Le 15 septembre 2026, tous les environnements Cloud Composer 1 et Cloud Composer 2 version 2.0.x atteindront leur fin de vie prévue et vous ne pourrez plus les utiliser. Nous vous recommandons de planifier la migration vers Cloud Composer 3.
Cette page explique comment utiliser les opérateurs Google Kubernetes Engine pour créer des clusters dans Google Kubernetes Engine et lancer des pods Kubernetes dans ces clusters.
Les opérateurs Google Kubernetes Engine exécutent des pods Kubernetes dans un cluster spécifié, qui peut être un cluster distinct et non lié à votre environnement.
En comparaison, KubernetesPodOperatorexécute les pods Kubernetes dans le cluster de votre environnement.
Cette page présente un exemple de DAG qui crée un cluster Google Kubernetes Engine avec GKECreateClusterOperator, utilise GKEStartPodOperator avec les configurations suivantes, puis le supprime avec GKEDeleteClusterOperator par la suite :
Pour suivre cet exemple, placez l'intégralité du fichier gke_operator.py dans le dossier dags/ de votre environnement ou ajoutez le code pertinent à un DAG.
Créer un cluster
Le code présenté ici crée un cluster Google Kubernetes Engine doté de deux pools de nœuds, pool-0 et pool-1, chacun disposant d'un nœud. Si nécessaire, vous pouvez définir d'autres paramètres à partir de l'API Google Kubernetes Engine dans le fichier body.
Nous vous recommandons d'utiliser des clusters régionaux dans Airflow 2. Les clusters zonaux sont plus exposés aux défaillances zonales. Par exemple, vous pouvez utiliser la région us-central1 pour votre cluster au lieu de la zone us-central1-a.
Pour en savoir plus sur les considérations spécifiques à la région, consultez Zones géographiques et régions.
Avant la sortie de apache-airflow-providers-google version 5.1.0, il n'était pas possible de transmettre l'objet node_pools dans GKECreateClusterOperator. Si vous utilisez Airflow 2, assurez-vous que votre environnement utilise apache-airflow-providers-google version 5.1.0 ou ultérieure. Vous pouvez installer une version plus récente de ce package PyPI en spécifiant apache-airflow-providers-google et >=5.1.0 comme version requise.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"node_pools":[{"name":"pool-0","initial_node_count":1},{"name":"pool-1","initial_node_count":1},],}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_REGION,body=CLUSTER,)
fromairflowimportmodelsfromairflow.providers.google.cloud.operators.kubernetes_engineimport(GKECreateClusterOperator,GKEDeleteClusterOperator,GKEStartPodOperator,)fromairflow.utils.datesimportdays_agofromkubernetes.clientimportmodelsask8s_modelswithmodels.DAG("example_gcp_gke",schedule_interval=None,# Override to match your needsstart_date=days_ago(1),tags=["example"],)asdag:# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"node_pools":[{"name":"pool-0","initial_node_count":1},{"name":"pool-1","initial_node_count":1},],}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_REGION,body=CLUSTER,)kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="perl:5.34.0",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Optional resource specifications for Pod, this will allow you to# set both cpu and memory limits and requirements.# Prior to Airflow 2.3 and the cncf providers package 5.0.0# resources were passed as a dictionary. This change was made in# https://github.com/apache/airflow/pull/27197# Additionally, "memory" and "cpu" were previously named# "limit_memory" and "limit_cpu"# resources={'limit_memory': "250M", 'limit_cpu': "100m"},container_resources=k8s_models.V1ResourceRequirements(limits={"memory":"250M","cpu":"100m"},),# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)delete_cluster=GKEDeleteClusterOperator(task_id="delete_cluster",name=CLUSTER_NAME,project_id=PROJECT_ID,location=CLUSTER_REGION,)create_cluster >> kubernetes_min_pod >> delete_clustercreate_cluster >> kubernetes_full_pod >> delete_clustercreate_cluster >> kubernetes_affinity_ex >> delete_clustercreate_cluster >> kubenetes_template_ex >> delete_cluster
Configuration minimale
Pour lancer un pod dans votre cluster GKE avec la commande GKEStartPodOperator, seules les options project_id, location, cluster_name, name, namespace, image et task_id doivent être définies.
Lorsque vous placez l'extrait de code suivant dans un DAG, la tâche pod-ex-minimum réussit tant que les paramètres répertoriés précédemment sont définis et valides.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)
Configuration du modèle
Airflow est compatible avec la modélisation Jinja.
Vous devez déclarer les variables requises (task_id, name, namespace, image) avec l'opérateur. Comme le montre l'exemple suivant, vous pouvez modéliser tous les autres paramètres avec Jinja, y compris cmds, arguments et env_vars.
Sans modification du DAG ou de votre environnement, la tâche ex-kube-templates échoue. Définissez une variable Airflow appelée my_value pour que ce DAG aboutisse.
Pour définir my_value avec gcloud ou l'interface utilisateur d'Airflow, procédez comme suit :
LOCATION par la région dans laquelle se trouve l'environnement.
Interface utilisateur d'Airflow
Dans l'interface utilisateur d'Airflow 2:
Dans la barre d'outils, sélectionnez Admin > Variables (Administration > Variables).
Sur la page List Variable (Variable de liste), cliquez sur Add a new record (Ajouter un enregistrement).
Sur la page Add Variable (Ajouter une variable), saisissez les informations suivantes :
Key (Clé) : my_value
Val (Valeur) : example_value
Cliquez sur Enregistrer.
Configuration du modèle :
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)
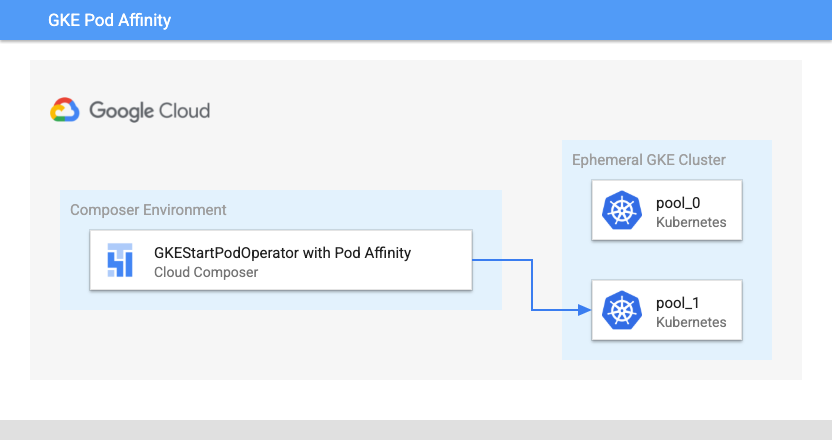
Configuration de l'affinité du pod
Lorsque vous configurez le paramètre affinity dans GKEStartPodOperator, vous contrôlez les nœuds sur lesquels les pods sont programmés, par exemple les nœuds d'un pool de nœuds spécifique. Lorsque vous avez créé votre cluster, vous avez créé deux pools de nœuds nommés pool-0 et pool-1. Cet opérateur indique que les pods ne doivent s'exécuter que dans pool-1.
Emplacement de lancement des pods Kubernetes de Cloud Composer avec affinité de pod (cliquez sur l'image pour l'agrandir)
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)
Configuration complète
Cet exemple présente toutes les variables que vous pouvez configurer dans GKEStartPodOperator. Il n'est pas nécessaire de modifier le code pour que la tâche ex-all-configs réussisse.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="perl:5.34.0",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Optional resource specifications for Pod, this will allow you to# set both cpu and memory limits and requirements.# Prior to Airflow 2.3 and the cncf providers package 5.0.0# resources were passed as a dictionary. This change was made in# https://github.com/apache/airflow/pull/27197# Additionally, "memory" and "cpu" were previously named# "limit_memory" and "limit_cpu"# resources={'limit_memory': "250M", 'limit_cpu': "100m"},container_resources=k8s_models.V1ResourceRequirements(limits={"memory":"250M","cpu":"100m"},),# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)
Supprimer le cluster
Le code présenté ici supprime le cluster créé au début de ce guide.
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/09/29 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/09/29 (UTC)."],[],[]]