Squarespace reduces number of escalations by 87 percent with analytics lakehouse on Google Cloud
Douglas O’Connor
Senior Software Engineering Manager, Squarespace
Constantinos Sevdinoglou
Senior Staff Software Engineer, Squarespace
Editor’s note: Today we hear from Squarespace, an all-in-one website building and ecommerce platform, about its migration from a self-hosted Hadoop ecosystem to Google Cloud, running BigQuery, Dataproc and Google Kubernetes Engine (GKE). Read on to learn about how they planned and executed the migration, and what kinds of results they’re seeing.
Imagine you are a makeup artist who runs an in-home beauty business. As a small business owner, you don’t have a software development team who can build you a website. Yet you need to showcase your business, allow users to book appointments directly with you, handle the processing of payments, and continuously market your services to new and existing clients.
Enter Squarespace, an all-in-one platform for websites, domains, online stores, marketing tools, and scheduling that allows users to create an online presence for their business. In this scenario, Squarespace enables the makeup artist to focus entirely on growing and running the business while Squarespace would handle digital website presence and administrative scheduling tasks. Squarespace controls and processes data for customers and their end-users. Squarespace stores data to help innovate customer user features and drive customer-driven priority investments in the platform.
Until Q4 2022, Squarespace had a self-hosted Hadoop ecosystem composed of two independently managed Hadoop clusters. Both clusters were “duplicated” because we utilized an active/passive model for geo-redundancy, and staging instances also existed. Over time, the software and hardware infrastructure started to age. We quickly ran out of disk space and came up against hard limits on what we could store. “Data purges,” or bulk deletion of files to free up disk space, became a near-quarterly exercise.
By early 2021 we knew we couldn’t sustain the pace of growth that we saw in platform usage, particularly with our on-premises Presto and Hive deployments, which housed several hundred tables. The data platform team tasked with maintaining this infrastructure was also small and unable to keep up with scaling and maintaining the infrastructure while delivering platform functionality to users. We had hit a critical decision point: double-down on running our infrastructure or move to a cloud-managed solution. Supported by leadership, we opted for Google Cloud because we had confidence in the platform and knew we could migrate and deploy quickly.
Project planning
Dependency mapping
We took the necessary time upfront to map our planned cloud infrastructure. We decided what we wanted to keep, update or replace. This strategy was beneficial, as we could choose the best method for a given component. For example, we decided to replace our on-premises Hadoop Distributed File System (HDFS) with Cloud Storage using the Hadoop GCS Connector but to keep our existing reporting jobs unchanged and not rewrite them.
In-depth dependency tracking
We identified stakeholders and began communicating our intent early. After we engaged the teams, we began weekly syncs to discuss blockers. We also relied on visual project plans to manage the work, which helped us understand the dependencies across teams to complete the migration.
Radical deprioritization
We worked backward from our target date and ensured the next two months of work were refined during the migration. With the help of top-down executive sponsorship, the team consistently fought back interrupted work by saying ‘no, not now’ to non-critical requests. This allowed us to provide realistic timelines for when we would be able to complete those requests post-migration.
Responsibilities
We broke down responsibilities by team, allowing us to optimize how our time was spent.
The data platform teams built reusable tooling to rename and drop tables and to programmatically ‘diff; entire database tables to check for exact matching outputs. They also created a Trino instance on Google Cloud that mirrored the on-prem Presto.
The data engineering teams leveraged these tools while moving each of their data pipelines.
Technology strategy
Approach
We took an iterative approach to migrating the compute and storage for all of our systems and pipelines. Changing only small, individual pieces at a time, let us validate the outputs at every migration phase, realize iterative wins, all while saving hours of manual validation time to achieve the overall architecture shown below.
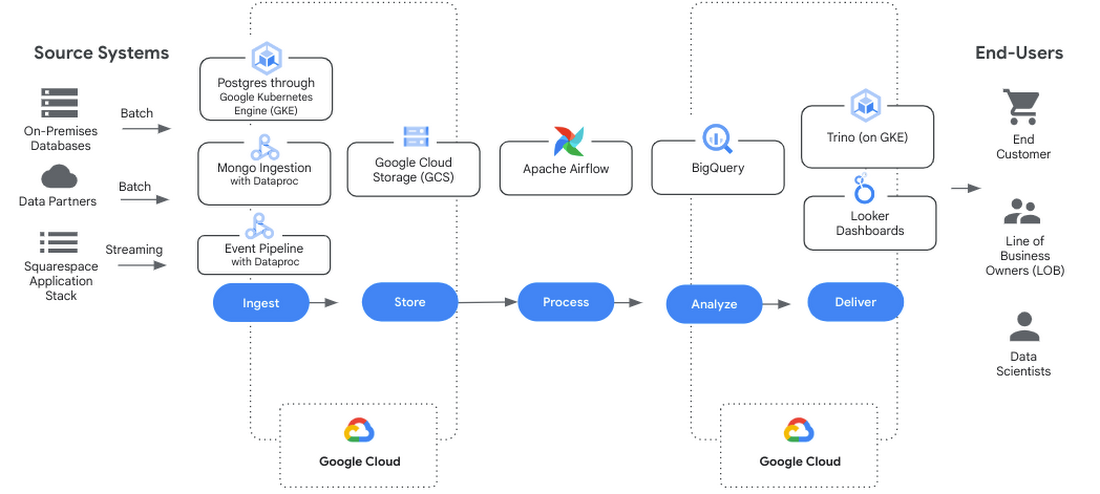
Phase 1: Cutover platform and policies
Our first step was to cut over our query engine, Presto, to run on Google Kubernetes Engine (GKE). Deploying this service gave end users a place to start experimenting with queries with an updated version of the software, now called Trino. We also cut over our platform policies, meaning we established usage guidelines for using Cloud Storage buckets or assigning IAM privileges to access data.
Phase 2: Move compute to the Cloud
Once we had a Trino instance in Google Cloud, we granted it access to our on-prem data stores. We updated our Trino Airflow operator to run jobs in Google Cloud instead of on-premises. Spark processes were migrated to Dataproc. One by one, stakeholder teams switched from executing on-premises compute to cloud-based compute while still reading and writing data on-premises. They also had the option to migrate straight to Google Cloud-based storage. We let teams decide what sequencing fit in their current commitment schedule but also stipulated a hard deadline to end on-premises storage.
Phase 3: Storage cutover
After confirming the jobs were all successfully running in Google Cloud and validating the output, we started redirecting downstream processes to read from Google Cloud data sources (Cloud Storage/BigQuery). Over time we watched the HDFS read/writes to the old clusters get to zero. At that point we knew we could shut down the on-premises hardware.
Phase 4: Cutover orchestration
Our orchestration platform, Airflow, runs on-premises. We’re investigating moving to Cloud Composer in 2023. This component is a thin slice of functionality, but represents one of the largest lifts due to the number of teams and jobs involved.
Leadership support
Our internal project sponsor was the Infrastructure team which needed to sunset the hardware. To make room for the data team to focus solely on Google Cloud migration, the Infrastructure leadership team found any opportunities possible to take responsibilities off of the data group.
Leadership within the data group shielded their engineers from all other asks from other parts of the organization, giving them plenty of support to say “no” to all non-migration related requests.
Looking forward, what’s next for Squarespace?
Following the successful migration to Google Cloud of our Hadoop ecosystem, we have seen the significant maintenance burden of the infrastructure disappear. From the months before our migration compared to the months immediately after, we’ve seen an 87% drop in the number of escalations. The data platform and data infrastructure teams have turned their attention away from monitoring the health of various services/filesystems, and are now focused on delivering new features and better software that our internal users need to move our business forward.
Next, in our analytics lakehouse plan is to continue the success we had with migrating our data lake and move more of the infrastructure responsibilities to Google Cloud. We’re actively planning the migration of our on-prem data warehouse to BigQuery and have begun to explore moving our Airflow Instances to Cloud Composer.
To learn how you can get started on your data modernization journey, contact Google Cloud.

