ML とデータの距離を縮める BigQuery の新しい推論エンジンの発表
Google Cloud Japan Team
※この投稿は米国時間 2023 年 3 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
世界中の企業が、AI と ML の機能の可能性に期待しています。一方、Harvard Business Review(HBR)によると、本番環境に移行される ML モデルはわずか 20% にすぎません。これは、多くの場合、中核となるデータ分析環境とは別の環境に ML がデプロイされるためです。データと AI の間に広がるこういったギャップを解消するには、企業は大規模なデータ パイプラインを構築し、Python やその他の高度なコーディング言語に精通したリソースを雇用し、ガバナンスを管理し、デプロイ インフラストラクチャをスケーリングしなくてはなりません。しかし、ML を活用するためのこのようなアプローチは費用がかかるだけでなく、いくつかのセキュリティ リスクもはらんでいます。
BigQuery ML は、ML でデータを直接活用できるようにすることで、このギャップに対処します。2019 年に BigQuery ML が一般提供されて以来、何億もの予測クエリやトレーニング クエリが実行され、その使用率は 2022 年に 200%(前年比)以上増加しています。
そこでこのたび、BigQuery ML 推論エンジンを発表いたします。このエンジンにより、BigQuery で直接一般的なモデル形式を使用して予測を実行できるだけでなく、リモートでホストされるモデルや、Google の最先端の事前トレーニング済みモデルを使用して予測を実行することもできます。これは、データ ウェアハウスにおける予測分析のシームレスな統合に向けた大きな一歩と言えるでしょう。この新機能を使用すると、以下に対して ML 推論を実行できます。
さまざまな形式(ONNX、XGBoost、TensorFlow など)の BigQuery の外部でトレーニングされ、インポートされたカスタムモデル
Vertex AI Prediction でリモートでホストされるモデル
最先端の事前トレーニング済み Cloud AI モデル(Vision、NLP、Translate など)
これらの機能はすべて、データが存在する BigQuery 内で利用できます。そのため、データの移動が不要になり、費用とセキュリティ リスクを低減できます。また、高度なプログラミング言語の知識がなくても、使い慣れた SQL を使用して、幅広い ML 機能を活用できます。さらに、BigQuery のペタバイト規模のスケーリングとパフォーマンスにより、サービスを提供するインフラストラクチャの設定に悩まされることもありません。どのようなワークロードにも対応します。
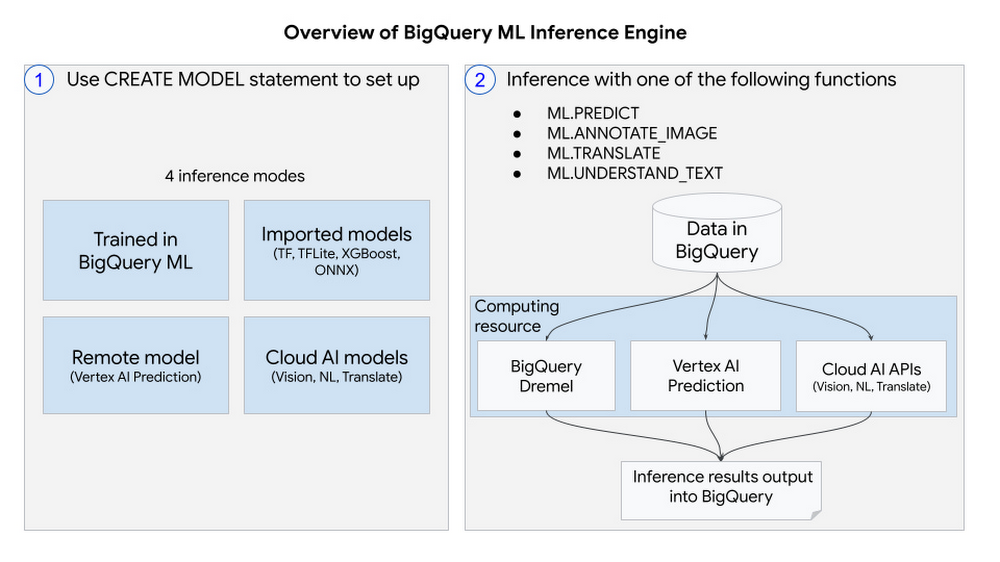
これらの各機能を詳しく見てみましょう。
BigQuery の外部でトレーニングされ、インポートされたカスタムモデル
BigQuery ML は、BigQuery の外部でトレーニングされたモデルをインポートできます。これまでは、TensorFlow モデルに限られていましたが、TensorFlow Lite、XGBoost、ONNX にも拡張しました。たとえば、PyTorch や scikit-learn などの多くの一般的な ML フレームワークを ONNX に変換し、BigQuery ML にインポートできます。これにより、データを移動することなく、他の場所で開発された最先端のモデルを使って BigQuery 内で直接予測を実行することができます。BigQuery 内で推論を実行することで、バッチ推論タスクに BigQuery の分散クエリ エンジンを活用できるため、パフォーマンスが向上します。
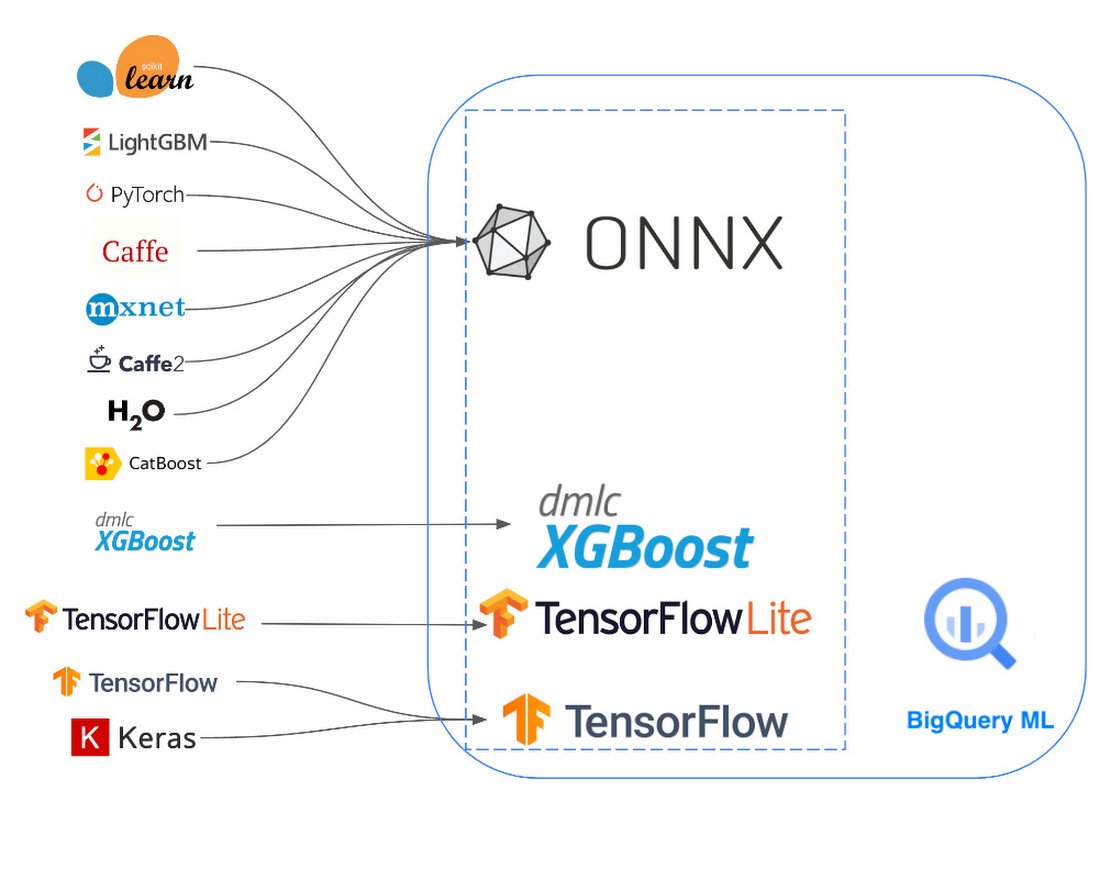
基本的なワークフローは次のようになります。
事前トレーニング済みモデルのアーティファクトを Cloud Storage バケットに保存する
CREATE MODEL ステートメントを実行し、モデルのアーティファクトを BigQuery にインポートする
ML.PREDICT クエリを実行し、インポートしたモデルで予測を行う

リモートモデルでの推論
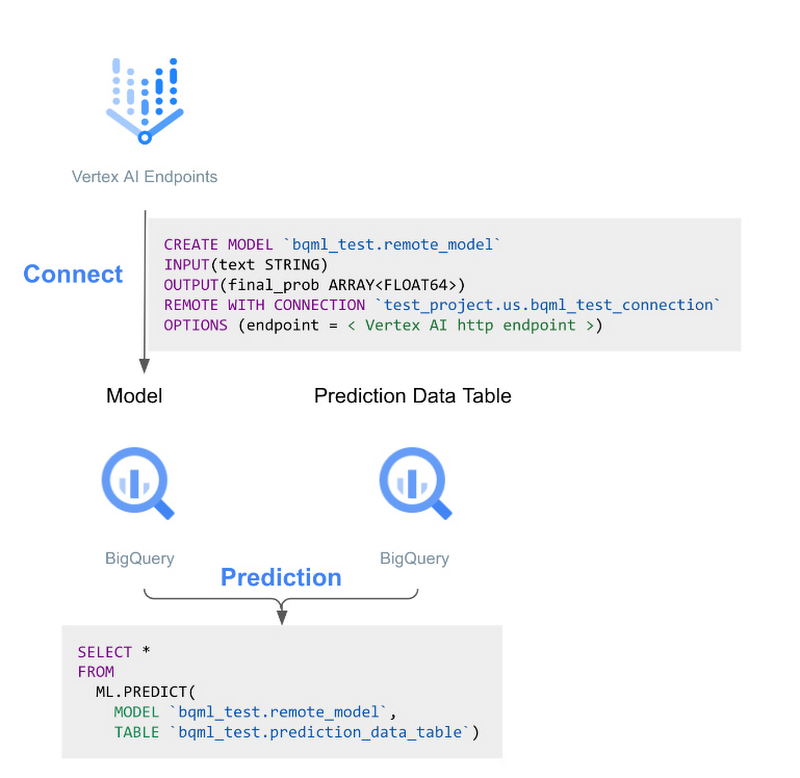
モデルによっては、低レイテンシのリクエストと大量のパラメータを処理するために、独自のサービスを提供するインフラストラクチャが必要になります。Vertex AI エンドポイントは、リクエストを処理するための自動スケーリングと、GPU およびマルチ GPU サービング ノードでコンピューティングを高速化するオプションにアクセスできるようにすることで、これを容易に実現します。これらのエンドポイントは、ビルド済みコンテナ、カスタム コンテナ、カスタム予測ルーチン、さらには NVIDIA Triton Inference Server の多くのオプションを使用して、実質無制限のモデルタイプに構成することが可能です。BigQuery ML 内から、これらのリモートモデルを使用して推論を行うことができます。
基本的なワークフローは次のようになります。
Vertex AI エンドポイントでモデルをホストする
Vertex AI エンドポイントを指定する CREATE MODEL ステートメントを BigQuery で実行する
ML.PREDICT を使用して BigQuery データを送信し、リモートの Vertex AI エンドポイントに対して推論を実行し、結果を BigQuery に返す
非構造化データによる Vertex AI API での推論
今年の初め、私たちは BigQuery ML で画像などの非構造化データをサポートすることを発表しました。このたび、その取り組みをさらに一歩進めて、BigQuery 内で、画像(Vision AI)、テキストの把握(Natural Language AI)、翻訳(Translate AI)に対し、Vertex AI の最先端の事前トレーニング済みモデルで推論を実行できるようになりました。これらのモデルは、BigQuery ML 推論エンジン内で直接独自の予測関数を使用して利用できます。これらの API は、テキストや画像を入力として受け取り、JSON データ型で BigQuery に保存されている JSON レスポンスを返します。
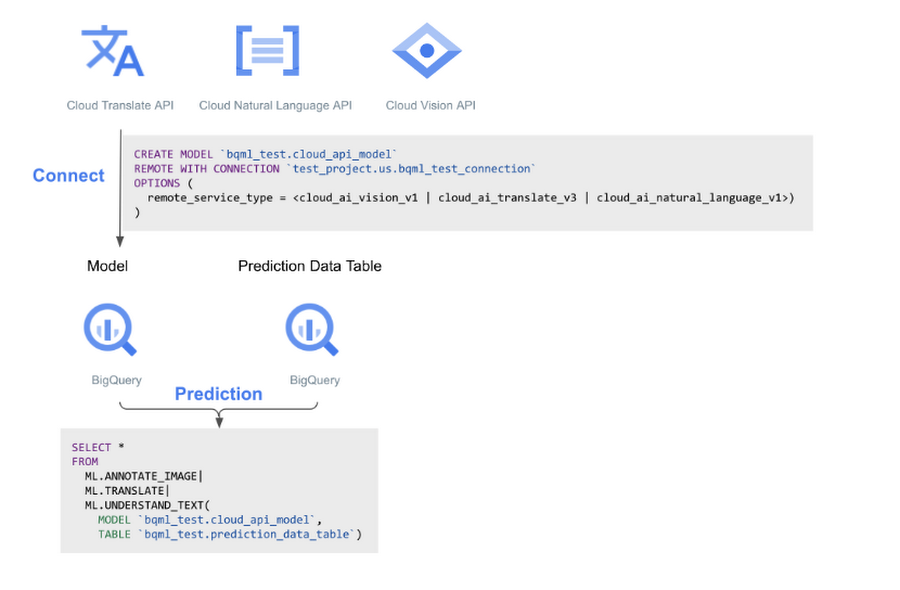
基本的なワークフローは次のようになります。
画像を扱う場合は、まず画像でオブジェクト テーブルを作成します。BigQuery でテキストを扱う場合、この手順は必要ありません。
CREATE MODEL ステートメントを実行し、リモート接続とともにパラメータとして Vertex AI モデルタイプを使用します。
以下の関数のいずれかを使用して、BigQuery のデータを Vertex AI に送信し、推論結果を取得します。
ML.ANNOTATE_IMAGE
ML.TRANSLATE
ML.UNDERSTAND_TEXT

使ってみる
BigQuery ML は、オープンソースやその他のプラットフォームでホストされる幅広いモデルで推論を実行できるようサポートを拡張することで、ビジネスデータへの ML の力の活用をシンプルかつ簡単で、費用対効果の高いものにします。これらの新機能の詳細については、ドキュメントをご確認ください。また、早期アクセスにもご登録いただけます。
このブログ投稿に、Google 社員(Firat Tekiner、Jiashang Liu、Mike Henderson、Yunmeng Xie、Xiaoqiu Huang、Bo Yang、Mingge Deng、Manoj Gunti、Tony Lu)が協力してくれました。多くの Google 社員の尽力によって、これらの機能が実現しています。
- Google、プロダクト管理 Abhinav Khushraj



