Google Cloud データベースの最新情報: より統合され、オープンでインテリジェントに
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
現在はどのような組織でもなんらかの形でデジタル トランスフォーメーションを進めており、新しい方法で顧客にサービスを提供しています。現代のサービスの利便性に慣れた消費者は、会社の規模や問題の複雑さに関係なく、消費者中心のサービスが提供されることを期待しています。このようなデジタル エクスペリエンスを支えているのがオペレーショナル データベースであり、ほとんどのアプリケーションのバックボーンとなっています。つまりカスタマー エクスペリエンスの質は、このオペレーショナル データベースの信頼性、スケーラビリティ、パフォーマンス、安全性に大きく依存することになります。
Google Cloud のミッションは、あらゆる組織のデジタル トランスフォーメーションを促進することです。そのためには、統合されたオープンでインテリジェントなデータクラウド プラットフォームによって、顧客やパートナーのイノベーションを加速させることが重要です。Google Cloud Next では、お客様の組織における成長とイノベーションの機会を拡大する Google Cloud データベースの新機能を発表しました。
注目したのは、次の 4 つの分野です。
トランザクション データと分析データに対応する統一および統合されたデータクラウドを構築する
従来のデータベースから脱却し、オープンなエコシステムおよび標準に取り組む
データドリブンなワークフローに AI と機械学習を導入する
ビルダーの生産性と効果を強化する
トランザクション データと分析データの統合
これまで、トランザクションのワークロードと分析のワークロードは、その基盤となるデータベースも含め、データ アーキテクチャによって分離されていましたが、それにはもっともな理由がありました。トランザクション データベースは高速な読み書きを実現するために最適化されているのに対し、分析データベースは大規模なデータセットを集約するために最適化されているからです。それぞれのシステムが大きく切り離されているために、さまざまな面で非効率性が生み出されています。これにより企業は、異なる種類のデータ ソリューションをつなぎ合わせる作業に苦心し、複雑なデータ パイプラインの管理に貴重な時間を費やし、データベース間でデータを複製する作業に多くの労力を費やすことになります。そして最終的には、インテリジェントでデータドリブンなアプリケーションを構築することが難しくなります。
Google は Google Cloud を提供しており、データ プラットフォームの設計方法によって、この問題を解決できる独自の立ち位置を確立しています。Google のトランザクション データベースと分析データベースは、スケーラビリティに優れた分散ストレージ システム上に構築されており、分散されたコンピューティングとストレージ、さらには自社所有の高性能なグローバル ネットワークが用意されています。この組み合わせにより、Cloud Spanner、Cloud Bigtable、PostgreSQL 向け AlloyDB、BigQuery の各プロダクトに対して緊密に統合されたデータクラウド サービスを提供できます。
このたび Google は、データ レプリケーションを容易に行える Bigtable 変更ストリームのプレビュー版を発表いたします。Bigtable は高パフォーマンスのフルマネージド NoSQL データベース サービスであり、ピーク時には毎秒 50 億以上のリクエストを処理し、10 エクサバイト以上のデータを管理します。変更ストリームを使用すると、Bigtable データベースに対する書き込み、更新、削除を追跡し、BigQuery などのダウンストリーム システムにレプリケートできます。変更ストリームは、リアルタイム分析、イベントベースのアーキテクチャ、マルチクラウドの運用データベースのデプロイを支援してくれる機能です。この機能は、最近発表された Spanner 変更ストリームと結合します。
また、Datastream for BigQuery のプレビュー版も先日発表いたしましたが、これを使用すれば、AlloyDB、PostgreSQL、MySQL、Oracle などの運用データベースから、数クリックで簡単にデータを BigQuery に直接レプリケートできます。Datastream はサーバーレスの自動スケーリング アーキテクチャを採用しているため、簡単に ELT(抽出、読み込み、変換)パイプラインを設定し、低レイテンシのデータ レプリケーションによって、BigQuery でリアルタイムの分析情報を取得できます。
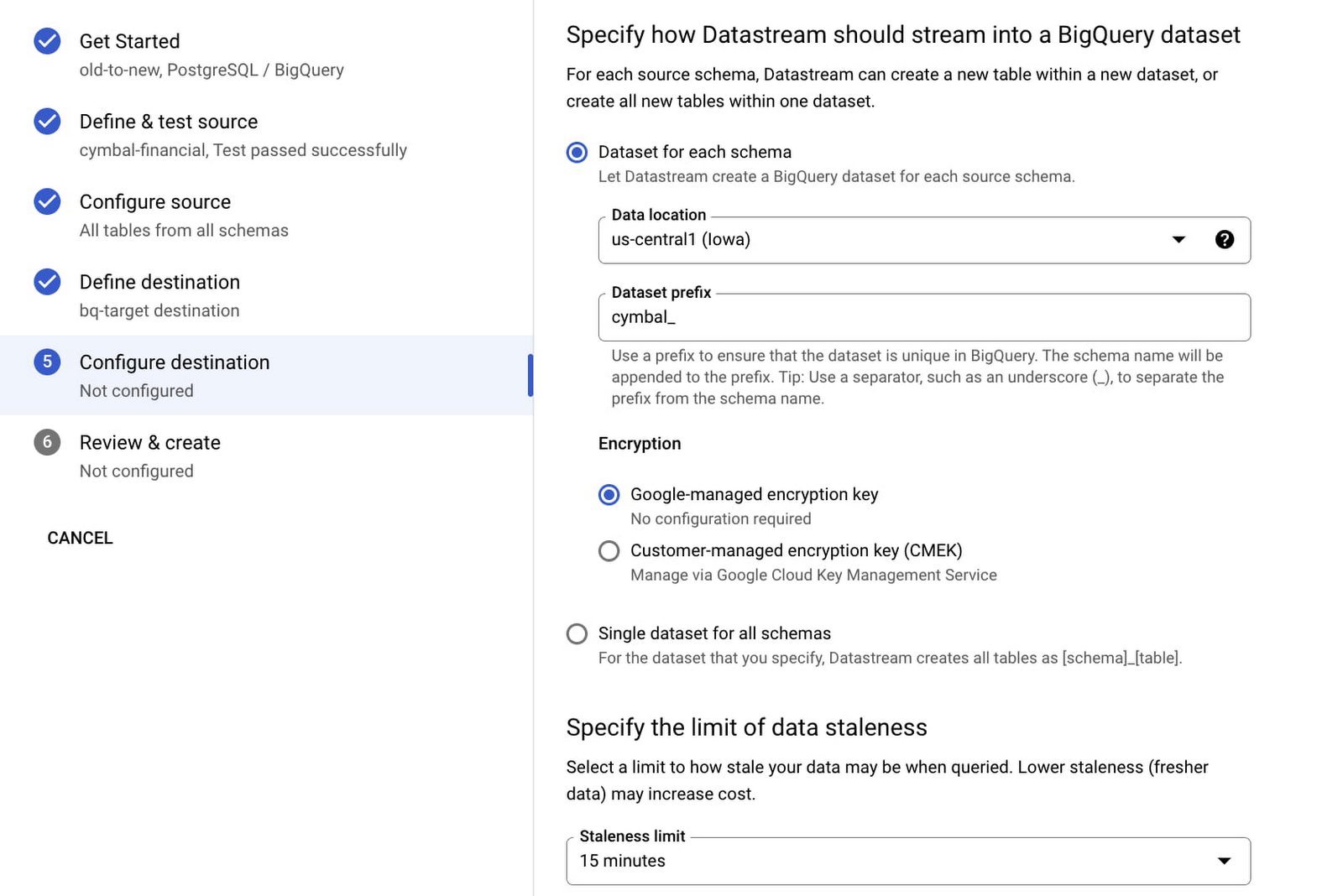
オープンソースとオープン標準による自由度と柔軟性の向上
近年、組織では不透明なコストや制限の多いライセンス、ベンダー ロックインに対する許容度が低下していることから、オープンソースのデータベースとオープン標準の採用が進んでいます。特に PostgreSQL は、その豊富な機能、エコシステムの拡張機能、エンタープライズ向け機能から、従来の独自データベースに代わる主要な選択肢として台頭してきました。
Google では、お客様のワークロードを確実にサポートできるように、3 種類の PostgreSQL オプションを提供しています。1 つ目は PostgreSQL 向け AlloyDB です。これは、PostgreSQL 互換のデータベースであり、現在はプレビュー版ですが、商用グレードのワークロードをサポートするために必要な性能、可用性、スケーリング、機能を提供します。Google のパフォーマンス テストでは、AlloyDB はトランザクション ワークロードにおいて標準の PostgreSQL よりも 4 倍以上高速でした。AlloyDB のパートナー エコシステムは大幅に拡大しており、ビジネス インテリジェンス、分析、データ ガバナンス、オブザーバビリティ、システム インテグレーションをサポートする 30 以上のパートナー ソリューションが揃っています。
また先日は、Database Migration Service によって PostgreSQL データベースを AlloyDB に移行するサポートをプレビュー版として発表いたしました。このサービスを使用することで、オンプレミス データベースや Google Cloud をはじめとするクラウド上のセルフマネージド データベースなど、あらゆる PostgreSQL データベースから AlloyDB への移行を使いやすく、安全で、またサーバーレスな方法で行い、ダウンタイムを最小限に抑えることができます。
2 つ目の PostgreSQL オプションは Cloud SQL for PostgreSQL です。フルマネージドの最新版 PostgreSQL であり、容易なリフト&シフト移行や新しいアプリケーションの開発を実現します。よく使われる PostgreSQL の拡張機能と 100 以上のデータベース フラグをサポートしており、Cloud SQL が持つ優れた管理機能や可用性、セキュリティによって、オープンソースの PostgreSQL と同様のエクスペリエンスを得ることができます。Google Cloud を利用する上位 100 社のお客様のうち、90% 以上が Cloud SQL を使用しているのは当然のことといえるでしょう。新規のお客様は、Cloud SQL 無料トライアルから始めることができます。
そして 3 つ目が Spanner です。強い外部整合性と最大 99.999% の可用性を持つ Google のグローバル分散リレーショナル データベースであり、PostgreSQL エコシステムの使い慣れたツールとスキルを活用できる PostgreSQL Interface を提供します。Google では、引き続き Spanner の PostgreSQL 互換性を優先しています。今回発表する Spanner PostgreSQL Interface は、その重要なマイルストーンであり、Java(JDBC)や Go(pgx)をはじめとする PostgreSQL エコシステムの最初のグループのドライバをサポートしています。このサポートにより、開発者がすでに使用している既製の PostgreSQL ドライバを使用できるため、アプリを Spanner に移行するコストを削減できます。また、Spanner を誰もが手に取りやすいものにするため、無料トライアル インスタンスの提供を発表いたしました。
データドリブンなワークフローに AI と機械学習を導入する
AI と機械学習(ML)はデータドリブンな変革を進めるうえで不可欠であり、データからさらなる価値を引き出してくれます。AI ツールと ML ツールには多くの利点がありますが、特に大きな利点は、パターンの認識、新しい分析情報による運用能力の強化と改善、魅力的なカスタマー エクスペリエンスの創造を支援してくれることです。ただし、ほとんどの企業にとって、ML モデルは構築することだけでなく、大規模なコーディングや AI / ML に特化したスキルなしでアプリケーションに統合することも大きな課題となっています。ワークフローの種類を問わず、AI と ML の活用は、特にデータ プラットフォーム内では容易でなければなりません。
Google Cloud では、サービスをよりインテリジェントにするためのデータベース システムの最適化と、AI および ML サービスの統合の両方を目的として、AI テクノロジーと ML テクノロジーに投資してきました。データベース システムの最適化については、Cloud SQL Cost Recommender や AlloyDB Autopilot などの機能により、データベース管理者や DevOps チームが大規模なデータベース フリートのパフォーマンスと容量を容易に管理できるようにします。
Google では、AI や ML をデータベースに取り入れることに加え、Google Cloud の機械学習プラットフォームである Vertex AI との統合を提供し、データベース トランザクション内でモデルの推論を直接行えるようにすることに注力してきました。そしてこのたびプレビュー版として、Vertex AI と Spanner の統合を発表いたします。これにより、Spanner のシンプルな SQL ステートメントを使って、Vertex AI の機械学習モデルを呼び出すことができるようになります。
今回の統合により、AlloyDB と Spanner のどちらを使用していても、データ サイエンティストは Vertex AI で簡単にモデルを構築できるようになり、開発者は SQL クエリ言語を使用して、そのモデルにアクセスできるようになります。たとえば、小売業者が購入手続きのプロセス中に不正なトランザクションを検知し、適切な措置を講じる必要があるとします。このような場合、Vertex AI が統合されているため、ML_PREDICT などの関数を使用して、Spanner クエリで不正検出の ML モデルを呼び出すことができます。
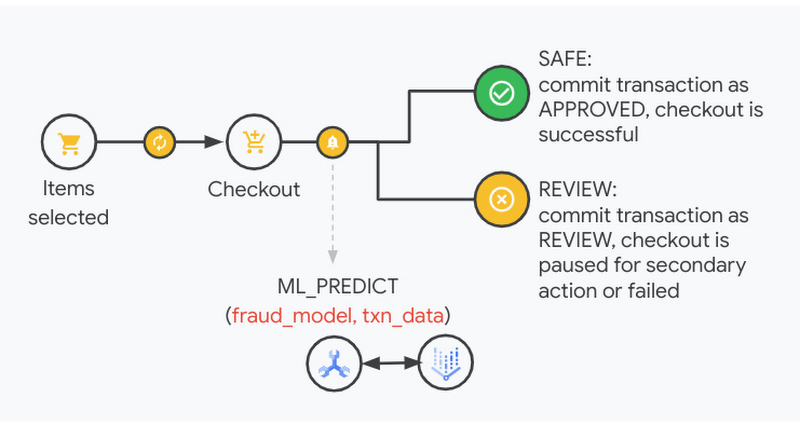
ビルダーの生産性を強化する
アプリの構築、テスト、デプロイは手間のかかる作業です。さらに、アプリを構築した後も、定期的なモニタリング、パフォーマンスの調整、スケーリング、セキュリティ パッチの適用などのメンテナンスが必要であり、そのすべてが開発者が戦略的イニシアチブに注力できない要因となります。その結果、イノベーションに時間がかかり、競合他社に遅れをとる可能性があります。Google が開発者のエクスペリエンスを重視するのはこのような理由からであり、以下で Firestore、Cloud SQL、Spanner の最新の情報についてお知らせいたします。
開発者が Firestore を好む理由は、アプリをエンドツーエンドで構築できる速さにあります。Firestore では 400 万以上のデータベースが作成され、Firestore アプリケーションは Firebase Auth を使用する月間 10 億人以上のアクティブ エンドユーザーに利用されています。では、アプリケーションが成長した場合はどうでしょうか。Google は、アプリが急成長しているときでも、開発者が生産性を重視できるようにしたいと考えています。そのため、Firestore に対して 3 つのアップデートを実施しましたが、いずれも成長のサポートとコストの削減を目的としたものです。
Firestore を Backend-as-a-Service として使用するアプリケーションについては、書き込みスループットと同時アクティブ接続数の制限を撤廃しました。これにより、一夜にして大成功を収めたアプリでも、Firestore のスムーズなスケーリングが保証されます。さらに、来週には COUNT() 関数をプレビュー版として展開する予定です。この関数により、コスト効率に優れ、スケーラブルなカウント集計を行えます。この機能は、ユーザーの友人の数を数えたり、コレクション内のドキュメント数を特定したりするようなユースケースをサポートします。最後に、ストレージのコストを効率的に管理するために、有効期間(TTL)を導入しました。これにより、ドキュメントの有効期限を事前に指定し、期限切れのドキュメントを Firestore によって自動的に削除できます。
また、Cloud SQL と Spanner のセキュリティとパフォーマンスも進化しています。Cloud SQL Query Insights for MySQL(Cloud SQL Insights for PostgreSQL も提供されています)を使用することで、データベース パフォーマンスの問題を簡単に検出、診断、防止できます。先日、PostgreSQL System Insights のプレビュー版を発表いたしましたが、今回さらに 2 種類の Cloud SQL Recommender を発表いたします。セキュリティ Recommender はセキュリティの脆弱性を継続的に検出し、広範にアクセスを提供しているパブリック IP アドレスや暗号化されていない接続など、リスクの高いセキュリティ構成をチェックします。一方、パフォーマンス Recommender は、パフォーマンスの低下やダウンタイムのリスクを増大させる一般的な構成ミスを特定し、解決するのを支援します。
最近、Spanner 向け Query Insights をリリースいたしましたが、これによりクエリのパフォーマンスに関する問題を迅速に診断できる事前構築済みダッシュボードが提供されます。さらに、Spanner 向けのロックとトランザクションの分析情報(2022 年第 4 四半期に提供予定)は、アプリケーションの速度を低下させる Spanner 上のロック競合の問題に対するトラブルシューティングを支援します。行範囲や列のほか、ロックが競合するサンプルのトランザクションを簡単に関連付けることが可能で、きめ細かい指標を使用して高レイテンシのトランザクションをデバッグできます。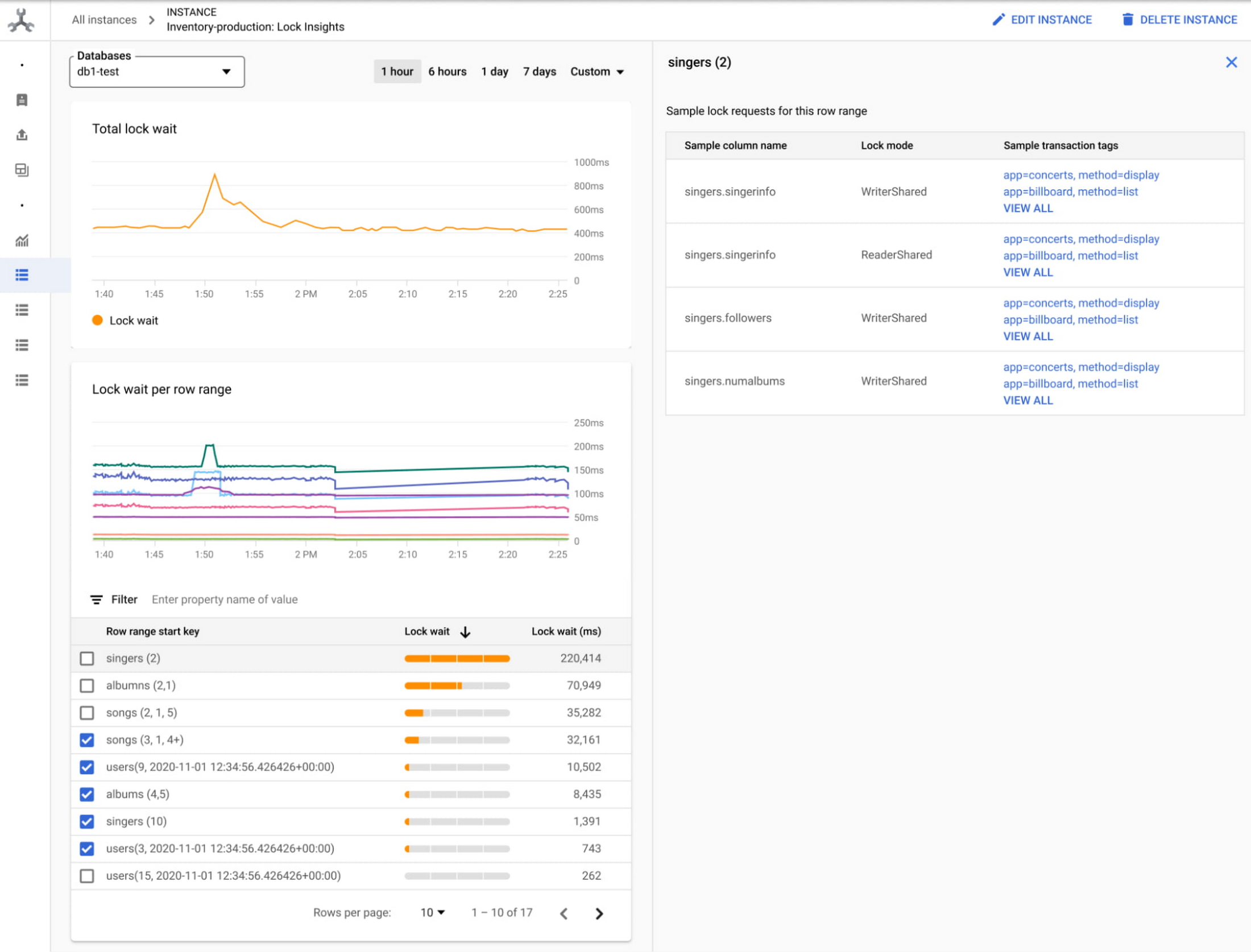
新たな可能性を切り拓く
データの未来には無限の可能性があります。Google はお客様のパートナーとして、データドリブンなビジネスの変革を促進できるようお手伝いいたします。
Next ‘22 では、発表内容の詳細をご覧いただけます。また、MLB、PLAID、Forbes、DaVita、Credit Karma、Box などの企業が Google Cloud データベースで、どのようにイノベーションを実現しているかをご紹介します。
- Google Cloud データベース エンジニアリング担当ゼネラル マネージャー兼バイス プレジデントAndi Gutmans

