Vertex AI の AutoML とパイプラインによる MLOps システム
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習プロダクトを構築する場合、少なくとも 2 つの MLOps シナリオを検討する必要があります。まず、画期的なアルゴリズムが学界や産業界に導入された際に、後でモデルを置き換える可能性があります。次に、変化を続ける環境のデータに合わせて、モデル自体を進化させる必要があります
Vertex AI が提供するサービスを利用すれば、この 2 つのシナリオに対処できます。次に例を示します。
AutoML 機能は、予算、データ、設定に基づいて最適なモデルを自動的に判断します。
Vertex マネージド データセットを使用すると、新規のデータセットを作成するか既存のデータセットにデータを追加して、データセットを簡単に管理できます。
また、機械学習パイプラインを構築して、データセットのインポートから Vertex Pipelines によるモデルのデプロイまでの一連のステップを自動化できます。
このブログ投稿では、このようなシステムの構築方法について説明します。再現用の完全なノートブックについては、こちらをご覧ください。MLOps に関しては、多くのユーザーが機械学習パイプラインに焦点を当てていますが、MLOps を「システム」として構築する要素は他にもあります。この投稿では、Google Cloud Storage(GCS)と Google Cloud Functions が MLOps システムでデータ管理とイベント処理にどのように役立つかを見てみましょう。
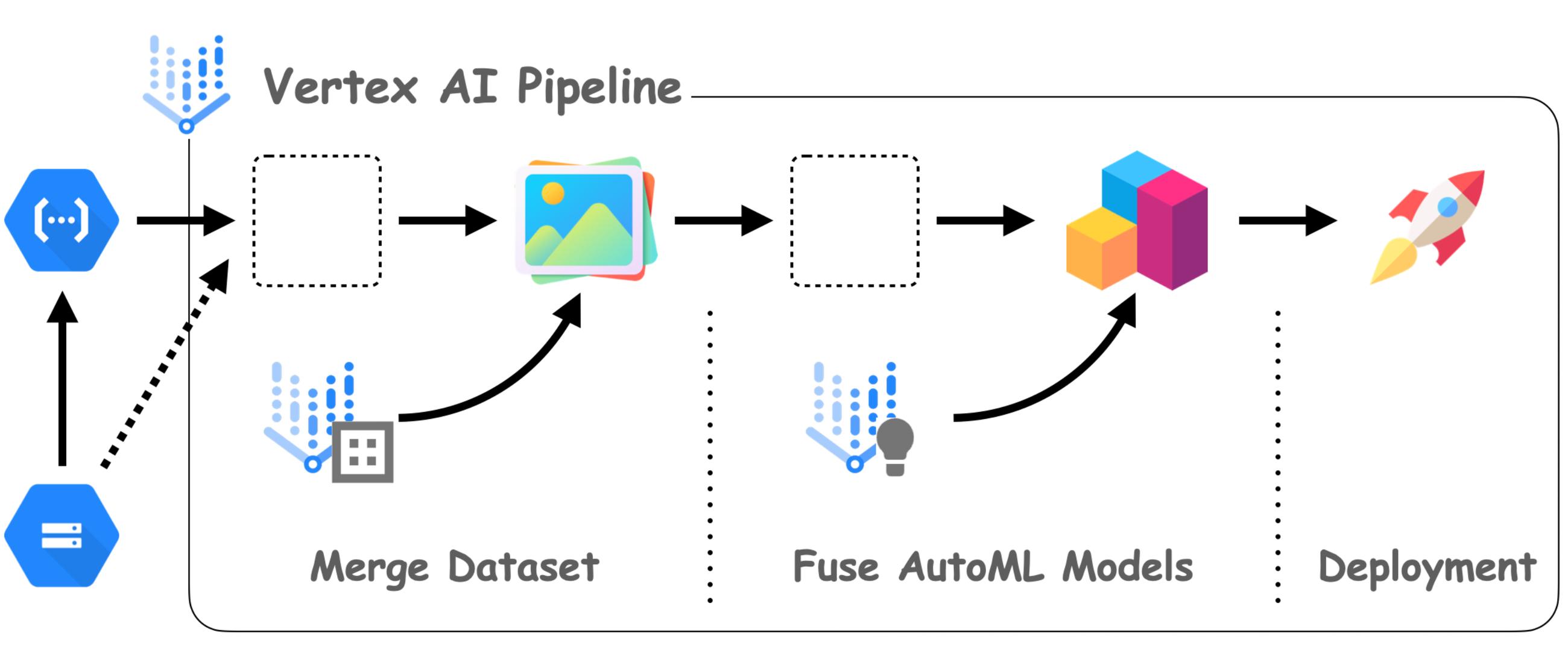
アーキテクチャ
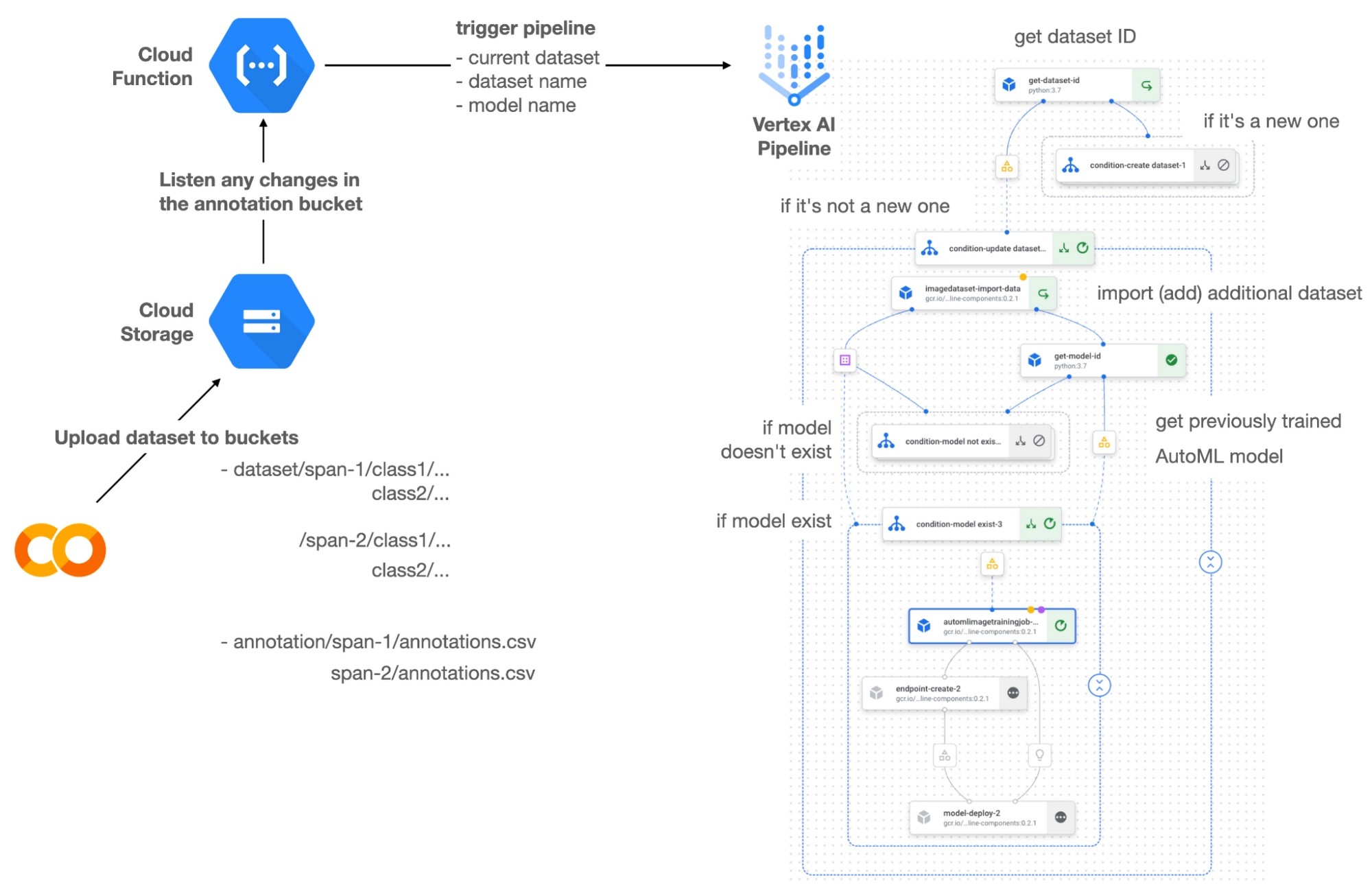
図 1 MLOps アーキテクチャの全体図(オリジナル)
図 1 は、このブログの全体的なアーキテクチャを示しています。まず、関連するコンポーネントを確認します。次に、それらのコンポーネントがどのように連係しているかを把握して、MLOps システムの上記 2 つの一般的なワークフローを理解しましょう。
コンポーネント
Vertex AI は MLOps システムの中心にあり、Vertex マネージド データセット、AutoML、Prediction、Pipelines を活用しています。Vertex マネージド データセットを使用すると、データセットの作成だけでなく、データの増加に応じてデータセットを管理することもできます。Vertex AutoML では、モデリングについてあまり知らなくても、可能な限り最適なモデルを生成できます。Vertex Prediction は、クライアントが通信するエンドポイント(RestAPI)を作成します。
これはフルマネージドでシンプルながら、ある意味完全なエンドツーエンドの MLOps ワークフローであり、データセットからデプロイ可能なモデルのトレーニングまでを扱います。このワークフローは、Vertex Pipelines でプログラムで記述できます。Vertex Pipelines は機械学習パイプラインの仕様を出力するため、いつでもどこでも同じパイプラインを実行できます。ユーザーはパイプラインをトリガーするタイミングと方法を知るだけでよく、そこで登場するのが、Cloud Functions と Cloud Storage の 2 つのコンポーネントです。
Cloud Functions は、サーバーレスでコードを GCP にデプロイする方法です。この特定のプロジェクトでは、指定した Cloud Storage のロケーションに関する変更をリッスンしてパイプラインをトリガーするために使用されます。具体的には、新しいスパン番号などの新しいデータセットを追加すると、パイプラインがトリガーされてデータセット全体がトレーニングされ、新しいモデルがデプロイされます。
ワークフロー
この MLOps システムは、次のように動作します。まず、Vertex データセットの組み込みユーザー インターフェースまたはお好みの外部ツールを使用してデータセットを作成します。作成したデータセットは、SPAN-NUMBER という名前の新しいフォルダを使用して指定の GCS バケットにアップロードできます。すると、Cloud Functions は GCS バケットの変更を検出し、Vertex Pipelines をトリガーして、AutoML のトレーニングからエンドポイントのデプロイまでのジョブを実行します。
Vertex Pipelines は、以前に作成された既存のデータセットがあるかどうかを内部でチェックします。データセットが新しい場合、Vertex Pipelines は GCS のロケーションからデータセットをインポートして新しい Vertex データセットを作成し、対応するアーティファクトを出力します。それ以外の場合、追加のデータセットを既存の Vertex データセットに追加し、アーティファクトを出力します。
Vertex Pipelines はデータセットが新しいと判断すると、新しい AutoML モデルをトレーニングし、新しいエンドポイントを作成してデプロイします。データセットが新しくない場合、Vertex Pipelines は Vertex モデルからモデル ID を取得し、新しい AutoML モデルと更新された AutoML モデルのどちらが必要かを判断します。2 つ目のブランチの理由は、AutoML モデルが作成されていない場合に、新しいモデルの作成を確認するためです。また、モデルがトレーニングされると、対応するコンポーネントもアーティファクトを出力します。
さまざまなディストリビューションを反映するディレクトリ構造
このプロジェクトで CIFAR-10 データセットのサブセットを 2 つ作成しました。1 つは SPAN-1 用で、もう 1 つは SPAN-2 用です。このプロジェクトのより一般的なバージョンについては、こちらをご覧ください。トレーニングとバッチ評価のパイプラインを構築し、それらを連携させることで、現在デプロイされているモデルを評価して再トレーニング プロセスをトリガーする方法を示しています。
Kubeflow Pipelines(KFP)で記述した ML パイプライン
パイプラインのオーケストレーションには、Kubeflow Pipelines を使用することにしました。いくつか注目していただきたい点として、まず、KFP で条件ステートメントを使用してブランチを作成する方法を理解しておきます。次に、AutoML API の仕様を確認し、AutoML 機能を十分に活用する必要があります(以前にトレーニングしたモデルに基づくモデルのトレーニングなど)。最後に、Vertex Dataset と Vertex Model のアーティファクトを出力して Vertex AI が認識できるようにする方法を見つける必要があります。1 つずつ見ていきましょう。
ブランチ戦略
このプロジェクトには、2 つのメイン条件があり、2 つ目のメインブランチ内に 2 つのサブブランチがあります。メインブランチは、既存の Vertex データセットがあるかどうかの条件に基づいてパイプラインを分割します。サブブランチは、既存の Vertex データセットがある場合に選択される 2 つ目のメインブランチで適用されます。また、モデルの一覧を検索し、AutoML モデルを最初からトレーニングするか、以前にトレーニングしたモデルに基づいてトレーニングするかの決定を試みます。
KFP で記述する機械学習パイプラインは、kfp.dsl.Condition という特殊構文を使用して条件が指定される可能性があります。たとえば、以下のようにブランチを作成できます。
get_dataset_id と get_model_id はカスタム KFP コンポーネントであり、それぞれ既存の Vertex データセットと Vertex モデルの有無を確認します。見つからなかった場合は「None」を返し、見つかった場合は「None」以外を返します。また、Vertex AI 対応のアーティファクトの出力も行います。これについては、次のセクションで解説します。
Vertex AI 対応のアーティファクトを出力する
アーティファクトは、機械学習パイプラインの各テストのパス全体を追跡しやすくなるだけでなく、パイプライン UI(この場合は Vertex Pipelines UI)にメタデータを表示します。Vertex AI 対応のアーティファクトがパイプラインで出力されると、Vertex Pipelines UI は、Vertex データセットなどの Vertex AI の内部サービスへのリンクを表示します。これにより、ユーザーはリンクをクリックしてウェブページにアクセスし、アーティファクトの詳細を確認できます。
では、Vertex AI 対応のアーティファクトを生成するカスタム コンポーネントを記述するにはどうすればよいでしょうか。その場合、まずカスタム コンポーネントのパラメータに Output[Artifact] を指定する必要があります。次に、メタデータ属性の resourceName を特別な文字列形式で入力する必要があります。
上記のサンプルコードは、前のコード スニペットで使用した get_dataset_id コンポーネントを実際に実装したものです。ご覧のように、パラメータで dataset が Output[Artifact] として定義されています。パラメータに表示されていますが、実際には自動的に出力されます。関数の変数と同様に、必要なデータを内部に入力するだけで済みます。
datasets は、aiplotform.ImageDataset.list API を呼び出して、Vertex データセットのリストを取得します。長さがゼロの場合は、単に「None」を返します。それ以外の場合は、Vertex データセットの検出されたリソース名を返し、同時に dataset.metadata['resourceName'] にリソース名を入力します。Vertex AI 対応のリソース名は、「projects/<project-id>/locations/<location>/<vertex-resource-type>/<resource-name>」という特別な文字列形式に従います。
<vertex-resource-type> は、内部の Vertex AI サービスを指すものであれば何でもかまいません。たとえば、アーティファクトが Vertex モデルであることを指定する場合、<vertex-resource-type> を models に置き換える必要があります。<resource-name> はリソースの一意の ID であり、aiplatform API で検出されたリソースの name 属性でアクセスできます。もう 1 つのカスタム コンポーネントである get_model_id も、よく似た方法で記述されています。
以前のモデルに基づいた AutoML
新しいモデルを、以前の最適なモデルに基づいてトレーニングしたい場合があります。それが可能であれば、事前に学習した知識をいくらか活用することになるため、新しいモデルは最初からトレーニングしたモデルよりもはるかに優れたものになる可能性があります。
幸い、Vertex AutoML にはこの機能が付属しています。AutoMLImageTrainingJobRunOp コンポーネントを使用すると、以下のように base_model 引数を入力するだけで実現できます。
新しい AutoML モデルを最初からトレーニングする場合、base_model 引数に None を渡します。これはデフォルト値です。ただし、この引数は VertexModel アーティファクトを使用して設定できるため、上記コンポーネントは他のモデルに基づいた AutoML トレーニング ジョブをトリガーします。
ここで注意すべきは、VertexModel アーティファクトは Python プログラミングの一般的な方法で構築できない点です。つまり、Vertex モデル ダッシュボードにある ID を設定して、VertexModel アーティファクトのインスタンスを作成することはできません。インスタンスを作成できる唯一の方法は、metadata['resourceName'] パラメータを適切に設定することです。同じルールを、VertexDataset などの他の Vertex AI 関連のアーティファクトにも適用する必要があります。VertexDataset アーティファクトを適切に構築し、既存の Vertex データセットを取得して、追加のデータをインポートする方法については、こちらにあるこのプロジェクトの詳細なノートブックでご確認いただけます。
費用
新しい GCP アカウントを作成すると、このプロジェクトの同じ結果を $300 の無料クレジットで再現できます。ただし、ご興味のある方のために、このようなジョブにかかる実際の費用をまとめてみます。
このブログ投稿の時点で、Vertex Pipelines の費用は実行ごとに約 $0.03 であり、各パイプライン コンポーネントの基盤となる VM のタイプは e2-standard-4 で、その費用は約 $0.134/時間です。Vertex AutoML トレーニングの画像分類の費用は約 $3.465/時間です。GCS は実際のデータを保持し、費用は 100 GiB 容量で約 $2.40/月になり、Vertex データセット自体は無料です。
2 つの異なるブランチをシミュレートするために、テスト全体で約 1~2 時間かかりました。すべてを合計すると、このプロジェクトの合計費用は約 $16.59 になります。Vertex AI の料金に関する詳細な情報については、こちらをご覧ください。
まとめ
AutoML の機能を過小評価している方は少なくありませんが、機械学習の基礎知識があまりないアプリ デベロッパーやサービス デベロッパーにとっては最適な選択肢です。Vertex AI は、機械学習ワークフローを自動化する AutoML とパイプライン機能を提供する優れたプラットフォームです。この記事では、データ インジェクションから、以前に獲得した最適なモデルに基づいたモデルのトレーニング、Vertex AI プラットフォームでのモデルのデプロイまで、基本的な MLOps ワークフローを設定して実行する方法をご紹介しました。さらに、機械学習モデルを新しいデータセットの変更に自動的に適応できます。残りの実装作業は、モデル モニタリング システムを統合してデータ / モデルのドリフトを検出することです(一例はこちらをご覧ください)。
- ML Google Developer Expert Chansung Park



{kind=link}