Cloud Data Fusion によるコードフリーのアプローチで Salesforce のデータを BigQuery に読み込む方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
最新のクラウド ウェアハウスとデータレイク ソリューションへの投資を拡大して、分析環境を強化し、ビジネス上の意思決定を改善しようとする組織が増えています。顧客関係データが読み込まれ、さらなる分析情報が生成されることで、このようなリポジトリのビジネス価値は高まります。
この投稿では、Google サービスのスケーラビリティと信頼性、事前に構築されたコネクタをベースにした直感的なドラッグ&ドロップ ソリューション、コードフリーのデータ統合サービスのセルフサービス モデルを使用して Salesforce のデータを段階的に BigQuery に移行するためのさまざまな方法をご紹介します。
一般的なデータ取り込みパターン
もう少し詳しくコンテキストを説明するために、具体的(かつ一般的)なユースケースを次に示します。
コールセンターのエージェントが SalesForce アプリケーションを使用する際、エージェントはアカウント、リード、連絡先といった Salesforce オブジェクトを頻繁に操作します。
これらのオブジェクトの変更を識別し、バッチまたはストリーミングのいずれかの方法でデータ ウェアハウス ソリューションに段階的に読み込む必要があります。
コードフリーのデータ パイプラインを素早く構築、管理するためには、クラウドネイティブのフルマネージド エンタープライズ データ統合サービスが適しています。
ビジネス パフォーマンス ダッシュボードは、Salesforce とデータ ウェアハウス内の使用可能な他の関連データを結合して作成されます。
Cloud Data Fusion で可能になった対策
上述の ETL(抽出、変換、読み込み)シナリオに対処するために、データ統合ツールとして Cloud Data Fusion を使用する方法をご紹介します。
Data Fusion は、コードフリーのデータ パイプラインを素早く構築、管理できる、クラウドネイティブのフルマネージド エンタープライズ データ統合サービスです。Data Fusion ウェブ UI を使用すると、基盤となるインフラストラクチャを管理することなく、データのクリーニング、準備、ブレンド、転送、変換を行うスケーラブルなデータ統合ソリューションを構築できます。Data Fusion を Google Cloud と統合することで、データをすぐに分析できるようになります。
Data Fusion には、バッチ処理とリアルタイム処理の両方に対応する数多くのビルド済みプラグインがあります。これらのカスタマイズ可能なモジュールは、Data Fusion のネイティブ機能を拡張するために使用でき、Data Fusion Hub のコンポーネントを介して簡単にインストールできます。
Salesforce のソース オブジェクト向けに、次のビルド済みプラグインが一般提供されています。
Batch Single Source - Salesforce から 1 つの sObject を読み取ります。データは SOQL クエリ(Salesforce Object Query Language クエリ)や sObject 名を使用して読み取ることができます。増分 / 範囲の日付フィルタを渡したり、主キーのチャンク パラメータを指定したりすることもできます。sObject の例としては、機会、連絡先、アカウント、リード、任意のカスタム オブジェクトなどがあります。
Batch Multi Source - Salesforce から複数の sObject を読み取ります。マルチシンクと組み合わせて使用することが推奨されます。
Streaming Source - Salesforce の sObject の更新を追跡します。sObject の例としては、機会、連絡先、アカウント、リード、任意のカスタム オブジェクトなどがあります。
これらのビルド済みプラグインがニーズに合わない場合は、Cloud Data Fusion のプラグイン API を使用して独自のプラグインを作成できます。
このブログでは、すぐに使える Data Fusion プラグインを使用して、バッチとストリーミングの両方の Salesforce パイプラインのオプションをご紹介します。
バッチ増分パイプライン
バッチ増分ロジックを実装するには、さまざまな方法があります。Salesforce バッチ マルチソース プラグインには、「Last Modified After(最終更新が指定日より後)」、「Last Modified Before(最終更新が指定日より前)」、「Duration(期間)」、「Offset(オフセット)」などのパラメータがあり、これらを使用して増分読み込みを制御できます。
以下は、Salesforce オブジェクトのリード、連絡先、アカウントに対する Data Fusion のバッチ増分パイプラインのサンプルです。パイプラインでは、増分読み込みに前回の開始 / 終了時間をガイドとして使用します。
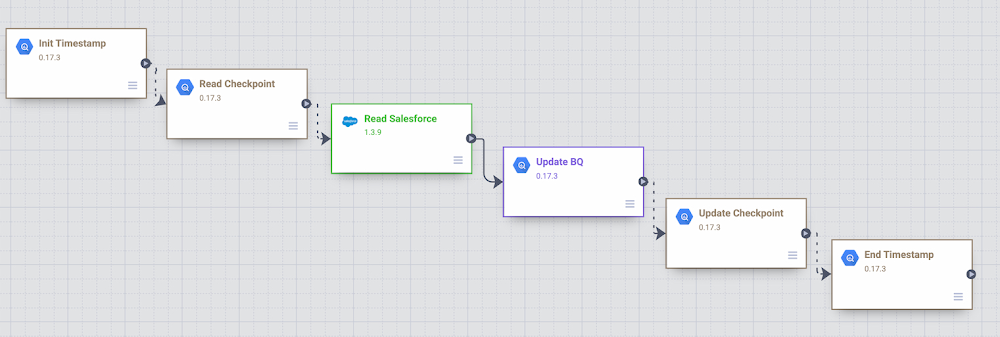
バッチ増分パイプライン - Salesforce から BigQuery へ
このサンプル パイプラインの主な手順は次の通りです。
このカスタム パイプラインでは、BigQuery に開始 / 終了時間を保存し、さまざまな BigQuery プラグインのデモを行うことにしました。パイプラインが開始されると、タイムスタンプが BigQuery のユーザー チェックポイント テーブルに保存されます。この情報は、その後の実行や増分ロジックのガイドとして使用されます。
パイプラインは BigQuery Argument Setter プラグインを使用して BigQuery のチェックポイント テーブルから読み取り、最小のタイムスタンプをフェッチして読み取ります。
リード、連絡先、アカウントの各オブジェクトは Batch Multi Source プラグインを使用して Salesforce から読み取られ、最小のタイムスタンプがプラグインに渡すパラメータとして使用されます。
BigQuery テーブルのリード、連絡先、アカウントの更新には、BigQuery Multi Table シンク プラグインが使用されます。
チェックポイント テーブルは実行終了時間で更新され、続いて current_time 列が更新されます。
もっと試してみたい場合
このサンプル Data Fusion パイプラインを開発環境で実行するには、GitHub から定義ファイルをダウンロードし、Cloud Data Fusion Studio でインポートします。インポートが完了したら、ご自身の Salesforce 環境に合わせて、プラグインのプロパティを調整してください。さらに、次の作業も必要になります。
from_salesforce_cdf_staging という名前の BigQuery データセットを作成します。
次のように、データセット from_salesforce_cdf_staging 上に sf_checkpoint BigQuery テーブルを作成します。
3. 次のレコードを sf_checkpoint テーブルに挿入します。
注意: 最初の last_completion date = “1900-01-01T23:01:01Z” は、最初のパイプラインの実行で、LastModifedDate 列が 1900-01-01 より大きいすべての Salesforce レコードを読み込むことを示しています。これは、最初のデータ読み込みを対象にしたサンプル値です。必要に応じて last_completion 列を調整し、初回実行時の環境や要件を反映させてください。
このサンプル パイプラインを数回実行した後、実行終了時に sf_checkpoint.last_completion 列がどのように変化するかを観察してください。また、以下に示すように、変更が BigQuery テーブルに段階的に読み込まれていることを検証することもできます。
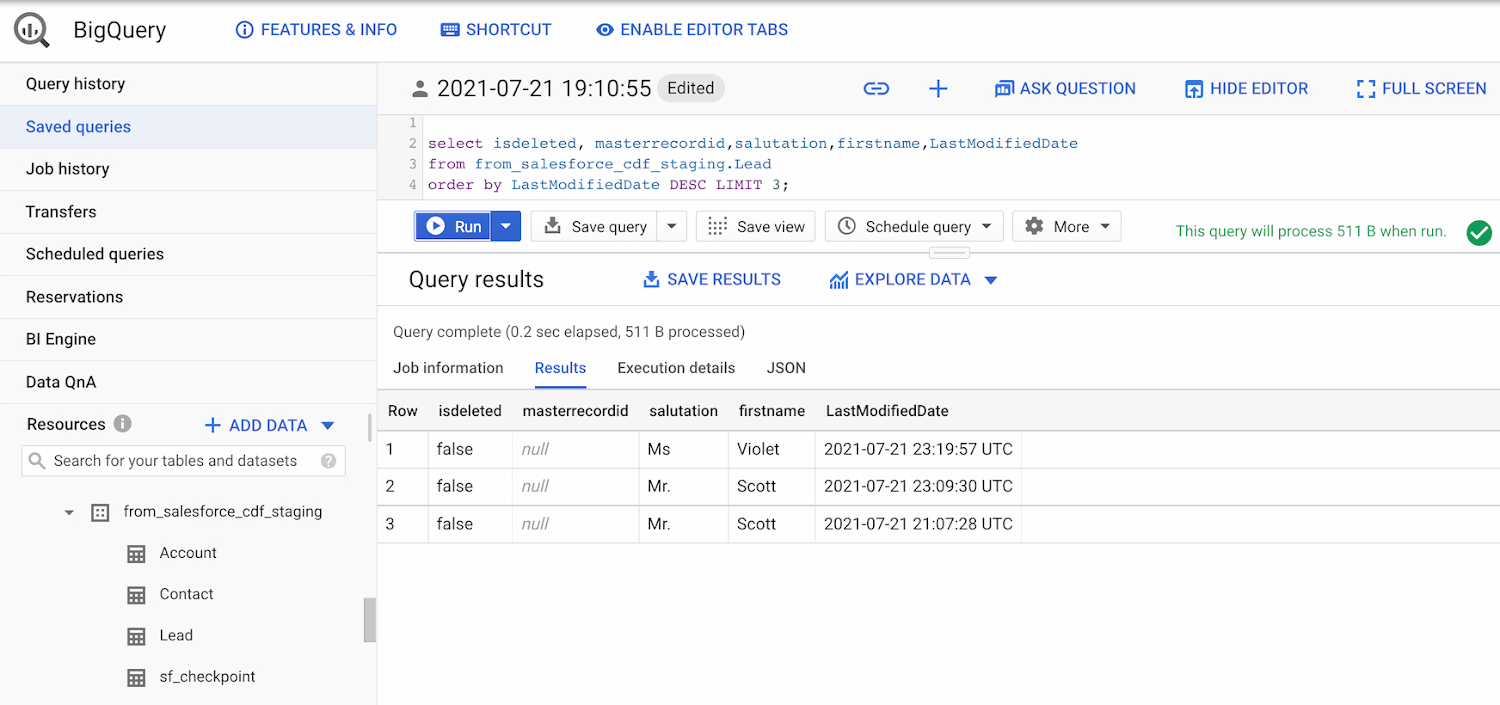
BigQuery の出力 - Salesforce 増分パイプライン
ストリーミング パイプライン
Data Fusion で Streaming Source プラグインを使用すると、Salesforce の sObject の変更は、PushTopic イベントを使用して追跡されます。Data Fusion の Streaming Source プラグインは、Salesforce PushTopic を作成することも、Salesforce ツールを使って事前に定義した既存の PushTopic を使用することもできます。
PushTopic の構成では、通知のトリガーとなるイベントの種類(挿入、更新、削除)と、スコープ内のオブジェクト列を定義します。Salesforce の PushTopic について詳しくは、こちらをクリックしてください。
データをストリーミングする場合、BigQuery でチェックポイント テーブルを作成する必要はありません。データはほぼリアルタイムで複製され、変更のみが発生と同時に自動的にキャプチャされます。Data Fusion のパイプラインは以下のサンプルのように非常にシンプルです。
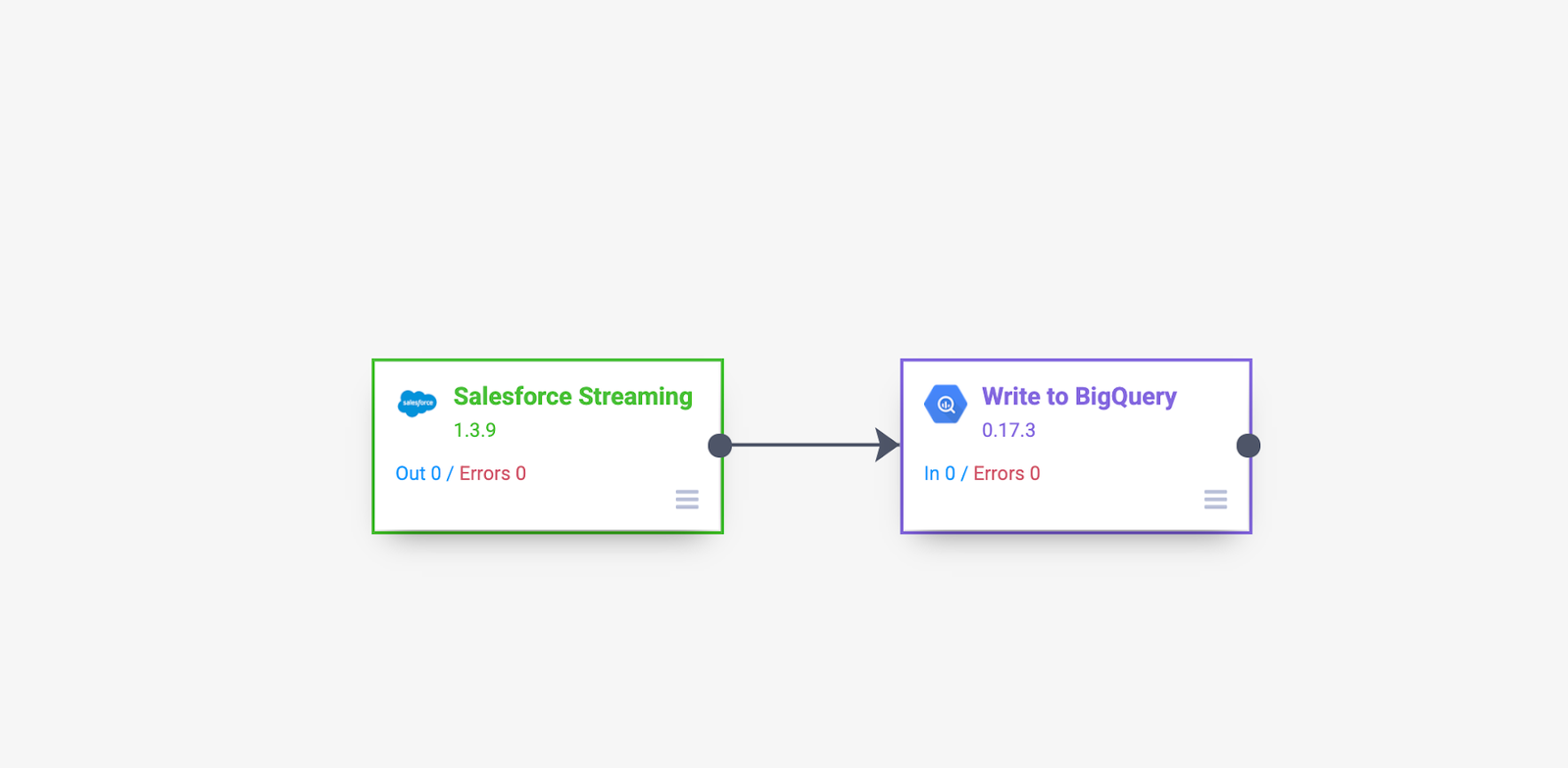
Cloud Data Fusion を使用した Salesforce ストリーミング パイプライン
このサンプル パイプラインの主な手順は次の通りです。
1. Salesforce のストリーミング ソースを追加し、その構成の詳細を提供します。この演習では、CDFLeadUpdates PushTopic から挿入と更新のみをキャプチャしています。参照用として、Salesforce で CDFLeadUpdates PushTopic を事前に作成するために使用したコードを示します。Data Fusion プラグインでは、必要に応じて PushTopic を事前に作成することもできます。
ヒント: このコードブロックを実行するには、適切な認証情報と権限を使用して Salesforce にログインし、Developer Console を開いて [Debug | Open Execute Anonymous Window] をクリックします。
2. ストリーミング イベントを受信するために、パイプラインに BigQuery シンクを追加します。パイプラインが実行され、最初の変更レコードが生成されると、BigQuery テーブルが自動的に作成されることが確認できます。
パイプラインを開始した後、Salesforce のリード オブジェクトにいくつかの変更を加え、BigQuery に流れ込む変更を観察すると次のようになります。
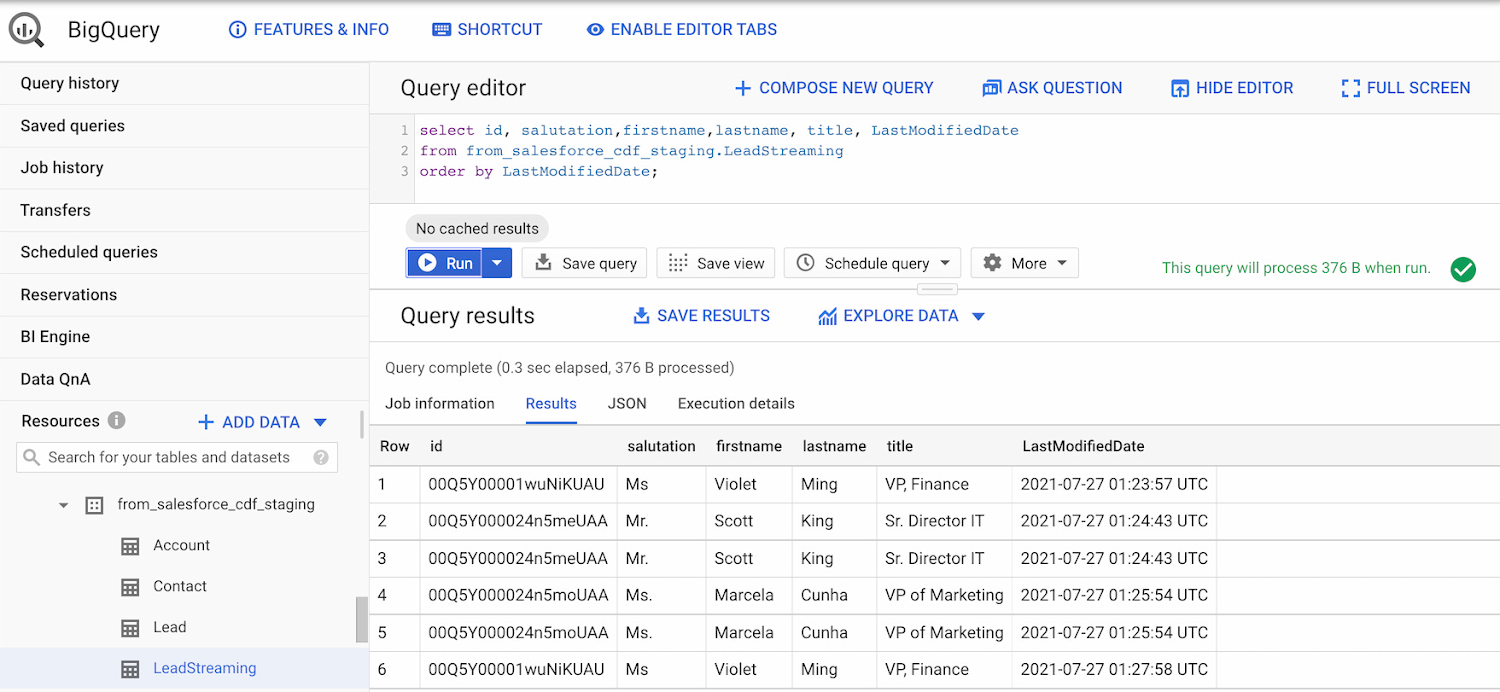
BigQuery の出力 - Cloud Data Fusion を使用した Salesforce ストリーミング パイプライン
もっと試してみたい場合
このサンプル Data Fusion パイプラインを開発環境で実行するには、GitHub から定義ファイルをダウンロードし、Cloud Data Fusion Studio でインポートします。インポートが完了したら、ご自身の Salesforce 環境に合わせて、プラグインのプロパティを調整してください。
削除が必要な場合
Salesforce の実装で「削除(復元不可)」が可能で、取得する必要がある場合、検討すべきアイデアのリストを以下に示します。
削除を追跡するための監査テーブル。たとえば、データベース トリガーを使用して、カスタムの監査テーブルに入力できます。その後、Data Fusion を使用して監査テーブルから削除レコードを読み込み、BigQuery で最終的な送信先テーブルを比較 / 更新できます。
ソースから主キーを読み込み、BigQuery のデータと比較 / 統合する追加の Data Fusion ジョブ。
削除 / 削除取り消しイベントをキャプチャするように構成された Salesforce PushTopic と、PushTopic からキャプチャするように追加された Data Fusion ストリーミング ソース。
Salesforce 変更データ キャプチャ。
結論:
会社で Salesforce を使用しており、データ ウェアハウスにデータを複製する作業を担当されている場合は、Cloud Data Fusion を使えば必要なものがすべて揃います。また、Cloud Storage、Dataproc、BigQuery など、データレイクをキュレートするために Google Cloud ツールをすでに使用している場合、Data Fusion の統合によって開発とイテレーションがさらに迅速かつ容易になります。
同じような課題をお持ちでしたら、次に Google Cloud でこちらの Cloud Data Fusion のクイックスタートをお試しください。
Data Fusion の詳細については、ドキュメントをご確認ください。
ご健闘をお祈りいたします。
-Google カスタマー エンジニア(大のデータ好き)Carlos Augusto
