Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
En esta página, se describe cómo usar DataflowTemplateOperator para iniciar canalizaciones de Dataflow desde Cloud Composer.
La canalización de Cloud Storage Text a BigQuery es una canalización por lotes que te permite subir archivos de texto almacenados en Cloud Storage, transformarlos con una función definida por el usuario (UDF) de JavaScript que proporciones y enviar los resultados a BigQuery.

Descripción general
Antes de iniciar el flujo de trabajo, crearás las siguientes entidades:
Una tabla de BigQuery vacía con un conjunto de datos vacío que contendrá las siguientes columnas de información:
location,average_temperature,monthy, de forma opcional,inches_of_rain,is_currentylatest_measurement.Un archivo JSON que normalizará los datos del archivo
.txtal formato correcto para el esquema de la tabla de BigQuery. El objeto JSON tendrá un array deBigQuery Schema, en el que cada objeto contendrá un nombre de columna, un tipo de entrada y si es o no un campo obligatorio.Un archivo
.txtde entrada que contendrá los datos que se subirán por lotes a la tabla de BigQuery.Una función definida por el usuario escrita en JavaScript que transformará cada línea del archivo
.txten las variables relevantes para nuestra tabla.Un archivo DAG de Airflow que apuntará a la ubicación de estos archivos.
A continuación, subirás el archivo
.txt, el archivo de UDF.jsy el archivo de esquema.jsona un bucket de Cloud Storage. También subirás el DAG a tu entorno de Cloud Composer.Después de que se suba el DAG, Airflow ejecutará una tarea desde él. Esta tarea iniciará una canalización de Dataflow que aplicará la función definida por el usuario al archivo
.txty lo formateará según el esquema JSON.Por último, los datos se subirán a la tabla de BigQuery que creaste antes.
Antes de comenzar
- En esta guía, se requiere estar familiarizado con JavaScript para escribir la función definida por el usuario.
- En esta guía, se supone que ya tienes un entorno de Cloud Composer. Consulta Crea un entorno para crear uno. Puedes usar cualquier versión de Cloud Composer con esta guía.
Enable the Cloud Composer, Dataflow, Cloud Storage, BigQuery APIs.
Asegúrate de tener los siguientes permisos:
- Roles de Cloud Composer: Crear un entorno (si no tienes uno), administrar objetos en el bucket del entorno, ejecutar DAGs y acceder a la IU de Airflow
- Roles de Cloud Storage: Crea un bucket y administra objetos en él.
- Roles de BigQuery: Crear un conjunto de datos y una tabla, modificar los datos de la tabla, modificar el esquema y los metadatos de la tabla
- Roles de Dataflow: Visualiza trabajos de Dataflow.
Asegúrate de que la cuenta de servicio de tu entorno tenga permisos para crear trabajos de Dataflow, acceder al bucket de Cloud Storage y leer y actualizar datos para la tabla en BigQuery.
Crea una tabla de BigQuery vacía con una definición de esquema
Crea una tabla de BigQuery con una definición de esquema. Usarás esta definición de esquema más adelante en esta guía. En esta tabla de BigQuery, se incluirán los resultados de la carga por lotes.
Para crear una tabla vacía con una definición de esquema, haz lo siguiente:
Console
En la consola de Google Cloud , ve a la página BigQuery:
En el panel de navegación, en la sección Recursos, expande tu proyecto.
En el panel de detalles, haz clic en Crear conjunto de datos.
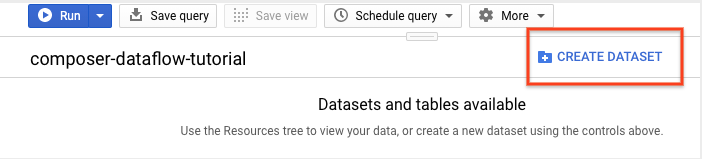
En la página Crear conjunto de datos, en la sección ID del conjunto de datos, asigna el nombre
average_weatheral conjunto de datos. Deja todos los demás campos con su estado predeterminado.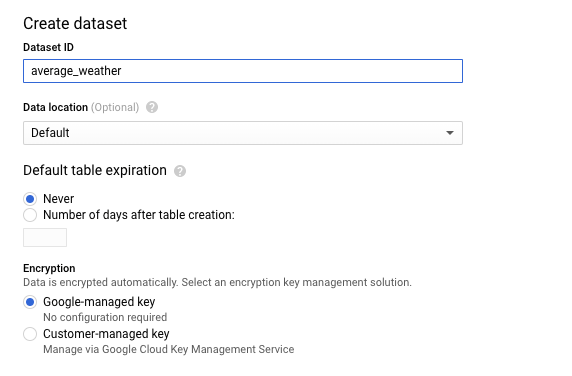
Haz clic en Crear conjunto de datos.
Regresa al panel de navegación, en la sección Recursos, expande tu proyecto. Luego, haz clic en el conjunto de datos
average_weather.En el panel de detalles, haz clic en Crear tabla (Create table).
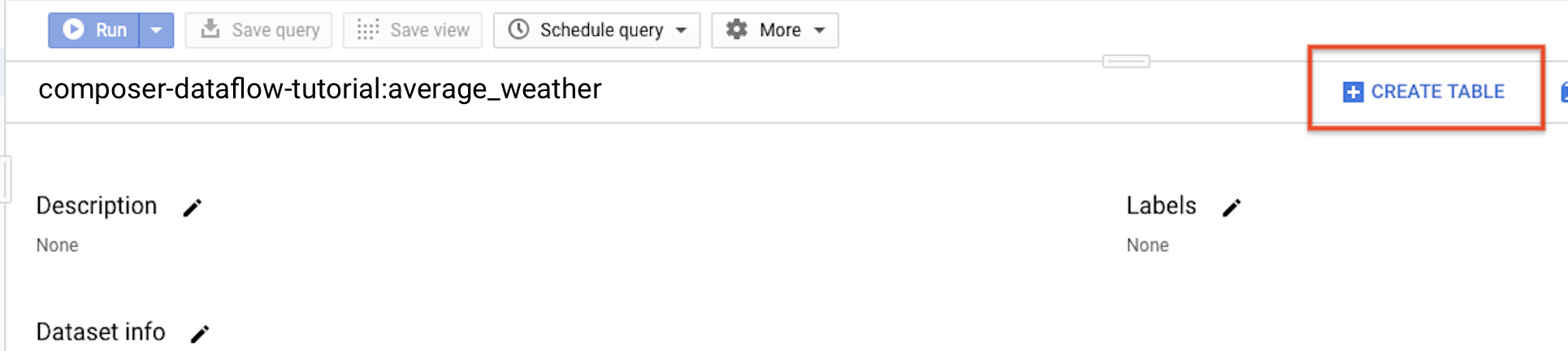
En la página Crear tabla, en la sección Origen, selecciona Tabla vacía.
En la sección Destination (Destino) de la página Create table (Crear tabla), haz lo siguiente:
En Nombre del conjunto de datos, selecciona el conjunto de datos
average_weather.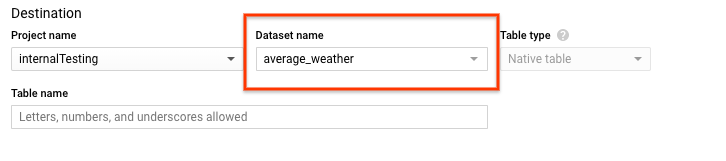
En el campo Nombre de la tabla, ingresa el nombre
average_weather.Verifica que Tipo de tabla esté establecido en Tabla nativa.
En la sección Esquema, ingresa la definición del esquema. Puedes usar uno de los siguientes enfoques:
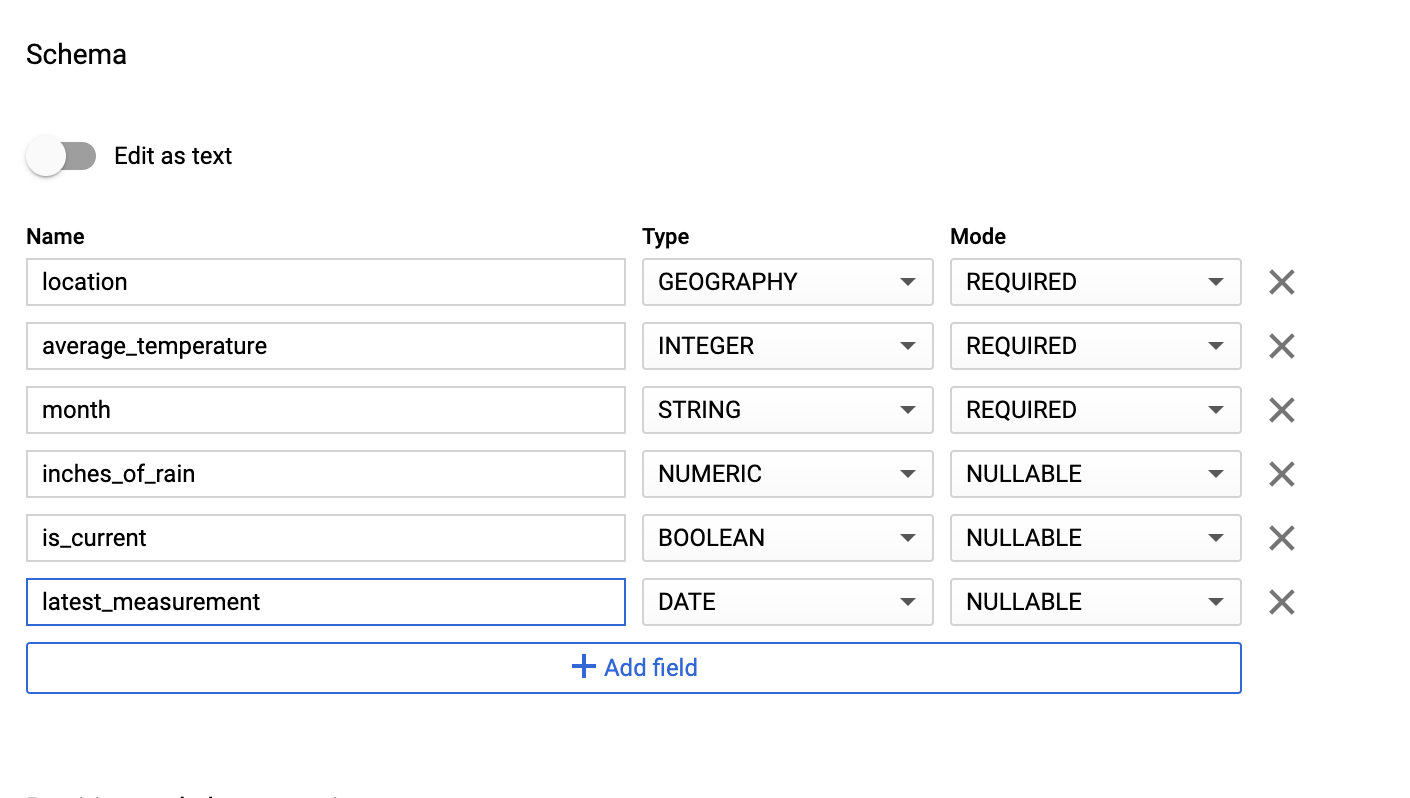
Ingresa la información del esquema de forma manual. Para ello, habilita Editar como texto y, luego, ingresa el esquema de la tabla como un arreglo JSON. Escribe en los siguientes campos:
[ { "name": "location", "type": "GEOGRAPHY", "mode": "REQUIRED" }, { "name": "average_temperature", "type": "INTEGER", "mode": "REQUIRED" }, { "name": "month", "type": "STRING", "mode": "REQUIRED" }, { "name": "inches_of_rain", "type": "NUMERIC" }, { "name": "is_current", "type": "BOOLEAN" }, { "name": "latest_measurement", "type": "DATE" } ]Usa Agregar campo para ingresar el esquema de forma manual:
En Configuración de partición y agrupamiento en clústeres, deja el valor predeterminado:
No partitioning.En la sección Opciones avanzadas, en Encriptación, deja el valor predeterminado,
Google-owned and managed key.Haz clic en Crear tabla.
bq
Usa el comando bq mk para crear un conjunto de datos vacío y una tabla en este conjunto.
Ejecuta el siguiente comando para crear un conjunto de datos del clima global promedio:
bq --location=LOCATION mk \
--dataset PROJECT_ID:average_weather
Reemplaza lo siguiente:
LOCATION: Es la región en la que se encuentra el entorno.PROJECT_ID: Es el ID del proyecto.
Ejecuta el siguiente comando para crear una tabla vacía en este conjunto de datos con la definición de esquema:
bq mk --table \
PROJECT_ID:average_weather.average_weather \
location:GEOGRAPHY,average_temperature:INTEGER,month:STRING,inches_of_rain:NUMERIC,is_current:BOOLEAN,latest_measurement:DATE
Una vez que se crea la tabla, puedes actualizar el vencimiento, la descripción y las etiquetas. También puedes modificar la definición de esquema.
Python
Guarda este código como dataflowtemplateoperator_create_dataset_and_table_helper.py y actualiza las variables en él para reflejar tu proyecto y ubicación; luego, ejecútalo con el siguiente comando:
python dataflowtemplateoperator_create_dataset_and_table_helper.py
Python
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Cree un bucket de Cloud Storage
Crea un bucket para almacenar todos los archivos necesarios para el flujo de trabajo. El DAG que crearás más adelante en esta guía hará referencia a los archivos que subas a este bucket de almacenamiento. Para crear un bucket de almacenamiento nuevo, sigue estos pasos:
Console
Abre Cloud Storage en la Google Cloud consola.
Haz clic en Crear depósito para abrir el formulario de creación de depósitos.
Ingresa la información de tu bucket y haz clic en Continuar para completar cada paso:
Especifica un Nombre único a nivel global para tu bucket. En esta guía, se usa
bucketNamecomo ejemplo.Selecciona Región para el tipo de ubicación. Luego, selecciona una Ubicación en la que se almacenarán los datos del bucket.
Selecciona Estándar como la clase de almacenamiento predeterminada para tus datos.
Selecciona el control de acceso Uniforme para acceder a los objetos.
Haz clic en Listo.
gcloud
Usa el comando gcloud storage buckets create:
gcloud storage buckets create gs://bucketName/
Reemplaza lo siguiente:
bucketName: Es el nombre del bucket que creaste anteriormente en esta guía.
Muestras de código
C#
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Ruby
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Crea un esquema de BigQuery con formato JSON para la tabla de salida
Crea un archivo de esquema de BigQuery con formato JSON que coincida con la tabla de salida que creaste antes. Ten en cuenta que los nombres, tipos y modos de campo deben coincidir con los definidos antes en el esquema de tu tabla de BigQuery. Este archivo normalizará los datos del archivo .txt en un formato compatible con el esquema de BigQuery. Asígnale el nombre jsonSchema.json a este archivo.
{
"BigQuery Schema": [
{
"name": "location",
"type": "GEOGRAPHY",
"mode": "REQUIRED"
},
{
"name": "average_temperature",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "month",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "inches_of_rain",
"type": "NUMERIC"
},
{
"name": "is_current",
"type": "BOOLEAN"
},
{
"name": "latest_measurement",
"type": "DATE"
}]
}
Crea un archivo JavaScript para dar formato a tus datos
En este archivo, definirás tu UDF (función definida por el usuario) que proporciona la lógica para transformar las líneas de texto en el archivo de entrada. Ten en cuenta que esta función toma cada línea de texto en tu archivo de entrada como su propio argumento, por lo que la función se ejecutará una vez por cada línea de tu archivo de entrada. Asígnale el nombre transformCSVtoJSON.js a este archivo.
Crea tu archivo de entrada
Este archivo contendrá la información que deseas subir a la tabla de BigQuery. Copia este archivo de forma local y asígnale el nombre inputFile.txt.
POINT(40.7128 74.006),45,'July',null,true,2020-02-16
POINT(41.8781 87.6298),23,'October',13,false,2015-02-13
POINT(48.8566 2.3522),80,'December',null,true,null
POINT(6.5244 3.3792),15,'March',14,true,null
Sube tus archivos a tu bucket
Sube los siguientes archivos al bucket de Cloud Storage que creaste antes:
- Esquema de BigQuery con formato JSON (
.json) - Función definida por el usuario de JavaScript (
transformCSVtoJSON.js) El archivo de entrada del texto que deseas procesar (
.txt)
Console
- En la consola de Google Cloud , ve a la página Buckets de Cloud Storage.
En la lista de buckets, haz clic en el tuyo.
En la pestaña Objetos del bucket, realiza una de las siguientes acciones:
Arrastra y suelta los archivos deseados desde tu escritorio o administrador de archivos en el panel principal de la Google Cloud consola.
Haz clic en el botón Subir archivos, selecciona los archivos que deseas subir en el cuadro de diálogo que aparece y haz clic en Abrir.
gcloud
Ejecuta el comando gcloud storage cp:
gcloud storage cp OBJECT_LOCATION gs://bucketName
Reemplaza lo siguiente:
bucketName: Es el nombre del bucket que creaste anteriormente en esta guía.OBJECT_LOCATION: Es la ruta de acceso local a tu objeto. Por ejemplo,Desktop/transformCSVtoJSON.js
Muestras de código
Python
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Ruby
Para autenticarte en Cloud Composer, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Configura DataflowTemplateOperator
Antes de ejecutar el DAG, configura las siguientes variables de Airflow.
| Variable de Airflow | Valor |
|---|---|
project_id
|
El ID del proyecto. Ejemplo: example-project. |
gce_zone
|
Es la zona de Compute Engine en la que se debe crear el clúster de Dataflow. Ejemplo: us-central1-a. Si deseas obtener más información sobre las zonas válidas, consulta Regiones y zonas. |
bucket_path
|
Ubicación del bucket de Cloud Storage que creaste anteriormente. Ejemplo: gs://example-bucket |
Ahora harás referencia a los archivos que creaste antes para crear un DAG que inicie el flujo de trabajo de Dataflow. Copia este DAG y guárdalo de forma local como composer-dataflow-dag.py.
Sube el DAG a Cloud Storage
Sube tu DAG a la carpeta /dags en el bucket de tu entorno. Una vez que la carga se haya completado correctamente, puedes verla si haces clic en el vínculo Carpeta de DAG en la página Entornos de Cloud Composer.
Consulta el estado de la tarea
- Ve a la interfaz web de Airflow.
- En la página de los DAG, haz clic en el nombre del DAG (por ejemplo,
composerDataflowDAG). - En la página de detalles de los DAG, haz clic en Graph View.
Verifica el estado:
Failed: La tarea tiene un cuadro rojo a su alrededor. También puedes mantener el puntero sobre la tarea y ver si aparece el mensaje Estado: con errores.Success: La tarea tiene un cuadro verde a su alrededor. También puedes mantener el puntero sobre la tarea y ver si aparece el mensaje Estado: correcto.
Después de unos minutos, puedes verificar los resultados en Dataflow y BigQuery.
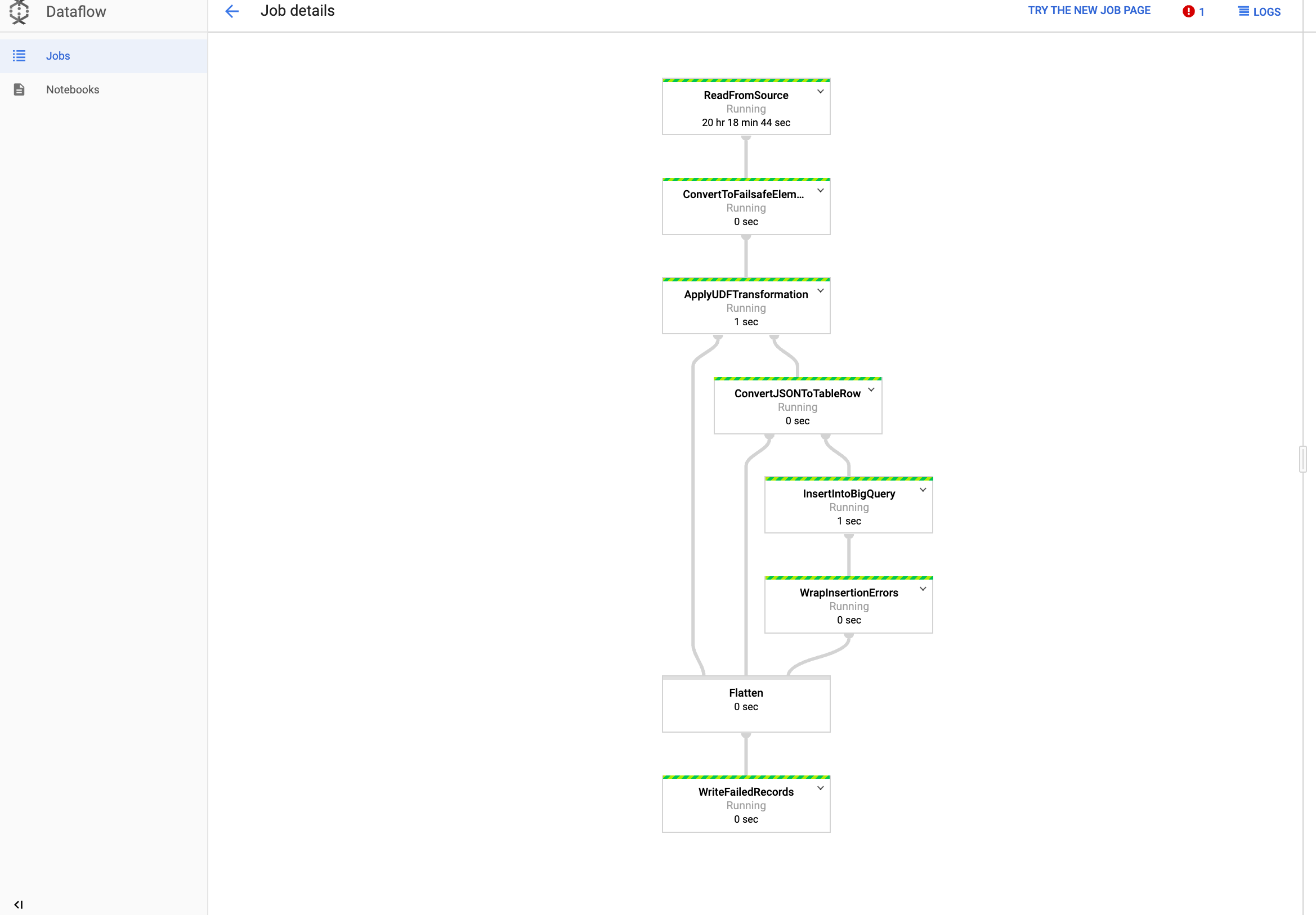
Visualiza tu trabajo en Dataflow
En la consola de Google Cloud , ve a la página Dataflow.
El trabajo se llamará
dataflow_operator_transform_csv_to_bqcon un ID único adjunto al final del nombre con un guion, como el siguiente:
Haz clic en el nombre para ver los detalles del trabajo.
Visualiza tus resultados en BigQuery
En la consola de Google Cloud , ve a la página BigQuery.
Puedes enviar una consulta mediante SQL estándar. Usa la siguiente consulta para ver las filas que se agregaron a su tabla:
SELECT * FROM projectId.average_weather.average_weather