Accelerating data lakes: Optimizing Apache Iceberg and Spark with gcs-analytics-core
Ajay Yadav
Software Engineer
Nivedita Aggarwal
Engineering Manager
Many data engineers spend significant time managing compatibility and getting best performance across multiple analytics engines. To help solve this pain point, we are excited to announce gcs-analytics-core, a new open-source Java library designed to centralize and accelerate analytics optimizations for Google Cloud Storage (GCS).
With this, you get the flexibility to select your preferred analytics engine while achieving high performance on GCS. The gcs-analytics-core library provides optimizations across various analytics engines that you use today on GCS, like the Iceberg Spark engine and plan to expand to other analytics engines by the end of this year.
Built to be shared across major data processing frameworks like Apache Spark, this library consolidates and improves performance for analytics workloads on GCS. Available natively in the Apache Iceberg Java runtime starting from version 1.11.0, this library improves read operations for columnar formats like Parquet.
What is the gcs-analytics-core library?
The gcs-analytics-core library is a centralized optimization layer that sits between your analytics engines — such as Apache Spark, Trino, and Apache Hive — and the underlying GCS Java SDK. It intercepts read calls and injects performance enhancements, providing a consistent experience without requiring framework-specific tuning.
For Apache Iceberg users, it integrates into the GCSFileIO implementation, replacing traditional sequential reads with parallelized strategies to minimize latency and maximize throughput.
Key technical optimizations
The library introduces specific optimizations designed to reduce time spent on I/O and end-to-end execution time:
-
Vectored I/O (threaded): This feature improves read performance by fetching multiple data ranges in parallel within a single operation, reducing the overhead of GCS calls. Without this feature, the system needs to issue a separate call for each data range, increasing both the number of operations and open file latency for each request.
-
Smart Parquet prefetching: When reading Parquet data, analytics engines typically perform an initial read of the file’s footer, which contains the data structure and information about where specific data ranges are located. The library automatically prefetches this footer data in a single chunk (typically 50KB–100KB), avoiding the multiple network calls that often occur when engines repeatedly seek backward to fetch metadata..
Spotlight: Apache Iceberg integration
We delivered the first major integration of this library into Apache Iceberg. With Iceberg 1.11.0 or later, analytics engines utilizing Iceberg’s GCSFileIO can leverage these performance enhancements. To adopt the library in your environment, verify your Iceberg catalog is configured to use the native GCS FileIO:
Because the core optimizations are embedded within the updated Iceberg runtime and the GCS connector architecture, you automatically benefit from Parquet footer prefetching and multi-threaded vectored reads — with no complex custom tuning required.
You can follow the specific integration details in Apache Iceberg Issue #14326.
Catalog compatibility
The gcs-analytics-core library is compatible with all Iceberg catalogs including the REST catalog, Hive, and other metadata management systems. By decoupling the performance optimizations from the catalog management layer, the library provides consistent read improvements without requiring adjustments to your existing infrastructure setup so you can scale across diverse data lake architectures.
TPC-DS Performance Benchmarks using Spark
To validate these improvements, end-to-end benchmarking was performed using an open source Apache Spark cluster with an Iceberg catalog configured to use GCSFileIO along with the gcs-analytics-core library.
The benchmark leveraged the industry-standard TPC-DS schema across varying dataset sizes (from 1GB up to 10TB), specifically comparing the new library's optimizations against the default GCSFileIO implementation, which uses sequential vectored reads.
By alleviating the I/O bottleneck at the storage layer, compute engines spend less time waiting for network responses (scan time) and more time processing data (execution time).
Here are the end-to-end TPC-DS benchmark results showcasing the percentage improvement when enabling gcs-analytics-core:
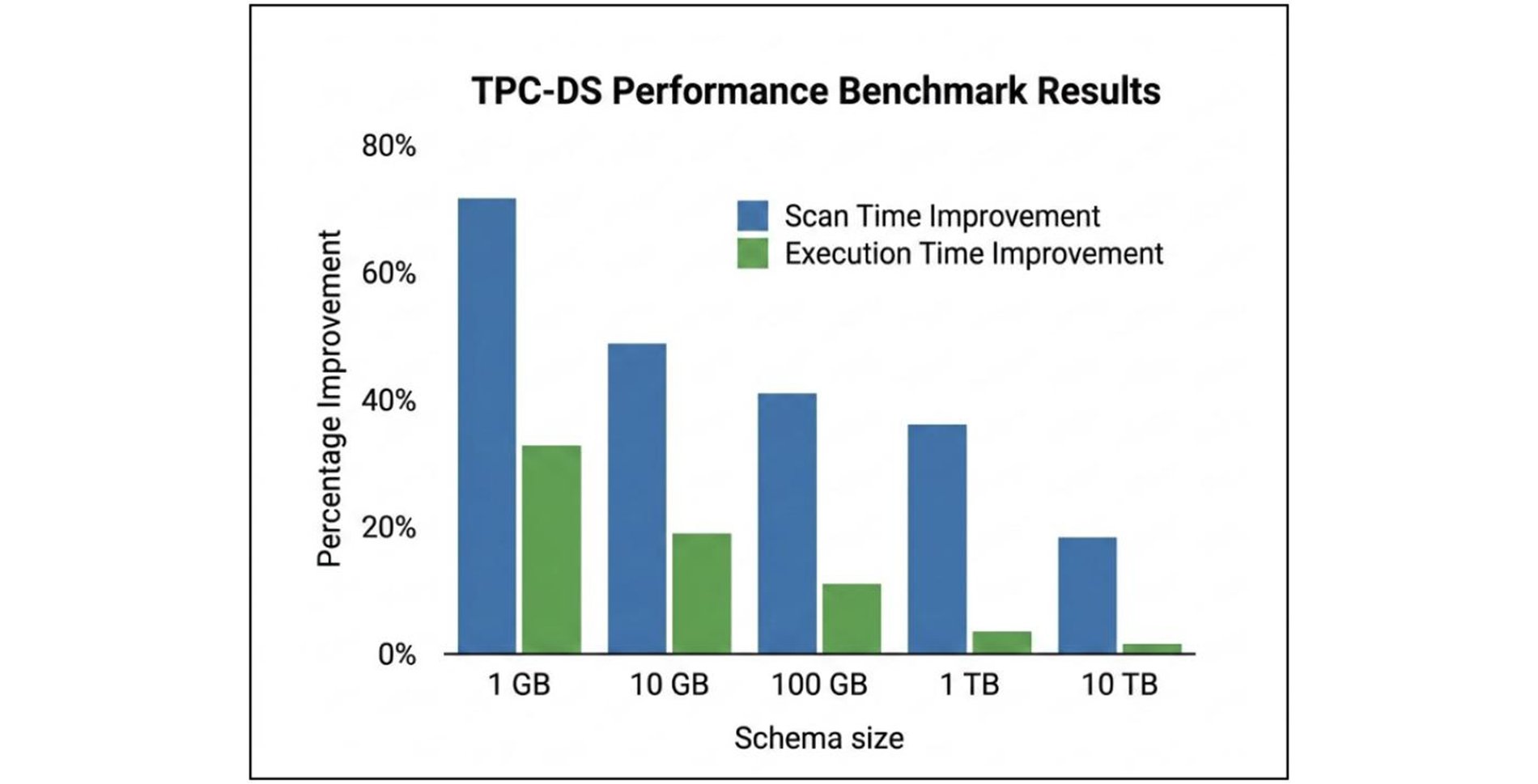
As the data shows, there is a consistent improvement across all dataset sizes. The library is effective for the complex query patterns in TPC-DS, delivering scan time reductions that directly lower overall query execution time.
Get started
Before running your Spark workloads, confirm that the following requirements and configurations are met:
-
Use Apache Iceberg Spark runtime 1.11.0+ and the iceberg-gcp-bundle 1.11.0+.
-
Configure your catalog to use GCSFileIO.
-
Enable the gcs-analytics-core optimization flag (
spark.sql.catalog.$CATALOG_NAME.gcs.analytics-core.enabled=true). -
Enable vectorized I/O (
spark.sql.iceberg.vectorization.enabled=true) to achieve read performance.
The gcs-analytics-core library is open source and available for developers to contribute to the project and explore the source code. Our implementation and micro-benchmark configurations are part of the repository and can be referenced for your contributions or validations.
-
GitHub repository: GoogleCloudPlatform/gcs-analytics-core
-
Documentation: Review the design document for deep architectural details.
We want to hear about your experience. If you test this on your own datasets, please feel free to open an issue on GitHub or share your results with the community. We look forward to seeing how you utilize these optimizations in your data lakes.

