Gemini and OSS text embeddings are now in BigQuery ML
Jasper Xu
Software Engineer
Haiyang Qi
Software Engineer, BigQuery ML
High-quality text embeddings are the engine for modern AI applications like semantic search, classification, and retrieval-augmented generation (RAG). But when it comes to picking a model to generate these embeddings, we know one size doesn’t fit all. Some use cases demand state-of-the-art quality, while others prioritize cost, speed, or compatibility with the open-source ecosystem.
To give you the power of choice, we’re excited to announce a major expansion of text embedding capabilities in BigQuery ML. In addition to the existing text-embedding-004/005 and text-multilingual-embedding-OO2 models, you can now use Google’s powerful Gemini embedding model and over 13K open-source (OSS) models directly within BigQuery. Generate embeddings with simple SQL commands, using the model that’s right for your job, right where your data lives.
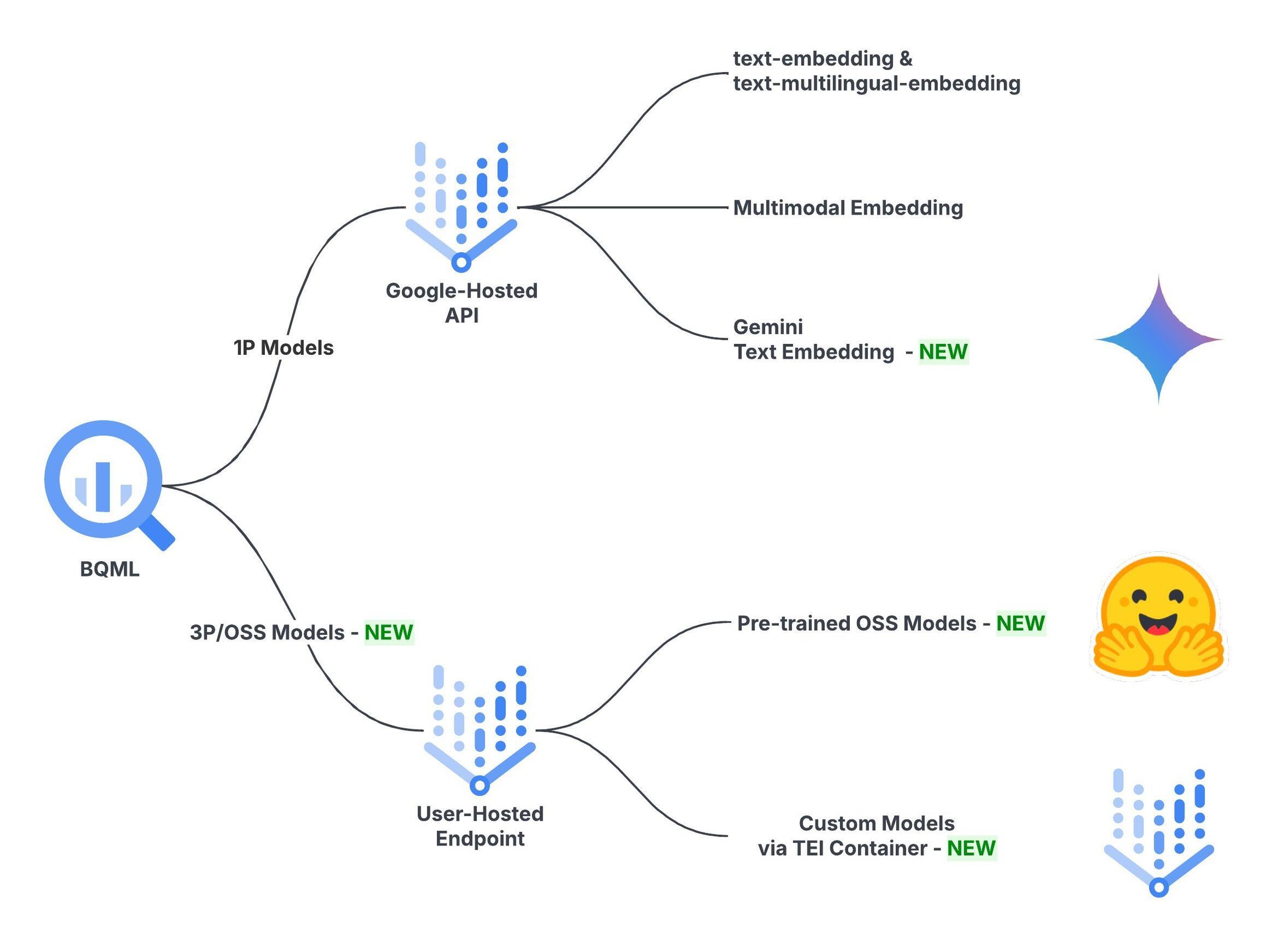
Choosing an embedding model to fit your needs
With the addition of Gemini and a wide array of OSS models, BigQuery now offers a comprehensive list of text-embedding options. You can choose the right one that fits your needs, for model quality, cost, and scalability. Here’s a breakdown to help you decide.
Gemini embedding model in BigQuery ML
The Gemini embedding model is a state-of-the-art text embedding model that has consistently secured the top position on the Massive Text Embedding Benchmark (MTEB) leaderboard, a leading industry text-embedding benchmark. The model's first-place ranking on the MTEB leaderboard directly demonstrates its high quality embedding.
Here’s how to use the new Gemini embedding model in BigQuery:
1. Create a Gemini embedding model in BigQuery
Create the Gemini embedding model in BigQuery with the following SQL statement: by specifying the endpoint to be `gemini-embedding-001`:
2. Batch embedding generation
Now you can generate embeddings using the gemini-embedding model directly from BigQuery. The following example embeds the text in the bigquery-public-data.hacker_news.full dataset.
The Gemini embedding model utilizes a new quota control method known as Tokens Per Minute (TPM). For projects with a high reputation score, the default TPM value is 5 million. It's important to note that the maximum TPM a customer can set without manual approval is 20 million.
The total number of rows a job can process depends on the number of tokens per row. For example, a job processing a table with 300 tokens per row can handle up to 12 million rows with a single job.
OSS embedding models in BigQuery ML
The OSS community is rapidly evolving the text-embedding model landscape, offering a wide spectrum of choices to fit any need. Offerings range from top-ranking models like the recent Qwen3-Embedding & EmbeddingGemma to small, efficient, and cost-effective small models such as multilingual-e5-small.
You can now use any Hugging Face text embedding models (13K+ options) deployed to Vertex AI Model Garden in BigQuery ML. To showcase this capability, in our example we will use multilingual-e5-small, which delivers respectable performance while being massively scalable and cost-effective, making it a strong fit for large-scale analytical tasks.
To use an open-source text-embedding model, follow these steps.
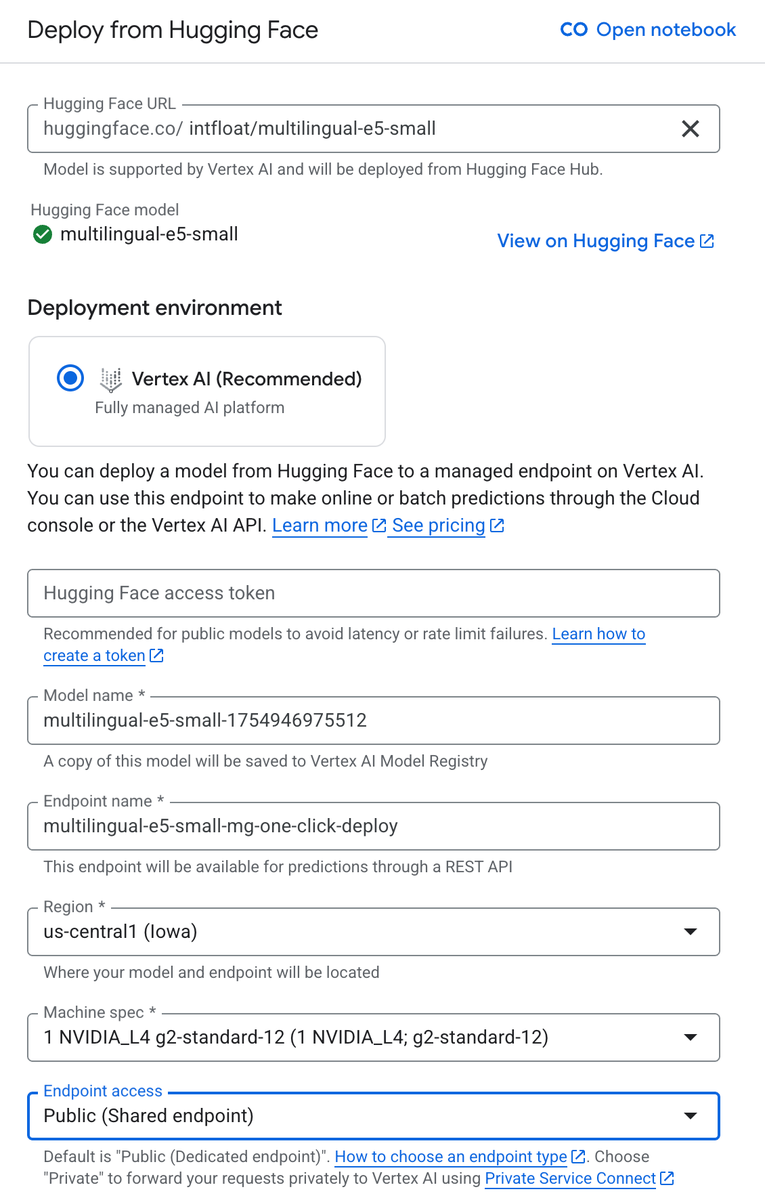
1. Host the model on a Vertex endpoint
First, choose a text-embedding model from Hugging Face, in this case, the above-mentioned multilingual-e5-small. Then, navigate to Vertex AI Model Garden > Deploy from Hugging Face. Enter the model URL, and set the Endpoint access to “Public (Shared endpoint)”. You can also customize the endpoint name, region, and machine specs to fit your requirements. The default settings provision a single replica of the specified machine type below:
Alternatively, you can do this step programmatically using BigQuery Notebook (see the tutorial notebook example) or other methods mentioned in the public documentation.
2. Create a remote model in BigQuery
Deploying the model deployment takes several minutes. Once it's complete, create the corresponding remote model in BigQuery with the following SQL statement:
Replace the placeholder endpoint in the above code sample with the endpoint URL. You can get information on endpoint_id from the console via Vertex AI > Online Prediction>Endpoints>Sample Request.
3. Batch embedding generation
Now you can generate embeddings using the OSS multilingual-e5-small model directly from BigQuery. See an example as follows, which embeds the text in the bigquery-public-data.hacker_news.full dataset.
By selecting the default resources for your model deployment, the query can process all 38 million rows in the hacker_news dataset in approximately 2 hours and 10 minutes — a baseline throughput achieved with just a single model replica.
You can scale the workload by provisioning more computational resources or enable endpoint auto scaling. For example, if you choose 10 replicas, the query gets 10 times faster, and is able to handle billions of rows per a six-hour query job.
4. Undeploy the model
Vertex AI endpoints accrue costs for as long as they are active, even when the machine is idle. To complete the batch job and prevent unexpected costs, you must “undeploy” the model after batch inference. You can do this through the Google Cloud console (Vertex AI > Endpoints > your endpoint > Undeploy model from endpoint), or by using our example Colab script.
For a batch workload, the most cost-effective pattern is to treat deployment, inference, and un-deployment as a continuous workflow, minimizing idle expenses. One way to achieve this is to run the sample Colab sequentially. The results are remarkable: processing all 38 million rows costs only about $2 to $3.
Get started today
Ready to build your next AI application? Start generating embeddings with Gemini or your favorite open-source models directly in BigQuery today. Dive into our documentation to learn the details, or follow our step-by-step Colab tutorial to see it in action.

