Getting started with MLOps: Selecting the right capabilities for your use case
Christos Aniftos
ML Practice Lead, UKI
Establishing a mature MLOps practice to build and operationalize ML systems can take years to get right. We recently published our MLOps framework to help organizations come up to speed faster in this important domain.
As you start your MLOps journey, you might not need to implement all of these processes and capabilities. Some will have a higher priority than others, depending on the type of workload and business value that they create for you, balanced against the cost of building or buying processes or capabilities.
To help ML practitioners translate the framework into actionable steps, this blog post highlights some of the factors that influence where to begin, based on our experience in working with customers.
The following table shows the recommended capabilities (indicated by check marks) based on the characteristics of your use case, but remember that each use case is unique and might have exceptions. (For definitions of the capabilities, see the MLOps framework.)
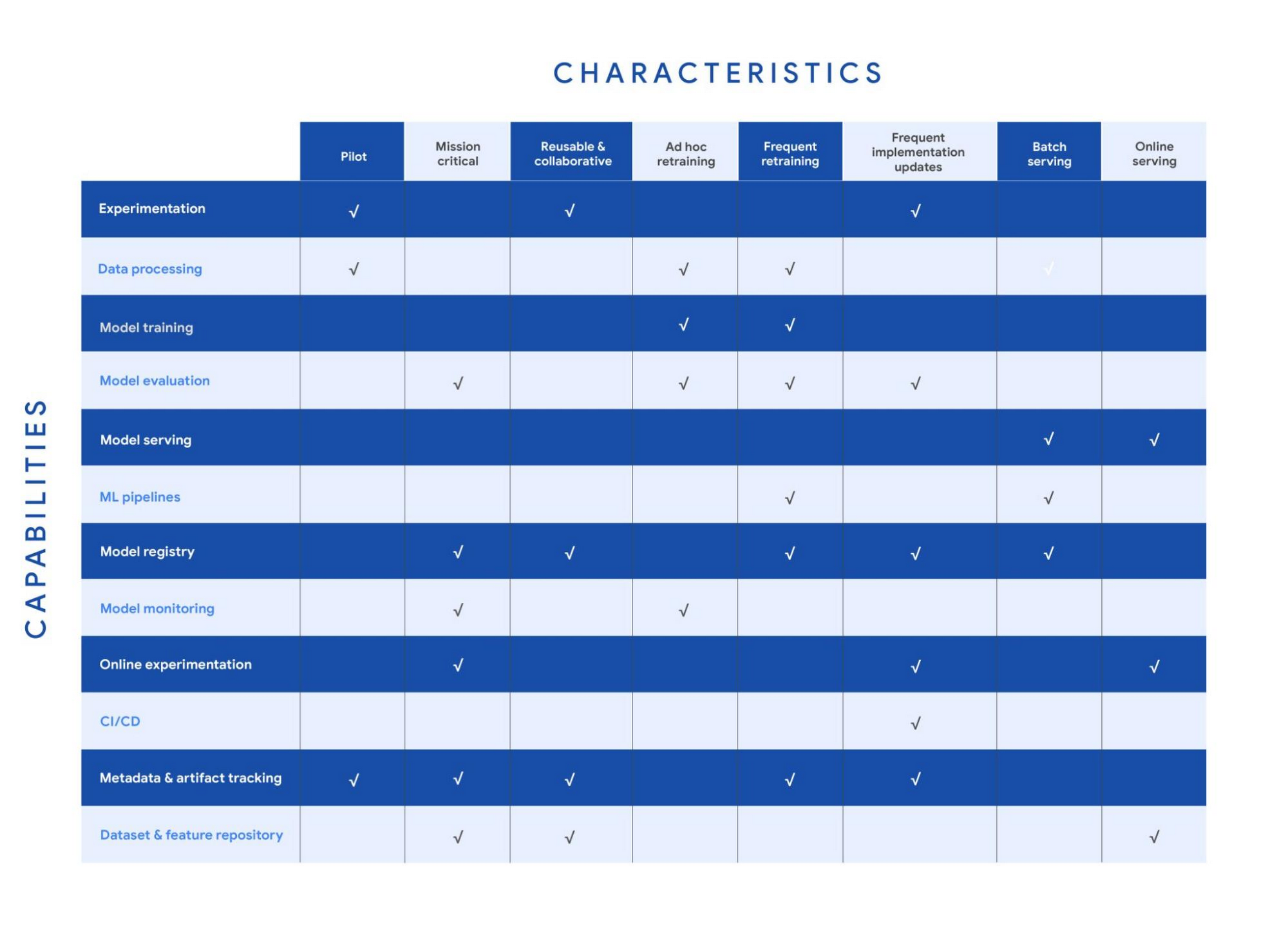
Your use case might have multiple characteristics. For example, consider a recommender system that's retrained frequently and that serves batch predictions. In that case, you need the data processing, model training, model evaluation, ML pipelines, model registry, and metadata and artifact tracking capabilities for frequent retraining. You also need a model serving capability for batch serving.
In the following sections, we provide details about each of the characteristics and the capabilities that we recommend for them.
Pilot
Example: A research project for experimenting with a new natural language model for sentiment analysis.
For testing a proof of concept, your focus is typically on data preparation, feature engineering, model prototyping, and validation. You perform these tasks using the experimentation and data processing capabilities. Data scientists want to set up experiments quickly and easily and track and compare them. Therefore, you need the ML metadata and artifact tracking capability in order to debug, to provide traceability and lineage, to share and track experimentation configurations, and to manage ML artifacts. For large-scale pilots, you might also require dedicated model training and evaluation capabilities.
Mission-critical
Example: An equities trading model where model performance degradation in production can put millions of dollars at stake.
In a mission-critical use case, failure with the training process or production model has a significant negative impact on the business (a legal, ethical, reputational, or financial risk). The model evaluation capability is important to identify bias and fairness, as well as to provide explainability of the model. Additionally, monitoring is essential to assess the quality of the model during training and to assess how it performs in production. Online experimentation lets you test newly trained models against the one in production using a controlled environment before you replace the deployed model. Such use cases also need a robust model governance process to store, evaluate, check, release, and report on models and to protect against risks. You can enable model governance by using the model registry and metadata and artifact tracking capabilities. Additionally, datasets and feature repositories provide you with high-quality data assets that are consistent and versioned.
Reusable and collaborative
Example: Customer Analytic Record (CAR) features that are used across various propensity modeling use cases.
Reusable and collaborative assets allow your organization to share, discover, and reuse AI data, source code, and artifacts. A feature store helps you standardize the processes of registering, storing, and accessing features for training and serving ML models. Once features are curated and stored, they can be discovered and reused by multiple data science teams. Having a feature store helps you avoid reengineering features that already exist, and saves time on experimentation. You can also use tools to unify data annotation and categorization. Finally, by using ML metadata and artifacts tracking, you help provide consistency, testability, security and repeatability of the ML workflows.
Ad hoc retraining
Example: An object detection model to detect various car parts, which needs to be retrained only when new parts are introduced.
In ad hoc retraining, models are fairly static and you do not retrain them except when the model performance degrades. In these cases, you need data processing, model training, and model evaluation capabilities to train the models. Additionally, because your models are not updated for long periods, you need model monitoring. Model monitoring detects data skews, including schema anomalies, as well as data and concept drifts and shifts. Monitoring also lets you continuously evaluate your model performance, and it alerts you when performance decreases or when data issues are detected.
Frequent retraining
Example: A fraud detection model that's trained daily in order to capture recent fraud patterns.
Use cases for frequent retraining are ones where model performance relies on changes in the training data. The retraining might be based on time intervals (for example, daily or weekly), or it could be triggered based on events like when new training data becomes available. For this scenario, you need ML pipelines to connect multiple steps like data extraction, preprocessing, and model training. You also need the model evaluation capability to ensure that the accuracy of the newly trained model meets your business requirements. As the number of models you train grows, both a model registry and metadata and artifact tracking help you keep track of the training jobs and model versions.
Frequent implementation updates
Example: A promotion model with frequent changes to the architecture to maximize conversion rate.
Frequent implementation updates involve changes to the training process itself. That might mean switching to a different ML framework, such as changing the model architecture (for example, LSTM to Attention) or adding a data transformation step in your training pipeline. Such changes in the foundation of your ML workflow require controls to ensure that the new code is functional and that the new model matches or outperforms the previous one. Additionally, the CI/CD process accelerates the time from ML experimentation to production, as well as reducing the possibility for human error. Because the changes are significant, online experimentation is necessary to ensure that the new release is performing as expected. You also need other capabilities such as experimentation, model evaluation, model registry, and metadata and artifact tracking to help you operationalize and track your implementation updates.
Batch serving
Example: A model that serves weekly recommendations to a user who has just signed up for a video-streaming service.
For batch predictions, there is no need to score in real time. You precompute the scores and you store them for later consumption, so latency is less of a concern than in online serving. However, because you process a large amount of data at a time, throughput is important. Often batch serving is a step in a larger ETL workflow that extracts, pre-processes, scores, and stores data. Therefore, you need the data processing capability and ML pipelines for orchestration. In addition, a model registry can provide your batch serving process with the latest validated model to use for scoring.
Online serving
Example: A RESTful microservice that uses a model to translate text between multiple languages.
Online inference requires tooling and systems in order to meet latency requirements. The system often needs to retrieve features, to perform inference, and then to return the results according to your serving configurations. A feature repository lets you retrieve features in near real time, and model serving allows you to easily deploy models as an endpoint. Additionally, online experiments help you test new models with a small sample of the serving traffic before you roll the model out to production (for example, by performing A/B testing).
Get started with MLOps using Vertex AI
We recently announced Vertex AI, our unified machine learning platform that helps you implement MLOps to efficiently build and manage ML projects throughout the development lifecycle. You can get started using the following resources:
MLOps: Continuous delivery and automation pipelines in machine learning
Best practices for implementing machine learning on Google Cloud
Acknowledgements: I’d like to thank all the subject matter experts who contributed, including Alessio Bagnaresi, Alexander Del Toro, Alexander Shires, Erin Kiernan, Erwin Huizenga, Hamsa Buvaraghan, Jo Maitland, Ivan Nardini, Michael Menzel, Nate Keating, Nathan Faggian, Nitin Aggarwal, Olivia Burgess, Satish Iyer, Tuba Islam, and Turan Bulmus. A special thanks to the team that helped create this, Donna Schut, Khalid Salama, and Lara Suzuki, and Mike Pope for his ongoing support.




