Exploring The Data Engineering Agent
Tim Bezold
Product Management, Data Engineering Agent
Varun Chandra
Engineering Manager, Data Engineering Agent
April 22, 2026: The Data Engineering Agent is now generally available. This blog has been updated to reflect the current state of the offering.
Data is the lifeblood of the modern enterprise, but the process of making it useful is often fraught with friction. Data engineers, analysts, and scientists—some of the most skilled and valuable talent in any organization—are spending a disproportionate amount of their time on repetitive, low-impact tasks. What if you could shift your focus from manually building and maintaining pipelines to defining the best practices and rules that automate them?
Today, we’re announcing a fundamental shift to solve this challenge. You now have access to the Data Engineering Agent, a first-party agent designed to automate the most complex and time-consuming data engineering tasks, powered by Gemini.
The Data Engineering Agent isn't just an incremental improvement; it's fundamentally transforming the way we work, with truly autonomous data engineering operations. According to IDC, ‘GenAI and other automation solutions will drive over $1 trillion in productivity gains for companies by 2026’1.
Here is a closer look at the powerful capabilities you can access today:
Pipeline development and maintenance
The Data Engineering Agent makes it easy to build and maintain robust data pipelines. The agent is available in BigQuery pipelines and it can help you with:
-
Natural language pipeline creation: Describe your pipeline requirements in plain language, and the agent generates the necessary SQL code, adhering to data engineering best practices that you can customize through instruction files. For example: "Create a pipeline to load data from the 'customer_orders' bucket, standardize the date formats, remove duplicate entries, and load it into a BigQuery table named 'clean_orders'.”
-
Intelligent pipeline modification: Need to update an existing pipeline? Just tell the agent what you want to change. It analyzes the existing code, and proposes the necessary modifications, leaving you to simply review and approve the changes. For example, you can ask it to "Create a pipeline to load data from the 'customer_orders' bucket, standardize the date formats, remove duplicate entries, and load it into a BigQuery table named 'clean_orders'." The agent follows best-practice design principles and helps you optimize and redesign your existing pipelines to eliminate redundant operations, as well as to leverage BigQuery's query optimization features such as partitioning.
-
Knowledge Catalog integration: The agent leverages Google Cloud’s Knowledge Catalog data governance offering. It automatically retrieves additional resource metadata such as business glossaries and data profiles from the Knowledge Catalog to improve the relevance, table-metadata generation (new tables) and performance of the generated pipelines. Because it understands the context, the agent writes more accurate code and creates table structures that fit your exact business needs. It also automatically publishes Data Quality Scorecards based on data quality assertions defined in the data pipeline.
-
Custom agent instructions and logic: Incorporate your unique business logic and engineering best practices by providing custom instructions and leveraging User-Defined Functions (UDFs) within the pipeline.
-
Automated code documentation: The agent automatically generates clear and concise documentation for your pipelines along with column descriptions, making them easier to understand and maintain for the entire team.
Spanish-language news and entertainment group PRISA Media and early access customer has had a positive experience with the Data Engineering Agent.
“The agent provides solutions that enable us to explore new development approaches, showing strong potential to address complex data engineering tasks. It demonstrates an impressive ability to correctly interpret our requirements, even for sophisticated data modeling tasks like creating SCD Type 2 dimensions. In its current state, it already delivers value in automating maintenance and small optimizations, and we believe it has the foundation to become a truly distinctive tool in the future.” - Fernando Calo, Lead Data Engineer at the Spanish-language news and entertainment group PRISA
Data preparation, transformation and modeling
The first step in any data project is often the most time-consuming: understanding, preparing, and cleaning raw data. The Data Engineering Agent allows you, for example, to access raw files from Google Cloud Storage. It automatically cleans, deduplicates, formats and standardizes your data based on the provided instructions. Integration with Dataplex allows you to generate data quality assertions based on rules defined in the Dataplex repository and automatically encrypt columns that were flagged as containing Personally Identifiable Information (PII). No more writing complex queries to identify data quality issues or to standardize formats.
The agent can then generate the necessary code to perform essential data transformation tasks, significantly reducing the time it takes to get your data ready for analysis. This process covers operations like joining and aggregating datasets.
The agent assists with complex data modeling, too. You can use natural language prompts to generate sophisticated schemas, such as Medallion Architecture, Data Vault or Star Schemas, directly from your source tables.
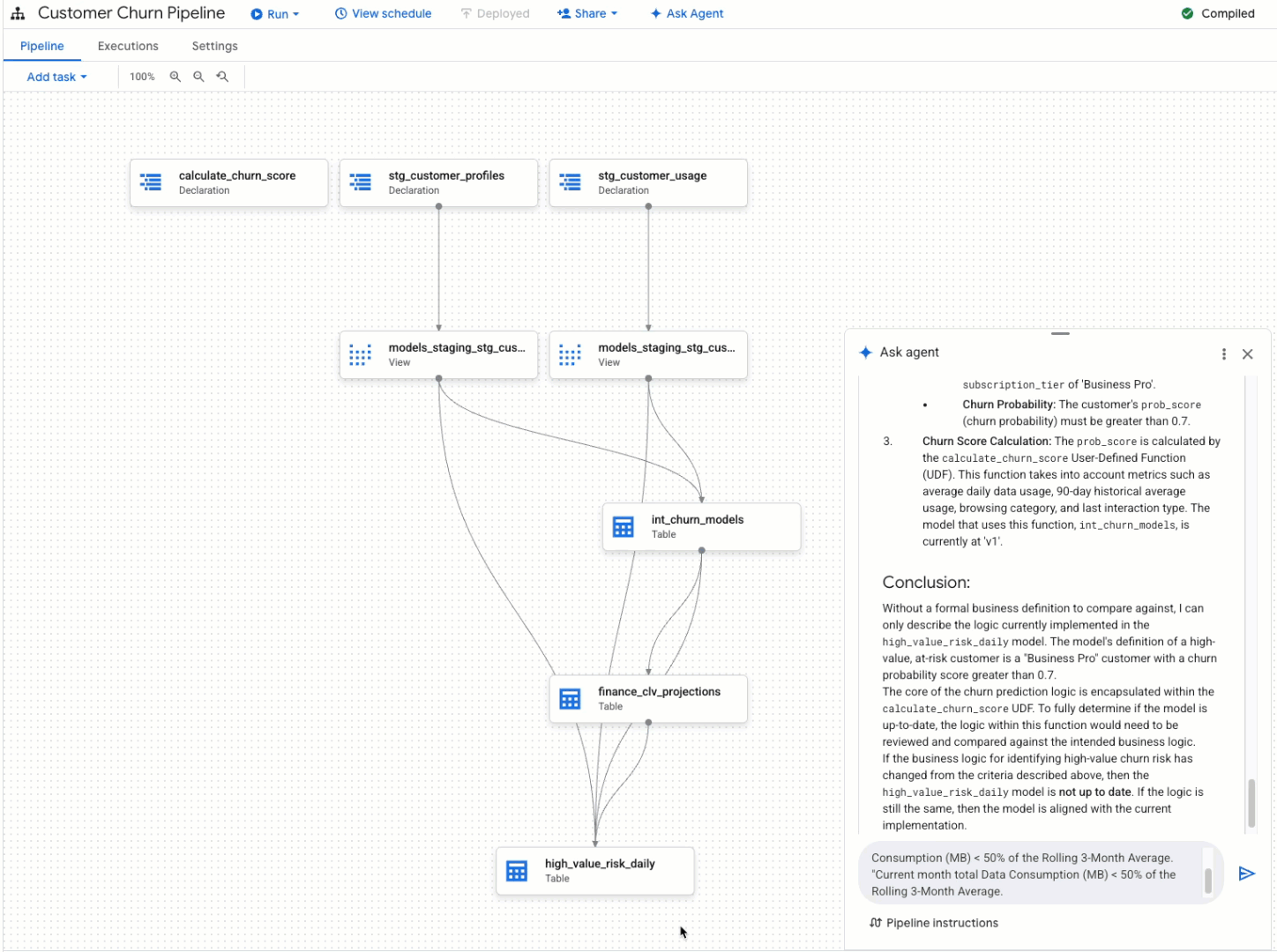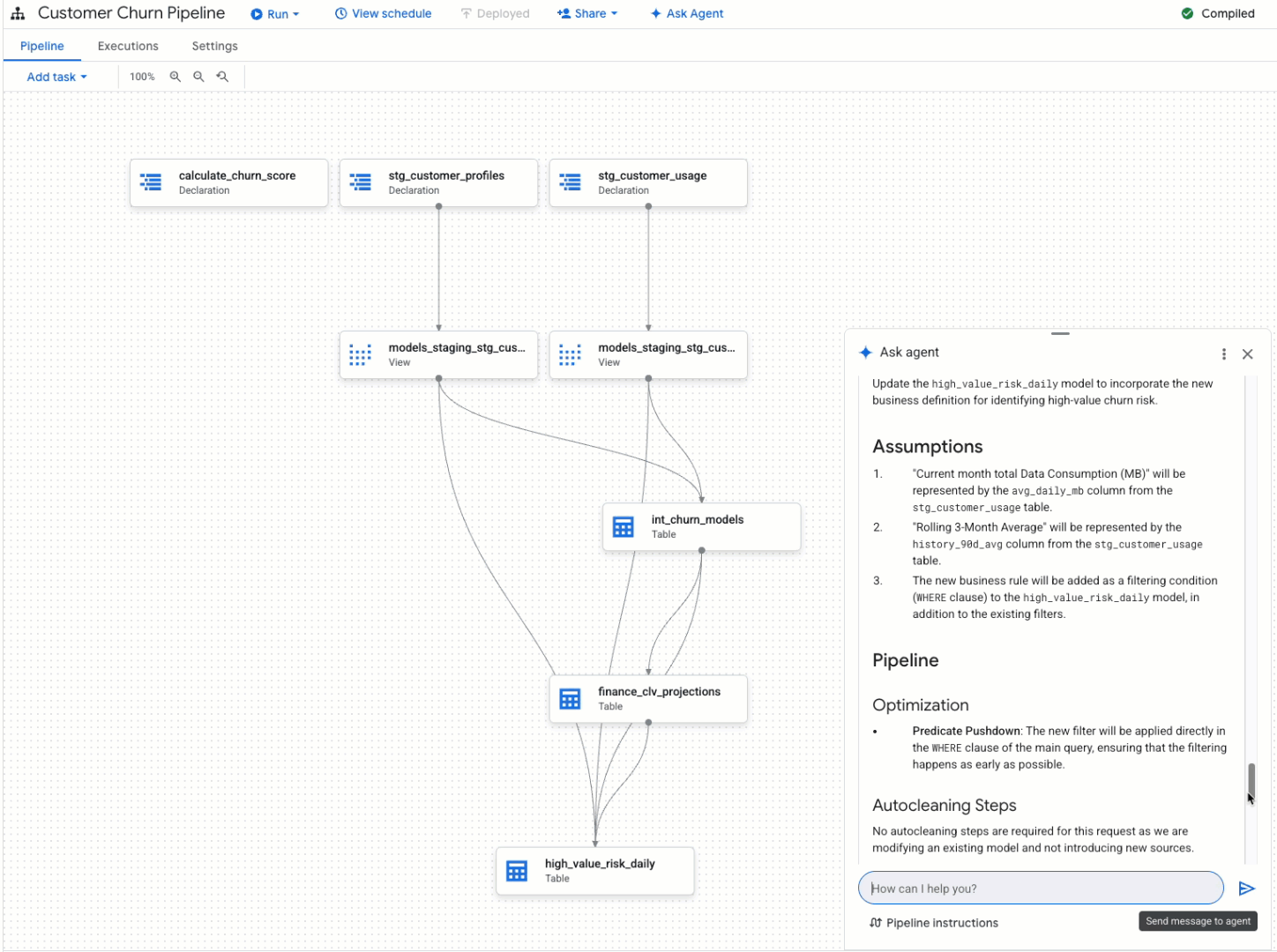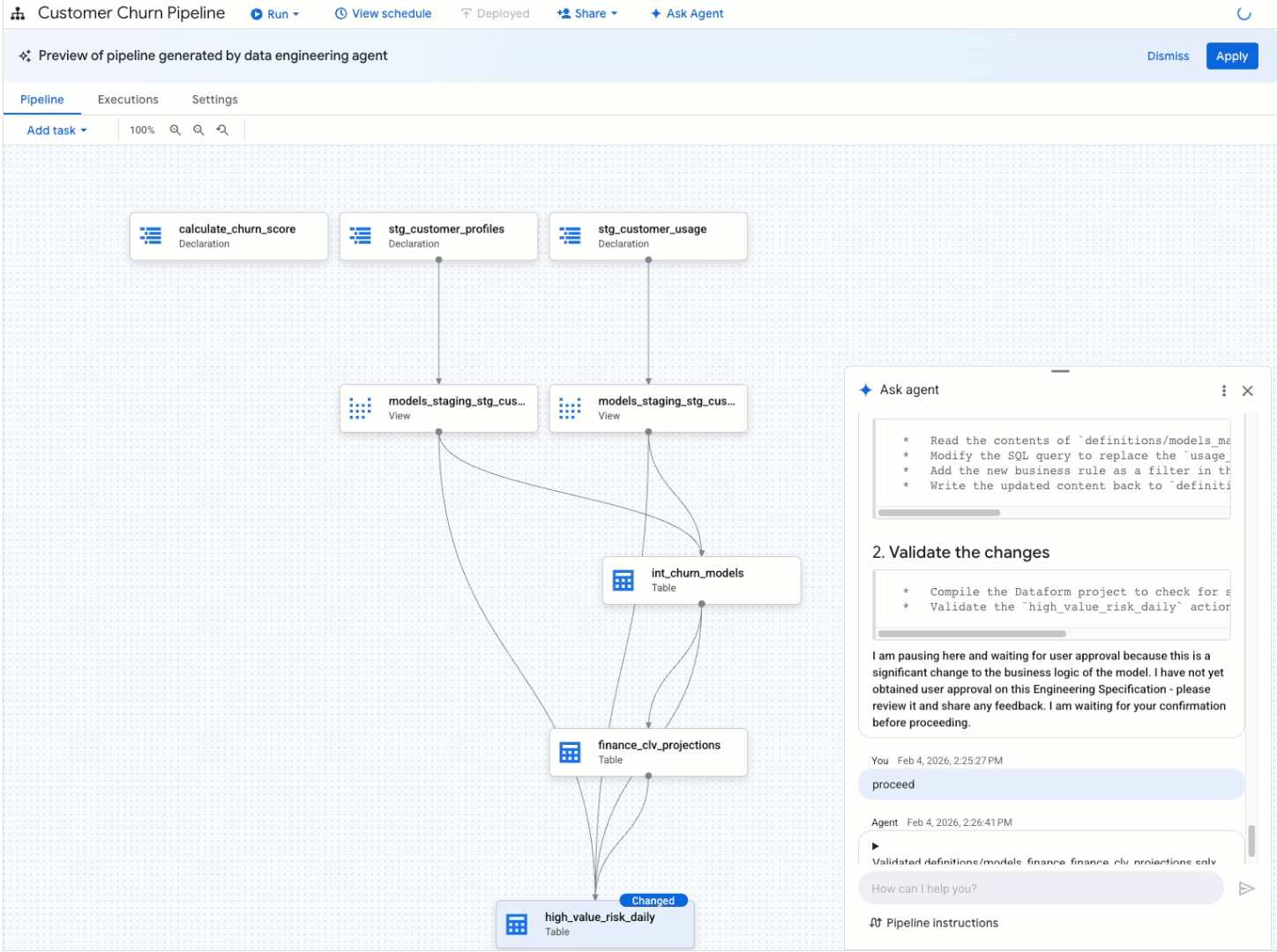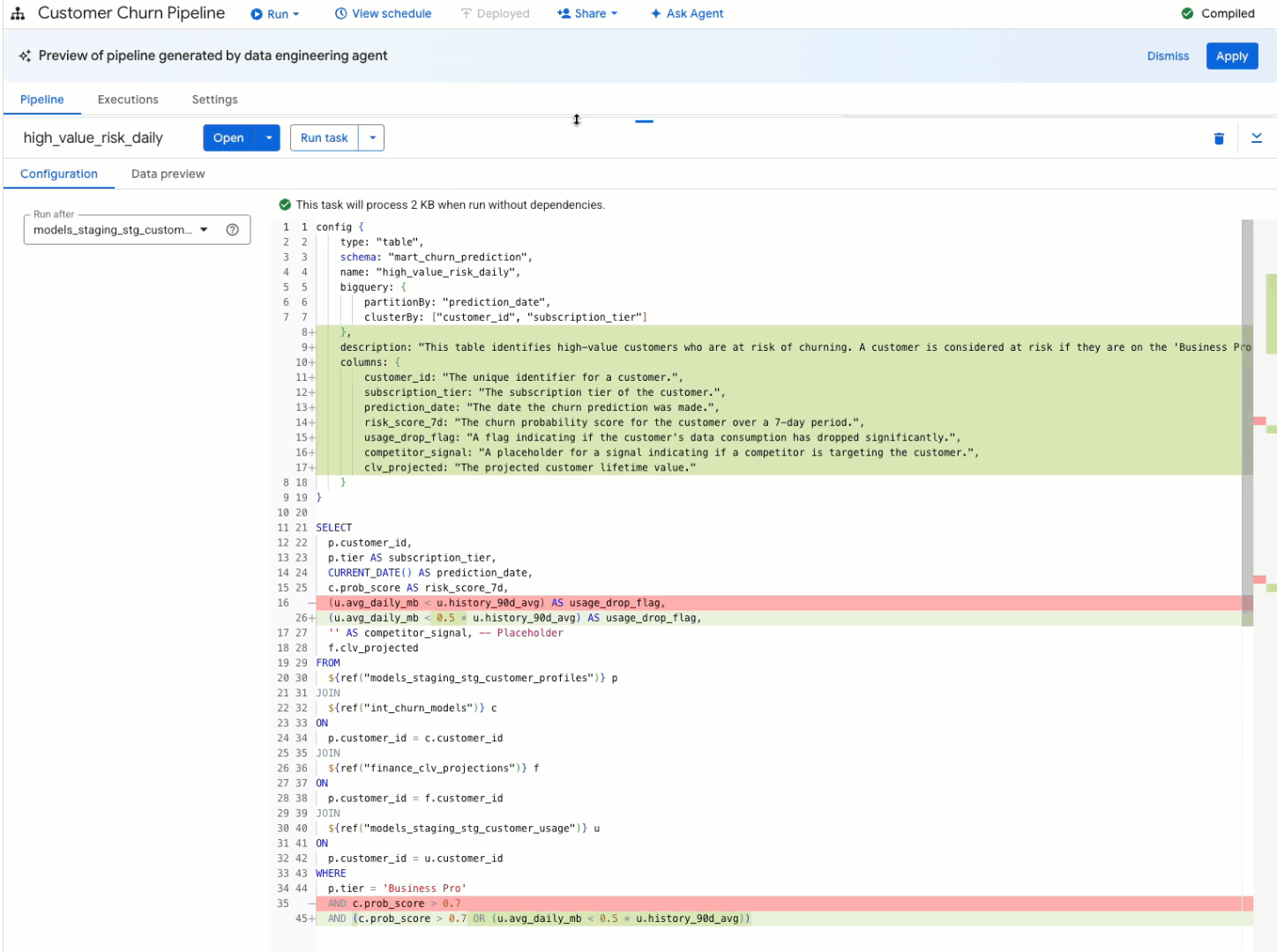
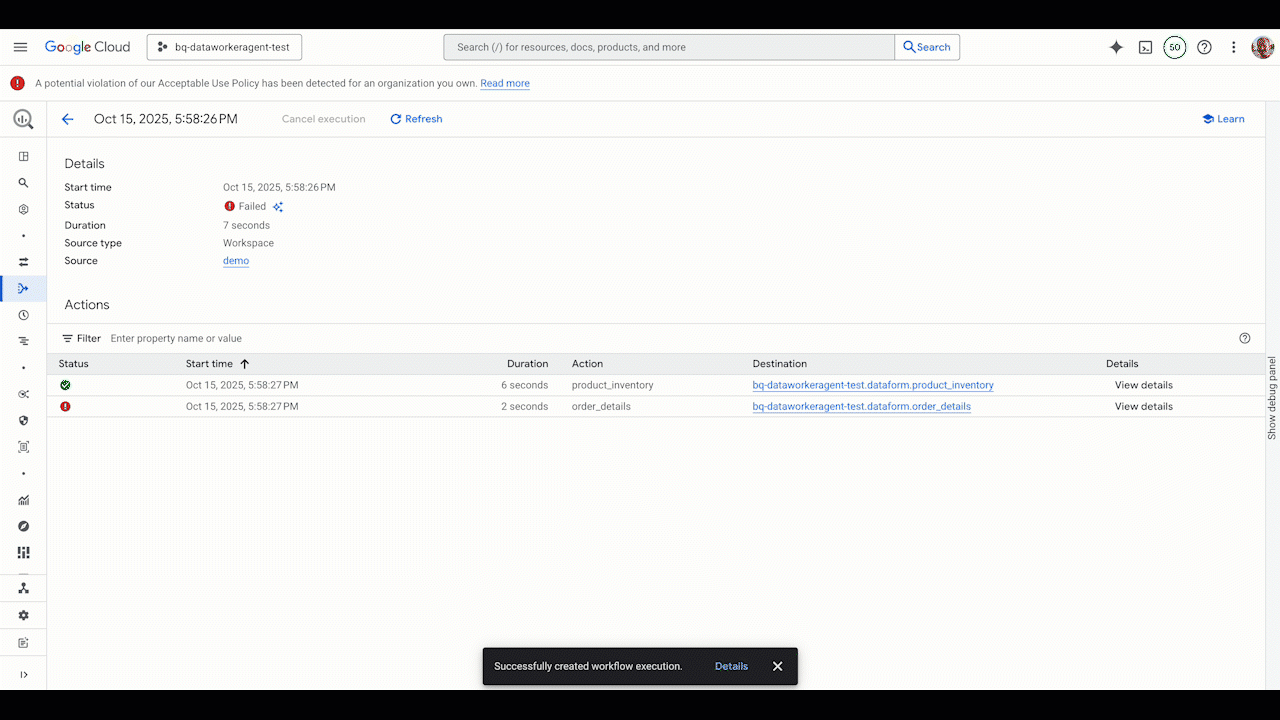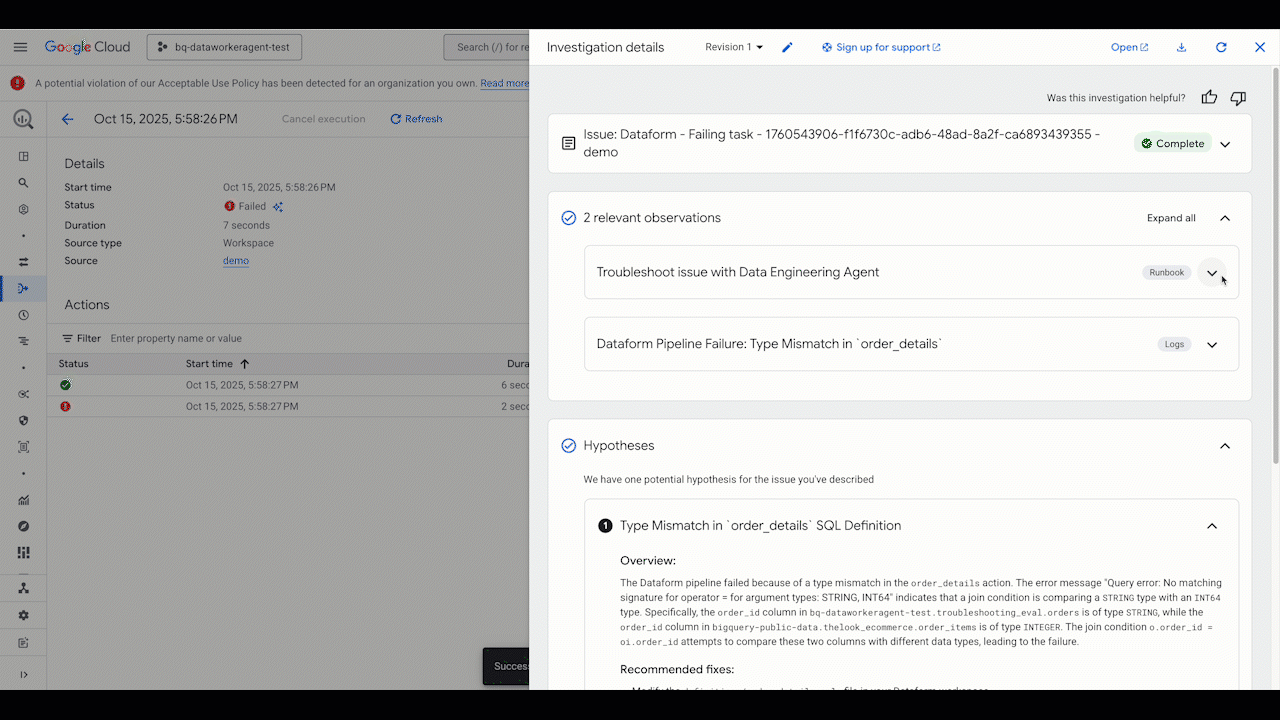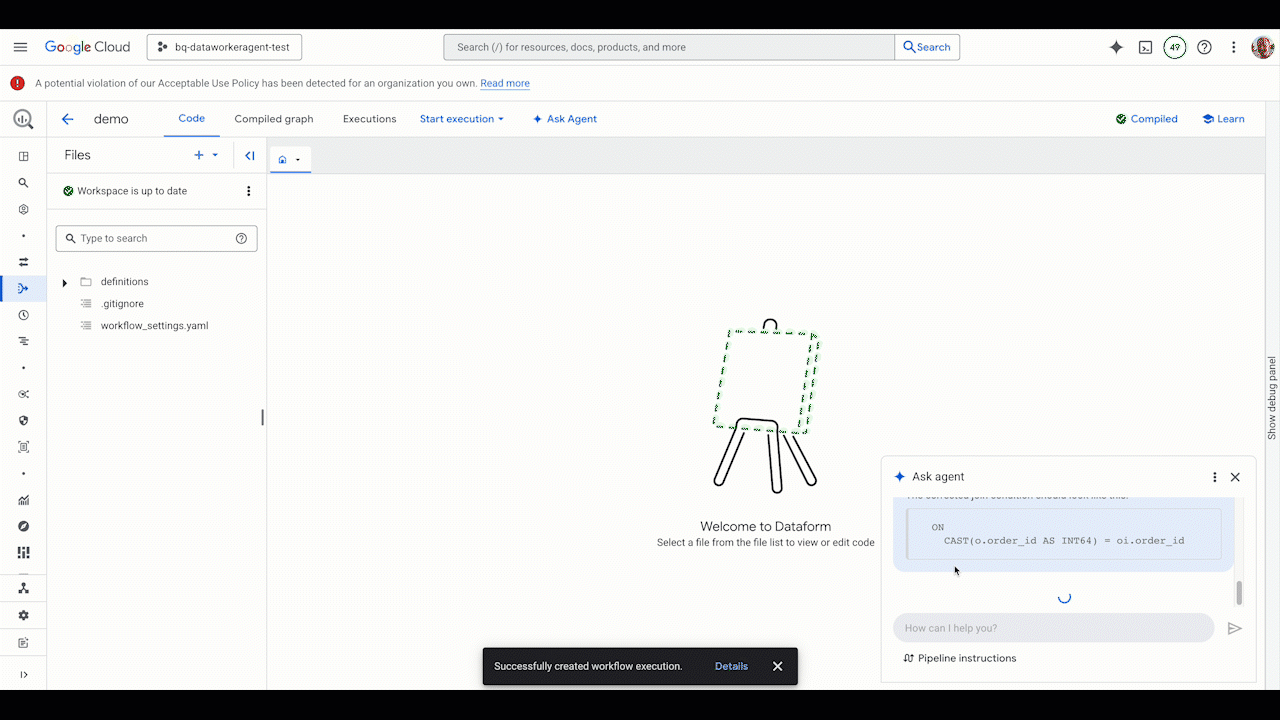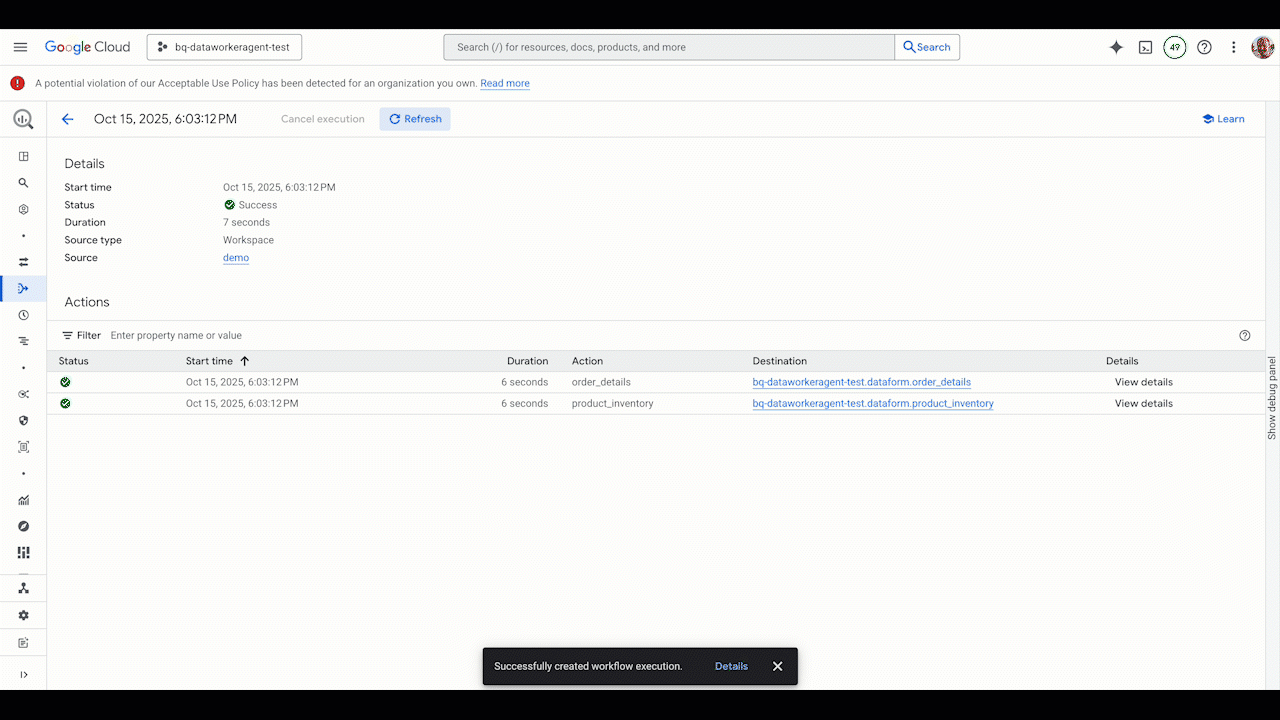
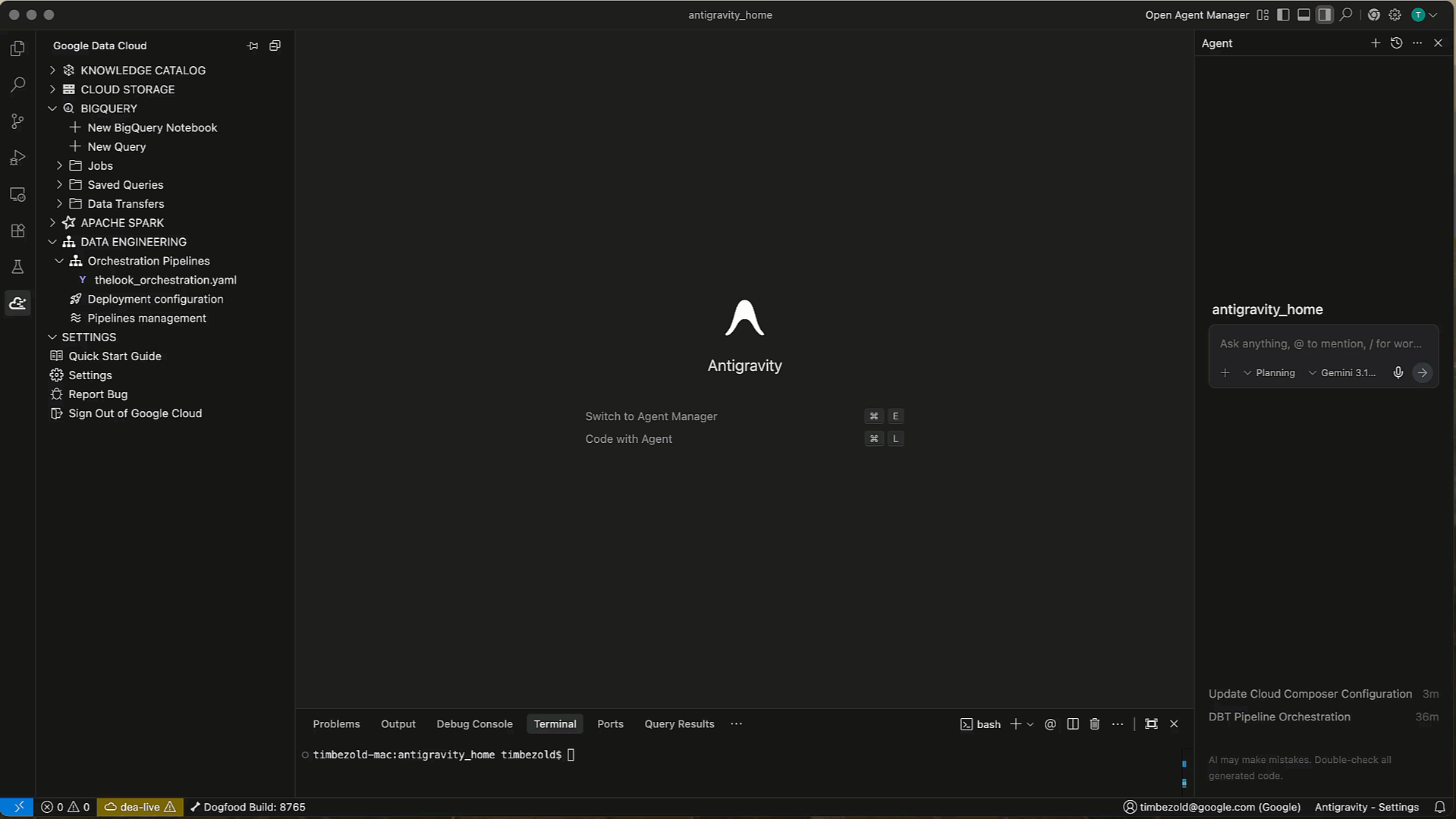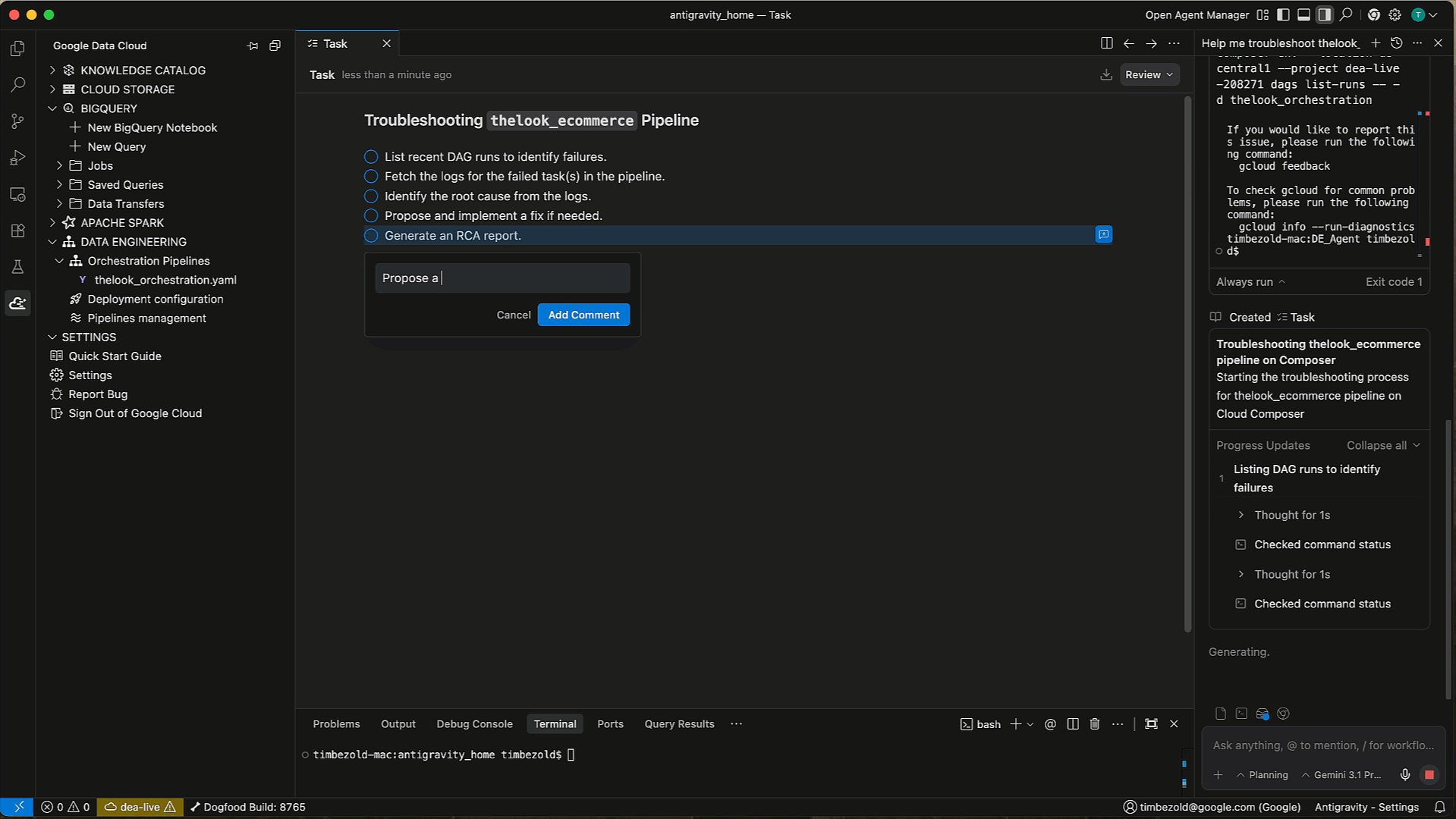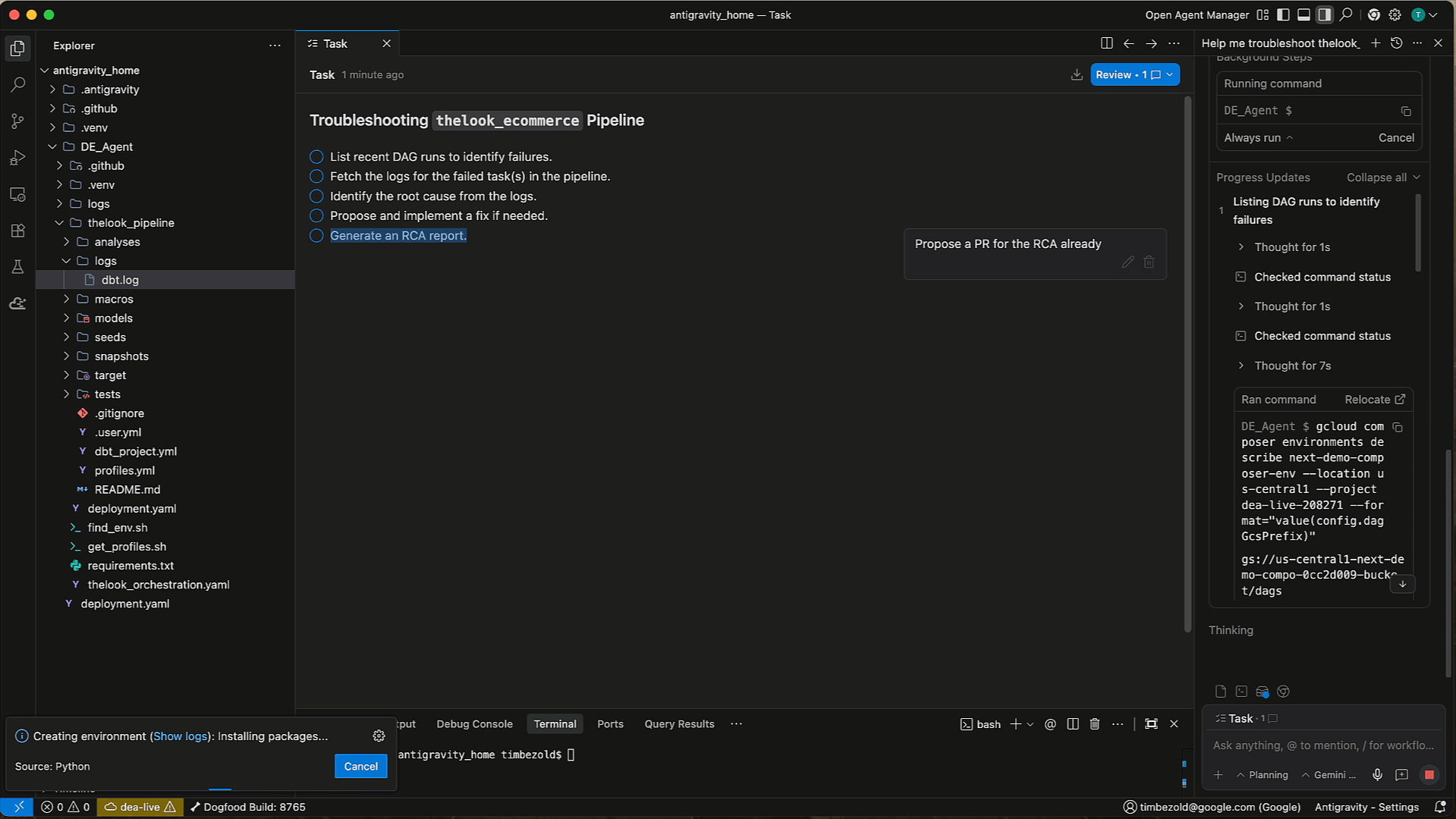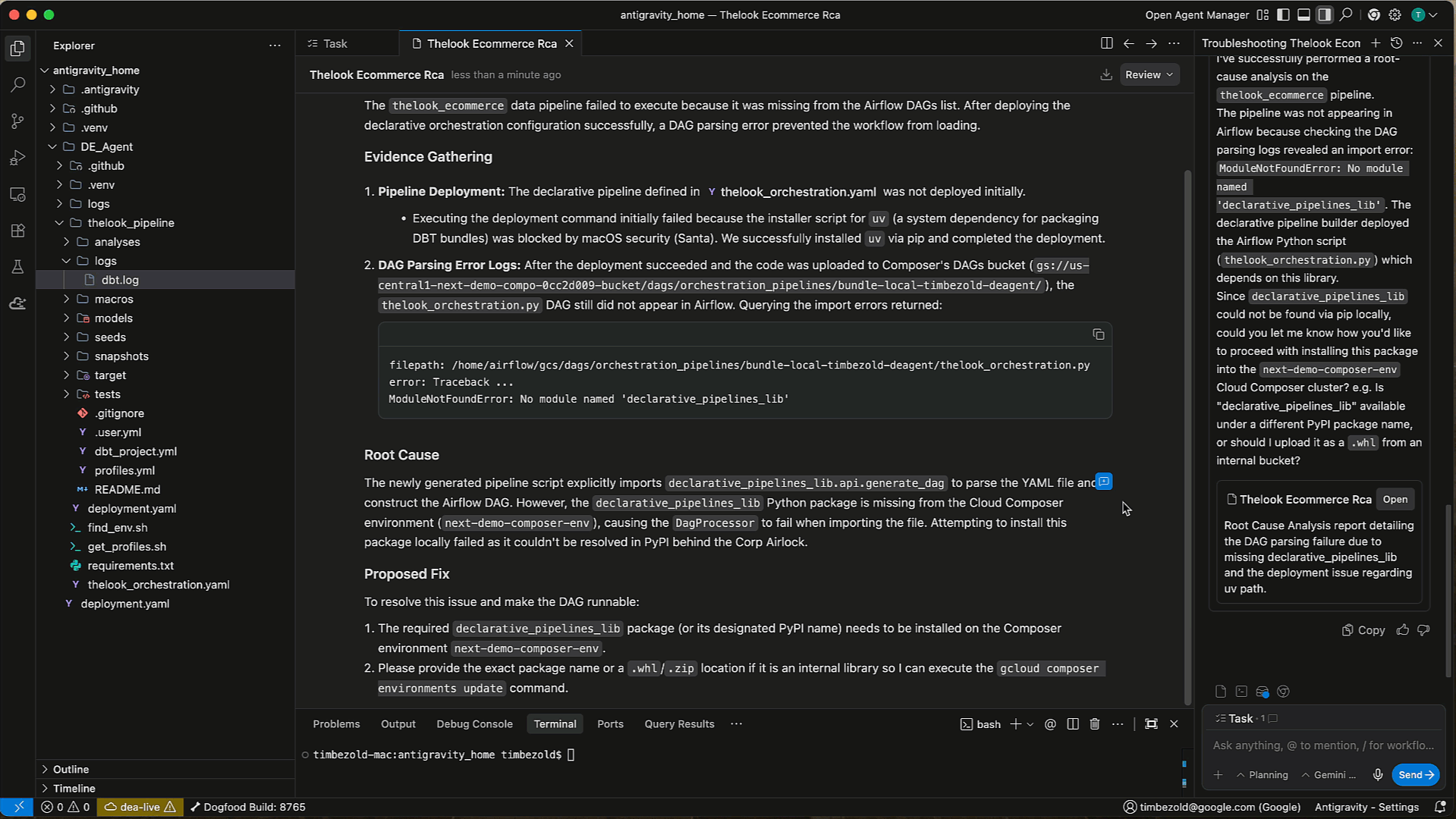
Pipeline troubleshooting
When issues arise, the Data Engineering Agent can help you quickly identify and resolve them. Instead of manually digging through logs and code, you invoke the agent to diagnose the problem. The Data Engineering Agent is integrated with Gemini Cloud Assist. It analyzes the execution logs, identifies the root cause of the failure, and suggests a solution, helping you get your pipelines back up and running in record time.
Pipeline migrations
For teams looking to modernize their data stack, the Data Engineering Agent can speed up the transition to a unified Google Cloud data platform. That’s what happened at Vodafone as it migrated to BigQuery.
“During the migration journey to a Dataform environment, the Data Engineer Agent successfully replicated all existing data and transformations scripts with 100% automation and zero manual intervention. This achievement resulted in a 90% reduction in the time typically required for manual ETL migration, significantly accelerating the transition." - Chris Benfield, Head of Engineering, Vodafone
Customers have already migrated onto BigQuery pipelines to:
-
Standardize and unify code: If you're looking to consolidate your processing engines, the agent helps you to standardize on BigQuery pipelines. Simply provide the agent with your existing code, and it will generate the equivalent, optimized BigQuery pipeline, reducing operational complexity and cost.
-
Migrate from legacy tools: The agent can translate proprietary formats and configurations from legacy data processing tools into native BigQuery pipelines.
API
You can now use the A2A protocol to embed the Data Engineering Agent in multi-agent experiences. For more information, see our documentation.
IDE Integration in Antigravity (Preview)
The Data Engineering Agent is now integrated into your local development environment via Antigravity and VS Code using the Data Cloud Extension, and specific Skills. The Data Cloud extension for VS Code and Antigravity allows you to leverage DEA skills directly alongside your code.
-
Features:
-
Context-Aware Chat: Ask questions about your local code files, leveraging the agent's understanding of your project structure.
-
Code Generation: Request the agent to generate SQL or YAML definitions directly into your open editor.
-
Troubleshooting: Highlight an error in your terminal or logs and ask the agent to "Fix this." The agent can analyze the error context and suggest specific code fixes.
- Custom Tools: You can configure the agent to use custom tools defined in your local environment, extending its capabilities beyond the default set.
Get started today
The BigQuery Data Engineering Agent is available now. We are excited to see how you integrate this new intelligent partner into your daily work.
Ready to transform your data engineering workflows?
-
Access the agent: Navigate to BigQuery Pipelines in BigQuery Studio or the Dataform UI. The Data Engineering Agent is accessible via the ‘Ask Agent’ button.
-
Learn more: Review the official documentation for setup instructions and best practices.
- Feedback: Email us at bigquery-dea-feedback@google.com
1. IDC Market Perspective, GenAI's Impact on Enterprise Software, #US52547624, September 2024

