ゲスト投稿 : ML API、Cloud Pub/Sub、Cloud Functions でサーバーレス のデジタル アーカイブを構築した Incentro
Google Cloud Japan Team
編集部注 : 今回はデジタル サービス プロバイダーで Google パートナーでもある Incentro の投稿記事をお届けします。同社は先ごろ、デジタル アセット管理ソリューションを Google Cloud Platform(GCP)で構築しました。このシステムでは、デジタル アセットの検索やタグ付けのために Cloud Vision API や Cloud Speech API などの機械学習(ML)サービスを使用するほか、サーバーレス ソリューションを自動化するにあたって Cloud Pub/Sub と Cloud Functions を使っています。本稿ではその実現方法を同社に解説していただきました。
私たち Incentro はメディアと出版業界をメインの顧客基盤としていますが、最近、そうした顧客企業がデジタル アセットの格納や検索で苦労していることを知りました。膨大な数のタグ付けを必要する煩雑な手作業を強いられているというのです。結果として、不適切なタグを付けられた動画は検索できなくなり、再利用できなくなるなどの問題がよく起こっています。
そのような手作業を取り除き、高価なデジタル アセットから多くのビジネス価値を引き出せるようにするべく、私たちは、画像や動画へのタグ付けといった煩雑な作業を自動化するソリューション、Segona Media を構築しました。これを使えば、顧客がデジタル アセットを格納すると、タグとインデックスが自動的に生成されます。
サポート対象のアセット
Segona Media は現在、デジタル アセットとして画像、動画、音声をサポートしています。これらのアセット タイプごとに、アセットからコンテンツを抽出する Google Cloud の専用マネージド API を使用しており、手作業によるタグ付けやテキスト起こしは不要です。
- 画像 : Google Cloud Vision API を使ってラベルやランドマーク、テキスト、属性など必要とされるコンテンツの大半を抽出でき、画像の検索に使用できます。
- 音声 : Google Cloud Speech API により、見事なテキスト起こしが可能です。また、書き起こされたテキストに対して Google Cloud Natural Language API を適用すれば、テキストの感情やカテゴリを認識できます。つまり、音声内のテキストだけでなく、テキストに含まれる感情やカテゴリなども検索できるわけです。
- 動画 : 動画については、通常は音声分析と画像分析を組み合わせて使用します。Google Cloud Video Intelligence API を使ってラベルとタイム フレームを抽出し、明示的なコンテンツを検出したうえで、動画の音声トラックに対しては音声アセットと同じ処理(上記参照)を行います。そのため、動画だけでなく、動画内の音声もコンテンツ検索に使用できます。
Segona Media のアーキテクチャ
従来、この種のソリューションを開発するには、ハードウェアを意識して稼働させ、アプリケーション サーバー、データベース、ストレージ ノードなどを明確に分けてインストールしなければなりませんでした。しかも、ソリューションを開発して本番稼働させた後には、OS の更新やアップグレードを迫られたり、予想外に膨れ上がった本番データに合わせてデータベースをスケーリングしたりといったお馴染みの難問が押し寄せてきます。
私たちはこういったことを避けたいと思い、熟慮を重ねたうえで、サーバーレス アーキテクチャのもとでフルマネージド ソリューションを構築することにしました。その結果、メンテナンスしなければならないサーバーはなくなり、日々進化する Google API をそのまま活用でき、どんなに大きなアーカイブにも対応できるスケーラビリティが得られました。
Segona Media の開発にあたっては、メディアや出版業界で広く使われているツールの併用も意識しました。Adobe の InDesign や Premiere、Photoshop、Digital Asset Management ソリューションなどを用いて Segona Media に簡単にアセットを格納したり、アセットを取り出したりする必要があったのです。そこで、Google Cloud Storage にアセットを格納する既存の GCP API を活用することにしました。アセットの取得には、GCP のマネージド Elasticsearch API を使用しています。
Segona Media が実行する個々のアクションは別々の Google Cloud Functions になっており、これらは通常 Google Cloud Pub/Sub キューによってトリガーされます。Cloud Pub/Sub キューによる Cloud Functions のトリガーは、新しいアクションを簡単かつスケーラブルにパブリッシュできる方法なのです。
Segona Media のアーキテクチャを大まかに示すと次のようになります。
俯瞰的に見たアーキテクチャ
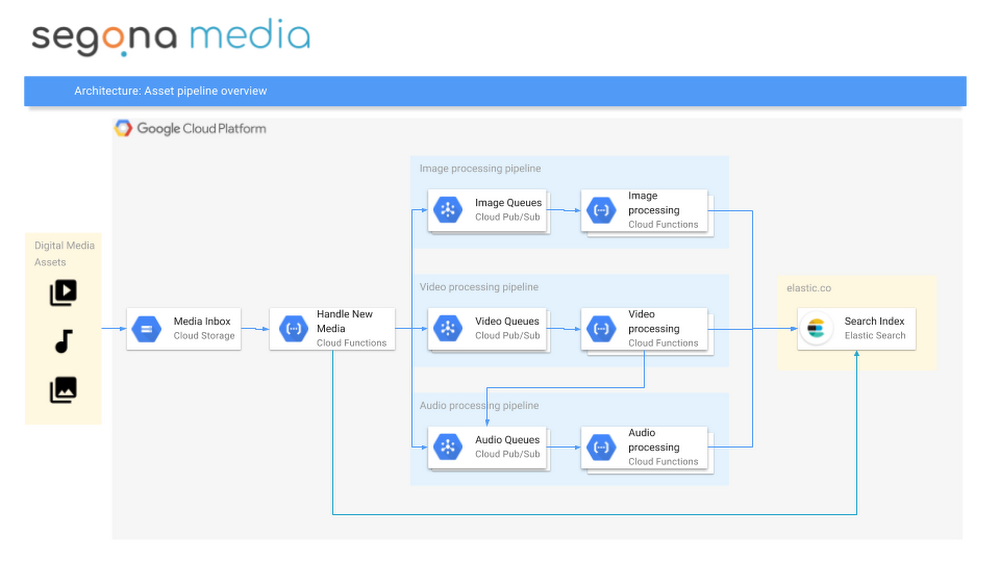
Segona Media の内部では、アセットは次のような流れで処理されます。
- アセットが Cloud Storage バケットにアップロード、格納されます。
- このイベントによって Cloud Functions がトリガーされます。このCloud Functions は一意の ID を生成して、ファイル オブジェクトからメタデータを抽出して適切なバケットに移し(ライフサイクル管理も行います)、Elasticsearch インデックスにアセットを作成します(GCP 上の Elastic Cloud を使います)。
- その過程で、Google API を使ってアセットからコンテンツを抽出するアセット プロセッサを、アセット タイプごとに Cloud Pub/Sub にキューイングします。
アセット タイプごとの処理
最後に、Segona Media がメディア アセットをどのように処理するのかをタイプごとに見ていきましょう。
画像
画像には専用のマイクロサービス プロセッサを介して検索できる特性がたくさんあります。- ファイル自体に埋め込まれたオブジェクトの XMP および EXIF メタデータを ImageMagick で抽出します。この情報はあとで Elasticsearch インデックスに追加され、著作権や解像度などによる画像の検索に利用されます。
- Cloud Vision API を使って画像のラベル、ランドマーク、テキスト、属性を抽出します。これにより、画像内のオブジェクトに基づいた手作業のタグ付けが不要になり、コンテンツに応じて画像を検索できるようになります。
- Segona Media では利用者がカスタム ラベルを作れるようにしています。たとえば、テレビの製造業者であれば画像に含まれる受像機のモデルを知りたいはずです。そのため、カスタム データで訓練した独自の TensorFlow モデルを構築し、カスタム予測を実装しています。訓練や予測は Google Cloud ML Engine で行います。
- すべてのアセットを提供しやすくするため、画像の低解像度サムネイルも作ります。
音声
音声の処理はごく単純です。ファイル内の音声を検索できるようにするため、Cloud Speech API を使って音声ストリームをテキストに変換します。変換後のテキストは Elasticsearch インデックスに追加され、すべての単語が検索対象として使用できるようになります。動画
動画の処理は基本的に画像や音声ファイルで行ったすべての処理を組み合わせたものとなります。ただし、微妙な違いもあるので、どのようなマイクロサービスを使用しているのかを説明しましょう。- まず、動画の低解像度イメージとして、解像度を 50 % にしたサムネイルを作ります。この処理は Cloud Functions で FFmpeg と FFprobe を組み合わせて実現しており、サムネイルは動画アセットともに格納されます。Cloud Functions と FFmpeg を使ったサムネイルの作成は簡単です。こちらのコードを参照してください。
- 同じ FFmpeg アーキテクチャを使用して動画から音声ストリームを抽出します。抽出した音声ストリームは他の音声ファイルと同様に処理します。つまり、音声ストリームをテキストに変換し、それを Elasticsearch インデックスに追加して、音声内のすべての単語から動画自体を検索できるようにしています。動画から抽出した音声ストリームは、最高の結果が得られるシングル チャネルの FLAC 形式に変換されます。
- Cloud Video Intelligence API を使用して動画コンテンツ自体からも関連情報を抽出しています。動画に含まれるラベルとともに、ラベルの作成日時も抽出します。これにより、どのオブジェクトが動画のどこに位置しているかがわかります。探しているオブジェクトを含む動画だけでなく、動画の中の時間も示せるという点で、ラベルの作成日時を抽出することには大きな意味があります。
以上が、完全にサーバーレスな形でメディアのタグ付けを行う方法の概要です。サーバーレスであれば、スケールアップやスケールアウト時の OS のアップデート、インフラストラクチャのメンテナンス、サポートなどは一切不要です。おかげで私たちは、革新的でスケーラブルなソリューションをエンドユーザーに提供するという本来の仕事に専念できます。
ぜひ質問をお寄せください。下記のコメント欄をご利用いただくか、こちらにメールしていただくか、Twitter の @incentro_ にご連絡いただければ幸いです。
* この投稿は米国時間 1 月 23 日、Incentro の Managing Director である Kees van Bemmel 氏によって投稿されたもの(投稿はこちら)の抄訳です。
- By Kees van Bemmel, Managing Director, Incentro



