BigQuery テーブルのデータリネージを追跡する
データリネージを使用すると、データがシステム内をどのように移動するか、つまりデータがどこから来て、どこに渡され、どのような変換がデータに適用されるかを追跡できます。
BigQuery のコピージョブとクエリジョブのデータリネージの追跡を開始する方法について学びます。
一般公開されている
new_york_taxi_tripsデータセットから 2 つのテーブルをコピーします。両方のテーブルのタクシー乗車数の合計を新しいテーブルに結合します。
3 つのオペレーションのリネージ可視化グラフを表示します。
始める前に
プロジェクトを設定する:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Data Catalog, BigQuery, and data lineage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Data Catalog, BigQuery, and data lineage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
必要なロール
リネージの可視化グラフを表示するために必要な権限を取得するには、次の IAM ロールの付与を管理者に依頼してください。
-
Data Catalog リソース プロジェクトの Data Catalog 閲覧者 (
roles/datacatalog.viewer) -
BigQuery を使用するプロジェクトのデータリネージ閲覧者(
roles/datalineage.viewer) -
BigQuery を使用するプロジェクトの BigQuery データ閲覧者(
roles/bigquery.dataViewer)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
一般公開データセットをプロジェクトに追加する
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、[追加] をクリックします。
[追加] ペインで
Public datasetsを検索し、[公開データセット] の結果を選択します。[Marketplace] ペインで「
NYC TLC Trips」を検索し、[NYC TLC Trips] の結果をクリックします。[データセットを表示] をクリックします。
これにより、一般公開データセットのプロジェクトが参照として追加され、[エクスプローラ] ペインで確認できるようになります。詳細ペインには、データセット ID、データのロケーション、最終更新日などのデータセット情報が表示されます。
プロジェクトにデータセットを作成する
[エクスプローラ] ペインで、データセットを作成するプロジェクトを選択します。
[アクション]、[データセットを作成] の順にクリックします。
[データセットを作成] ページの [データセット ID] フィールドに「
data_lineage_demo」と入力します。他のフィールドはデフォルト値のままにします。[データセットを作成] をクリックします。
[エクスプローラ] ペインで、新しく追加された
data_lineage_demoをクリックします。
詳細ペインにデータセット情報が表示されます。
一般公開されている 2 つのテーブルをデータセットにコピーする
クエリエディタを開きます。詳細ペインで、
data_lineage_demoという名前のタブの横にある (新しいクエリを作成)をクリックします。このステップでは、Untitledというタブが作成されます。クエリエディタで、次のクエリを入力して最初のテーブルをコピーします。
PROJECT_IDはプロジェクトの ID に置き換えます。CREATE TABLE `PROJECT_ID.data_lineage_demo.nyc_green_trips_2021` COPY `bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2021`[実行] をクリックします。 このステップでは、
nyc_green_trips_2021という最初のテーブルを作成します。[クエリ結果] ペインで、[テーブルに移動] をクリックします。この手順では、最初のテーブルの内容が表示されます。
クエリエディタで、前のクエリを次のクエリに置き換えて、2 番目のテーブルをコピーします。
PROJECT_IDはプロジェクトの ID に置き換えます。CREATE TABLE `PROJECT_ID.data_lineage_demo.nyc_green_trips_2022` COPY `bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2022`[実行] をクリックします。 このステップでは、
nyc_green_trips_2022という 2 番目のテーブルを作成します。[クエリ結果] ペインで、[テーブルに移動] をクリックします。このステップでは、2 番目のテーブルの内容が表示されます。
データを新しいテーブルに集計する
クエリエディタで、次のクエリを入力します。
PROJECT_IDはプロジェクトの ID に置き換えます。CREATE TABLE `PROJECT_ID.data_lineage_demo.total_green_trips_22_21` AS SELECT vendor_id, COUNT(*) AS number_of_trips FROM ( SELECT vendor_id FROM `PROJECT_ID.data_lineage_demo.nyc_green_trips_2022` UNION ALL SELECT vendor_id FROM `PROJECT_ID.data_lineage_demo.nyc_green_trips_2021` ) GROUP BY vendor_id[実行] をクリックします。 このステップでは、
total_green_trips_22_21という名前の結合されたテーブルを作成します。[クエリ結果] ペインで、[テーブルに移動] をクリックします。この手順では、結合されたテーブルが表示されます。
Dataplex でリネージグラフを表示する
Google Cloud コンソールで、Dataplex の [検索] ページに移動します。
[検索プラットフォームを選択] で、検索モードとして [Data Catalog] を選択します。
[検索] ボックスに「
total_green_trips_22_21」と入力し、[検索] をクリックします。結果リストで [
total_green_trips_22_21] をクリックします。この手順では、BigQuery テーブルの [詳細] タブが表示されます。[リネージ] タブをクリックします。
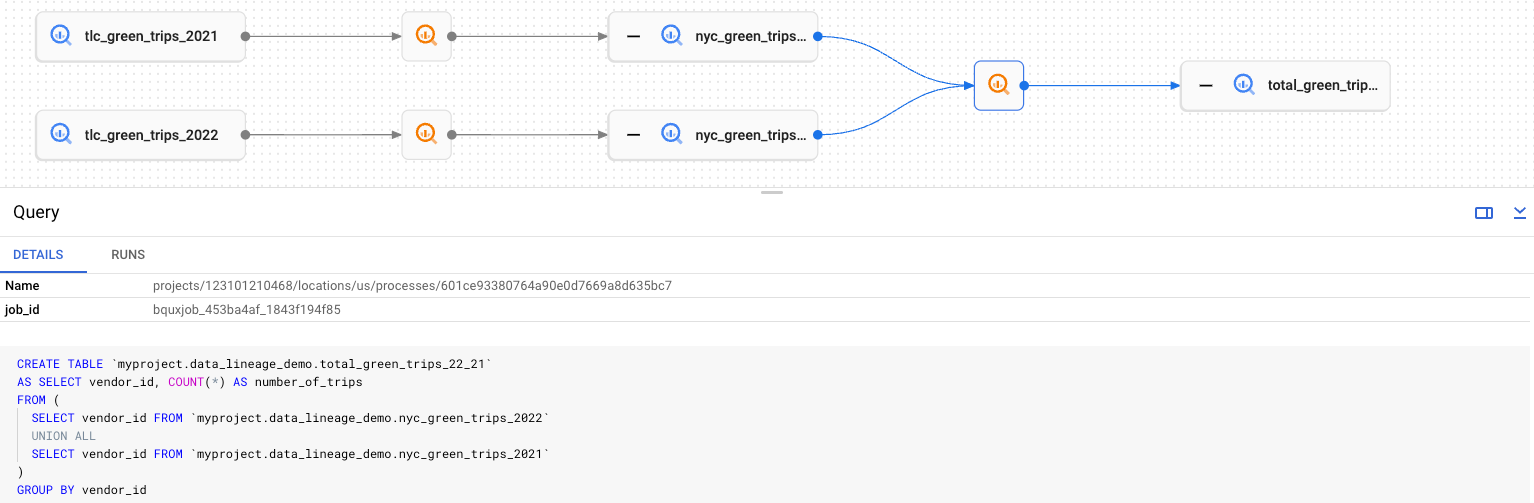
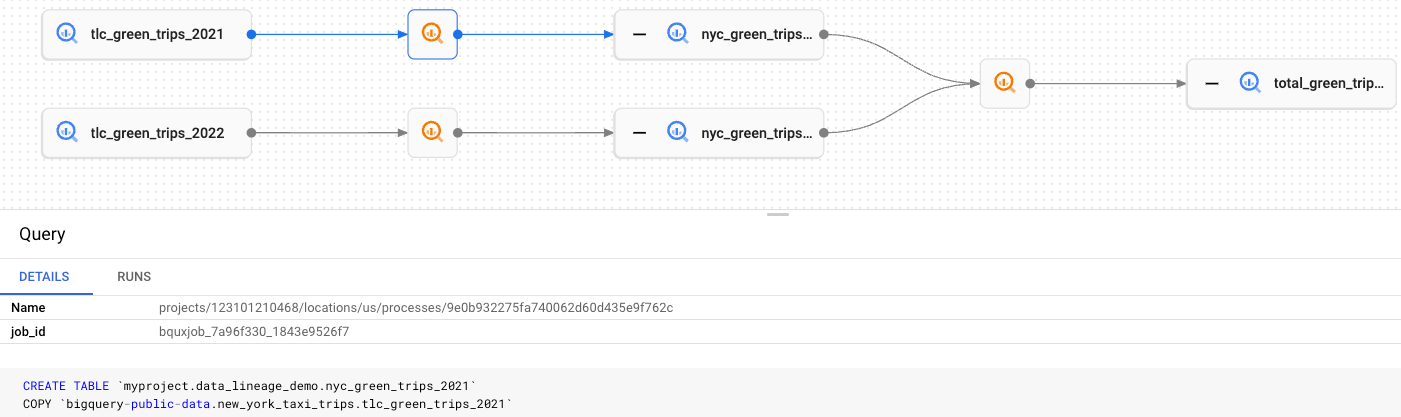
リネージグラフでは、各長方形ノードはテーブルを表します。テーブルは、元のテーブル、コピーされたテーブル、結合されたテーブルのいずれかです。以下の操作を行います。
テーブルの元データを表示または非表示にするには、[+](展開)または [-](閉じる)をクリックします。
テーブル情報を表示するには、ノードをクリックします。このステップでは、ノード [詳細] ペインが表示されます。
プロセス情報を表示するには、
 をクリックします。このステップでは、ソーステーブルをターゲット テーブルに変換したジョブを示すプロセスの [詳細] ペインが表示されます。
をクリックします。このステップでは、ソーステーブルをターゲット テーブルに変換したジョブを示すプロセスの [詳細] ペインが表示されます。
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の操作を行います。
プロジェクトの削除
課金をなくす最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
データセットの削除
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、作成した
data_lineage_demoデータセットを検索します。データセットを右クリックして、[削除] を選択します。
削除のアクションを確認します。
次のステップ
- Dataplex とデータリネージの詳細を確認する。
- BigQuery クエリを実行する方法を学習する。
- データリネージの使用方法とデータリネージ グラフを表示する方法を学習する。
- Dataplex の料金と請求について学習する。