Unify your data assets with an open analytics lakehouse
Firat Tekiner
Product Management
Ragi Mahil
Head of Product Marketing, Advanced Analytics
For over a decade, the technology industry has searched for ways to store and analyze vast amounts of data that can handle an organization’s volume, latency, resilience, and varying data access requirements. Companies have been making the best of existing technology stacks to tackle these issues, which typically involves trying to either make a data lake behave like an interactive data warehouse or make a data warehouse act like a data lake — processing and storing vast amounts of semi-structured data. Both approaches have resulted in unhappy users, high costs, and data duplication across the enterprise.
The need for architecture designed to address complex data needs for all users including data analysts, data engineers, and data scientists.
Historically for analytics, organizations have implemented different solutions for different data use cases: data warehouses for storing and analyzing structured aggregate data primarily used for business intelligence (BI) and reporting, and data lakes for unstructured and semi-structured data, in large volumes, primarily used for data exploration and machine learning (ML) workloads. This approach often resulted in extensive data movement, processing, and duplication, requiring complex extract, transform, and load (ETL) pipelines. Operationalizing and governing this architecture took time and effort and reduced agility. As organizations move to the cloud, they want to break these silos.
Moving to the cloud brings otherwise disparate data sources together and paves the way for everyone to become part of the data and AI ecosystem. It is undeniable that organizations want to leverage data science capabilities at scale, but many still need to realize their return on investments. According to a recent study, 91% of organizations increase investments in data and AI. Yet only 20% see their models go into production deployment. Business Users, Data Analysts, Data Engineers, and Data Scientists want to become part of the Data and AI ecosystem.
The rise of the analytics lakehouse
Google Cloud’s analytics lakehouse combines the key benefits of data lakes and data warehouses without the overhead of each. We discuss the architecture in detail throughout the “Build an analytics lakehouse on Google Cloud” technical whitepaper. However, in a nutshell, this end-to-end architecture enables organizations to extract data in real-time regardless of which cloud or datastore the data resides in and use it in aggregate for greater insight and artificial intelligence (AI), with governance and unified access across teams.
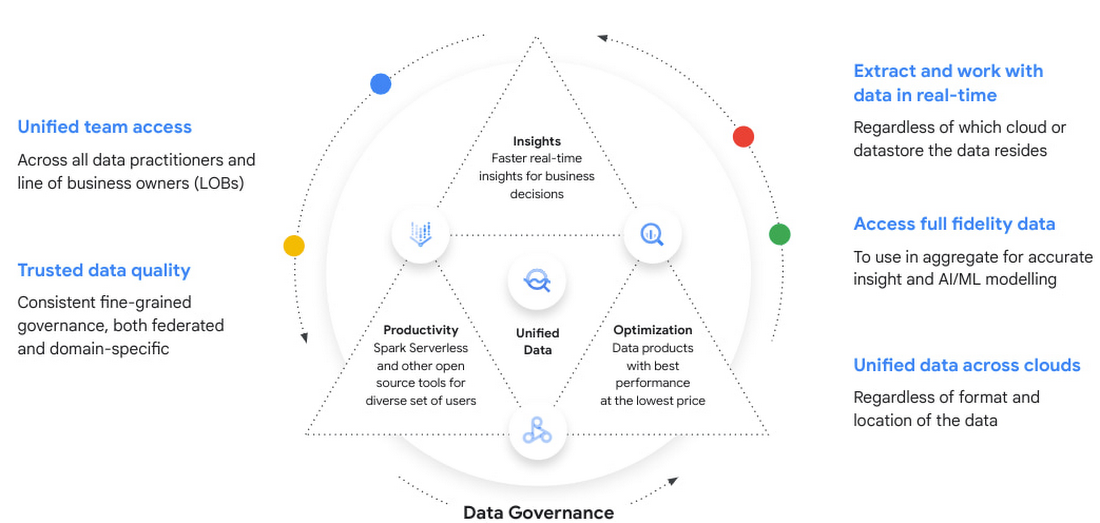
By breaking the barriers between data sources and providing serverless architectures, the game becomes choosing the optimal processing framework that suits your skills and business requirements. Here are the building blocks of the analytics lakehouse architecture to simplify the experience, while removing silos, risk, and cost:
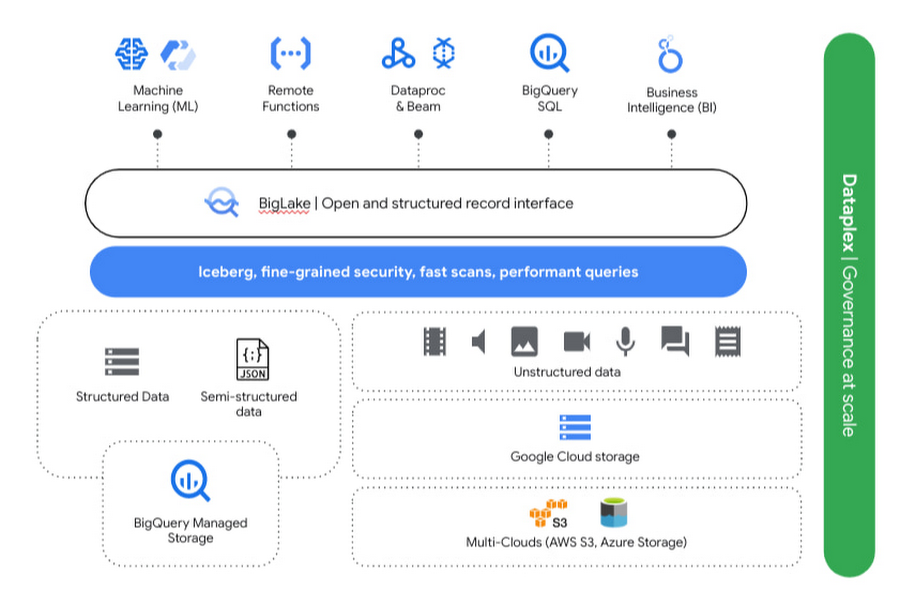
What makes Google’s analytics lakehouse approach unique?
Google’s analytics lakehouse is not a completely new product but is built on Google’s trusted services such as Cloud Storage, BigQuery, Dataproc, Dataflow, Looker, Dataplex, Vertex AI and others. Leveraging Google Cloud's resiliency, durability, and scalability, Google enables customers to innovate faster with an open, unified, intelligent data platform. This data platform is the foundation for Google's analytics lakehouse, which blurs the lines between traditional data warehouses and data lakes to provide customers with both benefits. Bring your analytics to your data wherever it resides with the
the analytics lakehouse architecture. These architecture components include:
Ingestion: Users can ingest data from various sources, including but not limited to real-time streams, change logs directly from transactional systems, and structured, semi-structured, and unstructured data on files.
Data processing: Data is then processed and moved onto a series of zones. First, data is stored as is within the raw zone. The next layer can handle typical ETL/ELT operations such as data cleansing, enrichment, filtering, and other transformations within the enriched zone. Finally, business-level aggregates are stored in the curated layer for consumption.
Flexible storage options: An analytics lakehouse approach which allows users to leverage open-source Apache Parquet, Iceberg, and BigQuery managed storage, Providing users with the storage options and meeting them where they are based on their requirements.
Data consumption: At any stage, data can be accessed directly from BigQuery, Serverless Spark, Apache Beam, BI tools, or Machine Learning (ML) applications. Providing the choice of compute platforms with unified serverless applications, organizations can leverage any framework that meets their needs. Data consumption does not impact processing due to the complete separation of compute and storage. Users are free to choose serverless applications and run queries within seconds. In addition, the lakehouse provides the dynamic platform to scale advanced new use cases with data-science use cases. With built-in ML inside the lakehouse, you can accelerate time to value.
Data governance: A unified data governance layer provides a centralized place to manage, monitor, and govern your data in the lakehouse and make this data securely accessible to various analytics and data science tools.
FinOps: Google's Data Cloud can auto adjust fluctuations in demand and can intelligently manage capacity, so you don't pay for more than you use. Capabilities include dynamic autoscaling, in combination with right-fitting, which saves up to 40% in committed compute capacity for query analysis.
"BigQuery’s flexible support for pricing allows PayPal to consolidate data as a lakehouse. Compressed storage along with autoscale options in BigQuery help us provide scalable data processing pipelines and data usage in a cost-effective manner to our user community." — Bala Natarajan, VP Enterprise Data Platforms at PayPal
Freedom of ‘data architecture’ choice without more data silos
Every organization has its own data culture and capabilities. Yet each is expected to use popular technology and solutions like everyone else. Your organization may be built on years of legacy applications, and you may have developed a considerable amount of expertise and knowledge, yet you may be asked to adopt a new approach based on the latest technology trend. On the other end of the spectrum, you may come from a digital-native organization with no legacy systems at all, but be expected to follow the same principles as process-driven, established organizations. The question is, should you use data processing technology that doesn’t match your organization style, or should you focus on leveraging your culture and skills?
At Google Cloud, we believe in providing choice to our customers — the option of an open platform that minimizes dependencies on a specific framework, vendor, or file format. Not only organizations, but also the teams in each organization, should be able to leverage their skills and do what’s right for them. Let’s go against the school of thought, how about we decouple storage and compute and we do this physically rather than just logically unlike most of the solutions. At the same time, we remove the computational needs with fully managed serverless applications as mentioned earlier. Then the game becomes leveraging the optimal application framework to solve your data challenges to meet your business requirements. In this way, you can capitalize on your team's skill sets and improve time to market.
Organizations that want to build their analytics lakehouse using open-source technologies can easily do so by using low-cost object storage provided by Cloud Storage or from other clouds — storing data in open formats like Parquet and Iceberg, for example. Processing engines and frameworks like Spark and Hadoop use these and many other file types, and can be run on Dataproc or regular virtual machines (VMs) to enable transactions. This open-source-based solution has the benefits of portability, community support, and flexibility (though it requires extra effort in terms of configuration, tuning, and scaling). Alternatively, Dataproc is a managed version of Hadoop, which minimizes the management overhead of Hadoop systems, while still being able to access non-proprietary, open-source data types.
Bring ML to your data
There are many users within an organization who have a part to play in the end-to-end data lifecycle. Consider a data analyst, who can simply write SQL queries to create data pipelines and analyze insights from BigQuery. Or a data scientist who dabbles with different aspects of building and validating models. Or an ML engineer who is responsible for the model to work without issues to end users in production systems. Users like data engineers, data analysts, and data scientists all have different needs, and we have intentionally built a comprehensive platform for them in mind.
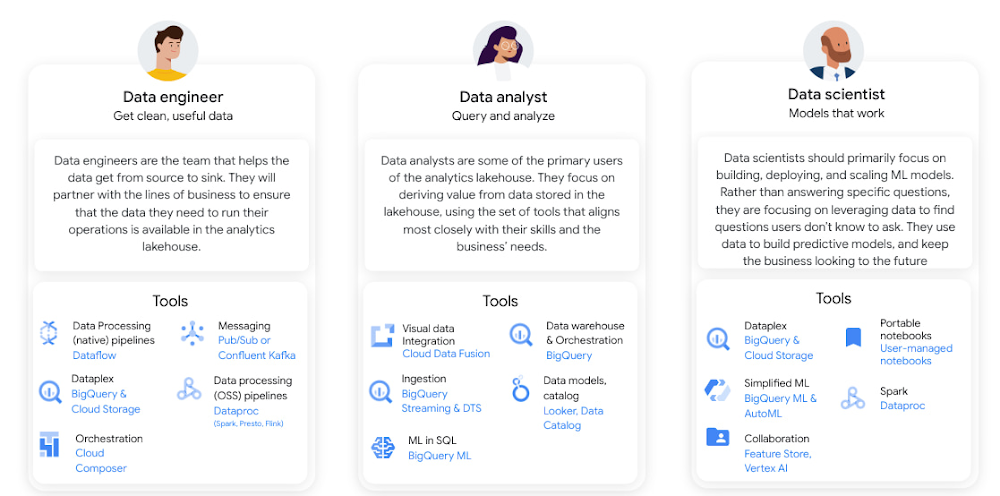
Google Cloud also offers cloud-native tools to build an analytics lakehouse with the cost and performance benefits of the cloud. These include a few key pieces that we will discuss throughout the whitepaper:
Different storage options and optimizations depending on the data sources and end users consuming the data.
Several serverless and stateful compute engines, balancing the benefits of speed and costs as required by each use case for processing and analytics.
Democratized and self-service BI and ML tools, to maximize the value of data stored in the lakehouse.
Governance, ensuring productive and accountable use of data so that bureaucracy does not inhibit innovation and enablement.
Advanced analytics and AI
BigQuery supports predictive analytics through BigQuery ML, an in-database ML capability for ML training and predictions using SQL. It helps users with classification, regression, time-series forecasting, anomaly detection, and recommendation use cases. Users can also do predictive analytics with unstructured data for vision and text, leveraging Google’s state-of-the-art pre-trained model services like Vertex Vision, Natural Language Processing (Text) and Translate. This can be extended to video and text, with BigQuery’s built-in batch ML inference engine, which enables users to bring their own models to BigQuery, thereby simplifying data pipeline creation. Users can also leverage Vertex AI and third-party frameworks.
Generative AI is a powerful and emerging technology but organizations are lacking a way to easily activate AI and move from experimentation into production. Integration with Cloud AI for Generative AI will embed advanced text analysis with your analytics lakehouse. This opens up new possibilities for your data teams to use AI for sentiment analysis, data classification, enrichment, and language translations.
Automate orchestration of repeatable tasks
Underpinning these architectural components is resilient automation and orchestration of repeatable tasks. With automation, as data moves through the system, improved accuracy instills confidence in end users to trust it, making them more likely to interact with and evangelize the analytics lakehouse.
To learn more about the analytics lakehouse on Google Cloud, download the complimentary white paper.
Further resources
Learn how Squarespace reduces the number of escalations by 87% with the analytics lakehouse.
Learn how Dun & Bradstreet improved performance by 5X with the analytics lakehouse.

