Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Este tutorial mostra como usar o Cloud Composer para criar um DAG (gráfico acíclico orientado) do Apache Airflow que executa uma tarefa de contagem de palavras do Apache Hadoop num cluster do Dataproc.
Objetivos
- Aceda ao seu ambiente do Cloud Composer e use a IU do Airflow.
- Crie e veja variáveis de ambiente do Airflow.
- Crie e execute um DAG que inclua as seguintes tarefas:
- Cria um cluster do Dataproc.
- Executa uma tarefa de contagem de palavras do Apache Hadoop no cluster.
- Envia os resultados da contagem de palavras para um contentor do Cloud Storage.
- Elimina o cluster.
Custos
Neste documento, usa os seguintes componentes faturáveis do Google Cloud:
- Cloud Composer
- Dataproc
- Cloud Storage
Para gerar uma estimativa de custos com base na sua utilização projetada,
use a calculadora de preços.
Antes de começar
Certifique-se de que as seguintes APIs estão ativadas no seu projeto:
Consola
Enable the Dataproc, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud
Enable the Dataproc, Cloud Storage APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com No seu projeto, crie um contentor do Cloud Storage de qualquer classe de armazenamento e região para armazenar os resultados da tarefa de contagem de palavras do Hadoop.
Tome nota do caminho do contentor que criou, por exemplo,
gs://example-bucket. Vai definir uma variável do Airflow para este caminho e usar a variável no DAG de exemplo mais tarde neste tutorial.Crie um ambiente do Cloud Composer com parâmetros predefinidos. Aguarde até que a criação do ambiente esteja concluída. Quando terminar, a marca de verificação verde é apresentada à esquerda do nome do ambiente.
Tenha em atenção a região onde criou o seu ambiente, por exemplo,
us-central. Vai definir uma variável do Airflow para esta região e usá-la no DAG de exemplo para executar um cluster do Dataproc na mesma região.
Defina variáveis do Airflow
Defina as variáveis do Airflow para usar mais tarde no DAG de exemplo. Por exemplo, pode definir variáveis do Airflow na IU do Airflow.
| Variável de fluxo de ar | Valor |
|---|---|
gcp_project
|
O ID do projeto que está a usar para este tutorial, como example-project. |
gcs_bucket
|
O contentor do URI do Cloud Storage que criou para este tutorial, como gs://example-bucket |
gce_region
|
A região onde criou o seu ambiente, como us-central1.
Esta é a região onde o cluster do Dataproc vai ser criado. |
Veja o fluxo de trabalho de exemplo
Um DAG do Airflow é uma coleção de tarefas organizadas que quer agendar e executar. Os DAGs são definidos em ficheiros Python padrão. O código apresentado em
hadoop_tutorial.py é o código do fluxo de trabalho.
Operadores
Para orquestrar as três tarefas no fluxo de trabalho de exemplo, o DAG importa os seguintes três operadores do Airflow:
DataprocClusterCreateOperator: cria um cluster do Dataproc.DataProcHadoopOperator: envia uma tarefa de contagem de palavras do Hadoop e escreve os resultados num contentor do Cloud Storage.DataprocClusterDeleteOperator: elimina o cluster para evitar incorrer em custos contínuos do Compute Engine.
Dependências
Organiza as tarefas que quer executar de uma forma que reflita as respetivas relações e dependências. As tarefas neste DAG são executadas sequencialmente.
Agendamento
O nome do DAG é composer_hadoop_tutorial e o DAG é executado uma vez por dia. Uma vez que o start_date transmitido para default_dag_args está definido como yesterday, o Cloud Composer agenda o fluxo de trabalho para começar imediatamente após o DAG ser carregado para o contentor do ambiente.
Carregue o DAG para o contentor do ambiente
O Cloud Composer armazena DAGs na pasta /dags no contentor do seu ambiente.
Para carregar o DAG:
Na sua máquina local, guarde
hadoop_tutorial.py.Na Google Cloud consola, aceda à página Ambientes.
Na lista de ambientes, na coluna Pasta DAGs do seu ambiente, clique no link DAGs.
Clique em Carregar ficheiros.
Selecione
hadoop_tutorial.pyno seu computador local e clique em Abrir.
O Cloud Composer adiciona o DAG ao Airflow e agenda o DAG automaticamente. As alterações ao DAG ocorrem no prazo de 3 a 5 minutos.
Explore execuções de DAG
Veja o estado da tarefa
Quando carrega o ficheiro DAG para a pasta dags/ no Cloud Storage, o Cloud Composer analisa o ficheiro. Quando concluído com êxito, o nome do fluxo de trabalho aparece na lista de DAGs e o fluxo de trabalho é colocado em fila para ser executado imediatamente.
Para ver o estado da tarefa, aceda à interface Web do Airflow e clique em DAGs na barra de ferramentas.
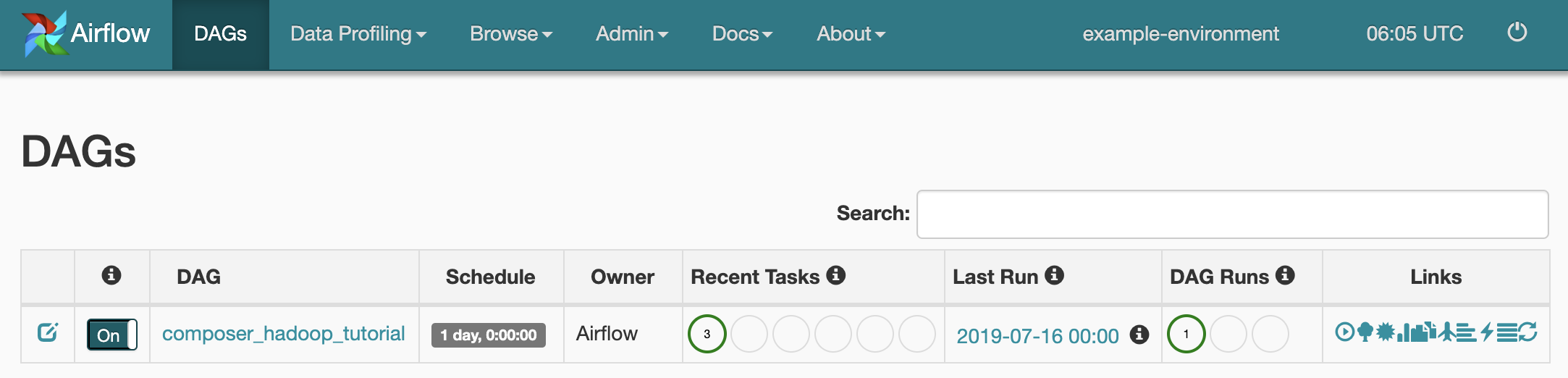
Para abrir a página de detalhes do DAG, clique em
composer_hadoop_tutorial. Esta página inclui uma representação gráfica das tarefas do fluxo de trabalho e das dependências.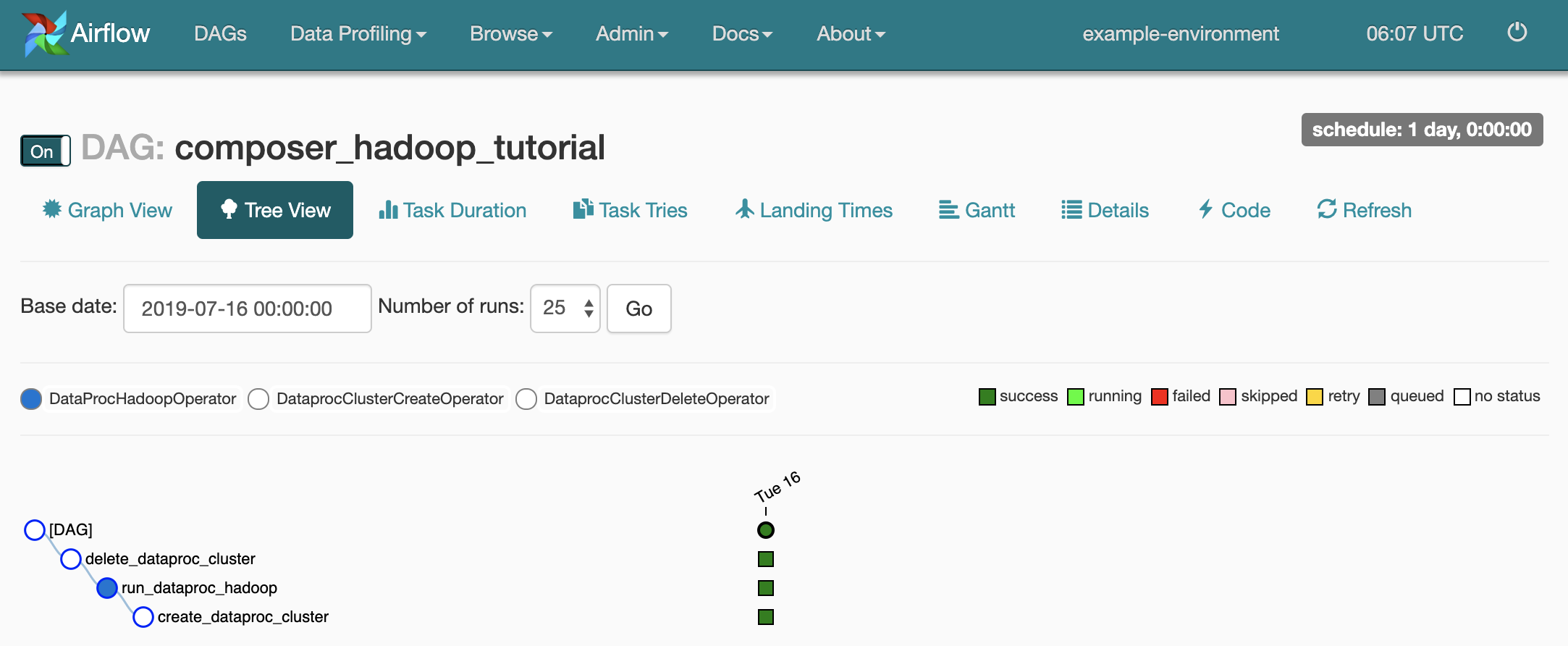
Para ver o estado de cada tarefa, clique em Vista de gráfico e, de seguida, passe o cursor do rato sobre o gráfico de cada tarefa.

Coloque o fluxo de trabalho novamente na fila
Para executar novamente o fluxo de trabalho a partir da vista de gráfico:
- Na vista de gráfico da IU do Airflow, clique no gráfico
create_dataproc_cluster. - Para repor as três tarefas, clique em Limpar e, de seguida, em OK para confirmar.
- Clique novamente em
create_dataproc_clusterna vista de gráfico. - Para colocar o fluxo de trabalho novamente na fila, clique em Executar.
Veja os resultados das tarefas
Também pode verificar o estado e os resultados do fluxo de trabalho acedendo às seguintes páginas da consola:composer_hadoop_tutorial Google Cloud
Clusters do Dataproc: para monitorizar a criação e a eliminação de clusters. Tenha em atenção que o cluster criado pelo fluxo de trabalho é efémero: só existe durante o fluxo de trabalho e é eliminado como parte da última tarefa do fluxo de trabalho.
Tarefas do Dataproc: para ver ou monitorizar a tarefa de contagem de palavras do Apache Hadoop. Clique no ID da tarefa para ver o resultado do registo de tarefas.
Navegador do Cloud Storage: para ver os resultados da contagem de palavras na pasta
wordcountno contentor do Cloud Storage que criou para este tutorial.
Limpeza
Elimine os recursos usados neste tutorial:
Elimine o ambiente do Cloud Composer, incluindo a eliminação manual do contentor do ambiente.
Elimine o contentor do Cloud Storage que armazena os resultados da tarefa de contagem de palavras do Hadoop.