本文档介绍了如何使用 Dataplex Universal Catalog Explore 检测零售交易数据集中的异常情况。
借助数据探索工作台(即 Explore),数据分析师可以实时以交互方式查询和探索大型数据集。Explore 可帮助您从数据中获取分析洞见,并让您能够查询存储在 Cloud Storage 和 BigQuery 中的数据。Explore 使用无服务器 Spark 平台,这样您无需管理和规模化底层基础设施。
目标
本教程介绍如何完成以下任务:
- 使用 Explore 的 Spark SQL 工作台编写和执行 Spark SQL 查询。
- 使用 JupyterLab 笔记本查看结果。
- 安排笔记本定期执行,以便您监控数据是否存在异常。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
您可使用价格计算器根据您的预计使用情况来估算费用。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
准备数据以供探索
下载 Parquet 文件
retail_offline_sales_march。创建一个名为
offlinesales_curated的 Cloud Storage 存储桶,如下所示:- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
按照从文件系统上传对象中的步骤,将您下载的
offlinesales_march_parquet文件上传到您创建的offlinesales_curatedCloud Storage 存储桶。按照创建数据湖中的步骤,创建一个 Dataplex Universal Catalog 数据湖并将其命名为
operations。在
operations数据湖中,按照添加可用区中的步骤添加一个可用区并将其命名为procurement。在
procurement可用区中,按照添加资产中的步骤,将您创建的offlinesales_curatedCloud Storage 存储桶添加为资产。
选择要探索的表
在 Google Cloud 控制台中,前往 Dataplex Universal Catalog 探索页面。
在数据湖字段中,选择
operations数据湖。点击
operations数据湖。前往
procurement区域,然后点击相应表以探索其元数据。在下图中,所选采购区域包含一个名为
Offline的表,其中包含以下元数据:orderid、product、quantityordered、unitprice、orderdate和purchaseaddress。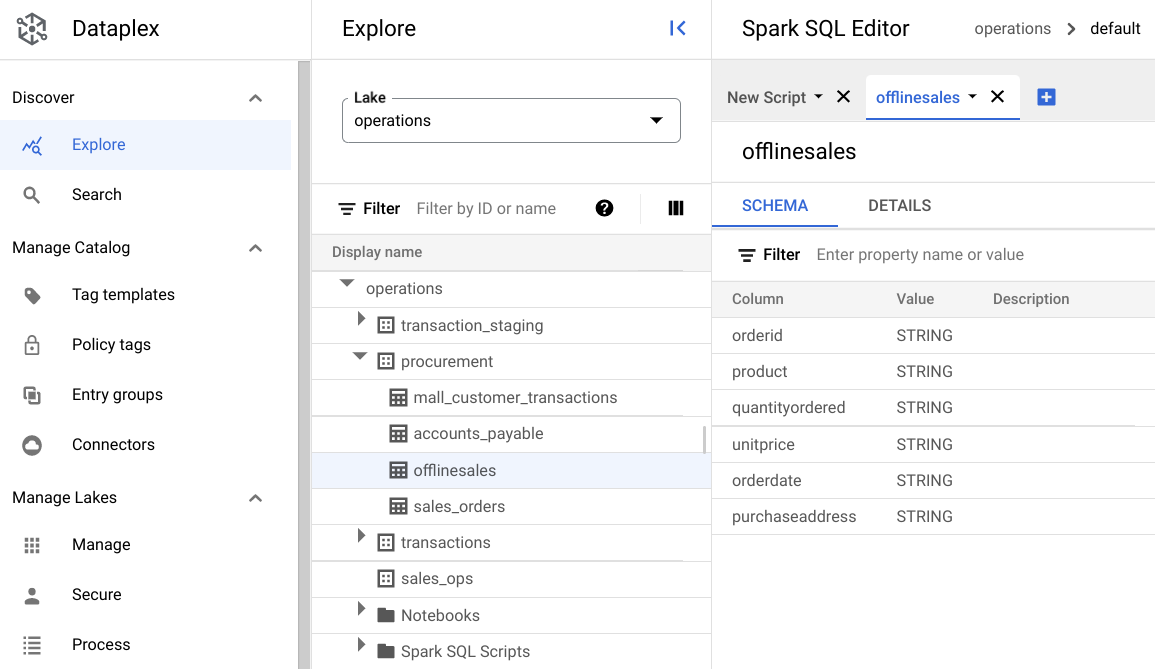
在 Spark SQL 编辑器中,点击 添加。系统会显示一个 Spark SQL 脚本。
可选:在拆分标签页视图中打开该脚本,以便并排查看元数据和新脚本。点击新脚本标签页中的 更多,然后选择将标签页拆分到右侧或将标签页拆分到左侧。
探索数据
环境为 Spark SQL 查询和笔记本提供无服务器计算资源,以便在数据湖中运行。在编写 Spark SQL 查询之前,请创建一个在其中运行查询的环境。
使用以下 SparkSQL 查询探索数据。在 SparkSQL 编辑器中,将查询输入到新脚本窗格中。
表中的 10 行示例
输入以下查询:
select * from procurement.offlinesales where orderid != 'orderid' limit 10;点击运行。
获取数据集中的交易总数
输入以下查询:
select count(*) from procurement.offlinesales where orderid!='orderid';点击运行。
查找数据集中不同产品类型的数量
输入以下查询:
select count(distinct product) from procurement.offlinesales where orderid!='orderid';点击运行。
查找交易价值较高的产品
通过按产品类型和平均销售价格细分销售数据,了解哪些产品的交易价值较高。
输入以下查询:
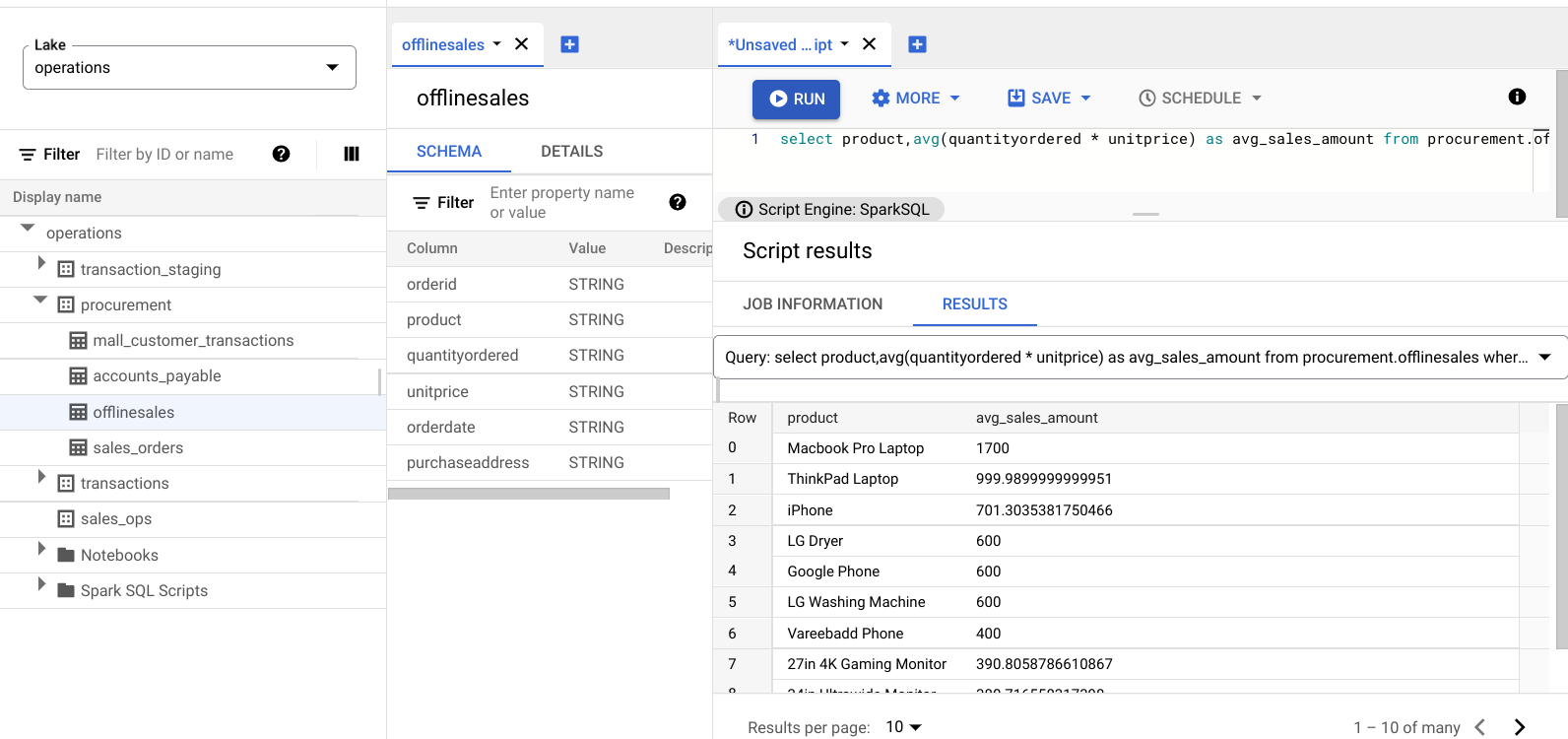
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;点击运行。
下图显示了一个 Results 窗格,该窗格使用名为 product 的列来识别交易价值较高的销售项,这些项显示在名为 avg_sales_amount 的列中。
使用变异系数检测异常
上一个查询表明,笔记本电脑的平均交易金额较高。以下查询展示了如何检测数据集中存在异常的笔记本电脑交易。
以下查询使用“变异系数”指标 rsd_value 来查找与平均值相比值分布较低的非异常交易。变异系数越低,异常就越少。
输入以下查询:
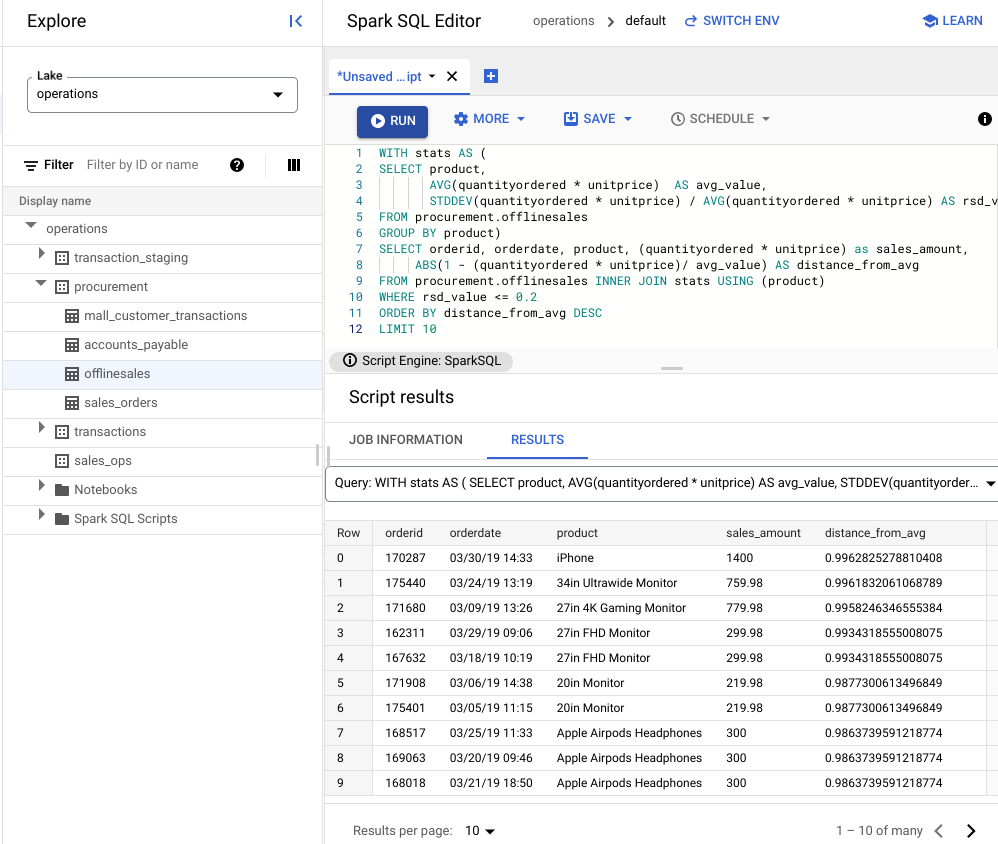
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10点击运行。
查看脚本结果。
在下图中,结果窗格使用一个名为“product”的列来识别交易价值在 0.2 变化系数范围内的销售项。
使用 JupyterLab 笔记本直观呈现异常
构建机器学习模型,以大规模检测和直观呈现异常。
在单独的标签页中打开该笔记本,然后等待其加载。您在其中执行 Spark SQL 查询的会话会继续。
导入必要的软件包,并连接到包含交易数据的 BigQuery 外部表。运行以下代码:
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()运行孤立森林算法以发现数据集中的异常:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())使用 Matplotlib 可视化绘制预测的异常:
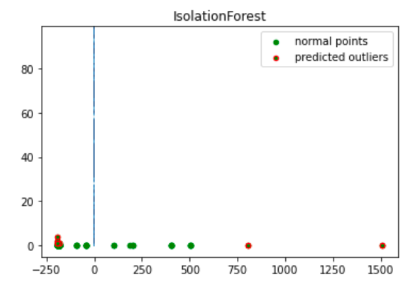
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
此图片显示了交易数据,其中异常以红色突出显示。
安排笔记本
Explore 可让您安排笔记本定期运行。按照相应步骤安排您创建的 Jupyter 笔记本。
Dataplex Universal Catalog 会创建一个安排任务来定期运行笔记本。如需监控任务进度,请点击查看时间表。
共享或导出笔记本
借助 Explore,您可以使用 IAM 权限与组织中的其他人共享笔记本。
查看角色。为此笔记本的用户授予或撤消 Dataplex Universal Catalog Viewer (roles/dataplex.viewer)、Dataplex Universal Catalog Editor (roles/dataplex.editor) 和 Dataplex Universal Catalog Administrator (roles/dataplex.admin) 角色。共享笔记本后,在数据湖级层具有查看者或编辑者角色的用户可以前往数据湖并在共享笔记本中进行操作。
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除项目
Delete a Google Cloud project:
gcloud projects delete PROJECT_ID
删除各个资源
-
删除存储分区:
gcloud storage buckets delete BUCKET_NAME
-
删除实例:
gcloud compute instances delete INSTANCE_NAME