Dataproc での Apache Ranger の使用に関するベスト プラクティス
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
Dataproc は、Apache Spark クラスタ、Apache Presto クラスタ、Apache Hadoop クラスタなどのマネージド オープンソースを簡単かつコスト効率よく実行できるようにする、使いやすいフルマネージド クラウド サービスです。Dataproc を使用すると、常時オンのオンプレミス OSS クラスタと同様の、実行時間の長いクラスタを構築できます。また、特定のジョブのみを処理する、規模の小さい、カスタマイズされたクラスタを複数構築することもできます。このようなクラスタは、ジョブが完了すると無効にできるので、コストの削減にもつながります。しかし、このような一時的なクラスタを使用した新しいアーキテクチャで、Hadoop サービスへのセキュアできめ細かいアクセスを管理するにはどうすればよいでしょうか。また、ユーザーによる操作を監査し、クラスタのライフサイクルに影響されずにログを保持するにはどのようにすればよいでしょうか。
このブログでは、Hadoop に認可機能を提供する OSS の Apache Ranger を Google Cloud 上で使用してエンドツーエンドのアーキテクチャとベスト プラクティスを提案することで、これらの疑問に答えます。
このアーキテクチャでは、複数の Dataproc クラスタが単一の Ranger バックエンド データベースを共有しますが、各クラスタには Ranger の管理およびプラグイン コンポーネントがそれぞれインストールされます。ポリシーは、Cloud SQL にホストされたデータベースに一元化され、すべてのクラスタ間で同期されます。
このアーキテクチャでは、クラスタごとに Ranger データベースをデプロイする必要がないため、ポリシーの同期に手間をかける必要がなく、コストも抑えられます。さらに、一元的な Ranger 管理インスタンスを用意し、常時稼働するようにメンテナンスを行う必要もありません。一元化されるコンポーネントは、Google Cloud のフルマネージド リレーショナル データベース Cloud SQL を基盤とする Ranger データベースのみです。
クラウドの特長
Dataproc を利用すると、わずか数分でクラスタを作成し、簡単に管理して、不要なときには無効にして費用を節約できます。特定のジョブやジョブのグループに合わせてカスタマイズしたクラスタを任意の数だけ作成し、それらのジョブの実行中のみ利用できます。
良いことばかりのようですが、このような環境で認証や認可はどのように管理すればよいでしょうか。Dataproc では、Google Cloud のその他のコンポーネントと同じく Cloud Identity and Access Management(Cloud IAM)機能を使用できますが、IAM 権限は Hadoop 環境のサービスで必要になるようなきめ細かなアクセス管理機能は備えていません。そこで、Ranger が必要になります。
オンプレミス環境で Ranger を使用することに慣れていれば、Dataproc でも難なく活用できます。Dataproc はオプション コンポーネントとして Ranger をサポートしているので、Dataproc のコンポーネント交換を使用して、各クラスタで引き続き Rangers を使用できます。
次の図には、Google Cloud 上に構築された 4 つの Dataproc クラスタが示されています。各クラスタには Ranger のインスタンスがホストされていて、Hive、Presto、HBase などのクラスタ サービスへのアクセスを制御しています。
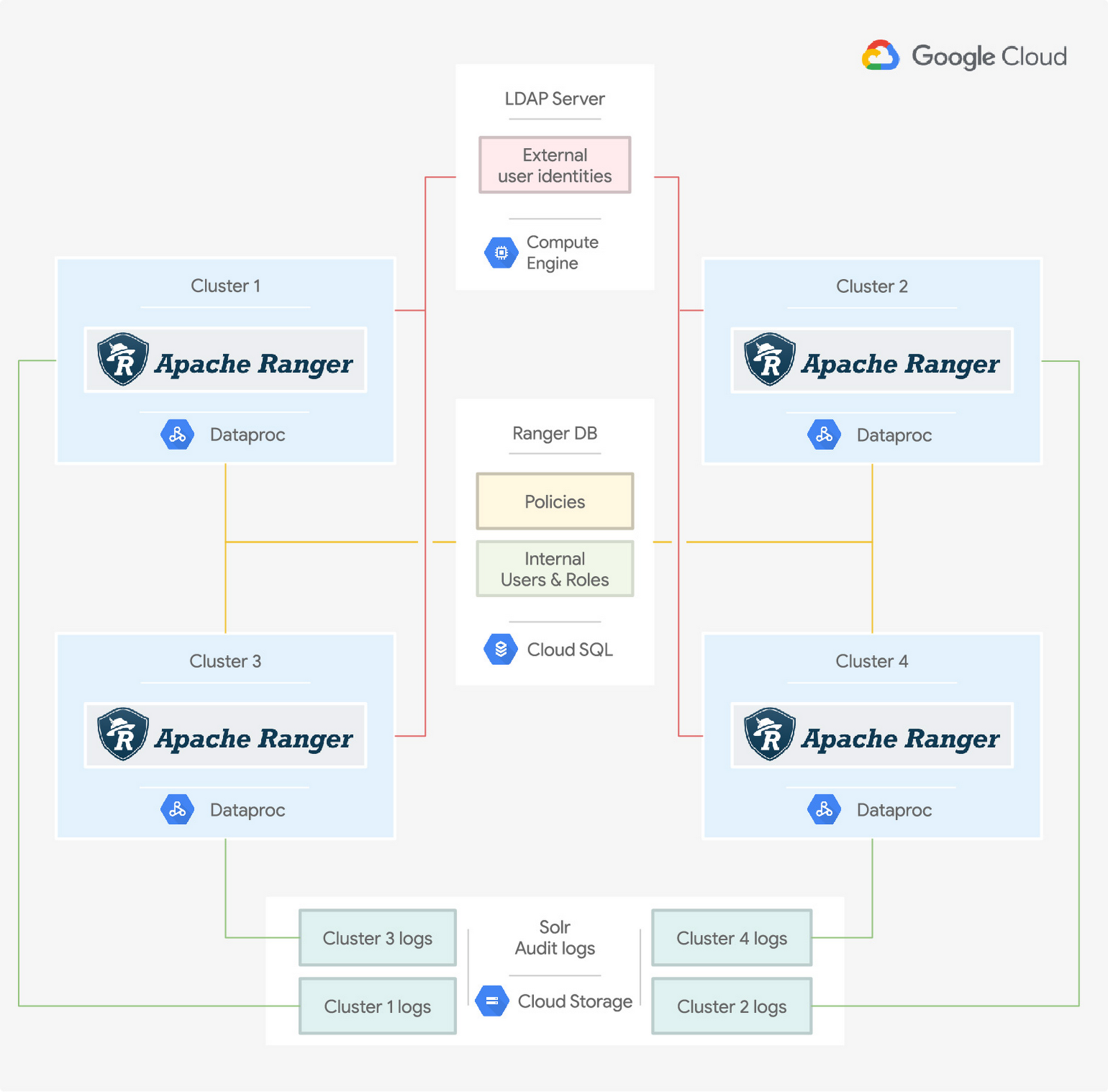
これらのサービスを使用するユーザーの ID は、クラスタ外部の ID プロバイダ サービスで定義されています。この図では、例として、Google Compute Engine 上で実行されている LDAP サーバー(Apache DS など)が示されていますが、オンプレミスや別のクラウド プロバイダにある独自の ID プロバイダ(Active Directory など)を使用することもできます。詳しくは、ハイブリッド環境で企業ユーザーを認証するをご覧ください。
Ranger に定義されたアクセス ポリシーもクラスタ外部にあります。この図では、アクセス ポリシーが Ranger の内部ユーザー ともに Cloud SQL インスタンスで一元管理されている様子が示されています。さらに、監査も Cloud Storage に外部化されています。各クラスタは、独自のバケットとフォルダにそれぞれのログを保存します。ポリシー、内部ユーザー、ログが Hadoop クラスタから分離されているので、必要に応じてクラスタの作成や無効化が可能です。
クラスタ内部の仕組み
では、このアーキテクチャを実現するコンポーネントのレベルまで掘り下げて、クラスタ内部の仕組みを見てみましょう。
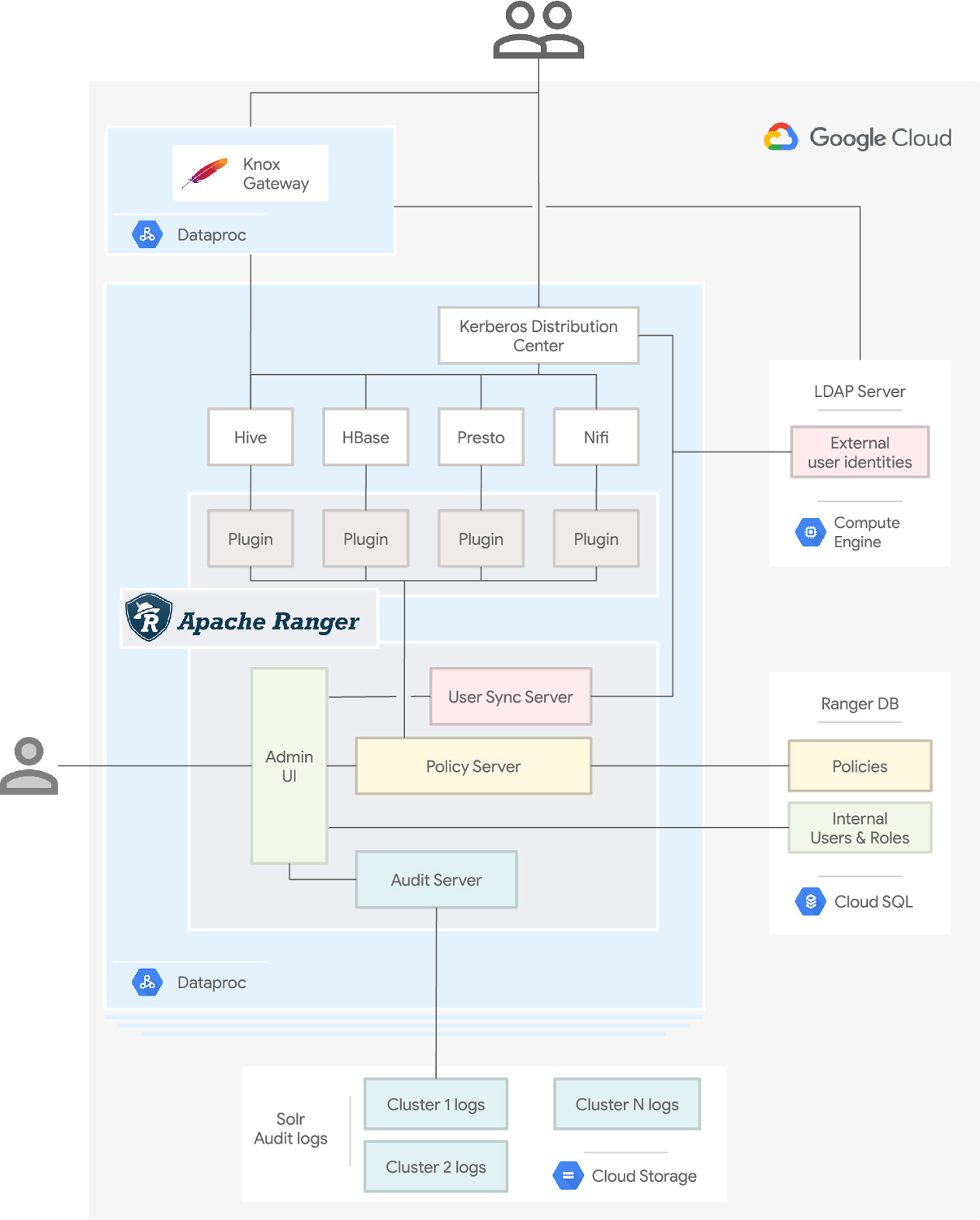
この図の上部に示されているシステム ユーザーは、データを処理して結果を取得するために、1 つ以上のクラスタ サービスにアクセスする必要があります。
このユーザーは、クラスタ上の Kerberos Key Distribution Center、またはこの記事で説明されている Apache Knox ゲートウェイを使用して認証を行います。Kerberos と Apache Knox はどちらも、外部 LDAP サーバーに定義されているユーザー ID を検証できます。Ranger のユーザー同期サーバーは、ユーザーにアクセス ポリシーを適用できるように、LDAP サーバーから定期的に ID を取得します。
Dataproc では、クラスタでの Kerberos 統合があらかじめサポートされています。このアーキテクチャのクラスタで Kerberos を使用する場合は、ユーザーとグループを Kerberos プリンシパルにマッピングするため、レルム間の信頼を設定して、LDAP サーバーを外部の信頼できるレルムとして指定する必要があります。
ユーザーが認証されると、リクエストは適切なサービスにルーティングされます。ただし、リクエストは、各サービスに対応する Ranger プラグインによってインターセプトされます。プラグインは、Ranger ポリシー サーバーから定期的にポリシーを取得します。これらのポリシーによって、特定のユーザー ID に対し、それぞれのサービスでリクエストされた操作が許可されるかが判断されます。許可される場合、プラグインはサービスによるリクエストの処理を許可し、ユーザーに結果が返されます。ポリシーはクラスタ外部の Cloud SQL データベースに格納されているので、クラスタのライフサイクルとは独立して保持されていることに注意してください。
ユーザーが Hadoop サービスに対して行う操作は、許可されたものも拒否されたものも含め、すべてが Ranger 監査サーバーによってクラスタログに記録されます。Cloud Storage には、各クラスタ固有のログフォルダがあります。Ranger は、Apache Solr を利用して、これらのログのインデックス作成や検索を行うことができます。削除済みのクラスタのログを調査する場合は、新しいクラスタを作成し、以前のクラスタログ フォルダを指すように dataproc:solr.gcs.path プロパティを設定するだけです。
そして最後になりますが、インストールされる Ranger の管理 UI を使用すると、クラスタ全体のさまざまなポリシー、ロール、ID、ログを視覚的かつ簡単に管理できます。管理 UI へは、Ranger データベースに格納された、サービスのユーザーとは別に用意されている Ranger の内部ユーザーがアクセスできます。
すべての Ranger コンポーネントは、Hadoop マスターノードで実行されます。各ジョブは、最終的には YARN によるオーケストレーションを通してワーカーノードで実行されますが、この図には示されておらず、特別な構成も必要ありません。
このアーキテクチャにおける一時的なクラスタの利用方法
Dataproc では、長時間実行するクラスタや一時的なクラスタを同時に複数実行できます。では、すべてのクラスタに Ranger をインストールする必要はあるでしょうか。答えは、「はい」でもあり「いいえ」でもあります。
すべてのクラスタに独自の Ranger 管理サービスとデータベースを用意する場合、新たにクラスタを追加するたびにユーザーとポリシーを再設定する必要があり、手間がかかります。一方、Ranger サービスを一元化すると、このサービスですべてのクラスタのユーザーの同期、ポリシーの同期、監査ログの記録を行う必要があり、スケーラビリティの問題が生じます。
ここで提案したアーキテクチャでは、一元的な Cloud SQL データベースを常に稼働させておき、クラスタはすべて一時的とします。データベースには、ポリシー、ユーザー、ロールを格納します。各クラスタは独自の Ranger コンポーネントを持ち、このデータベースと同期されます。ポリシーを同期する必要がなく、一元化されるコンポーネントは Google Cloud が管理する Cloud SQL のみであることが、このアーキテクチャの利点です。本投稿の最初の図にこのアーキテクチャを示していますのでご覧ください。
ユーザーの認証方法
Ranger には、2 種類のユーザーが存在します。
外部ユーザー: Hive などのデータ処理サービスにアクセスするユーザーです。ほとんどの場合、これらのユーザーには Ranger UI への明示的なアクセス権は不要です。各クラスタでは、Ranger によってユーザー同期デーモン サービスが実行されていて、LDAP から外部ユーザーとグループが取得され、Ranger データベースに保持されます。各 Dataproc クラスタ内のこれらのデーモンは、同じ LDAP サーバーから同じパラメータを使用してユーザーを取得している限り、安全に動作します。特定のユーザーの情報が異なるクラスタから複数回にわたって同期されて競合状態が発生する事態を避けるため、Ranger データベースにはユーザー ID やグループ ID に関して一意性制約が指定されています。
内部ユーザー: Ranger UI のユーザーです。内部ユーザーの認証の仕組みは、外部ユーザーと異なります。LDAP や AD をセットアップするか、手動でユーザーを作成して、UI に認証を定義します。各 UI は認証情報のクエリをどこに対して実行すればよいかの判断にクラスタ独自の構成を確認するため、各クラスタで明示的にユーザー認証の方法を設定する必要があります。UI から直接ユーザーを作成すると、そのユーザーの情報は共有データベースに保持されます。そのため、特に構成を行わなくても、すべてのクラスタの Ranger UI でそのユーザーを使用できます。
Ranger 管理ユーザーは、ポリシーの作成、内部ユーザーの追加、他のユーザーへの管理者ロールの割り当てなど、Ranger UI でのあらゆる操作の実行権限を持つ特別な内部ユーザーです。Dataproc の Ranger コンポーネントでは、起動時に Ranger 管理ユーザーのパスワードを設定し、一元管理された Ranger データベースに認証情報を格納できます。したがって、管理ユーザーとパスワードは、すべてのクラスタで同一になります。
クラスタ間で認可ポリシーを同期する方法
Ranger は、認可ポリシーをリレーショナル データベースに格納します。このアーキテクチャでは、すべてのクラスタでポリシーを利用できるように、共有の Cloud SQL Ranger データベースを使用しています。管理ユーザーは、このデータベースを共有する任意の Ranger UI にログインして、これらのポリシーを変更できます。
ユーザー操作の監査方法
Ranger の監査ログは、Apache Solr を使用して Cloud Storage バケットに保存されるので、クラスタが削除された後でも保持されます。
削除されたクラスタのログを確認する必要がある場合は、クラスタを作成し、同じ Cloud Storage フォルダを指すように Solr を設定します。その後、そのクラスタの Ranger UI でログを参照できます。ログを取得するために作成するクラスタは、単一ノードクラスタのように小さく、また一時的なものでかまいません。
クラスタごとに異なる Cloud Storage バケットが必要にならないように、すべてのクラスタで同じバケットを使用しますが、各クラスタのログは異なるフォルダに格納します。各クラスタには、ログを管理する独自の Solr コンポーネントがあるため、異なるクラスタが同じフォルダに監査ログを書き込むことはできません。
Ranger の監査ログ以外に、Google Cloud には Cloud Audit Logs も用意されています。これらのログは Ranger のログほど詳細なものではありませんが、Google Cloud リソースで「誰がいつどこでどのような操作を行ったか」を把握するのに役立ちます。たとえば、Dataproc Jobs API を使用する場合、Cloud Audit Logging を通して、どの Cloud IAM ユーザーがジョブを送信したかを確認できます。あるいは、Dataproc のサービス アカウントによる Cloud Storage バケットへの読み書きを追跡することもできます。
ユースケースに適したアクセス制御の使用
最後に、Ranger が必要かどうかをもう一度検討することをおすすめします。Ranger を使用する場合は、クラスタ作成時に細かい設定が必要になるほか、ポリシーの管理も必要になります。
Ranger を使用する代わりに、多数の一時的な Dataproc クラスタを作成し、それぞれに異なるアクセス権を持つ個別のサービス アカウントを割り当てることもできます。企業の規模によっては、ユーザーごとにサービス アカウントとクラスタを作成する方法では高い費用対効果を見込めないこともあります。多くのユースケースでは、チームごとに共有クラスタを作成するだけで十分な分離を実現できます。
クラスタで個人(人間)のユーザーによる対話的なジョブのみを実行する場合は、Dataproc 個人用クラスタ認証を使用することもできます。
サービス、テーブル、列のレベルでのきめ細かな認可や監査が必要ない場合は、Ranger の代わりにこれらの方法を使用して、サービス アカウントまたはユーザー アカウントが特定のクラスタやデータセットにのみアクセスできるよう制限できます。
Dataproc で Ranger を使ってみる
このブログ投稿では、長時間実行する Dataproc クラスタや一時的な Dataproc クラスタを複数構築するための、Ranger を使用したアーキテクチャを提案しました。中核となったのは、Ranger データベース、認証プロバイダ、監査ログストレージを共有して、Ranger 管理サービス、Ranger UI、Ranger ユーザー同期、Solr などのその他のすべてのコンポーネントは個別のクラスタで実行するというアイデアです。ポリシー、ユーザー、ユーザーのロールは、データベースからすべてのクラスタに提供されます。Ranger コンポーネントはステートレスなので、一元化された Ranger サービスを実行する必要はありません。監査ログは Solr によって Cloud Storage に保存されるので、クラスタが削除された後でも参照して分析できます。
Dataproc の Ranger コンポーネントは簡単にインストールできます。このコンポーネントを利用して、Dataproc で Ranger を使ってみましょう。共有の Ranger データベースとなる Cloud SQL と組み合わせて使用しましょう。さらに一歩進んで、可視化ソフトウェアを Google Cloud 上の Hadoop に接続してみましょう。
-戦略的クラウド エンジニア Yunus Durmuş
-ソリューション アーキテクト David Cueva Tello




{kind=link}
{kind=link}