua seu cluster DPMS e de espera em espera para reduzir ainda mais sua fatura mensal geral. Ao fazer o failover para sua região de espera (região B), provisione o DPMS em espera e o cluster do Dataproc e também execute um job de importação. Como os arquivos de backup são armazenados em um bucket birregional, eles são acessíveis mesmo se a região principal (região A) ficar inativa.
Manipular failovers
Após fazer o failover para a região B, aplique as etapas a seguir para preservar os requisitos de recuperação de desastres e proteger a infraestrutura contra uma possível falha na região B:
- Pause seus jobs atuais do Cloud Scheduler.
- Atualize a região do DPMS principal para a região B (
us-east1). - Atualize a região DPMS em espera para a região A (
us-central1). - Atualize a instância principal do DPMS para
dpms2. - Atualize a instância de espera do DPMS para
dpms1. - Reimplante os serviços do Cloud Run com base nas variáveis atualizadas.
- Crie novos jobs do Cloud Scheduler que apontem para os novos serviços do CloudCloud Run.
As etapas necessárias na lista anterior repetem muitas etapas das seções anteriores, apenas com pequenos ajustes (como trocar os nomes das regiões). Use as informações da Opção 1: Cloud Run e Cloud Scheduler para concluir esse trabalho necessário.
Opção 2: Cloud Composer
Nesta seção, mostramos como usar o Cloud Composer para executar os jobs de exportação e importação em um único gráfico acíclico dirigido (DAG) do Airflow.
No Cloud Shell, ative a API Cloud Scheduler:
gcloud services enable composer.googleapis.comCrie um ambiente do Cloud Composer.
export COMPOSER_ENV=comp-env gcloud beta composer environments create ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --image-version composer-1.17.0-preview.1-airflow-2.0.1 \ --python-version 3- A imagem do compositor
composer-1.17.0-preview.1-airflow-2.0.1é a versão mais recente no momento da publicação. - Os ambientes do Composer podem usar apenas uma versão principal do Python. O Python 3 foi selecionado porque o Python 2 tem problemas de compatibilidade.
- A imagem do compositor
Configure o ambiente do Cloud Composer com estas variáveis de ambiente:
gcloud composer environments update ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --update-env-variables=DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION},DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE}Faça o upload do arquivo DAG para o ambiente do Composer:
gcloud composer environments storage dags import \ --environment ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --source dpms_dag.pyRecupere o URL do Airflow:
gcloud composer environments describe ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --format "value(config.airflowUri)"No navegador, abra o URL retornado pelo comando anterior.
Você verá uma nova entrada do DAG chamada
dpms_dag. Em uma única execução, o DAG executa uma exportação, seguida por uma importação. O DAG pressupõe que o DPMS em espera está sempre ativo. Se você não precisar de uma espera ativa e quiser apenas executar a tarefa de exportação, comente todas as tarefas relacionadas à importação no código (find_backup, wait_for_ready_status, current_ts,dpms_import).Clique no ícone Seta para acionar o DAG e fazer um teste:
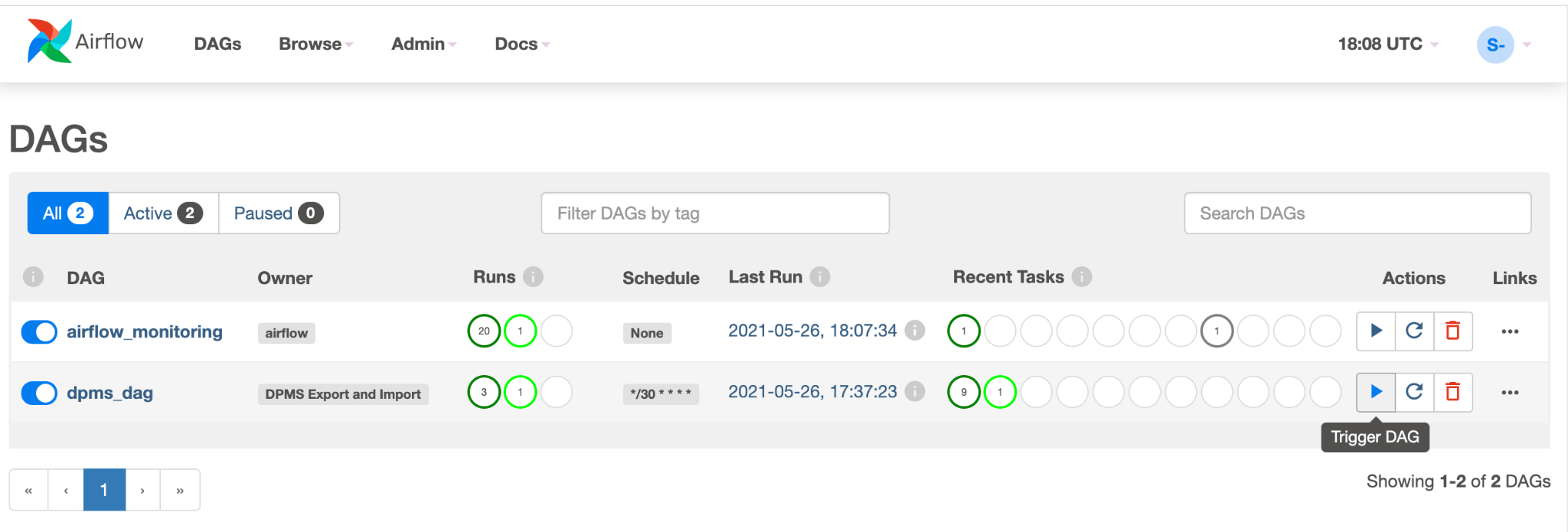
Clique em Visualização de gráfico do DAG em execução para verificar o status de cada tarefa:
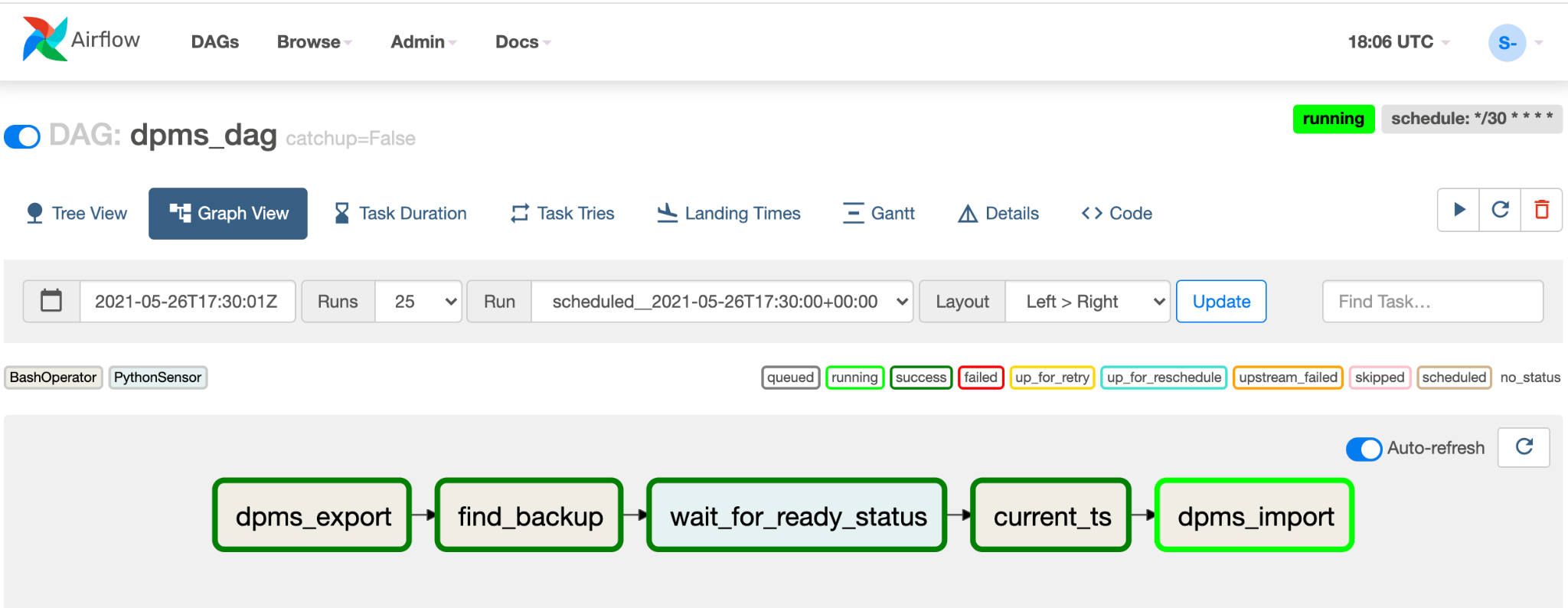
Depois de validar o DAG, permita que o Airflow o execute regularmente. A programação é definida como um intervalo de 30 minutos, mas pode ser ajustada alterando o parâmetro
schedule_intervalno código para atender aos requisitos do tempo.
Gerenciar failovers
Após fazer o failover para a região B, aplique as etapas a seguir para preservar os requisitos de recuperação de desastres e proteger a infraestrutura contra uma possível falha na região B:
- Atualize a região do DPMS principal para a região B (
us-east1). - Atualize a região DPMS em espera para a região A (
us-central1). - Atualize a instância principal do DPMS para
dpms2. - Atualize a instância de espera do DPMS para
dpms1. - Crie um novo ambiente do Cloud Composer na região B (
us-east1). - Configure o ambiente do Cloud Composer com as variáveis de ambiente atualizadas.
- Importe o mesmo DAG do Airflow do
dpms_dagpara o novo ambiente do Cloud Composer.
As etapas necessárias na lista anterior repetem muitas das etapas anteriores, apenas com pequenos ajustes (como a troca dos nomes das regiões). Use as informações da Opção 2: Cloud Composer para concluir este trabalho necessário.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Saiba como monitorar a instância do metastore do Dataproc.
- Entenda como sincronizar seu metastore do Hive com o Data Catalog
- Saiba mais sobre o desenvolvimento de serviços do Cloud Run
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.