Introduction to Google Cloud

Priyanka Vergadia
Staff Developer Advocate, Google Cloud
Imagine you are a Google Cloud Architect for foo.com, an internet accessible application. There are many different ways to architect such an application on Google Cloud; no one way is right or wrong. Let’s examine one approach, from the perspective of a generic request flow for when a user opens the browser and types foo.com in the address bar.
Domain Name System (DNS)
The request goes to the DNS server, which responds back with an IP address. Cloud DNS is Google’s infrastructure for high-volume authoritative DNS serving that offers 100% SLA (which means it never goes down). It uses Google’s global network of anycast name servers to serve DNS zones from redundant locations around the world, providing high availability and low latency for your users.
Web and application servers
The IP address obtained from the DNS is used by the user’s computer to make a connection to the web server where the code for the foo.com frontend is deployed. The application’s business logic is deployed on the application server. This includes functionalities such as authentication service, inventory, payment service, and so on. Requests to this application server are usually limited to only web servers and internal services. The web and application servers are housed inside VPC, which provides managed networking functionality for all Google Cloud resources.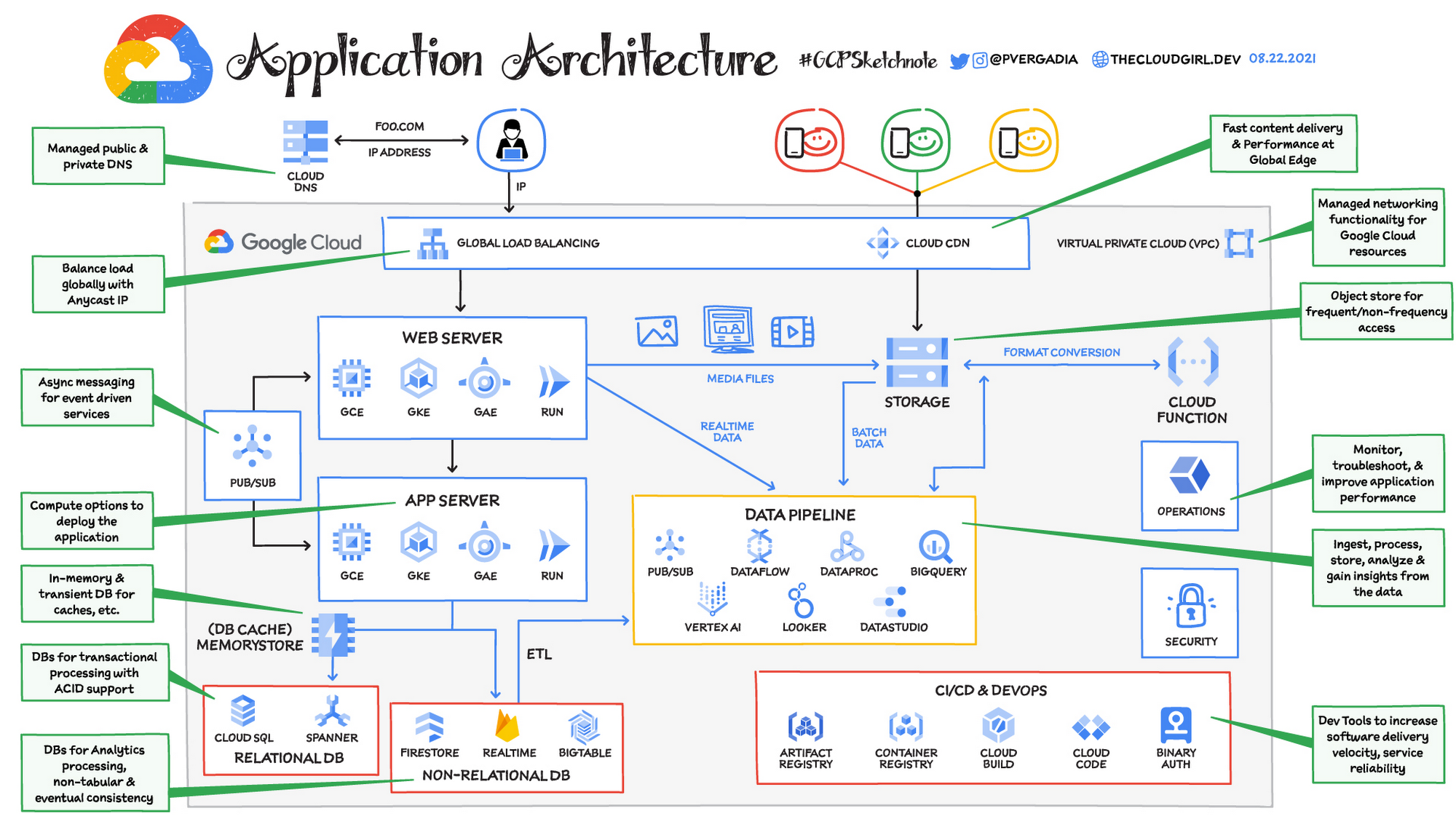
For web and application servers you have multiple options across Cloud Run, App Engine, GKE, and Compute Engine. Check out where I should run my stuff for more details.
Serverless: If you have a team of developers, you want them to focus on coding and not worry about infrastructure and scaling tasks. Cloud Run or App Engine would be great picks. Both are serverless and scale from low to high traffic as needed. If you want to run serverless containers serving web and event-driven microservices architectures, then Cloud Run is recommended. Cloud Run should work for most use cases, check out App Engine if you are developing websites with built-in static file hosting.
Google Kubernetes Engine (GKE): If you want to run containerized apps with more configuration options and flexibility then you can use GKE. It helps you easily deploy containerized apps with Kubernetes while giving you control over the configuration of nodes. Scaling is also easy; you can define the number of nodes to scale to as traffic grows. GKE also offers autopilot, when you need the flexibility and control but have limited ops and engineering support.
Compute Engine: Your other maximum-control option is Compute Engine. It is straight-up virtual machines (VMs), so you can precisely define the configuration of your machines depending on the amount of memory and CPU you need. This level of control, however, means you have more responsibility to scale, manage, patch, and maintain the VMs as needed. Compute Engine works well for legacy applications with specific needs and in situations that truly require full control.
Database
Of course, foo.com needs one or more databases to store information. These could be relational or non-relational databases depending on the type of data and the use case. (For more detailed guidance on picking the right database for your use case, see Your Google Cloud database options, explained.)
Google Cloud relational databases include Cloud SQL and Cloud Spanner, which are both managed.
Cloud SQL is perfect for generic SQL needs - MySQL, PostgreSQL, and SQL server.
Spanner is best for massive scale relational databases that need horizontal scalability. (Massive here means thousands of writes per second and tens of thousands of reads per second, while supporting ACID transactions.)
For non-relational databases Google Cloud has three major options: Firestore, Bigtable, and Memorystore.
Firestore is a serverless document database that provides strong consistency,supports ACID transactions, and delivers fast results to complex queries. It also supports offline data and syncs, which make it a great choice for mobile use cases along with web, IoT, and gaming.
Bigtable is a wide-column NoSQL database that supports heavy reads and writes with extremely low latency. This makes it a perfect choice for events, time series data from IoT devices, click stream data, ad events, fraud detection, recommendations and other personalization related use cases.
Memorystore is a fully managed in-memory data store service for Redis and Memcached. It’s best for transient stores and database caches.
Load balancing and scale
As the traffic grows you will need to scale the web and application servers with it. And, as the number of servers grows you will need a load balancer to route traffic to the web and application servers. Cloud Load Balancing is a fully distributed and software defined system based on anycast IP addresses, which means you can set up your frontend with a single IP address. It is also global, so it can serve content as close as possible to your users and respond to over a million queries per second. You can set up content-based routing decisions based on attributes, such as the HTTP header and uniform resource identifier. It also offers internal load balancing for internal application servers so you can route traffic amongst them as needed.
Content delivery network (CDN)
Static files don't change often, so CDN is used to cache these files and serve them from a location closest to the user, which helps reduce latency. Right at the load balancer you also have the option to enable Cloud CDN to cache frequently requested media and web content at the edge location closest to your users. This reduces latency and optimizes for last-mile performance. It also saves cost by fielding requests right at the edge, so they don’t have to be handled by the backend.
Object store
All static files for foo.com such as media files and images as well as CSS and JavaScript can be stored in an object store. In Google Cloud, Cloud Storage is your object store for both long- and short-term storage needs.
Serverless functions
Let’s say foo.com is also available on mobile devices, which need images rendered in smaller mobile formats. You can decouple functionality like this from the web server and make it a function-as-a-service with Cloud Functions. This approach enables you to apply your image resizing logic to other applications as well. You can trigger the serverless function as soon as a file is added to Cloud Storage and convert the file into multiple formats, storing them back into storage, where they are used by the web server. You could also use serverless functions for other use cases such as address lookups, chatbots, machine learning, and more.
Events
In certain situations foo.com might need to send messages, notifications to the user, or events between various microservices. This is where an asynchronous messaging service such as Cloud Pub/Sub can be used to push notifications to a topic and have other services subscribe to the topic and take appropriate action on it asynchronously.
Data analytics
Applications like foo.com generate real-time data (for example, clickstream data) and batch data (for example, logs). This data needs to be ingested, processed, and made ready for downstream systems in a data warehouse. From there it can be analyzed further by data analysts, data scientists, and ML engineers to gain insights and make predictions. You can ingest batch data from Cloud Storage or BigQuery and real-time data from the application using Pub/Sub, and scale to ingesting millions of events per second. Dataflow, based on open-source Apache Beam, can then be used to process and enrich the batch and streaming data. If you are in the Hadoop ecosystem then you can use Dataproc for processing; it is a managed Hadoop and Spark platform that lets you focus on analysis instead of worrying about managing and standing up your Hadoop cluster.
To store the processed data you need a data warehouse. BigQuery is a serverless data warehouse that supports SQL queries and can scale to petabytes of storage. It can also act as long term storage and a data lake along with Cloud Storage. You can use data from BigQuery to create a dashboard in Looker and Data Studio. With BigQuery ML you can create ML models and make predictions using standard SQL queries.
Machine learning
For ML/AI projects you can use the data in BigQuery to train models in Vertex AI. Your media, image, and other static file datasets from Cloud Storage can be directly imported into Vertex AI. You can create your own custom model or use the pretrained models. It’s a good idea to start with a pretrained model, and see if it works for you. Most common use cases are covered (including image, text, video, and tabular data). If a pretrained model does not work for your use case then use the AutoML model in Vertex AI to train a custom model on your own dataset. AutoML supports all the common use cases and requires no code. In case you have lots of ML and data science expertise in house, then you may decide to write your own custom model code in the framework of your choice. More on this in an upcoming post .
Operations
foo.com needs to be holistically monitored to make sure the servers and every part of its architecture is healthy. Google Cloud’s operations suite offers all the tools needed for logging, monitoring, debugging, and troubleshooting your application and infrastructure.
DevOps
You also need to make sure the foo.com development and operations teams have the right access and the right tools to build the application and deploy it. As Developers write the code for the app, they can use Cloud Code within the IDE to push the code to Cloud Build, which then packages and tests it, runs vulnerability scans on the code, invokes Binary Authorization to check for trusted container images, and once the tests are passed deploys the package to staging. From there you can create a process to review and promote to production. Container images are stored in Artifact Registry from where they can be deployed to GKE or Cloud Run. Compute Engine images are stored in your project.
Security
foo.com needs to be secured at the data, application, user/identity, infrastructure, and compliance level. This topic will be covered in detail in an upcoming post.
Wrap-up
That was one way of building a web application like foo.com on Google Cloud. I have provided you with a starting point, and possibilities from here are endless. Interested in getting started with building websites on Google Cloud? Check out these resources. For more #GCPSketchnote and similar cloud content, follow me on twitter @pvergadia and keep an eye out on thecloudgirl.dev