Hive-BigQuery オープンソース コネクタの紹介
Google Cloud Japan Team
※この投稿は米国時間 2023 年 7 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
Google における Big Data ソリューション アーキテクチャ、BigQuery、Dataproc の各チームの取り組みにおいて、私たちはこれまでに多くのお客様と話をしてきました。その中で、データ ウェアハウスのすべてまたは一部を Apache Hive から BigQuery に移行することに関心を持っているものの、その過程で頓挫してしまっているケースをいくつか見てきました。このたび、この取り組みを支援する Hive-BigQuery コネクタの一般提供を開始したことをお知らせいたします。
このオープンソースのコネクタを使用することで、Apache Hive ワークロードで BigQuery テーブルと BigLake テーブルの読み取りと書き込みが行えるようになります。基盤となるデータは、BigQuery ネイティブ ストレージに保存するか、Cloud Storage にオープンソース データ形式で保存できます。Apache Hive から BigQuery に完全に移行する場合でも、両方のシステムを共存させて相互作用させる場合でも、この新しいコネクタを使用することで幅広いユースケースに対応できます。
Hive-BigQuery コネクタとは
Google Cloud で Hadoop や Spark のワークロードを実行した経験があれば、Cloud Storage コネクタや BigQuery 用の Apache Spark SQL コネクタについてはご存知かもしれません。前者は Hadoop 互換ファイル システム(HCFS)API を実装し、スケーラビリティと可用性に優れた Google Cloud のオブジェクト ストレージ サービスである Cloud Storage にデータ ファイルを保存してアクセスできるようにします。後者は Spark SQL データソース API を実装し、BigQuery テーブルを Spark の DataFrame に読み込んだり、DataFrame を BigQuery に書き戻したりできます。
同様に、Hive-BigQuery コネクタは Hive StorageHandler API を実装し、Hive ワークロードを BigQuery テーブルや BigLake テーブルと統合できるようにします。Hive の実行エンジンは、集約や結合などのすべてのコンピューティング オペレーションを引き続き処理し、Hive-BigQuery コネクタは、基盤となるデータが BigQuery ネイティブ ストレージに保存されているか、BigLake 接続を介して Cloud Storage バケットに保存されているかに関係なく、BigQuery のデータレイヤとのすべてのインタラクションを管理します。
次の図は、Hive-BigQuery コネクタがアーキテクチャにどのように適合するかを示しています。
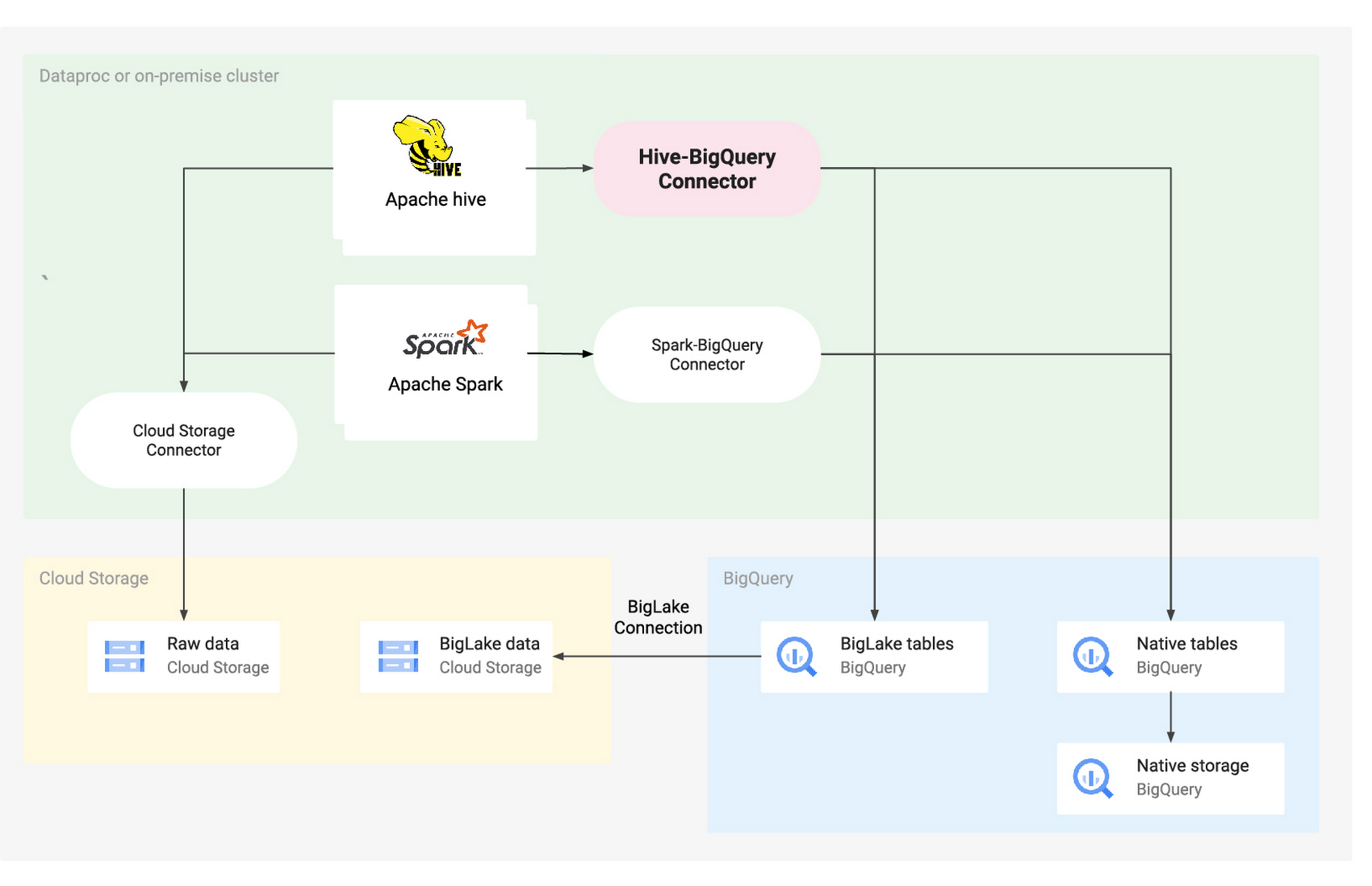
この一部を担う Apache Hive は、よく利用されているオープンソースのデータ ウェアハウスの一つです。SQL のようなインターフェースを提供し、これによって、Apache Hadoop と統合されたさまざまなデータベースやファイル システムに保存されているデータをクエリできます。時間の経過とともに、Hive は専用のデータ ストレージ レイヤとしてオンプレミスの HDFS を使用するものから、クラウド ストレージ サービスを使用するものへと進化してきました。そして今回、この新しいコネクタによって、Hive は BigQuery のようなネイティブ ストレージ ソリューションとのインテグレーションが可能になり、移行も簡素化されます。
データ ウェアハウスのクラウドへの移行は複雑なプロセスですが、次のような大きなメリットを得られます。
費用の削減: 支払いは使用したリソースの分のみ
スケーラビリティの向上: 進化するニーズに合わせて簡単にスケールアップやスケールダウンが可能
信頼性の向上: 冗長性のある高可用性システムを活用
セキュリティの強化: 転送中および保存中のデータを暗号化し、きめ細かいアクセス制御を実装
拡張機能: 以下のような Google Cloud ネイティブの膨大なツールやソリューションと直接的または間接的に統合可能
BigQuery のマテリアライズド ビューおよび BI Engine - パフォーマンスと効率の向上
Pub/Sub - 低レイテンシでのデータ転送
Dataflow - バッチモードまたはストリーミング モードでの大規模なデータ処理
Vertex AI - ML モデルの構築、デプロイ、スケーリング
その他多数
Google Cloud は、Hive データ ウェアハウスから BigQuery への移行を加速する包括的なソリューションとして BigQuery Migration Service を提供しています。このサービスには、評価と計画、データ転送、データ検証など、移行の各フェーズに役立つ無料ツールが用意されています。これらのツールのうち、BigQuery バッチ SQL トランスレータとインタラクティブ SQL トランスレータは、Hive クエリを BigQuery 独自の ANSI 準拠 SQL 構文に変換できるため、BigQuery 実行エンジンでネイティブにクエリを実行できます。
新しい Hive-BigQuery コネクタには、もう一つオプションがあります。これは、元のクエリを HiveQL 言語で保持したまま、クラスタ上の Hive 実行エンジンでそれらのクエリを引き続き実行しつつ、BigQuery テーブルや BigLake テーブルに移行されたデータにそれらのクエリがアクセスできるようにするものです。
Flipkart は、Hive-BigQuery コネクタを使用して自社のデータレイクを Google Cloud に移行しました。
「Flipkart は、オープンソース コミュニティを信頼し、またそれに貢献している企業として、オープンソース テクノロジーとの相互運用を非常に重視しています。Hive はデータレイク上の主要なクエリエンジンであり、Hive-BigQuery コネクタは、Hive から BigQuery データへのクエリを可能にするうえで重要な役割を果たしました。このインテグレーションにより、Flipkart は、さまざまなデータストアにまたがるデータの重複やサイロがなくなり、BigQuery のような高速クエリエンジンを利用できる柔軟性を得ることができました。」- Flipkart、プリンシパル アーキテクト兼 Apache コミッター Venkata Ramana Gollamudi 氏
ユースケース
Hive-BigQuery コネクタは、少なくとも次のような主要なユースケースに役立ちます。
全面的な移行時に運用の継続性を確保する: Hive データ ウェアハウス全体を BigQuery に移行することを決定し、最終的には既存の Hive クエリをすべて BigQuery の SQL 言語に変換するケースを想定してみます。この場合、データ ウェアハウスの規模が大きく、接続されているアプリケーションの数が多いため、移行にはかなりの時間がかかることが予想されます。また、移行期間中も業務をスムーズに継続する必要があります。このため、まずデータを BigQuery に移行し、その後、元の Hive クエリが Hive-BigQuery コネクタ経由でそのデータにアクセスできるようにしつつ、BigQuery 独自の ANSI 準拠 SQL 言語に徐々に変換していきます。移行が完了したら、BigQuery だけを使用するようにし、Hive を完全に廃止します。
データ ウェアハウスのすべてのニーズではなく、特定のニーズに対してのみ BigQuery を使用する: Hive-BigQuery コネクタでは、ほとんどのワークロードで Hive を使用し続け、BI Engine や BigQuery ML などの特定の BigQuery 機能が役立つと思われるワークロードにのみ BigQuery を使用することもできます。このユースケースの場合、Hive-BigQuery コネクタを使用して、Hive の独自のテーブルと BigQuery が管理するテーブルを結合することで、2 つの環境を統合できます。
完全なオープンソース ソフトウェア(OSS)スタックを維持する: 潜在的なベンダー ロックインを避け、データ ウェアハウスに完全な OSS スタックを使用し続けるケースを想定してみます。この場合、データは、元の OSS 形式(Avro、Parquet、ORC など)で Cloud Storage に移行し、引き続き Hive を使用して、Hive 独自の SQL 言語でクエリを実行および処理します。このユースケースでは、Hive-BigQuery コネクタを使用して OSS スタック基盤を強化できます。このためには、クエリのパフォーマンス向上のためのメタデータ キャッシュ保存、データ損失防止(DLP)、列レベルのアクセス制御、大規模なセキュリティとガバナンスのための動的データ マスキングといった、BigLake や BigQuery の機能を活用します。
機能
Hive-BigQuery コネクタのプレビュー版はすでに公開されており、次の機能が含まれています。
MapReduce および Tez 実行エンジンを使用したクエリの実行
Hive からの BigQuery テーブルの作成と削除
BigQuery テーブル / BigLake テーブルと Hive テーブルの結合
Storage Read API ストリームおよび Apache Arrow 形式を使用した BigQuery テーブルからの高速読み取り
BigQuery にデータを書き込む 2 つの方法:
BigQuery Storage Write API を保留モードで使用した直接書き込み。この方法は、更新間隔が短いニア リアルタイムのダッシュボードなど、低い書き込みレイテンシを必要とするワークロードに使用します。
一時的な Avro ファイルを Cloud Storage にステージングしてから、読み込みジョブ API を使用して、これらのファイルを宛先テーブルに読み込む間接書き込み。BigQuery の読み込みジョブは無料であるため、この方法は直接書き込みよりも安価です。ただし、処理速度が遅いため、時間を重視しないワークロードにのみ使用する必要があります。
BigQuery の時間パーティション分割テーブルおよびクラスタ化テーブルへのアクセス。Hive テーブルと、BigQuery でネイティブにパーティション分割されたテーブルおよびクラスタ化されたテーブルとの関係を定義する例を次に示します。
データレイヤから不要な列を取得しないようにする列のプルーニング
BigQuery ストレージ レイヤでデータ行を事前にフィルタするための述語プッシュダウン。これにより、ネットワークを通過するデータ量を大幅に削減できるため、クエリのパフォーマンスが全体的に向上します。
Hive データ型から BigQuery データ型への自動変換
BigQuery のビューおよびテーブル スナップショットの読み取り
使ってみる
ご利用にあたっては、Hive クラスタに Hive-BigQuery コネクタをインストールして構成する方法に関するドキュメントをご覧ください。
Google は継続的に新機能を追加し、改善を行っています。皆様からのフィードバックをお待ちしております。ご意見や機能リクエストがある場合は、Google Cloud の営業担当者までご連絡いただくか、GitHub でご報告ください。この新しいコネクタを革新的な方法で使用していただけることを楽しみにしています。
このコネクタの設計と開発にご協力いただいた David Rabinowitz、Yi Zhang、Dagang Wei、Vinay Londhe、Roderick Yao、Kartik Malik、Guruprasad S、Nikunj Bhartia、Gaurav Khandelwal、Vijay Dulipala、Savitha Sethuram、Palak Mishra、Akanksha Singh、Prathap Reddy に感謝します(順不同)。
- Google Cloud、ソリューション アーキテクト Julien Phalip
