オープンな分析レイクハウスでデータアセットを統合する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
テクノロジー業界では 10 年以上にわたって組織のボリューム、レイテンシ、復元性、そして多様なデータアクセスの要件に対応しつつ、膨大なデータを保存、分析するための方法を模索してきました。多くの企業が既存の技術スタックを最大限活用してこうした課題に取り組み、大量の半構造化データの処理、保存を行っています。広く見られた対策として、データレイクをインタラクティブなデータ ウェアハウスとして機能させる方法と、データ ウェアハウスをデータレイクとして機能させる方法が挙げられます。どちらの方法でも、ユーザーには不満がつのり、コストはかさみ、企業全体でデータが重複してしまうという結果になりました。
あらゆるユーザー(データ アナリスト、データ エンジニア、データ サイエンティストなど)の複雑なデータニーズに応えられるアーキテクチャが必要です。
分析においては、組織はこれまでデータのユースケースに応じて異なるソリューションを実装してきました。主にビジネス インテリジェンス(BI)やレポートに使用される構造化された集計データの保存、分析にはデータ ウェアハウスが、データ探索や機械学習(ML)ワークロードを主な用途とする大量の非構造化データおよび半構造化データにはデータレイクが使用されていました。この方法ではデータの移動、処理、重複が多くなってしまい、複雑な ETL(抽出、変換、読み込み)パイプラインが必要になります。このアーキテクチャの運用と管理は時間と労力を要することで、アジリティを低下させていました。組織がクラウドに移行するにあたって、こうしたサイロの解消は目標の一つとなります。
クラウドへ移行することで別々のデータソースをまとめることができ、誰もがデータと AI のエコシステムを利用できるようになります。組織がデータ サイエンスの機能を大々的に活用したいと考えていることに疑いはありませんが、多くの組織はまだ ROI 実現の途上にあるといえます。最新の調査では、91% の組織がデータと AI への投資を増やしていることがわかっています。対して、本番環境へモデルをデプロイできている組織はわずか 20% にすぎません。ビジネス ユーザー、データ アナリスト、データ エンジニア、データ サイエンティストはデータと AI のエコシステムの一員になりたいと考えています。
分析レイクハウスの台頭
Google Cloud の分析レイクハウスはデータレイクとデータ ウェアハウスの主な利点を組み合わせたもので、オーバーヘッドを生じさせることもありません。このアーキテクチャについては、テクニカル ホワイトペーパー「Google Cloud で分析レイクハウスを構築する」で詳しく説明しています。簡単に言えば、組織はこのエンドツーエンドのアーキテクチャを使用することで、データがどのクラウドやデータストアにあったとしてもリアルタイムに抽出でき、そのデータを集約して優れた分析情報を得たり、人工知能(AI)に活用したりできます。そしてガバナンスやチーム全体の統合アクセスも備えています。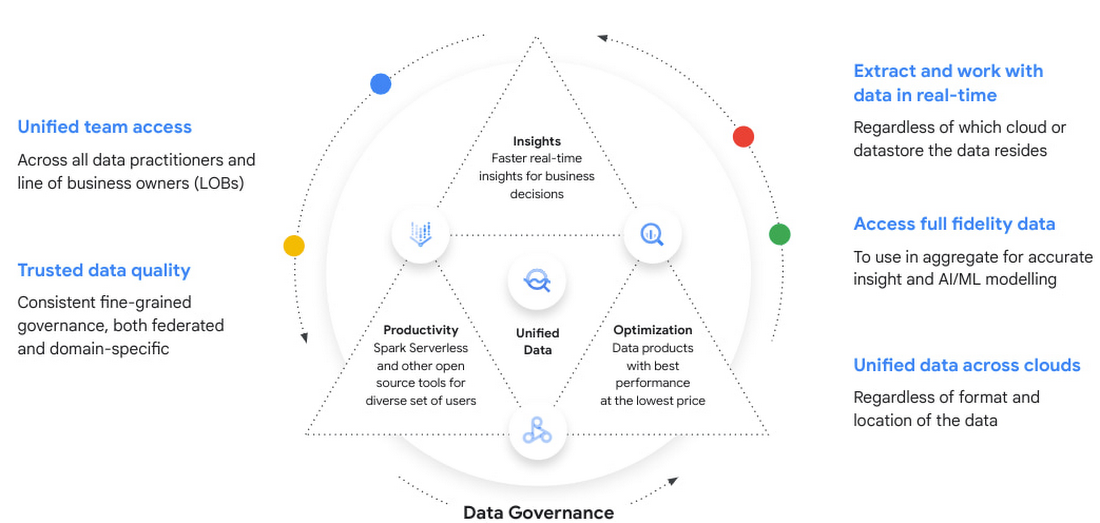
データソースの壁を取り払い、サーバーレス アーキテクチャを提供することで、スキルやビジネス要件に合った最適な処理フレームワークを選択できるようになります。次の図は、サイロ、リスク、コストの問題を解消しつつ、エクスペリエンスを簡素化するための分析レイクハウスのアーキテクチャの構成要素を示しています。
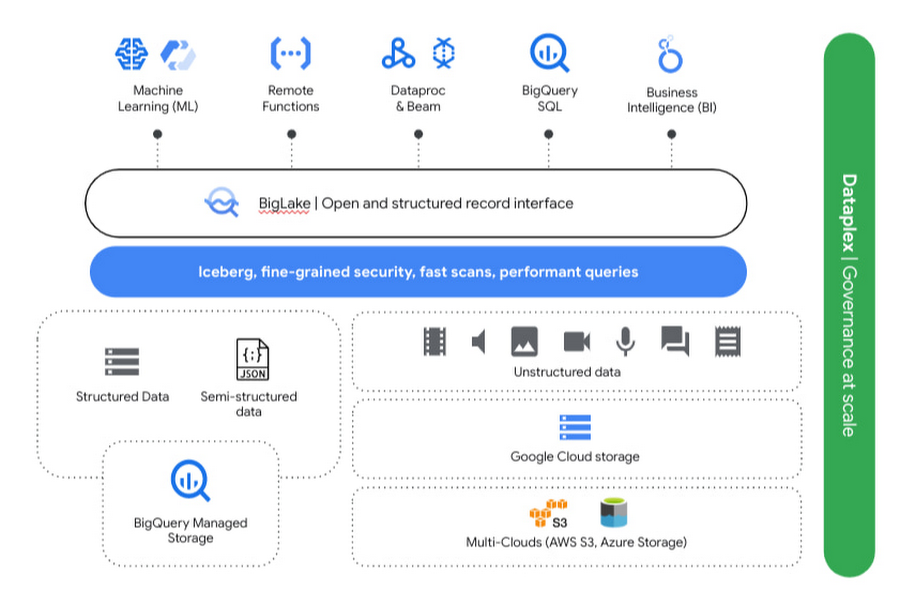
Google の分析レイクハウスの特長
Google の分析レイクハウスはまったくの新しいプロダクトというわけではなく、信頼性の高い Google サービス(Cloud Storage、BigQuery、Dataproc、Dataflow、Looker、Dataplex、Vertex AI など)で構築されているものです。Google Cloud の復元性、耐久性、スケーラビリティを活用し、オープンでインテリジェントな統合型データ プラットフォームで顧客のイノベーションを加速させます。このデータ プラットフォームは、従来のデータ ウェアハウスとデータレイクをシームレスにつなぎ、両方の利点を顧客にもたらしてくれる、Google の分析レイクハウスの基盤となるものです。分析レイクハウスのアーキテクチャでは、データがどこにあったとしても
分析が可能です。このアーキテクチャは以下のようなコンポーネントで構成されます。
取り込み: リアルタイム ストリーム、トランザクション システムの生の変更ログ、ファイル上の構造化 / 半構造化 / 非構造化データなど、さまざまなソースからのデータを取り込めます。
データ処理: 取り込んだデータは処理され、一連のゾーンへと移されます。まず、データはそのままの状態で未加工ゾーンに保存されます。次のレイヤでは、拡充ゾーンで一般的な ETL / ELT 処理(データ クレンジング、拡充、フィルタリング、その他の変換など)を行うことができます。最後に、ビジネスレベルの集計データは使用のためにキュレートされたレイヤに保存されます。
柔軟なストレージ オプション: 分析レイクハウスではオープンソースの Apache Parquet、Iceberg、BigQuery マネージド ストレージが利用できるので、ユーザーの要件に合わせてストレージを選択できます。
データの使用: いずれの段階でも、BigQuery、サーバーレス Spark、Apache Beam、BI ツール、または機械学習(ML)アプリケーションから直接データにアクセスできます。統合型のサーバーレス アプリケーションを備えたコンピューティング プラットフォームのオプションを揃えており、ニーズに合ったフレームワークを組織に活用できます。コンピューティングとストレージが完全に分離されているため、データの使用が処理に影響することがありません。ユーザーは自由にサーバーレス アプリケーションを選択し、数秒以内にクエリを実行できます。さらに、レイクハウスにはデータ サイエンスのユースケースで高度な新しいユースケースをスケーリングする動的なプラットフォームが用意されています。レイクハウスには ML が組み込まれており、短期間で効果が得られるようになっています。
データ ガバナンス: 統合されたデータ ガバナンス レイヤによりデータの管理、モニタリング、統制がレイクハウスに一元化され、さまざまな分析ツールやデータ サイエンス ツールにデータを提供できるようになります。
FinOps: Google Data Cloud では、需要の変動に対して自動的に調整を行い、インテリジェントに容量を管理できるので、実際に使用した量以上の支払いが発生することはありません。Right Fitting を組み合わせた動的な自動スケーリングにより、クエリ分析のためのコンピューティング容量を最大で 40% 削減できます。
「BigQuery は価格設定に柔軟に対応しているため、PayPal はデータをレイクハウスとして統合できます。BigQuery の圧縮ストレージと自動スケーリングのオプションは、スケーラブルなデータ処理のパイプラインとデータ使用を、費用対効果の高い方法でユーザー コミュニティに提供するのに役立っています。」 - PayPal、エンタープライズ データ プラットフォーム担当バイス プレジデント Bala Natarajan 氏
データサイロを増やすことなく「データ アーキテクチャ」を自由に選択
データにまつわる文化と能力は、組織によって異なります。それでも、他の組織と同じように人気のあるテクノロジーやソリューションを利用することが期待されがちです。所属している組織では何年にもわたってレガシー アプリケーションを活用しており、自身でも膨大な量の専門技術と知識を身に付けてきたにもかかわらず、最新のテクノロジーのトレンドに基づいた新たな方法を採用するよう指示されることがあるでしょう。一方、レガシー システムを一切持たないデジタル ネイティブな組織出身であっても、プロセス ドリブン型の確立された組織と同じ原理に従うよう期待されるかもしれません。問題は、組織のスタイルに合っていないデータ処理テクノロジーを使うべきか、それとも組織のデータに関する文化やスキルを活用することに注力すべきかという点です。
Google Cloud では、特定のフレームワーク、ベンダー、ファイル形式への依存を最小限に抑えたオープンなプラットフォームのオプションを提供することを理念としています。組織全体としてだけではなく、組織内のチームレベルでも、独自のスキルを活用し、それぞれに適した方法を取ることができるはずです。固定観念にとらわれず考えてみましょう。ストレージとコンピューティングを分離するのはどうでしょうか。しかも、多くのソリューションとは違い、単に論理的にではなく物理的にも分離します。それと同時に、先ほどのフルマネージド サーバーレス アプリケーションを使ってコンピューティングの必要性をなくしてしまうのです。そうすればデータの課題を解決するための最適なアプリケーション フレームワークを活用できるようになり、ビジネス要件を満たすことができます。こうすることでチームのスキルセットを活用し、製品化にかかる時間を短縮できます。
オープンソース テクノロジーを使って組織に分析レイクハウスを構築する場合は、Cloud Storage が提供している低コストのオブジェクト ストレージやその他のクラウドを使用し、Parquet や Iceberg などのオープン フォーマットでデータを保存すれば簡単です。Spark や Hadoop といった処理エンジンや処理フレームワークでは、これらを含む多くのファイル形式が使用されています。こうしたエンジンまたはフレームワークを Dataproc や標準の仮想マシン(VM)で実行し、トランザクションを可能にできます。このオープンソース ベースのソリューションには、ポータビリティ、コミュニティ サポート、柔軟性といった面で利点があります(ただし、構成、チューニング、スケーリングの面では必要な作業が増えます)。別の方法として、Hadoop のマネージド バージョンである Dataproc を活用することもできます。それにより、Hadoop システムの管理上のオーバーヘッドを最小限に抑えつつ、公開されているオープンソースのデータタイプにアクセスできます。
データに ML を取り入れる
組織内には、エンドツーエンドのデータ ライフサイクルにおいて特定の役割を担うユーザーが多くいます。データ アナリストは SQL クエリを記述してデータ パイプラインを作成し、BigQuery から得られたインサイトを分析します。データ サイエンティストは、モデルの構築と検証のさまざまな面に関わります。ML エンジニアは、本番環境システムでモデルがエンドユーザーに対して問題なく動作するようにする責任を負っています。データ エンジニア、データ アナリスト、データ サイエンティストなど、ユーザーの職務が異なればニーズも異なります。こうした点を踏まえ、Google はプラットフォームが包括的なものになるように構築してきました。
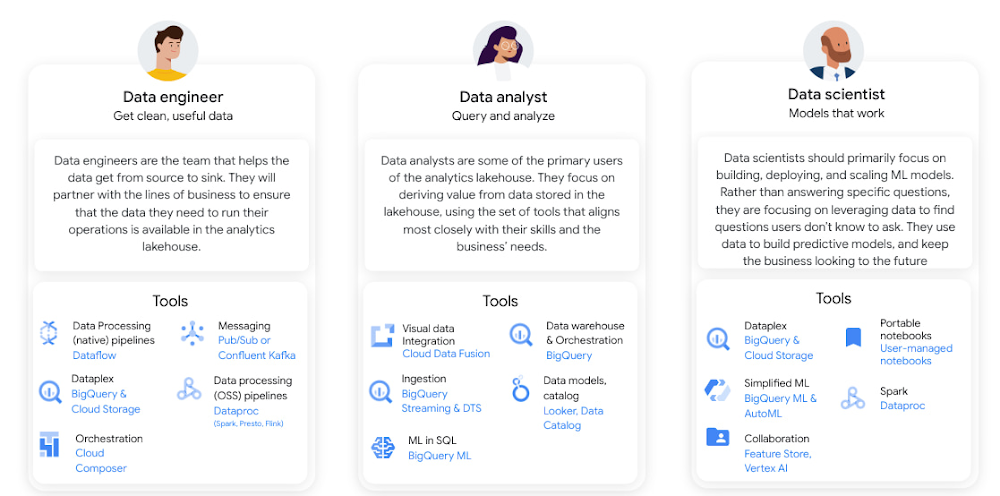
また、Google Cloud に用意されている種々のクラウドネイティブ ツールは、コストやパフォーマンスの点でクラウドの利点を備えた分析レイクハウスを構築するのに役立ちます。こうしたツールには、こちらのホワイトペーパーで説明している、以下のような主要な機能が含まれています。
データソースや、データを使用するエンドユーザーに合わせた各種のストレージ オプションと最適化。
処理と分析について、ユースケースごとに求められるスピードとコストのバランスを最適化する複数のサーバーレス コンピューティング エンジンとステートフル コンピューティング エンジン。
レイクハウスに保存されたデータの価値を最大化する、誰もが利用できるセルフサービスの BI および ML ツール。
煩雑な事務作業によりイノベーションや支援が阻害されないよう、データ使用の生産性とアカウンタビリティを確保するガバナンス。
高度な分析と AI
BigQuery は BigQuery ML を使って予測分析をサポートします。BigQuery ML は SQL を使用して ML のトレーニングと予測を行うインデータベースの ML 機能です。分類、回帰、時系列予測、異常検出、レコメンデーションのユースケースに活用できます。また、Vertex Vision、自然言語処理(テキスト)、翻訳など、Google の最先端の事前トレーニング済みモデルサービスを活用し、ビジョンやテキストの非構造化データで予測分析を行うことができます。これは BigQuery に組み込まれているバッチの ML 推論エンジンを使って動画やテキストに拡張できます。これによって独自のモデルを BigQuery に持ち込めるので、データ パイプラインの作成を簡素化できます。また、Vertex AI やサードパーティのフレームワークも利用できます。
ジェネレーティブ AI はパワフルではあるものの新しいテクノロジーであり、簡単に AI を有効化してテストから本番環境へ移行する方法が組織にはありません。ジェネレーティブ AI の Cloud AI とのインテグレーションにより、高度なテキスト分析が分析レイクハウスに組み込まれます。これにより、データチームが AI を感情分析、データ分類、拡充、翻訳に活用する可能性が広がります。
繰り返し可能なオーケストレーションを自動化する
これらのアーキテクチャ コンポーネントの土台となっているのは、繰り返し可能なタスクの復元性に優れた自動化とオーケストレーションです。自動化を使用することでデータがシステムを移動する際の精度が向上し、エンドユーザーにデータの信頼性が認められるようになり、分析レイクハウスの使用、普及が促されます。
Google Cloud の分析レイクハウスの詳細は、包括的なホワイト ペーパーをダウンロードしてご確認ください。
その他の情報
分析レイクハウスを使用して、Squarespace がエスカレーション件数を 87% 削減した方法。
分析レイクハウスを使用して、Dun & Bradstreet がパフォーマンスを 5 倍向上させた方法。
- Google、プロダクト管理 Firat Tekiner
- アドバンスト アナリティクス担当プロダクト マーケティング責任者 Ragi Mahil



