より迅速で費用対効果に優れた Dataproc ジョブを実行する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
Dataproc は、Apache Hive、Apache Spark、Presto、Apache Flink、Apache Hadoop などのオープンソース型分散処理プラットフォームを Google Cloud でホストするためのフルマネージド サービスです。Dataproc を使用するとさまざまなサイズのクラスタをオンデマンドで柔軟にプロビジョニング、構成できます。また、費用の削減やパフォーマンスの向上、クラウドで実行しているワークロードの効率的な運用管理を実現する優れた機能も Dataproc に備わっています。
Dataproc はデータレイクのモダナイゼーションの取り組みにおける重要なサービスです。多くのお客様は Hadoop ワークロードを Dataproc に移行することでクラウドへの移行を開始し、Google Cloud のデータサービスをフルパッケージで組み入れ、ソリューションを継続的にモダナイズします。
このガイドでは Dataproc ジョブの安定性、パフォーマンス、費用対効果を最適化する方法を紹介します。これはワークフロー テンプレートを使用し、計算したアプリケーション固有のプロパティで Dataproc ジョブを実行する構成済みのエフェメラル クラスタをデプロイすることで実現できます。
はじめに
前提事項
Dataproc を高度に理解していること(よくある質問)
シェル スクリプト、YAML テンプレート、Hadoop エコシステムの使用経験
既存の Dataproc アプリケーション(「ジョブ」または「アプリケーション」)
クラスタの作成に十分なプロジェクトの割り当て(CPU、ディスクなど)
Dataproc Serverless または BigQuery を検討する
Dataproc を開始する前に、アプリケーションが Dataproc Serverless または BigQuery に適している(もしくは移植可能)かを確認してください。これらのマネージド サービスによりメンテナンスと構成の時間を短縮できます。
この投稿では開発者がシナリオに最適な方法として Dataproc を特定したと仮定します。その他のソリューションについては Hive ACID テーブルを BigQuery に移行するためのベスト プラクティスや Apache Spark バッチ ワークロードを実行するなどを参照してください。
データと計算処理を分離する
Cloud Storage を使用する利点を検討してください。ワークフローにこの永続ストレージを使用すると、次の利点があります。
Hadoop 互換ファイル システム(HCFS)を採用しているため、既存のジョブで簡単に使用できます。
Cloud Storage は HDFS よりも速い可能性があります。HDFS において、MapReduce ジョブは、NameNode がセーフモードから抜けるまで開始できません。これには、データのサイズや状態に応じて数秒から数分かかる場合があります。
HDFS よりもメンテナンスが少なくなります。
Google Cloud プロダクト全体でデータを簡単に使用できます。
永続的な Dataproc クラスタで複製(3x)HDFS にデータを保持するよりも、かなり低コストです。
価格比較例(北米、2022 年 11 月現在):
GCS: 1 GB あたり $0.004~$0.02(階層によって異なる)
Persistent Disk: 1 GB あたり $0.04~$0.34 + コンピューティング VM コスト
オンプレミスの Hadoop インフラストラクチャを Google Cloud に移行すると HDFS と Cloud Storage の比較: 長所、短所、移行のヒントを参照してください。Google Cloud は HDFS から GCS への移行を実行するためのオープンソース ツールを開発しました。
Cloud Storage を最適化する
Dataproc を使用すると Hive、HBase などで外部テーブルを作成できます。この場合、スキーマは Dataproc にありますがデータは Google Cloud Storage に保存されます。コンピューティングとストレージを分けることで、コンピューティング パワーとは無関係にデータをスケールングできます。
HDFS / Hive オンプレミス設定では、コンピューティングとストレージは同じマシン上か周辺マシンのいずれかで密接につながっています。HDFS で Google Cloud Storage を使用する場合、レイテンシを犠牲にしてコンピューティングとストレージを分けることになります。Dataproc で Google Cloud Storage のファイルを取得する場合は時間がかかってしまいます。たくさんの小さいファイル(数百万個の 1mb 未満のファイルなど)はクエリ パフォーマンスに悪影響を及ぼす可能性があります。ファイルタイプと圧縮もクエリ パフォーマンスに影響を及ぼす可能性があります。
Google Cloud でデータ分析を実行する場合、Cloud Storage ファイル ストラテジーを慎重に選択することが重要になります。
Dataproc ジョブをモニタリングする
次のガイドに従って、Dataproc ジョブを送信し、ユースケースのランタイムとコストを継続的に最適化します。ジョブ送信中またはジョブ送信後に Dataproc ジョブ コンソールをモニタリングし、Dataproc クラスタのパフォーマンスに関する詳細情報を取得します。ここでは、最適化の機会を特定する際に役立つ特別な指標、特に YARN 保留中メモリ、YARN NodeManager、CPU 使用率、HDFS の容量、ディスクのオペレーションが分かります。このガイドを通じてこうした指標がクラスタの構成変更に与える影響を確認できます。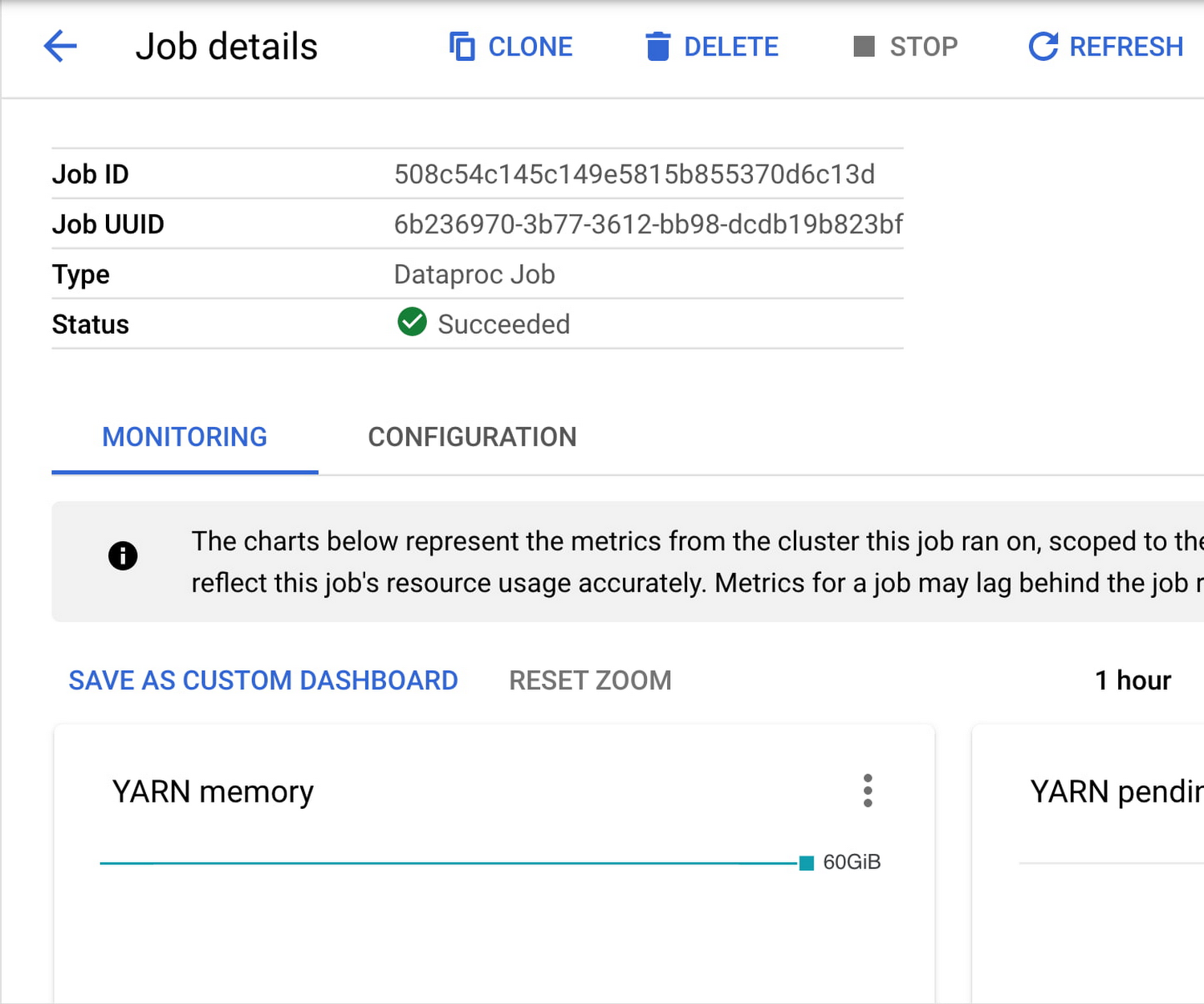
ガイド: より迅速で費用対効果に優れた Dataproc ジョブを実行する
1. はじめに
このガイドでは Dataproc クラスタで実行されるアプリケーションのパフォーマンスとコストを最適化する方法について説明します。Dataproc は多くのビッグデータ テクノロジーに対応しており、それぞれのテクノロジーが複雑なため、このガイドでは試行錯誤を繰り返すことを意図しています。最初はデフォルト設定の汎用 Dataproc クラスタで始めます。ガイドを続けるうちに特定のワークロードに合うように徐々に Dataproc クラスタ構成を最適化していきます。
個別の Dataproc ジョブをさまざまなクラスタに分けるようにします。各データ処理プラットフォームではリソースを異なる方法で使用します。また、各データ処理プラットフォームを同時に実行すると互いのパフォーマンスに影響を及ぼす可能性があります。さらに単一のジョブを単一のクラスタに分けることで、エフェメラル クラスタを設定できます。これにより、ジョブを専用リソースで並列に実行できます。
ジョブが正常に実行されると、構成を安全に繰り返し、ランタイムとコストを改善することができます。またテスト用の変更により悪影響が生じる場合は最後の正常な実行にフォールバックできます。
テスト中は既存のクラスタの構成をファイルにエクスポートできます。以下の構成を使用し、import コマンドを通じて新しいクラスタを作成します。
ズレの発生に備え、これらを最後の正常な構成の参照として保存します。
2. Dataproc クラスタのサイズを計算する
a. オンプレミス ワークロード経由(該当する場合)
YARN UI を表示する
このジョブをオンプレミスで実行している場合、ジョブに使用したリソースは Yarn UI で特定できます。以下の画像ではオンプレミスで正常に実行された Spark ジョブを示しています。
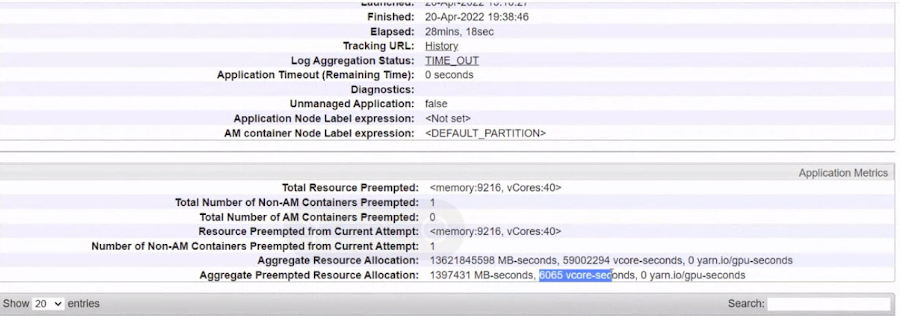
以下の表はこのジョブの重要業績評価指標です。
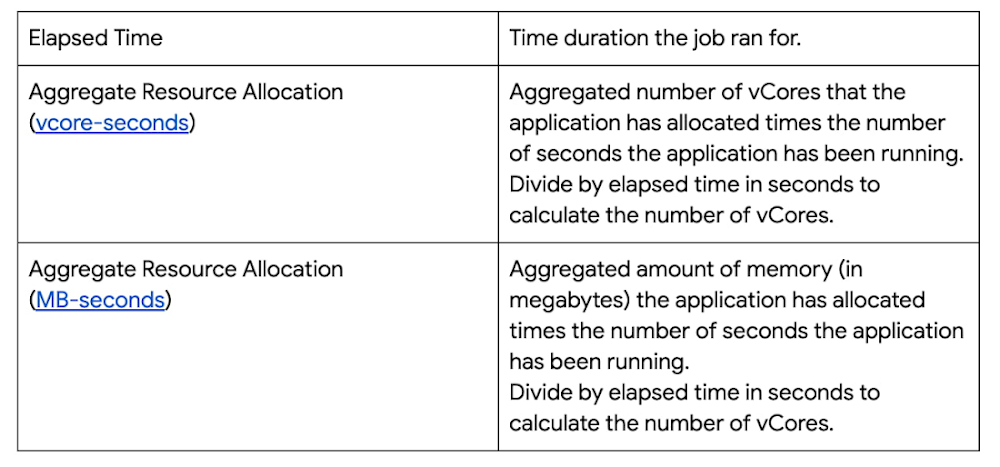
上記のジョブについて次のとおり計算できます。

クラスタをオンプレミスのサイズにしたら、次に Google Cloud で最初のクラスタのサイズを特定します。
最初の Dataproc クラスタのサイズを計算する
この演習では n2-standard-8 を使用していると仮定しますが、ワークロードのタイプによって別のマシンタイプの方が適切な場合があります。なお、n2-standard-8 には 8 個の vCPU と 32 GiB のメモリがあります。その他の Dataproc-対応マシンタイプはこちらで確認できます。
必要な vCore の数に基づいて必要なマシンの数を計算します。

上記の計算に基づく推奨事項:
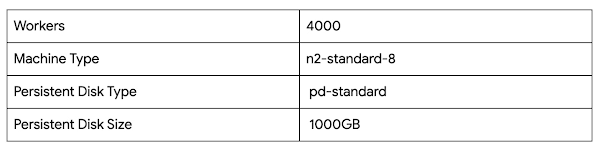
独自のジョブ / ワークロードの計算をメモします。
b. 自動スケーリング クラスタ経由
自動スケーリング クラスタによりアプリケーションに適切なワーカーの数を判断できます。このクラスタには自動スケーリング ポリシーを適用できます。自動スケーリング ポリシーの最小値 / 最大値をプロジェクト / 組織の許容値に設定します。そして、このクラスタでジョブを実行します。自動スケーリングは YARN 保留中メモリ指標がゼロになるまでノードを追加し続けます。最適なサイズのクラスタは YARN 保留中メモリの量を最小限に抑えつつ、過剰なコンピューティング リソースも最小限に抑えます。
サイズ設定 Dataproc クラスタをデプロイする
例:
2 個のプライマリ ワーカー(n2-standard-8)
0 個のセカンダリ ワーカー(n2-standard-8)
pd-standard 1000GB
自動スケーリング ポリシー: 0(最小)、100(最大)
アプリケーション プロパティ設定なし
sample-autoscaling-policy.yml
Dataproc クラスタにジョブを送信する
ワーカーの数 / YARN NodeManager をモニタリングする
ジョブを完了するために必要なピーク時のワーカーの数を観察します。
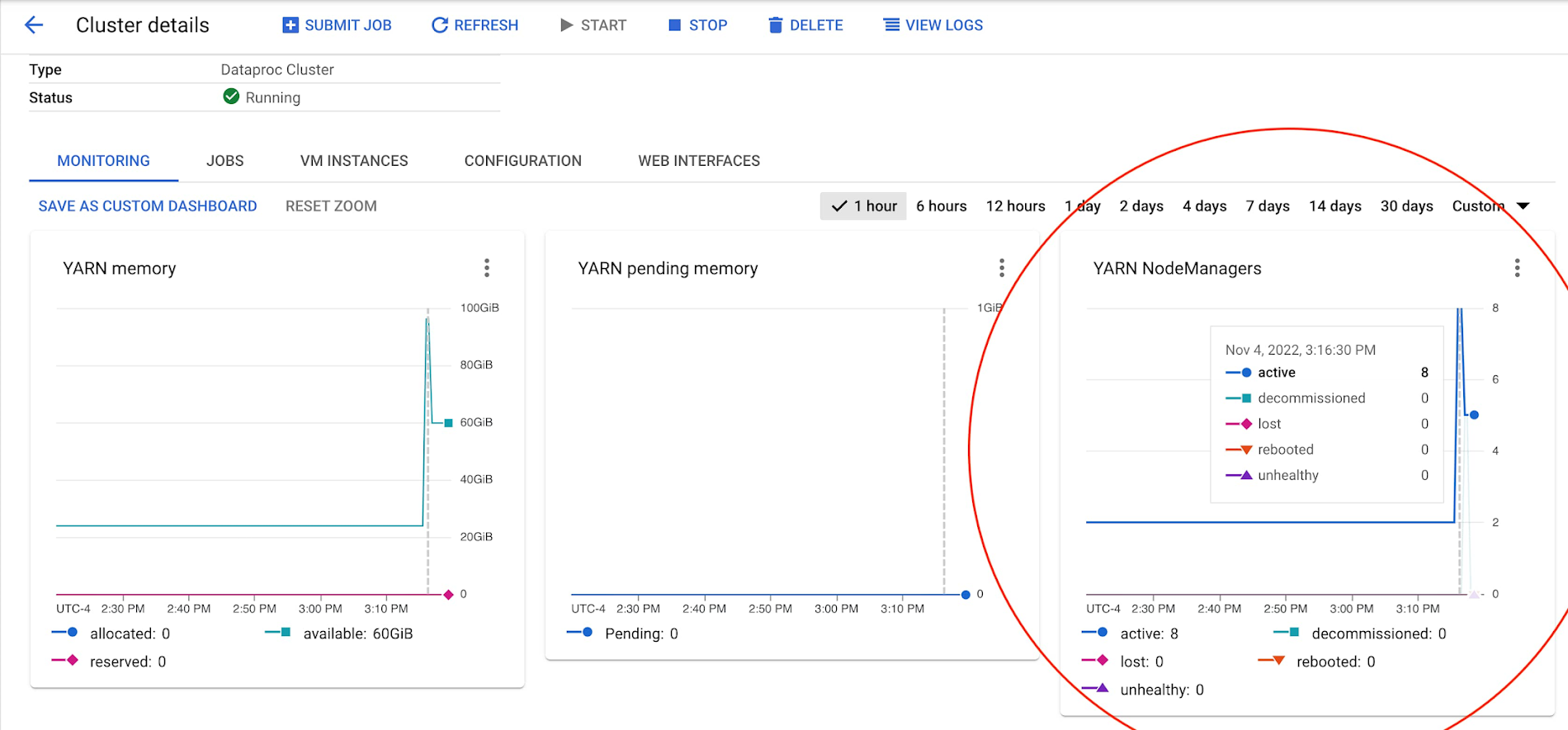
必要なコア数を計算するには、マシンサイズを乗算します(2、8、16 などをノード マネージャーの数に乗じます)。
3. Dataproc クラスタ構成を最適化する
このテストフェーズで自動スケーリングしないクラスタを使用すると、より正確なマシンタイプ、永続ディスク、アプリケーション プロパティなどが特定できるようになります。ここでは、ジョブのためにプライマリ ワーカーの数が最適化された、隔離された自動スケーリングしないクラスタを構築します。
例:
N 個のプライマリ ワーカー(n2-standard-8)
0 個のセカンダリ ワーカー(n2-standard-8)
pd-standard 1000GB
自動スケーリングのポリシーなし
アプリケーション プロパティの設定なし
自動スケーリングしない Dataproc クラスタをデプロイする
正しいマシンタイプとマシンサイズを選択する
適切にサイズ設定された、自動スケーリングしないクラスタでジョブを実行します。CPU が最大値に達する場合 C2 マシンタイプの使用を検討してください。メモリが最大値に達する場合は N2D-highmem マシンタイプの使用を検討してください。
より小さいマシンタイプを使用するようにしてください(n2-highmem-32 を n2-highmem-8 に切り替えるなど)。クラスタに数百個の小さいマシンがあっても問題ありません。Dataproc クラスタの場合、最大ネットワーク帯域幅(32 Gbps)を使用する最も小さいマシンを選んでください。通常これらのマシンは n2-standard-8 または n2d-standard-16 になります。
マシンサイズを 32 コアまたは 64 コアに増やす必要がまれにあります。組織で IP アドレスが不足している場合や ML や処理のワークロードが大きい場合、マシンサイズを増やす必要がある可能性があります。
詳細はマシン ファミリーのリソースと比較ガイド | Compute Engine ドキュメント | Google Cloud を参照してください。
Dataproc クラスタにジョブを送信する
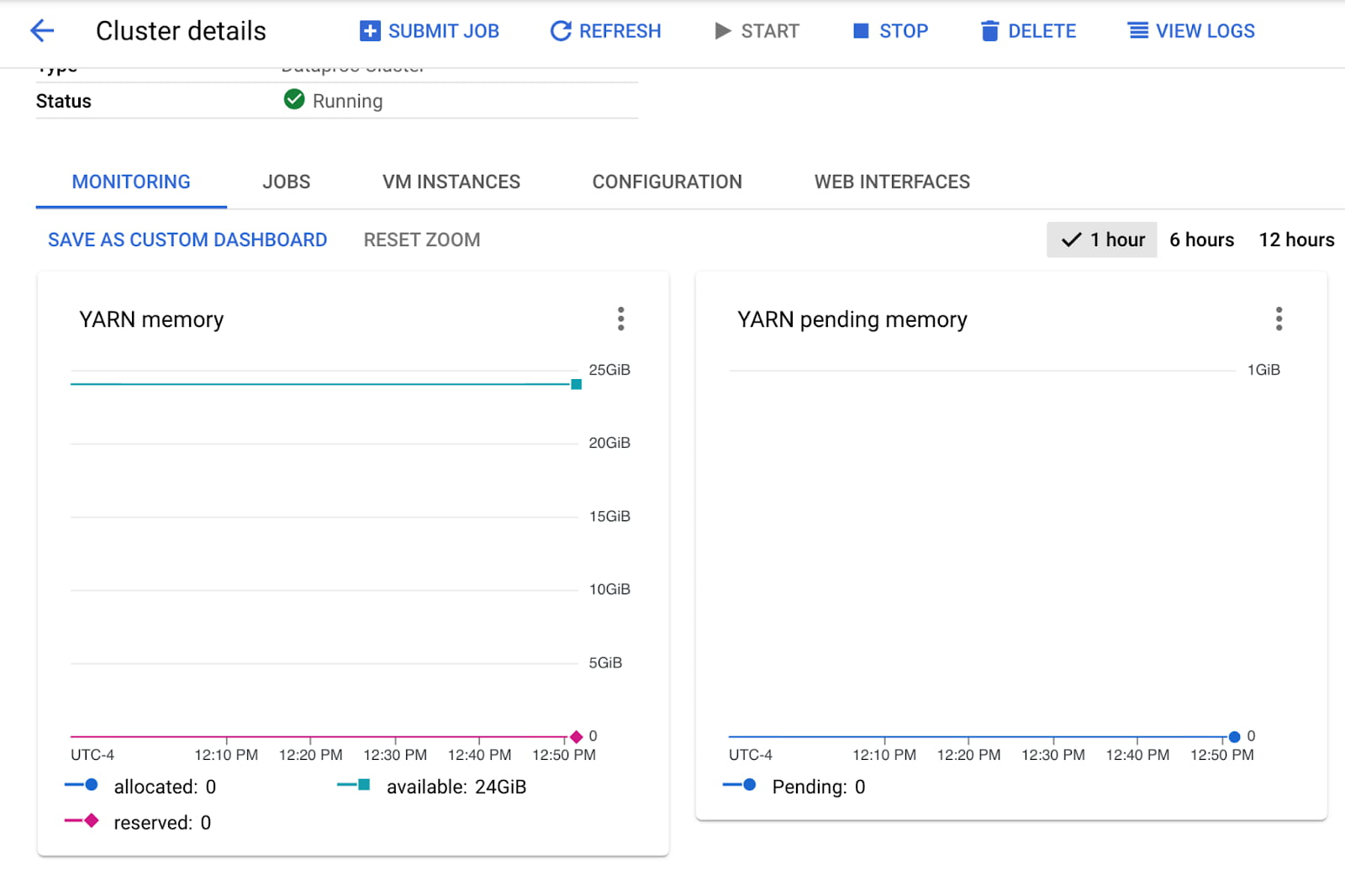
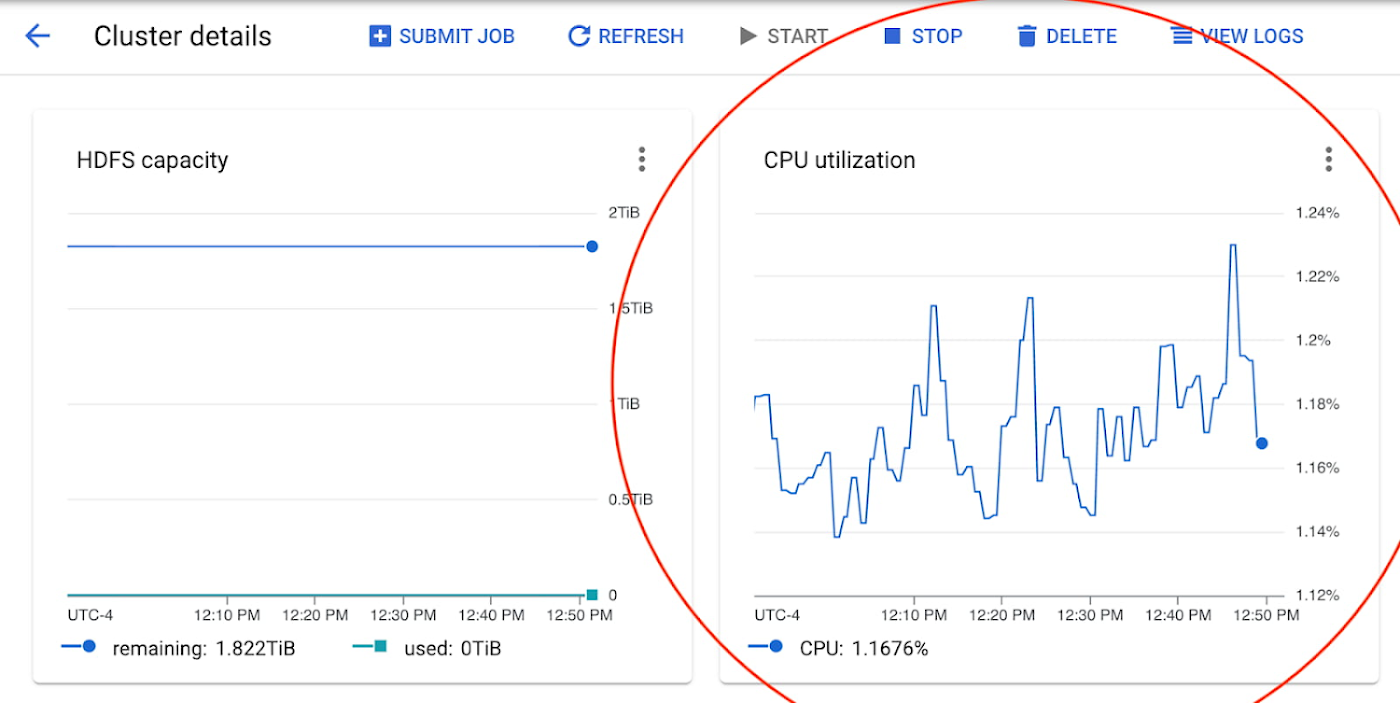
クラスタの指標をモニタリングする
メモリをモニタリングしてマシンタイプを決める:
CPU をモニタリングしてマシンタイプを決める:
最適な永続ディスクを選択する
パフォーマンスの問題が解決しない場合、pd-standard から pd-balanced または pd-ssd に切り替えることを検討してください。
標準永続ディスク(pd-standard)は主にシーケンシャル I/O を使用する大規模なデータ処理ワークロードに適しています。ローカル SSD がない PD-Standard の場合、1TB(1000GB)以上にプロビジョニングして一貫した高 I/O パフォーマンスを実現することを強くおすすめします。
バランス永続ディスク(pd-balanced)はパフォーマンスとコストのバランスが取れたディスクで、SSD 永続ディスクの代わりに使用できます。バランス永続ディスクの最大 IOPS は SSD 永続ディスクと同じですが、1 GB あたりの IOPS は低くなります。また、バランス永続ディスクは、ほとんどの汎用アプリケーションに適したパフォーマンスを標準ディスクと SSD 永続ディスクの中間の価格で提供します。
SSD 永続ディスク(pd-ssd)は標準永続ディスクが提供するものより低いレイテンシと高い IOPS が必要なエンタープライズ アプリケーションや高パフォーマンス データベースを求める場合に最適です。
同様のコストで pd-standard は 1000GB、pd-balanced は 500GB、pd-ssd は 250 GB を提供します。ディスクを構成する際はパフォーマンスの影響を必ず確認してください。ディスク I/O パフォーマンスの詳細については、パフォーマンス要件を満たすようにディスクを構成するをご覧ください。マシンタイプと永続ディスクの関係の詳細については、マシンタイプと vCPU 数別のパフォーマンスをご覧ください。32 コア以上のマシンを使用している場合、ワークロードで十分なパフォーマンスが得られるようにノードごとに複数のローカル SSD に切り替えることを検討してください。
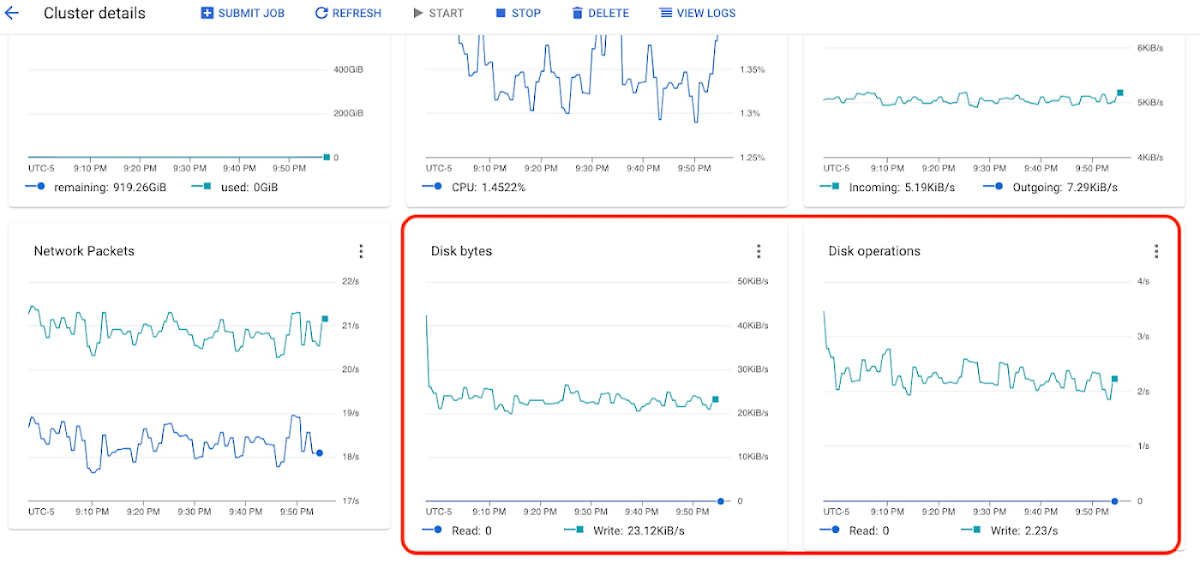
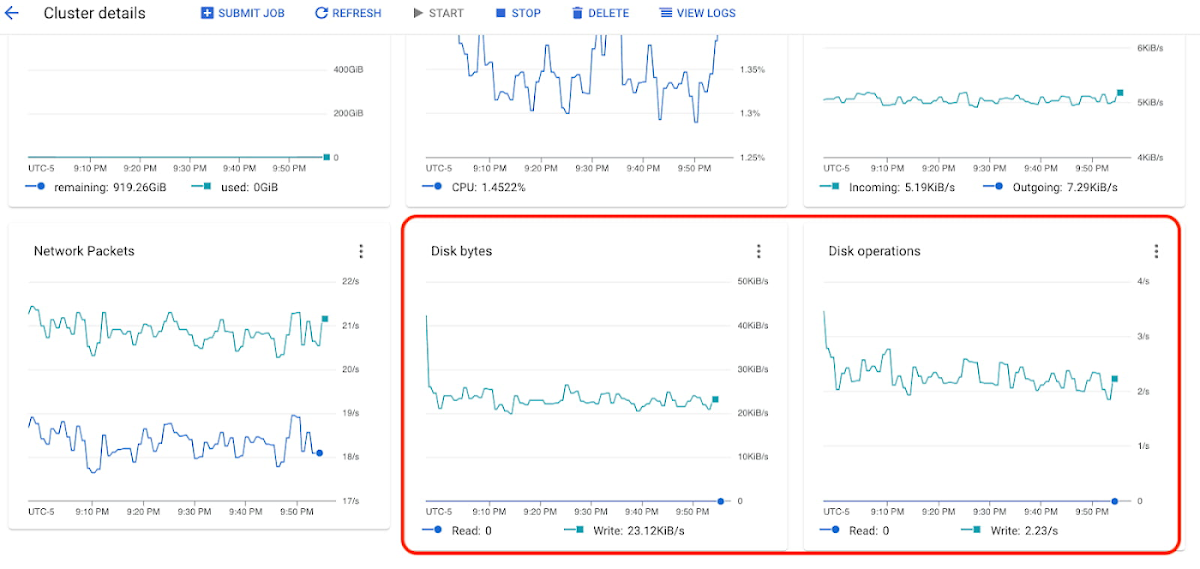
HDFS 容量をモニタリングしてディスクサイズを決定できます。HDFS 容量がゼロになる場合、永続ディスクのサイズを増やす必要があります。
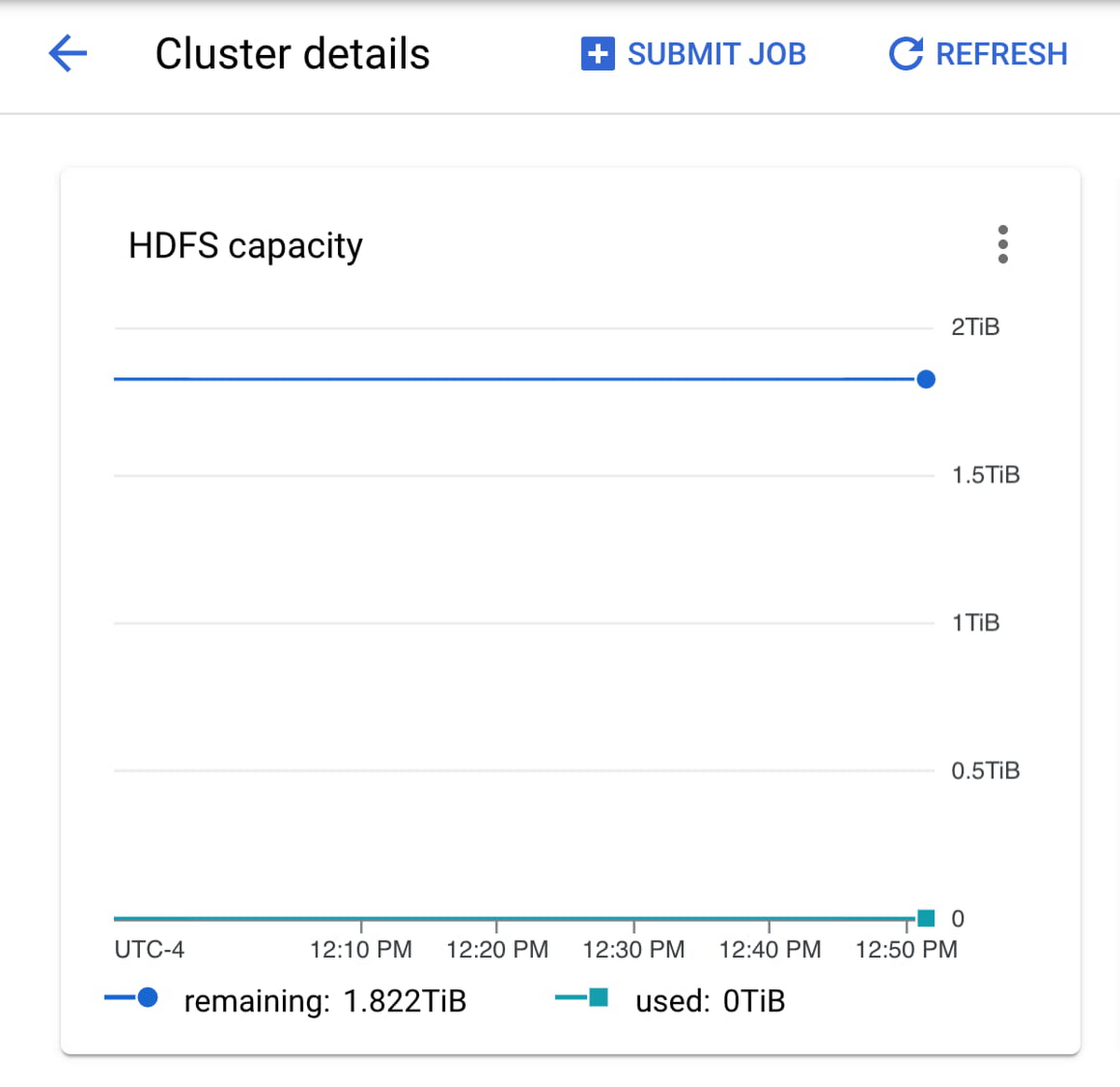
ディスクのバイト数やディスク操作のスロットリングがみられる場合、クラスタの永続ディスクをバランス ディスクまたは SSD ディスクに変更することを検討します。
プライマリ ワーカーとセカンダリ ワーカーの適切な比率を選ぶ
クラスタにはプライマリ ワーカーが必要になります。クラスタを作成し、プライマリ ワーカーの数を指定しない場合、Dataproc によって 2 個のプライマリ ワーカーがクラスタに追加されます。その後パフォーマンスとコストの最適化のどちらを優先するか決める必要があります。
パフォーマンスを優先する場合、すべてのプライマリ ワーカーを活用します。コストの最適化を優先する場合は残りのワーカーをセカンダリ ワーカーに指定します。
プライマリ ワーカー マシンはクラスタ専用となり HDFS 容量を提供します。他方でセカンダリ ワーカー マシンには Spot VM、標準プリエンプティブル VM、非プリエンプティブル VM の 3 種類あります。デフォルトでは、セカンダリ ワーカーが 100 GB またはプライマリ ワーカーのブート ディスク サイズのいずれか小さい方で作成されます。このディスク容量はデータをローカルのキャッシュに保存するために使用され、HDFS は実行しません。セカンダリ ワーカーはクラスタ専用でなく、いつでも削除される可能性があるので注意してください。セカンダリ ワーカーを使用する際はアプリケーションがフォールト トラレントであることを確認してください。
ローカル SSD のアタッチを検討する
一部のアプリケーションでは永続ディスクが提供するよりも高いスループットが必要な場合があります。そのようなシナリオではローカル SSD を試してください。ローカル SSD は、クラスタに物理的にアタッチされ、永続ディスクよりもスループットが高くなります(パフォーマンス表をご覧ください)。ローカル SSD は、375 GB の固定サイズで利用できますが、複数の SSD を追加してパフォーマンスを改善することもできます。
ローカル SSD は、クラスタのシャットダウン後にデータを保持しません。永続ストレージが必要な場合は、SSD 永続ディスクを使用して、標準永続ディスクよりもサイズに対するスループットを高めることができます。パーティション サイズが 8 KB 未満の場合も SSD 永続ディスクが適しています(ただし、小さいパーティションは避けてください)。
永続ディスクのように、ディスクのバイト数やディスク オペレーションのスロットリングを引き続きモニタリングし、ローカル SSD が最適かどうか判断します。
GPU のアタッチを検討する
処理パワーをさらに高める場合は、クラスタに GPU をアタッチすることを検討してください。Dataproc クラスタでは Compute Engine のマスターノードまたはワーカーノードにグラフィック プロセッシング ユニット(GPU)をアタッチできます。この GPU を使用して、インスタンスで実行される機械学習やデータ処理などの特定のワークロードを高速化できます。
Dataproc ノードにアタッチされた GPU を利用するには、GPU ドライバが必要です。GPU ドライバをインストールするには、この初期化アクションの手順に従ってください。
GPU を使用してクラスタを作成する
コンピューティング負荷の高いワークロード用のサンプル クラスタ
4. アプリケーション固有のプロパティを最適化する
パフォーマンスの問題が解決しない場合、アプリケーションのプロパティを調整します。理想的には、これらのプロパティがジョブの送信時に設定され、プロパティがそれぞれのジョブで分かれるようにします。以下のアプリケーションのベスト プラクティスを確認してください。
プロパティを使用して Dataproc ジョブを送信する
5. 自動スケーリング ポリシーを通じてエッジケースのワークロードの急増に対応する
クラスタを最適なサイズに設定し、構成、調整したので、自動スケーリングが導入できるようになりました。積極的なスケールアップとスケールダウンにより Dataproc ジョブが不安定になるため、自動スケーリングを費用を最適化するための手法として捉えないでください。ただし保守的な自動スケーリングによって、より多くのワーカーノードを要するエッジケース時の Dataproc クラスタのパフォーマンスを向上させることができます。
エフェメラル クラスタ(次のステップを参照)を使用してクラスタをスケールアップできるようにし、ジョブまたはワークフローが完了したら削除します。
プライマリ ワーカーがクラスタの 50% 超であるようにします。
プライマリ ワーカーの自動スケーリングは避けてください。プライマリ ワーカーは HDFS データノードを実行しますが、セカンダリ ワーカーはコンピューティングのみを行います。HDFS の Namenode には競合状態が複数あり、これによって HDFS が破壊状態に陥り、デコミッションが恒久的に停止します。
プライマリ ワーカーはより高額ですが、ジョブの安定性とパフォーマンスが向上します。プライマリ ワーカーとセカンダリ ワーカーの比率は安定性とコストのトレードオフになります。
メモ: セカンダリ ワーカーが多すぎるとジョブが不安定になります。過半数をセカンダリ ワーカーにしないことがベスト プラクティスです。
可能な限り自動スケーリングのないエフェメラル クラスタを選びます。
これらをスケールアップして、ジョブが完了したら削除します。
前述したように、ワーカーのスケールダウンは避けてください。ジョブが不安定になる可能性があります。
エフェメラル クラスタで scaleDownFactor を 0.0 に設定します。
自動スケーリング ポリシーを作成し、適用する
sample-autoscaling-policy.yml
6. Dataproc のエフェメラル クラスタを通じてコストと再利用性を最適にする
エフェメラル クラスタの主な利点は次のとおりです。
ジョブごとに異なるクラスタ構成を使用できるため、ジョブ間でツールを管理する負担がなくなります。
個々のジョブまたはジョブグループに合わせてクラスタをスケーリングできます。
ジョブで使用したリソース量に対してのみ課金されます。
クラスタは、使用するたびに新しく構成されます。そのため、クラスタを常時維持する必要はありません。
開発、テスト、本番環境用に別々のインフラストラクチャを維持する必要はありません。同じ定義を使用して、必要に応じて必要な種類のクラスタを作成できます。
カスタム イメージを作成する
クラスタのパフォーマンスに満足したら、自動オートスケーリングのないクラスタからエフェメラル クラスタに移行できます。
クラスタにはさまざまなソフトウェアをインストールする初期化スクリプトがありますか?Dataproc カスタム イメージを使用してください。より迅速な起動時間でエフェメラル クラスタを作成できるようになります。Google Cloud ではカスタム イメージを生成するオープンソースのツールを提供しています。
カスタム イメージを生成する
カスタム イメージを使用する
ワークフロー テンプレートを作成する
エフェメラル クラスタを作成するには Dataproc ワークフロー テンプレートを設定する必要があります。ワークフロー テンプレートは、再利用可能なワークフロー構成です。ジョブの実行場所に関する情報を含むジョブのグラフを定義します。
gcloud dataproc クラスタの export コマンドを使用してクラスタ構成用の YAML を生成します。
ワークフロー テンプレートでこのクラスタ構成を使用します。新しく作成したカスタム イメージ(アプリケーション)にポイントし、ジョブ固有のプロパティを追加します。
ワークフロー テンプレートの例(カスタム イメージ付き)
ワークフロー テンプレートを通じてエフェメラル クラスタをデプロイする
Dataproc ワークフロー テンプレートでは次のようなユースケースに Dataproc オーケストレーション ソリューションを提供します。
反復的なタスクの自動化
トランザクション型ファイア アンド フォーゲット方式 API インタラクション モデル
エフェメラル クラスタと長寿命クラスタのサポート
きめ細かい IAM セキュリティ
さらに幅広いデータ オーケストレーション ストラテジーについては、Cloud Composer のようなより包括的なデータ オーケストレーション サービスを検討してください。
次のステップ
この投稿では Dataproc ジョブの安定性、パフォーマンス、費用対効果を最適化する方法を紹介しました。ワークフロー テンプレートを使って、計算したアプリケーション固有のプロパティで Dataproc ジョブを実行する構成済みのエフェメラル クラスタをデプロイします。
最後に、最適なパフォーマンスを実現するための努力を続ける方法はたくさんあります。Google Cloud 公式ブログに記載されているガイダンスを参照して、検討してみてください。一般的なベスト プラクティスについては、Dataproc ベスト プラクティス | Google Cloud 公式ブログをご覧ください。本番環境での実行におけるガイダンスについては、本番環境で Cloud Dataproc を実行するための 7 つのベスト プラクティス | Google Cloud 公式ブログをご覧ください。



