Best practices to use Apache Ranger on Dataproc
Yunus Durmuş
Strategic Cloud Engineer
David Cueva Tello
Cloud Solutions Architect
Dataproc is an easy-to-use, fully managed cloud service for running managed open source, such as Apache Spark, Presto, and Apache Hadoop clusters, in a simpler, more cost-efficient way. Dataproc allows you to have long-running clusters similar to always-on on-premises OSS clusters. But even better, it allows multiple smaller, customized, job-focused clusters that can be turned off when a job is done to help manage costs. However, using these ephemeral clusters opens a few questions: How do you manage secure and fine-grained access to Hadoop services in this new architecture? How can you audit user actions and make sure the logs persist beyond any cluster lifecycle?
In this blog, we propose an end-to-end architecture and best practices to answer these questions using Apache Ranger, an authorization OSS for Hadoop, on Google Cloud.
In this architecture, several Dataproc clusters share a single Ranger back-end database while each cluster has its own Ranger admin and plugin components. The database, hosted on Cloud SQL, centralizes the policies so that policies are synchronized among all the clusters.
With this architecture, you don’t have to deploy one Ranger database per cluster and consequently, deal with policy synchronization and incur higher costs. Moreover, you don’t need a central Ranger admin instance, which requires maintenance to be always up. Instead, the only centralized component is your Ranger database, backed by Cloud SQL, Google Cloud’s fully managed relational database service.
How is the cloud different?
With Dataproc you create clusters in a few minutes, manage them easily, and save money by turning clusters off when you don't need them. You can create as many clusters as you need, tailor them for a job or a group of jobs, and have them around only while those jobs are running.
That sounds great, but how is authentication and authorization managed in such an environment? Dataproc shares the Cloud Identity and Access Management (Cloud IAM) functionalities with the rest of Google Cloud; however, IAM permissions are high-level and not specifically aimed to control very fine-grained access to the services in a Hadoop environment. That is where Ranger excels.
If you are used to Ranger on your on-prem environments, you will feel at home on Dataproc. Dataproc supports Ranger as an optional component, so you continue to have Ranger installed on each cluster using Dataproc’s component exchange.
In this diagram, you can see four Dataproc clusters on Google Cloud. Each cluster hosts an instance of Ranger to control access to cluster services such as Hive, Presto, HBase, and others
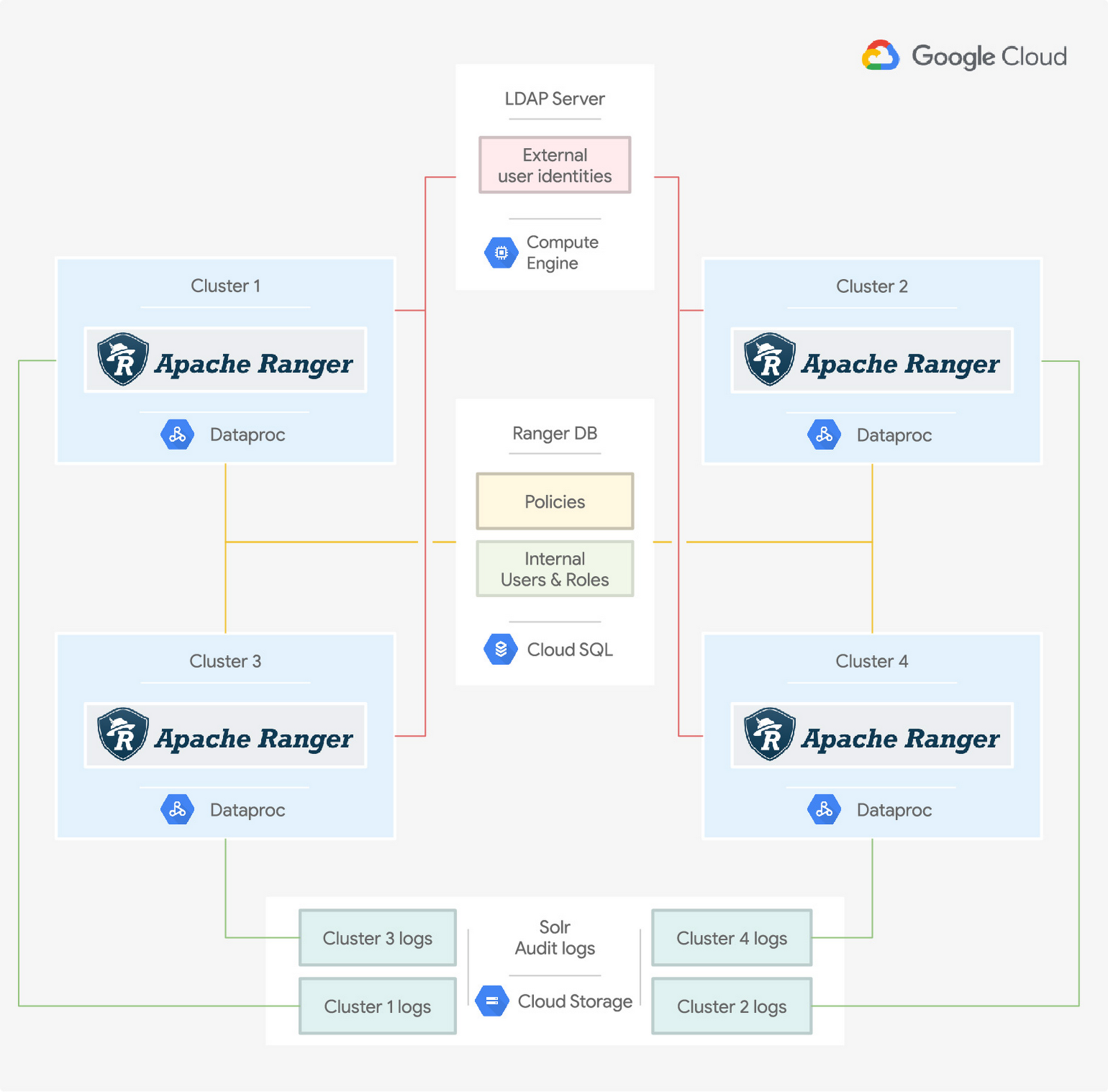
Users of these services have their identities defined in an identity provider service that is external to the clusters. As an example, the diagram shows an LDAP server such as Apache DS running on Google Compute Engine. However, you can also use your own identity provider like Active Directory on-prem or on a different cloud provider. See Authenticating corporate users in a hybrid environment.
The access policies defined in Ranger are also external to the clusters. The diagram shows them stored in a centralized Cloud SQL instance, along with the Ranger internal users. Finally, auditing is externalized to Cloud Storage, with each cluster storing its logs in its own bucket and folder. Having the policies, internal users, and logs separated from the Hadoop clusters allows you to create and turn off clusters as needed.
What is behind the scenes in a cluster?
Let's go under the hood of a cluster and drill down to the components that make this architecture possible:
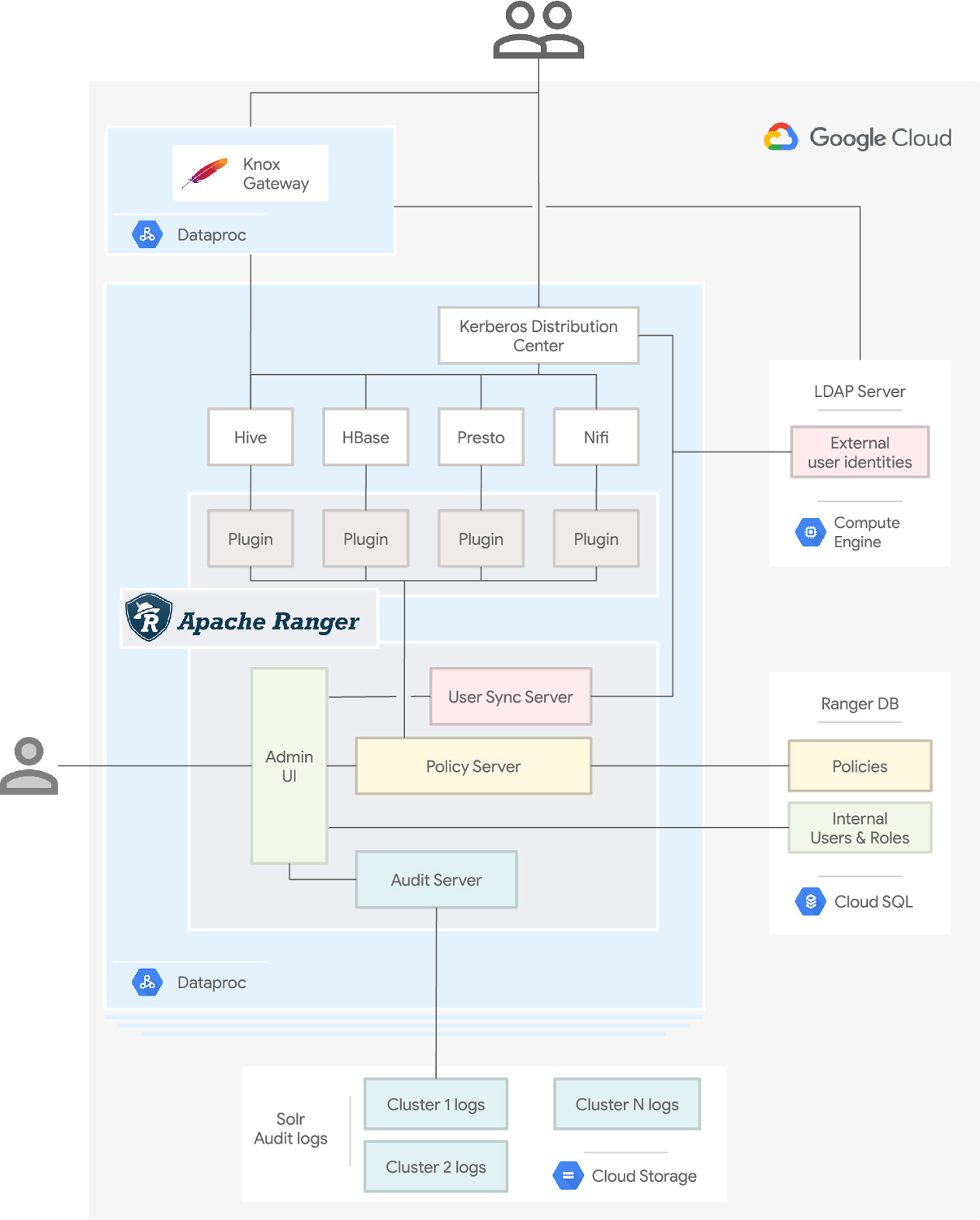
Users of the system, shown on top of the diagram, want to access one or more of the cluster services to process some data and get results back.
They authenticate using an on-cluster Kerberos Distribution Center, or alternatively using an Apache Knox Gateway as described in this article. Both Kerberos and Apache Knox can verify the user identities defined in an external LDAP server. The Ranger User Sync Server periodically retrieves the identities from the LDAP server so that it can apply access policies to the users.
Dataproc supports Kerberos integration on the cluster out of the box. If you use Kerberos in your cluster with this architecture, you need to use an LDAP server as an external cross-realm trust to map users and groups into Kerberos principals.
Once a user is authenticated, their request is routed to the appropriate service. However, it is intercepted by the corresponding Ranger plugin for the service. The plugin periodically retrieves the policies from the Ranger Policy Server. These policies determine if the user identity is allowed to perform the requested action on the specific service. If it is, then the plugin allows the service to process the request and the user gets back the results. Note that the policies are external to the cluster and stored in a Cloud SQL database so that they persist independently of the cluster lifecycle.
Every user interaction with a Hadoop service, both allowed or denied, is written to cluster logs by the Ranger Audit Server. Each cluster has its own logs folder in Cloud Storage. Ranger can index and search these logs leveraging Apache Solr. Examining the logs of a previously deleted cluster is as easy as creating a new cluster and pointing the dataproc:solr.gcs.path property to the old cluster logs folder.
Last but not least, the Admin UI of Ranger is installed to allow an easy way to visualize and manage the different policies, roles, identities, and logs across clusters. Access to the Admin UI is given to a separate group of users, internal to Ranger, and stored in the Ranger database.
All the Ranger components run on the Hadoop master node. Workers that ultimately run jobs orchestrated through YARN are not pictured in the diagram, and do not need any particular configuration.
How does the architecture work with ephemeral clusters?
Dataproc allows you to run multiple long-running and/or ephemeral clusters simultaneously. Should you install Ranger in every cluster? The answer is yes and no.
If every cluster had its own Ranger admin and database, it would be cumbersome to re-populate the users and policies every time you have a new cluster. On the other hand, a central Ranger service brings up scalability issues, since it has to deal with the user sync, policy sync, and the audit logs for all the clusters.
The proposed architecture keeps a central Cloud SQL database always up while all the clusters can be ephemeral. The database stores policies, users, and roles. Every cluster has its own Ranger components synchronized with this database. The advantage of this architecture is that you avoid policy synchronization and the only centralized component is Cloud SQL, which is managed by Google Cloud. See the first figure above that shows the architecture.
How do you authenticate users?
For Ranger, there are two user types:
External users: These are users that access data processing services such as Hive. In most cases, they do not need explicit access to the Ranger UI. Ranger runs a user synchronization daemon service in every cluster to fetch these users and groups from LDAP, then persists them in the Ranger database. This daemon can run safely in each Dataproc cluster as long as they all fetch users from the same LDAP server with the same parameters. To avoid race conditions, where a particular user is synchronized twice by different clusters, the Ranger database has a uniqueness constraint on user/group IDs.
Internal users: These are the users of the Ranger UI. Authentication is different from external users. You define authentication to the UI via an LDAP/AD setup or by manually creating the users. This method must be set up in every cluster explicitly because every UI checks its own configuration to learn where to query for authentication. When you create a user via UI directly, Ranger persists that user into the shared database. Hence, it is available in the Ranger UIs on all clusters without any additional configuration.
A Ranger admin user is a special internal user who has the authority to perform any action on the Ranger UI, such as creating policies, adding internal users, and assigning the admin role to others. The Dataproc Ranger component allows you to set the Ranger admin user password during startup and stores the credentials in the central Ranger database. Therefore, the admin user and password are the same across all the clusters.
How do you synchronize authorization policies across clusters?
Ranger stores authorization policies in a relational database. The architecture uses a shared Cloud SQL Ranger database so that policies are available to all clusters. Admin users can alter these policies by logging into any Ranger UI that shares the same database.
How do you audit user actions?
Apache Solr handles the Ranger audit logs and stores them in a Cloud Storage bucket for durability even after cluster deletion.
When you need to read the logs of a deleted cluster, you create a cluster and point Solr to the same Cloud Storage folder. You will then be able to browse the logs in the Ranger UI of that cluster. The cluster that you create for log retrieval can be small, such as a single node cluster, and ephemeral.
To avoid having different Cloud Storage buckets per cluster, use the same bucket for all as long as each cluster logs to a different folder. Clusters cannot write their audit logs to the same folder since each cluster has its own Solr component managing these logs.
In addition to Ranger audit logs, Google Cloud provides Cloud Audit Logs. These logs are not as granular as the Ranger logs, but are an excellent tool that allows you to answer the questions of "who did what, where, and when?" on your Google Cloud resources. For example, if you use the Dataproc Jobs API, you could find out which Cloud IAM user submitted a job through Cloud Audit Logging. Or you can track the Dataproc Service Account reads and writes on a Cloud Storage Bucket.
Use the right access control for your use case
Before we finish, we’d ask you to consider whether you need Ranger. Ranger adds minutes to cluster creation and you have to manage its policies.
As an alternative, you can create many ephemeral Dataproc clusters and assign them individual service accounts with different access rights. Depending on your company size, creating a service account and cluster per person may not be cost-effective, but creating shared clusters per team would offer enough degree of separation for many use cases.
You can also use Dataproc Personal Cluster Authentication if a cluster is only intended for interactive jobs run by an individual (human) user.
Use these alternatives instead of Ranger when you don't need fine-grained authorization and audit at the service, table, or column level. You can limit a service account or user account to access only a specific cluster and data set.
Get started with Ranger on Dataproc
In this blog post, we propose a Ranger architecture to serve multiple long-running and/or ephemeral Dataproc clusters. The core idea is sharing the Ranger database, authentication provider, and audit log storage and running all other components such as Ranger Admin, Ranger UI, Ranger User Sync, and Solr in individual clusters. The database serves the policies, users, and their roles for all the clusters. You don’t need to run a central Ranger service because Ranger components are stateless. Solr stores the audit logs on Cloud Storage to keep them for further analysis even after the deletion of a cluster.
Try Ranger on Dataproc with the Dataproc Ranger Component for easy installation. Combine it with Cloud SQL as the shared Ranger database. Go one step further and connect your Visualization Software to Hadoop on Google Cloud.

