MLOps の利用を開始: ユースケースに適した機能の選択
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
ML システムを構築および運用化する成熟した MLOps 手法の確立に際しては、適切な手法が得られるまで数年の歳月を要する場合もあります。Google ではこのほど、この重要な作業の時間短縮を支援する MLOps フレームワークを公開しました。
MLOps の使用を開始する際に、これらのプロセスと機能を必ずしもすべて実装する必要はありません。ワークロードのタイプおよびそれにより生み出されるビジネス価値や、プロセスもしくは機能の構築または購入にかかるコストとのバランスによって、プロセスや機能の中で優先順位の差が生じます。
フレームワークを実用的手順に変換しようとする ML 担当者を支援するため、このブログ投稿では、お客様をサポートした経験を元に、何から始めるべきかを左右するいくつかの要素についてご説明します。
ユースケースの性質に基づく推奨機能(チェックマークを表示)を次の表に示しています。ただし、ユースケースはそれぞれが独特であり、例外がある可能性があります(機能の定義については、MLOps フレームワークをご覧ください)。
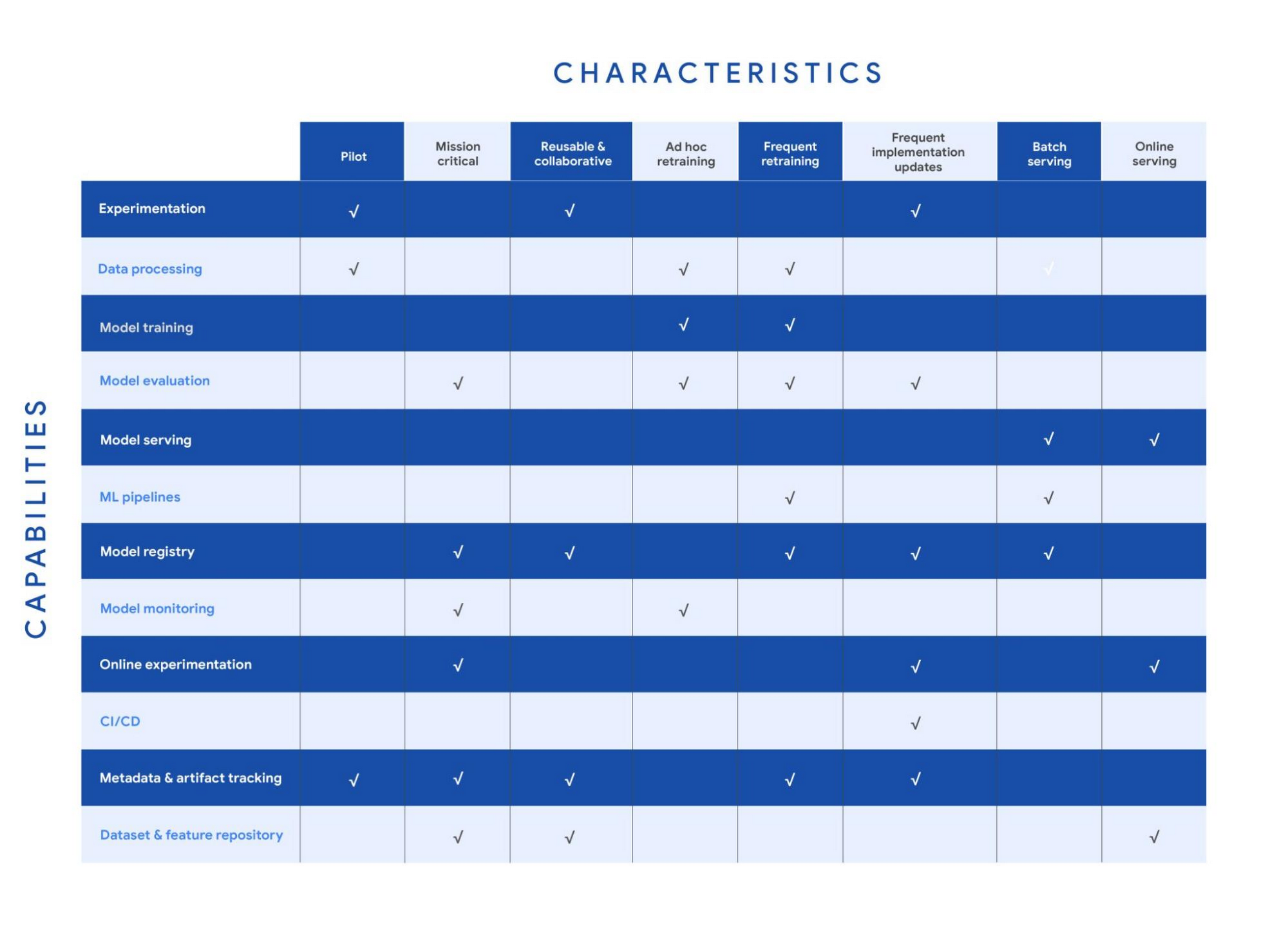
ユースケースが複数の性質を備えている場合もあります。たとえば、頻繁に再トレーニングされバッチ予測を提供するレコメンデーション システムがあるとします。その場合、頻繁な再トレーニングのために、データ処理、モデル トレーニング、モデル評価、ML パイプライン、モデル レジストリ、メタデータおよびアーティファクト トラッキングの各機能が必要です。また、バッチ サービングのためのモデル サービング機能も必要です。
以降のセクションでは、各性質およびそれに対応するおすすめの機能について詳しくご説明します。
試験運用
例: 感情分析のために新しい自然言語モデルを試す研究プロジェクト。
概念実証をテストするためには、一般的に、データ準備、特徴量エンジニアリング、モデル プロトタイピング、検証に重点が置かれます。これらのタスクには実験機能とデータ処理機能を使用します。データ サイエンティストには、複数の実験を迅速かつ簡単にセットアップして追跡および比較したいという希望があります。したがって、デバッグ、トレーサビリティおよびリネージの実現、実験構成の共有と追跡、ML アーティファクトの管理のために、ML メタデータおよびアーティファクト トラッキング機能が必要になります。大規模な試験運用の場合には、専用のモデル トレーニング機能と評価機能が必要になることもあります。
ミッション クリティカル
例: 本番環境でモデル パフォーマンスが低下すると数百万ドルの損失が生じるリスクもあるエクイティ トレーディング モデル。
ミッション クリティカルなユースケースでは、トレーニング プロセスまたは本番環境モデルに不具合があると、ビジネスに大きな悪影響が出ます(法的、倫理的、評判、財政的なリスク)。バイアスと公平さを見極めるとともにモデルの説明可能性を実現するために、モデル評価機能が重要です。加えて、トレーニング中モデルの品質評価と本番環境でのパフォーマンスの評価のために、モニタリングが不可欠です。オンラインでの試験運用によって、デプロイモデルを入れ替える前に、新たにトレーニングしたモデルと本番環境モデルとの比較を制御環境下で行います。そのようなユースケースでは、モデルを保存、評価、チェック、リリース、レポートしてリスクから守る堅固なモデル ガバナンス プロセスも必要です。モデル ガバナンスは、モデル レジストリ機能とメタデータおよびアーティファクト トラッキング機能を使用して実現できます。加えて、データセットおよび機能リポジトリによって、バージョニングされ一貫性のある高品質データアセットが得られます。
再利用可能かつコラボレーション指向
例: 多様な傾向モデリング ユースケースにわたって使用される顧客分析記録(CAR)機能。
再利用可能でコラボレーション指向なアセットでは、AI データ、ソースコード、アーティファクトの共有、検出、再利用が可能です。Feature Store は、ML モデルをトレーニングしてサービングする機能の登録、保存、利用プロセスの標準化に寄与します。キュレートされ保存された機能は、複数のデータ サイエンス チームにより検出および再利用できるようになります。Feature Store があると、既存の機能の再エンジニアリング回避に役立ち、実験時間が節約されます。また、ツールを使ってデータのアノテーションと分類を統合することもできます。最後に、ML メタデータおよびアーティファクト トラッキングを使用することで、ML ワークフローの整合性、テスト性、セキュリティ、反復性の実現に寄与します。
アドホック再トレーニング
例: さまざまな自動車部品を検出するオブジェクト検出モデル。新たな部品の導入時のみ再トレーニングが必要。
アドホック再トレーニングでは、モデルがきわめて静的であり、モデル パフォーマンスが低下したとき以外は再トレーニングを行いません。このようなケースに必要なのは、モデルをトレーニングするためのデータ処理機能、モデル トレーニング機能、モデル評価機能です。加えて、モデルの更新が長期間行われないため、モデル モニタリングが必要です。モデル モニタリングによって、スキーマ異常などのデータスキューや、データおよびコンセプトのドリフトとシフトが検出されます。モニタリングではモデル パフォーマンスの継続評価も実施され、パフォーマンス低下時またはデータ問題検出時にはアラートが発生します。
頻繁な再トレーニング
例: 最新の不正行為パターンをキャプチャするために毎日トレーニングされる不正行為検出モデル。
頻繁な再トレーニングが適用されるのは、モデル パフォーマンスがトレーニング データの変更に依存するようなユースケースです。再トレーニングは、所定の間隔で(毎日または毎週など)行われることが想定されますが、新規トレーニング データが利用可能になった場合などのイベントに基づいてトリガーすることも可能です。このシナリオには、データ抽出、前処理、モデル トレーニングなどの複数の手順をつなぐ ML パイプラインが必要です。また、新しくトレーニングされたモデルの精度がビジネス要件に合致しているか確かめるモデル評価機能も必要です。トレーニング対象モデルの数が増えた場合、トレーニング ジョブとモデル バージョンを追跡するために、モデル レジストリとメタデータおよびアーティファクト トラッキングの両方が役に立ちます。
頻繁な実装更新
例: コンバージョン数を最大化するためにアーキテクチャが頻繁に変更されるプロモーション モデル。
頻繁な実装更新には、トレーニング プロセス自体の変更が伴います。つまり、モデル アーキテクチャの変更(LSTM から Attention など)またはトレーニング パイプラインへのデータ変換ステップの追加など、異なる ML フレームワークへの切り替えを伴う場合があります。ML ワークフローの土台部分にそのような変更を加える場合、新しいコードが機能することおよび新しいモデルが以前のモデルに匹敵する以上のパフォーマンスを発揮することを確認するための制御が必要です。加えて、CI / CD プロセスによって、ML 試験運用から本番環境までの時間が短縮するとともに、人的エラーの可能性が減少します。変更が大きいため、新しいリリースが想定どおりに動作しているか確認するオンライン試験運用が必要です。そのほか、試験運用、モデル評価、モデル レジストリ、メタデータおよびアーティファクト トラッキングなど、実装更新の運用化と追跡を支援する機能も必要です。
バッチ サービング
例: 動画ストリーミング サービスに登録して間もないユーザーに週 1 回のおすすめを提供するモデル。
バッチ予測の場合、リアルタイムでスコアリングする必要はありません。スコアをあらかじめ計算し、後で使えるよう保存しておきます。そうすることで、オンライン サービングの場合よりもレイテンシの心配が少なくなります。ただし、一度に処理するデータ量が大きいため、スループットが重要になります。バッチ サービングは一般的に、データを抽出、前処理、スコアリング、保存する大規模 ETL ワークフロー内の 1 ステップとして使用されます。したがって、データ処理機能とオーケストレーション用の ML パイプラインが必要です。さらに、モデル レジストリによって、スコアリングに使用する最新の検証済みモデルをバッチ サービング プロセスに提供できます。
オンライン サービング
例: モデルを使用して複数言語間のテキスト翻訳を行う RESTful マイクロサービス。
オンライン推論では、レイテンシ要件を満たすためのツールとシステムが必要になります。システムは多くの場合、機能を取得して推論を実行した後に、サービング構成に応じて結果を返す必要があります。機能リポジトリによって、機能をほぼリアルタイムで取得します。また、モデル サービングによって、モデルをエンドポイントとして簡単にデプロイできます。加えて、モデルを本番環境に展開する前に小規模のサービング トラフィック サンプルで新しいモデルをテストするために、オンライン試験運用が役立ちます(たとえば A/B テストの実施)。
Vertex AI を使用して MLOps を開始する
Google はこのほど Vertex AI を発表しました。これは、開発ライフサイクルを通じて ML プロジェクトを効率よく構築して管理するための MLOps 実装を支援する統合機械学習プラットフォームです。利用開始にあたっては次の資料を参考にしてください。
謝辞: Alessio Bagnaresi、Alexander Del Toro、Alexander Shires、Erin Kiernan、Erwin Huizenga、Hamsa Buvaraghan、Jo Maitland、Ivan Nardini、Michael Menzel、Nate Keating、Nathan Faggian、Nitin Aggarwal、Olivia Burgess、Satish Iyer、Tuba Islam、Turan Bulmus など、協力してくれたすべての対象分野のエキスパートに感謝します。特に、この制作を支援してくれたチームメンバー、Donna Schut、Khalid Salama、Lara Suzuki と、継続的にサポートしてくれる Mike Pope に感謝いたします。
-UKI 機械学習プラクティス リード Christos Aniftos



