New open-source tools in Cloud Dataproc process data at cloud scale

Christopher Crosbie
Product Manager, Data Analytics
Last week’s Google Cloud Next ‘19 conference highlighted a multitude of new products, services, and features. One product with no shortage of announcements was Cloud Dataproc, our fully managed Apache Hadoop and Apache Spark service. Designed to be fast, easy, and cost-efficient, Cloud Dataproc’s feature set is constantly growing. In 2018 alone, we released more than thirty new features with the goal of bringing Apache Hadoop and Apache Spark into the cloud era by evolving the open-source ecosystem to be more cloud-native.
In this post, we’ll give you a whirlwind tour of the most recent Cloud Dataproc features announced last week. Everything listed here is publicly available today and ready for you to try.
The best of open source software
Cloud Dataproc brings the best of open source technology available today into Google Cloud Platform (GCP) so our users can access it. Here are some of the new ways you can incorporate open source software with your cloud infrastructure.
Cloud Dataproc version 1.4 now generally available
This latest image of Cloud Dataproc brings several new open source packages, including
Apache Spark 2.4
Python 3 and Miniconda 3
Support for Apache Flink 1.6 init action
The version 1.4 image also now defaults to a 1TB disk size when using the CLI to ensure consistently high I/O performance.

Support for Ubuntu 18
Ubuntu 18.04 LTS-based images versions are now in preview. You can use Ubuntu with Cloud Dataproc versions 1.3 and 1.4.
Kerberos security component in beta
The Kerberos security component for Cloud Dataproc is now in beta. While many customers have implemented robust security controls with Cloud Dataproc using GCP’s native identity and access management (IAM) capabilities, we know lots of you also want the option to incorporate the open source integrations that Kerberos provides. New functionality that the Kerberos security component unlocks includes the ability to:
Directly tie back Cloud Dataproc logins to Microsoft Active Directory
Prevent everything from running as root on the Cloud Dataproc instances
Enable Hadoop secure mode with a single checkbox action
Encrypt data in flight
Prevent users on the same cluster from interfering with other users’ jobs
New initialization actions
When creating a Cloud Dataproc cluster, you can specify initialization actions in executables or scripts that Cloud Dataproc will then run on all nodes in your cluster immediately after cluster setup. Initialization actions let you customize a cluster with everything you need for job dependencies (e.g., Apache Flink, Apache Ranger, etc.) so that you can submit jobs to the cluster without any need to manually install software.
The Cloud Dataproc team provides sample initialization action scripts in a GitHub repository for commonly installed OSS software. Some recently added initialization actions include:
- Apache Beam lets you do your own advanced tuning of Apache Beam jobs on Cloud Dataproc.
- Dr. Elephant helps with flow-level performance monitoring and tuning for Apache Hadoop and Apache Spark.
- Apache Gobblin simplifies common data integration tasks.
- While many Google Cloud customers use Cloud Bigtable for a NoSQL database with an HBase API, others prefer to use Apache HBase when they need co-processors or SQL functionality with Apache Phoenix.
- The Cloud Dataproc Jobs API is a way to provide controlled job submission through a secure perimeter. Apache Livy can help extend this to other cluster types or applications as well.
- Apache Prometheus is an open source monitoring and alerting toolkit that customers have used in conjunction with Stackdriver. Among various features, Prometheus provides a functional query language called PromQL (Prometheus Query Language) that lets you select and aggregate time series data in real time, which you may find useful for advanced time series analysis of your Cloud Dataproc logging.
- Many customers start their cloud journeys by first offloading batch and ETL jobs that might be slowing down or interfering with ad hoc analysis performed on their on-prem clusters. The Apache Ranger initialization action makes it possible to keep all your security policies in place when you start shifting data workloads to the cloud.
- Apache Solr is an open source enterprise search platform that allows sophisticated and customized search queries. If you have invested heavily in the Solr infrastructure, Cloud Dataproc offers an easy way to migrate to the cloud while keeping your Solr investments intact.
- Tensorflow on YARN (TonY) is a framework that lets you natively run deep learning jobs on Apache Hadoop. It currently supports TensorFlow and PyTorch. TonY makes it possible to run either single node or distributed training as a Hadoop application. This native connector, together with other TonY features, runs machine learning jobs reliably and flexibly.
New optional components for Cloud Dataproc

When you create a Cloud Dataproc cluster, standard Apache Hadoop ecosystem components are automatically installed on the cluster. You can install additional components, called "optional components," on the cluster when you create it. We’re excited to add a number of new optional components to Cloud Dataproc that provide fully pre-configured and supported open source tools as part of the Cloud Dataproc image.
In addition to updating the product launch stage of many optional components (updated list here), these components can now be installed with a single click in the Google Cloud Console as well, as shown here:

Druid alpha now publicly available
Apache Druid is a new public alpha component that you can use with Cloud Dataproc. This component provides an open-source, high-performance, distributed OLAP data store that is well-integrated with the rest of the big data OSS ecosystem. The Druid component installs Druid services on the Cloud Dataproc cluster master (Coordinator, Broker, and Overlord) and worker (Historical, Realtime and MiddleManager) nodes.
New Cloud Dataproc jobs in beta
There are also some new job types for Cloud Dataproc available now. You can submit a job to an existing Cloud Dataproc cluster via a Cloud Dataproc API jobs.submit HTTP or programmatic request, using the Cloud SDK gcloud command-line tool in a local terminal window. You can also use Cloud Shell or use the Cloud Console opened in a local browser.
Two new Cloud Dataproc job types are now in beta: Presto and SparkR.

Open, high-performing connectors
Our Cloud Dataproc team is directly involved in building the open source connectors alongside other Google Cloud engineering teams. That ensures that the Cloud Dataproc connectors open sourced to the community are optimized for working in Google Cloud. Here are some new features and improvements to our connectors:
Google Cloud Storage Connector

Improvements to the Cloud Storage Connector (starting in version 1.9.5) bring several enhancements, including:
Fadvise modes (sequential, random, auto)
Adaptive HTTP range requests (fadvise random and auto mode)
Lazy metadata initialization from HTTP headers
Metadata caching with list requests
Lazy footer prefetching
Consistent generation reads (latest, best effort, strict)
Multithreaded batch requests (copy, move, rename, delete operations)
Support for HDFS metadata attributes (allowing direct HDFS backups to GCS)
Cloud Spanner Connector in the works
Work on a Cloud Spanner Connector is underway. Cloud Spanner Connector for Apache Spark is a library that will support Apache Spark to access Cloud Spanner as an external data source or sink.
Apache Spark SQL Connector for BigQuery in beta
There’s a new Apache Spark SQL Connector for Google BigQuery. It has a number of advantages over using the previous export-based read flow that should lead to better read performance:
Direct streaming via the Storage API. This new connector streams data in parallel directly from BigQuery via gRPC without using Cloud Storage as an intermediary
Column and predicate filtering to reduce the data returned from BigQuery storage
Dynamic sharding, which rebalances records between readers so map phases will finish nearly concurrently.
Auto-awesomeness
In addition to providing big data open source software support, management, and integration, Cloud Dataproc also offers new capabilities that let you automate your data workloads and modernize your Apache stack as you move to the cloud.
Here are some of the latest innovations coming out of Cloud Dataproc that you can try for yourself.
Component Gateway in alpha: Automatic access to web interfaces
Some of the core open-source components included with Cloud Dataproc clusters, such as Apache Hadoop and Apache Spark, provide web interfaces. These interfaces can be used to manage and monitor cluster resources and facilities, such as the YARN resource manager, the Hadoop Distributed File System (HDFS), MapReduce, and Spark. Component Gateway provides secure access to web endpoints for Cloud Dataproc core and optional components.
Clusters created with Cloud Dataproc image version 1.3 and later can enable access to component web interfaces without relying on SSH tunnels or modifying firewall rules to allow inbound traffic.
Component Gateway automates an installation of Apache Knox and configures a reverse proxy for your components, making the web interfaces easily accessible only to those users who have dataproc.clusters.use IAM permission. You can opt in to the gateway in Cloud Console, like this:

Workflow templates, now in Cloud Console: Auto-configuring frequent efforts
The Cloud Dataproc WorkflowTemplates API provides a flexible and easy-to-use mechanism for managing and executing workflows. A Workflow Template is a reusable workflow configuration. It defines a graph of jobs with information on where to run those jobs. You can now view these workflows and workflow templates in the Cloud Console, as shown here:
Autoscaling clusters, now in beta
Estimating the right number of cluster workers (nodes) for a workload is difficult, and a single cluster size for an entire pipeline is often not ideal. User-initiated cluster scaling partially addresses this challenge, but requires monitoring cluster utilization and manual intervention.
The Cloud Dataproc AutoscalingPolicies API provides a mechanism for automating cluster resource management and enables cluster autoscaling. An autoscaling policy is a reusable configuration that describes how clusters using the autoscaling policy should scale. It defines scaling boundaries, frequency, and aggressiveness to provide fine-grained control over cluster resources throughout the cluster’s lifetime.
Enhanced Flexibility Mode in alpha
Cloud Dataproc Enhanced Flexibility Mode is for clusters that use preemptible VMs or autoscaling. When a Cloud Dataproc node becomes unusable due to a node loss, the stateful data that was produced is persevered. This can minimize disruptions to running jobs while still allowing for rapid scale down.
It is often cost-effective to use preemptible VMs, which have lower per-hour compute costs, for long-running workloads or large clusters. However, VM preemptions can be disruptive to applications, causing jobs to be delayed or fail entirely. Autoscaling clusters can run into similar issues. Enhanced flexibility mode mitigates these issues by saving intermediate data to a distributed file system.
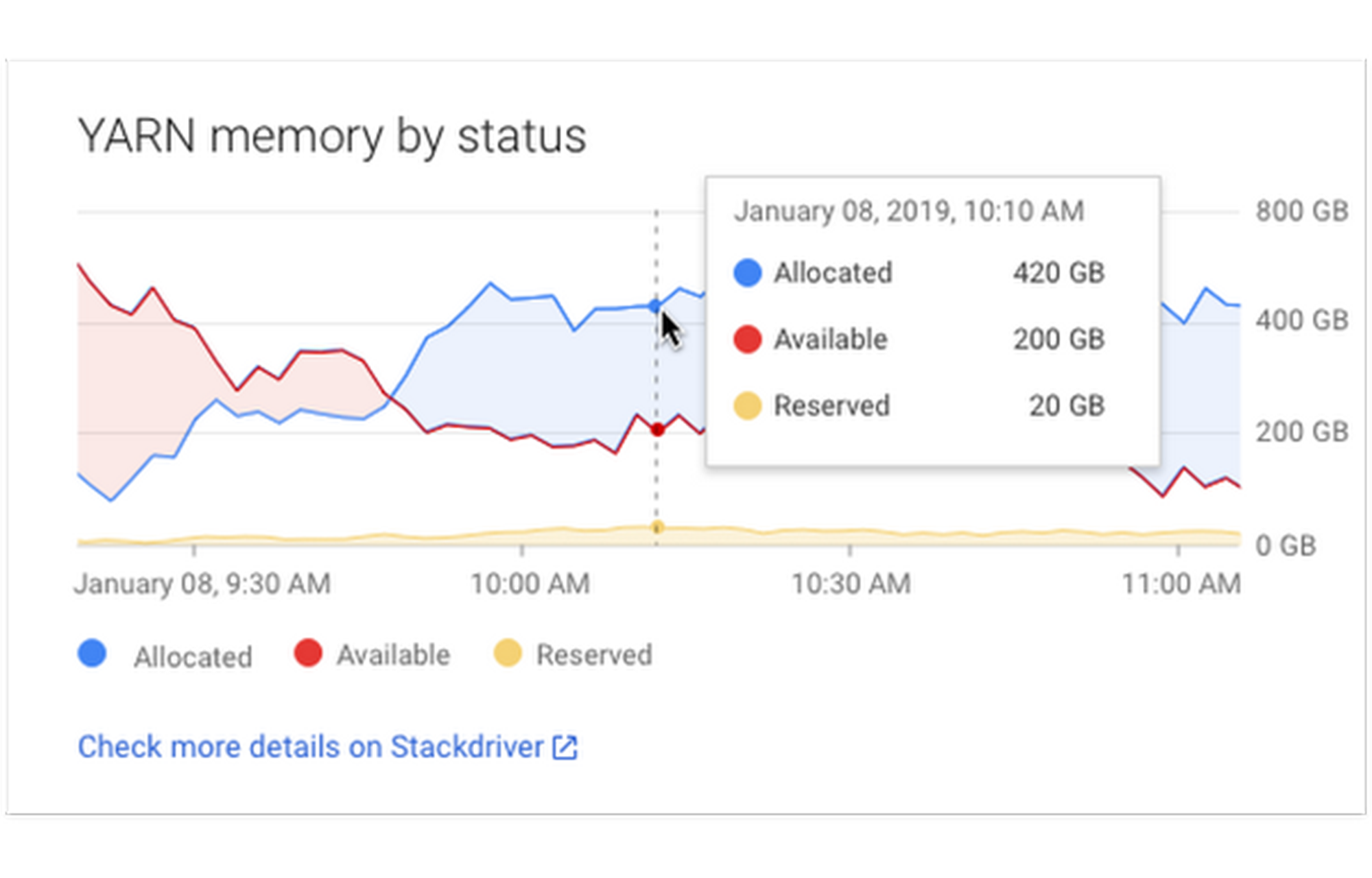
Improved Stackdriver integration
Stackdriver Monitoring provides visibility into the performance, uptime, and overall health of cloud-powered applications. Stackdriver collects and ingests metrics, events, and metadata from Cloud Dataproc clusters to generate insights via dashboards and charts. You can use Stackdriver to understand the performance and health of your Cloud Dataproc clusters and examine HDFS, YARN, and Cloud Dataproc job and operation metrics.
Recent improvements to this Stackdriver integration include more Cloud Dataproc information:
Job logs in Stackdriver
Job driver information
Linked directly to container logs
Additional metrics available in Cloud Console
Getting started with new Cloud Dataproc features
Cloud Dataproc already offers many core features that enhance running your familiar open-source tools, such as
Rapid cluster creation
Customizable machines
Ephemeral clusters that can be created on demand
Tight integration with other GCP services
Cloud Dataproc also provides the ability to develop architectures that support both:
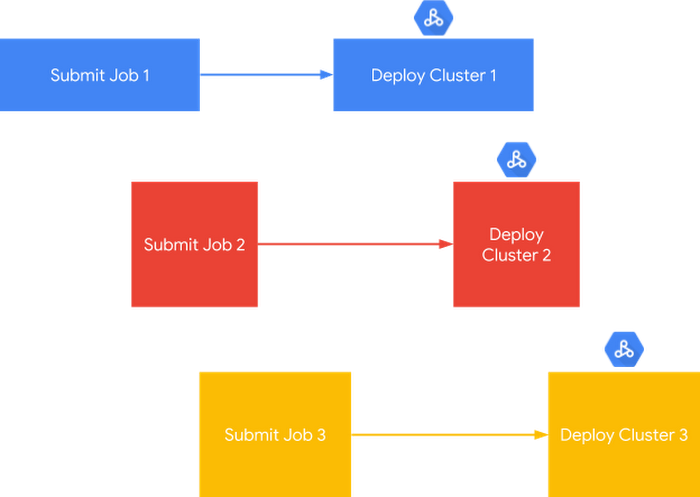
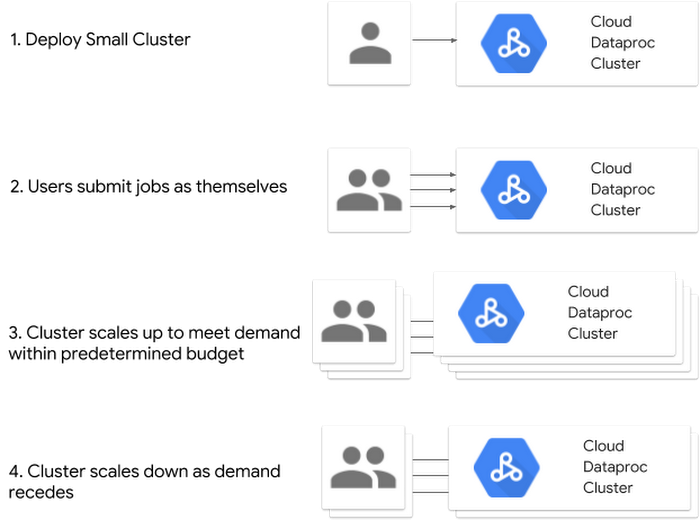
One major advantage of open source software is its dynamic nature—an active development community can provide frequent updates, useful fixes, and innovative features. Coupling this with the knowledge that Google brings in supporting and managing big data workloads, along with unique and open cloud-native features, makes Cloud Dataproc an ideal engine for running and modernizing big data open source software.
All the Cloud Dataproc features listed are ready for use today, to bring flexibility, predictability, and certainty to your data processing workloads. You can test out Cloud Dataproc with one of our Quickstarts or how-to guides.
In case you missed them, here are some of the Cloud Dataproc breakout sessions from Cloud Next 2019 that are now available on YouTube.
- Cloud Dataproc’s Newest Features
- Data Science at Scale with R on GCP
- How Customers Are Migrating Hadoop to Google Cloud Platform
- Data Processing in Google Cloud: Hadoop, Spark, and Dataflow
- Building and Securing a Data lake on Google Cloud Platform
- Machine Learning with Tensorflow and PyTorch on Apache Hadoop using Cloud Dataproc
