Extending the SQL capabilities of your Cloud Dataproc cluster with the Presto optional component
Christopher Crosbie
Group Product Manager
Jerry Ding
Software Engineer, Cloud Dataproc
Presto is an open source, distributed SQL query engine for running interactive analytic queries against data sources of all sizes. We are happy to announce that the Presto Distributed SQL Query Engine for Big Data is now available in public beta as an optional component for Cloud Dataproc, our fully managed cloud service for running Apache Spark and Hadoop clusters. Optional components like Presto let you expand the number of open source software applications running on your clusters. These optional components bring fast cluster startup times, integration testing with the rest of Cloud Dataproc, and support from Google Cloud Platform (GCP).
You might be thinking, “Why would I possibly need another SQL engine?” Cloud Dataproc already offers SparkSQL and Hive on Tez for SQL job types. Plus, Cloud Dataproc already has a connector to BigQuery, GCP’s serverless enterprise data warehouse that uses standard SQL.
What makes Presto unique is that a single Presto query can efficiently process data from multiple sources such as HDFS, Cloud Storage, MySQL, Cassandra, or even Kafka. It’s a well-supported methodology that runs federated queries across large-scale Cloud Dataproc instances and those other sources. So the connector becomes a great tool for ad hoc analysis and lets you quickly answer one-off questions that require linking disparate systems. (We’ll walk through an example of one of these questions using publicly available Chicago taxi data later in this post.)
Presto can also help you plan out your next BigQuery extract, transform, and load (ETL) jobs. With Presto, you can query various data sources across both on-premises systems and other clouds. This lets you better understand how to link the datasets, determine what data is needed, and design a wide and denormalized BigQuery table that encapsulates information from multiple underlying source systems.
Why you might run Presto on Cloud Dataproc
The Cloud Dataproc optional component means Cloud Dataproc takes care of the cluster integration and testing of Presto, so you won’t need to write scripts that tie together coordinators and workers, configure Presto to leverage your Hive metastore, and keep those scripts updated with the latest versions of Presto.
Since optional components are part of the Cloud Dataproc image, you can expect any newly provisioned Presto cluster to be up and running in less than 90 seconds, on average. This fast startup time translates into rapid data queries without the need to leave a cluster up and running or spend time waiting for a cluster to provision itself. You can think of a question and create a Presto cluster on Cloud Dataproc to answer that question without losing your train of thought.
There is no additional charge for Presto other than the standard Cloud Dataproc pricing, so Cloud Dataproc is a cost-effective way to run Presto. Since Presto is often used to explore unfamiliar datasets and can scale to petabyte-sized queries, a pricing model where you pay by the data scanned per query could get prohibitively expensive. Cloud Dataproc only charges for the underlying resources that you specify. You can use autoscaling clusters in conjunction with Presto, so you get the flexibility of increasing compute resources when you need them but staying within a predefined budget.
Setting up Presto on Cloud Dataproc
A common architecture pattern associated with Cloud Dataproc and Presto is joining your big data to reference data stored in a separate relational database. That could be in Cloud SQL, as this example shows, but could also be on-prem or in another cloud. We’ll walk through this architecture to help explain the configuration and offer some best practices for creating persisting tables and views across multiple Presto clusters.
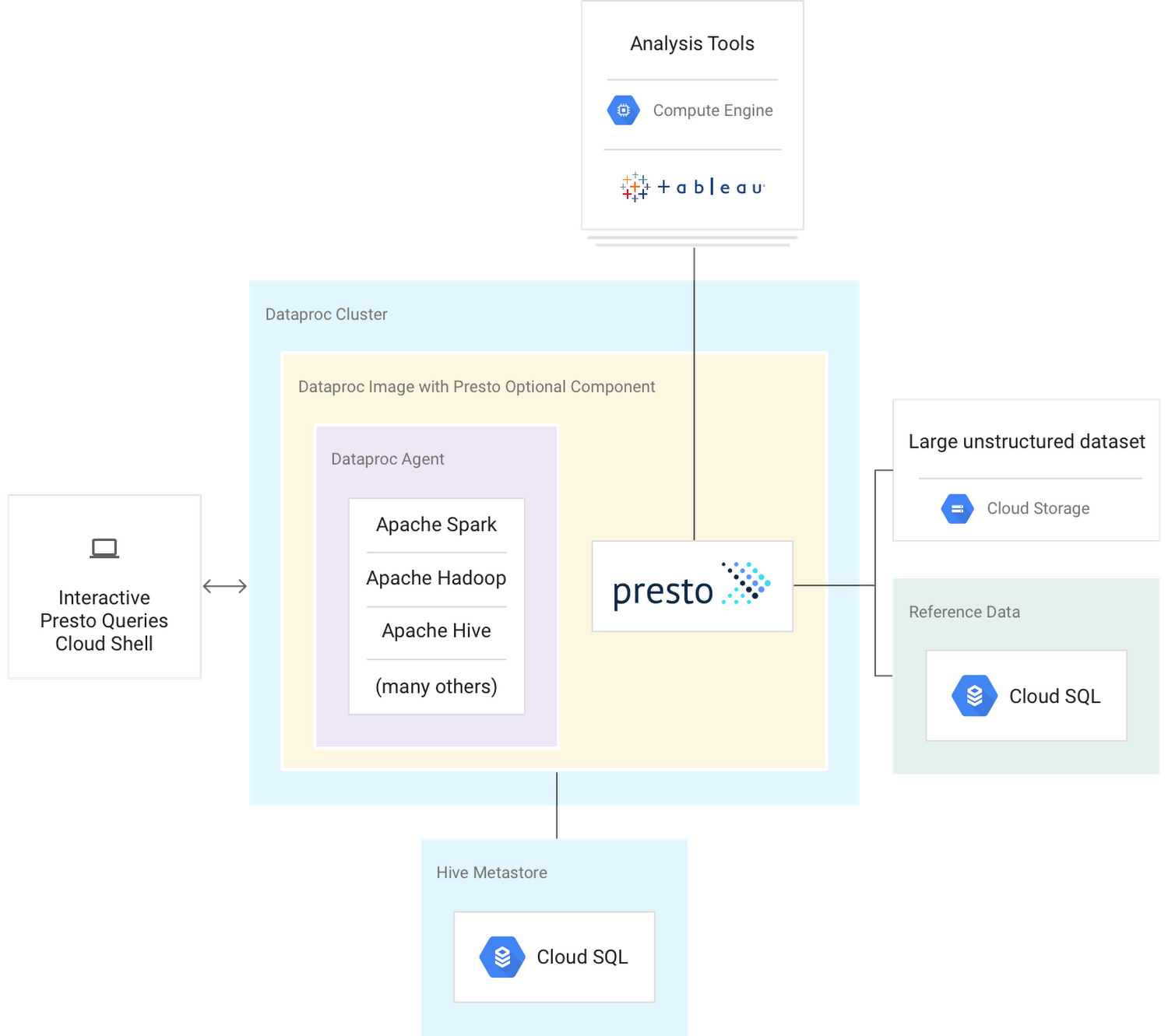
Cloud Dataproc’s agent binary runs on the virtual machine and receives job requests from the Cloud Dataproc server. It is also responsible for spawning the driver programs that run customer-supplied code. Since Presto runs as an optional component, it is not directly integrated with this Cloud Dataproc agent. And since Presto does not directly interact with the Dataproc agent, it is susceptible to task failures. One small hiccup could cause a query to fail. You can mitigate these failures by breaking up a large query on petabytes of data into smaller queries and then aggregate the final results from those multiple queries. If you’d like to learn more about the Dataproc agent, see Life of a Cloud Dataproc Job.
2. Dataproc image with Presto optional component
Optional components such as Presto are built into the Cloud Dataproc image, configured to work on the Cloud Dataproc cluster, and they’re tested regularly. The distinction when using optional components is that they typically do not interact with the Cloud Dataproc agent and are not automatically installed on a Cloud Dataproc cluster.
To create a Cloud Dataproc cluster with the Presto optional component, simply run:
For more, see Cloud Dataproc’s optional components documentation.
3. Large unstructured datasets
Large unstructured datasets typically reside in Cloud Storage. The definition of “unstructured” in this example is not only text, videos, or images. It can also be log files, SQL backups, messaging system output, metadata, genomic sequencer information (BAM/VCF) or any other text-heavy information that is not properly structured and not yet consumable by the business.
Presto makes it easy to explore these large unstructured datasets and quickly join them to other known or reference sources. The optional component automatically configures Presto to use the Cloud Dataproc Hive metastore. So you can use Hive to create external tables that put structure on top of the unstructured Cloud Storage objects, then query those objects using Presto’s SQL.
For more on using external tables with Cloud Storage and setting up a persistent Hive metastore in CloudSQL, check out Using Apache Hive on Cloud Dataproc.
4. Persistent Hive metastore
While we’re talking about the Hive metastore, it’s worth mentioning moving the Hive metastore off the Cloud Dataproc cluster. This separation will give you multiple Presto clusters that use the same Hive metastore information and maintain the table structures and view logic without having to keep a Cloud Dataproc cluster up and running. The easiest way to set up this architecture is by running the Cloud SQL proxy `init` action alongside the Presto optional component. An example of a cluster creation statement for this would look like this:
For more on using the initialization action, check out Cloud SQL I/O and Hive Metastore.
5. Reference data
Presto’s various connectors let you run federated queries against large unstructured datasets and reference datasets. A connector adapts Presto to a data source; you can think of a connector like a database driver. Presto provides various built-in connectors and is also extensible. There are third-party connectors available, or if needed, you could build your own. You can learn more about Presto concepts in Presto’s connectors documentation. See below for more on adding new connectors to Cloud Dataproc.
6. Analysis tools
Presto can also be used with reporting and analysis tools such as Tableau to help you identify patterns and outliers in your cross-database queries so you can quickly answer more complicated questions or better prepare your ETL requirements.
When you connect to Tableau or any other web interface or tool, you should make sure you are not inadvertently exposing ports such as 8088 to the public internet. Open ports and improperly configured firewall rules on a public network can allow unauthorized users to execute arbitrary code on your Cloud Dataproc cluster.
Check out the cluster Web interfaces documentation on how to set up a secure connector to tools such as Tableau.
How to add a new connector to Cloud Dataproc
The Presto optional component will automatically set up a connection from the Cloud Dataproc Apache Hive metastore to Presto. Here, let’s walk through the steps for adding additional Presto connectors. In this example, we will add a MySQL database. You can follow a similar process for any type of connector.
Step 1: Create a properties file containing your connector information.
The file name should conform to the following format:
For this MySQL database, create a file called mysql.properties containing the following:
In this example, since you’ve used theCloud SQL proxy `init` action, you can reach the Cloud SQL-based MySQL instance securely over `localhost`.
For additional information about configuring a MySQL connection, see the Presto MySQL connector page. Similar pages are available for each connector type.
Step 2: Copy or move your file.
On the cluster, copy or move your customized properties file to /var/presto/data/etc/catalog/
Step 3: Restart the Presto service.
In Cloud Dataproc, you can restart the service by calling:
Step 4: Rinse and repeat.
Unless you use a single-node cluster, trying to run a query against the new connector at this point will simply produce an error of “No nodes available to run query.” You’ll need to repeat these steps for each worker node in the Cloud Dataproc cluster.
For a running cluster, consider automating this task by modifying a script such as the following:
If you know in advance which connectors you’ll want to use, you can also use initialization actions to run those commands on every node in the cluster on startup. For more, take a look at the documentation on initialization actions.
Putting Presto into practice
Now that we’ve explored our Presto environment, it’s time for the fun part: using Presto to better understand our various data sources. This example source will let us explore data about taxi trips in Chicago.
As a preliminary step, you may want to run through this short tutorial on using Presto with Cloud Dataproc. The rest of the steps make an assumption that we have created a Hive external table `chicago_taxi_trips_parquet` that consists of Cloud Storage data structured by metadata in our Cloud Dataproc Hive metastore.
Starting Presto
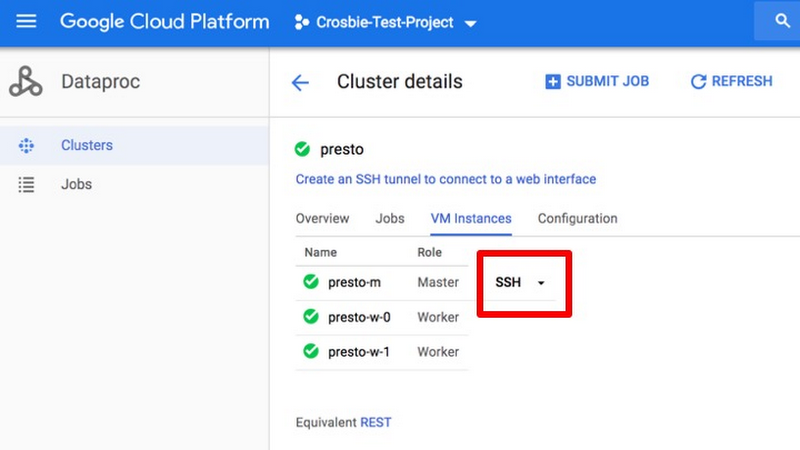
For this example, let’s forgo both the local Presto client on the demo machine and the web UI as shown in the tutorial. Instead, jump onto our Cloud Dataproc cluster’s master instance over SSH, shown here:
Once you’ve kicked off Cloud Shell in the browser, start the Presto client simply by typing “presto.”
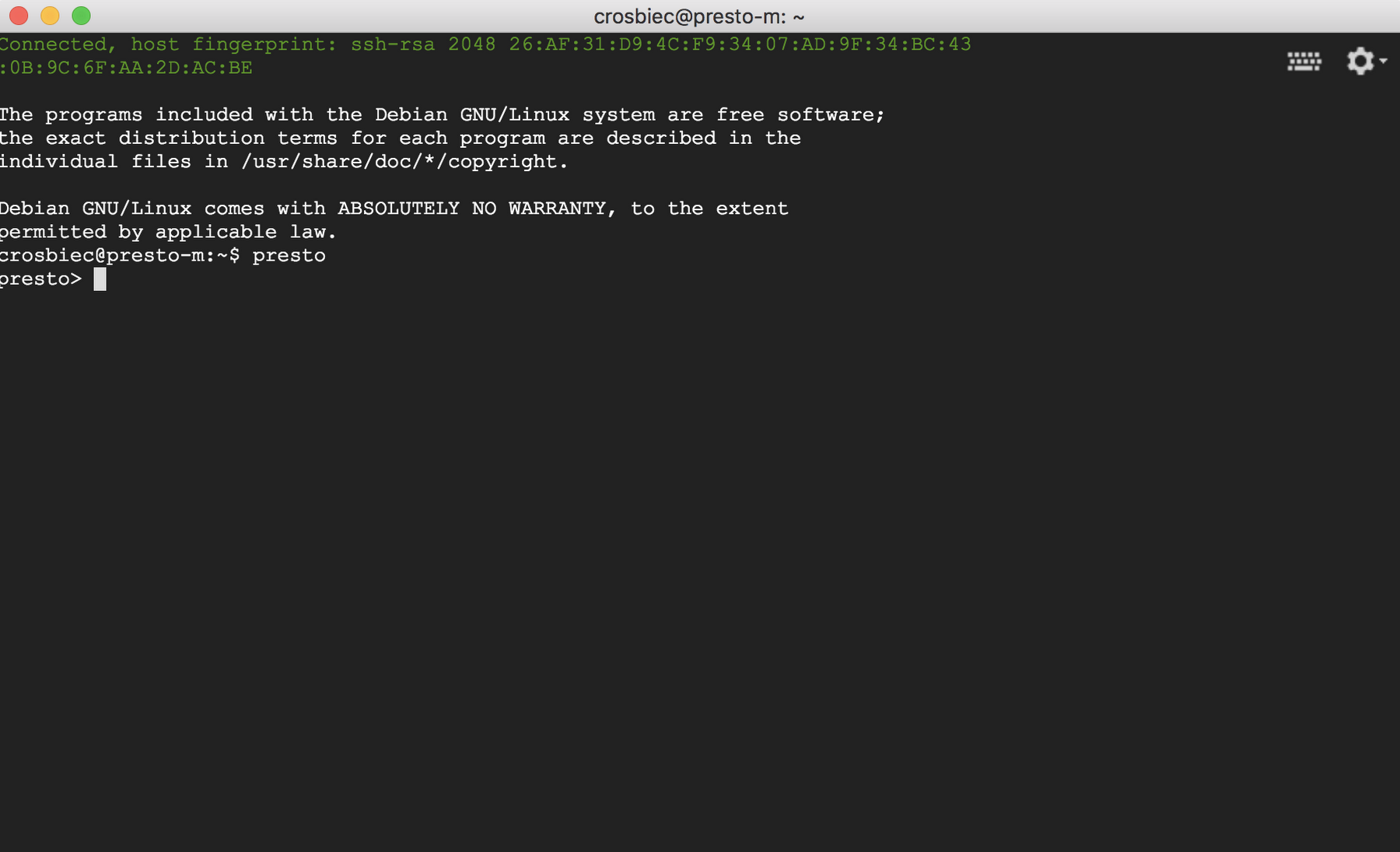
Note: The first time you start the Presto shell, you may see the following warning message: “History file is not readable/writeable.” If you would like to maintain your Presto query history between Cloud Shell sessions, just add a file to the current user’s home directory. The command below should do the trick:
When you’re in Cloud Shell, you can explore your Presto setup.
First, run `SHOW catalogs` to see what data sources the Presto shell can see. For the architecture described above, the Presto command shell returns the following:Querying transactional (or big) data
Now that you’ve verified the Presto shell can query the necessary data sources, you can learn more about the life of a Chicago taxi cab driver. One of the first things to ask is “What neighborhood should I pick people up in to earn the highest fares?”
To answer this question, run the below Presto query below:
The following result returns in a few seconds:
For pickups, community area 76 has the highest average fare, though his information isn’t particularly helpful to a taxi driver who doesn’t know how to map the lookup numbers to specific neighborhoods. This is a common challenge in using big data. You may have large, transactional sources of data sitting in Cloud Storage, but to make sense of that data you need the smaller data it references in various other sources. This is where Presto comes to the rescue.
Adding reference data
With Presto, you can quickly restore reference information from sources outside the Hive metastore, or even from outside GCP, while keeping all the data in its place. You can run queries without first performing a data movement or ETL step just to answer a simple question.
In this example, you have a MySQL database that contains the 117 Chicago neighborhoods mapped to community areas. A quick `describe` from Presto on that table offers a little more information.
This RDBMS data looks promising. It has the previous community number associated back to the community area name and neighborhood. Let’s join it back into the big data query.
In just over a minute, with a single query, you’ve joined more than 112 million records of transactional data back to their lookup values in a completely separate database, and aggregated the necessary information, shown here:
It’s clear that Chicago’s O’Hare International Airport is by far the best place to pick up passengers for the highest fares. Perhaps more importantly, you may also find this information intuitive enough that an ETL process and data warehousing table to consolidate this is unnecessary.
Using Presto views to explore further
This is a simple example, but there is much more to explore in the various analysis tools that communicate with Presto. With Presto Views, you can encapsulate our query logic and then let other tools do more complex analysis, such as time-series analysis on taxi starts and stops, like this:
In this statement, since it’s using the `hive.default` catalog and schema that is stored off-cluster, this query logic will be saved even if you shut down the Cloud Dataproc cluster. When you’re ready to pick up where you left off, you can have another Cloud Dataproc cluster ready in around 90 seconds with the queries and tables right where you left them.
Getting started with Presto on Cloud Dataproc
To get started with Presto on Cloud Dataproc, check out the code lab written by Dagang Wei, Software Engineer, Cloud Dataproc on Using Presto with Cloud Dataproc and use the optional components to create your first Presto on Cloud Dataproc cluster.

