ETL 不要の Bigtable データ分析を BigQuery で実現

Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
現代のビジネスで競争優位性を維持するためには、リアルタイムな分析情報の活用が非常に重要になってきています。人間による意思決定の迅速化であれ、意思決定の完全自動化が目的であれ、分析情報を得るためには、複数のデータソースを使用することが多い、ハイブリッドなトランザクション分析のワークロード実行が必要です。
BigQuery は、Google Cloud のサーバレスなマルチクラウド データ ウェアハウスです。複数ソースのデータを統合することで分析作業を簡素化します。Cloud Bigtable は、Google Cloud によるフルマネージド NoSQL データベースです。時間的制約のあるトランザクション ワークロードや分析ワークロードに適しています。
Bigtable は、リアルタイムでの不正検出、最適化案、カスタマイズ、時系列など、多種多様なユースケースでお客様に使用されています。こうしたユースケースにより作成されたデータは、高いビジネス上の価値を有します。
これまでも、Dataflow などの ETL ツールを用いてデータを Bigtable から BigQuery へコピーし、有効活用することは可能でした。しかし、このアプローチにはいくつかの弱点がありました。たとえば、データ鮮度の問題、同じデータのためのストレージ費用が二重になること、また、ETL パイプラインの維持管理の必要性などです。Bigtable のお客様の多くが数百テラバイトや数百ペタバイトものデータを保存していることを踏まえると、こうした重複コストがかなりの高額になる可能性があります。さらには、日次的な ETL ジョブでデータをコピーすることによって、ビジネスにおいて多大な競争上の優位性にもなりうる最新データから分析情報を獲得する能力が制限されてしまいます。
本日一般提供された BigQuery での Bigtable 連携クエリは、データのコピーや移動をせず、Bigtable 内のデータを BigQuery 経由で迅速にクエリできます。Google Cloud の全リージョンで連携クエリの同時実行の上限が拡大し、これまで運用データと分析の間に存在していたギャップが解消されました。
機能のプレビュー期間中、お客様の一般的な利用方法には以下の 2 パターンがあることが分かりました。
SQL の JOIN 演算子を使用して他のデータ ソースからの属性を付加することで、Bigtable のデータを強化する。他のデータソースの例としては、BigQuery テーブルやその他の外部データベース(CloudSQL、Spanner など)、BigQuery がサポートするファイル形式(CSV、Parquet など)。
SQL の UNION 演算子を使用して Bigtable 内のホットデータと BigQuery 内のコールドデータを合わせ、長期的な縦断データ分析を行う。
それでは、BigQuery が Bigtable に保存されているデータへアクセスできるように連携クエリを設定する方法をご紹介します。
外部テーブルの設定
例として、デジタル通貨のトランザクション ログを Bigtable に保存しているとします。次のようなステートメントを使用して、外部テーブルを作成し、BigQuery の内部からこのデータへアクセスすることができるようになります。
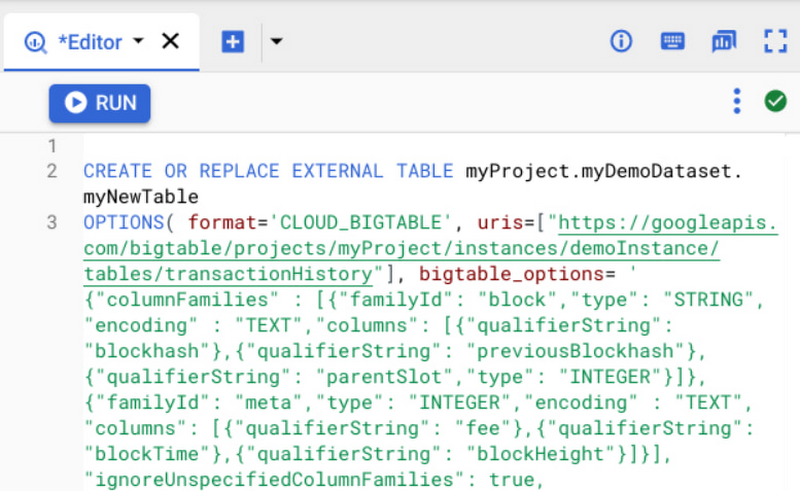
外部テーブル構成は BigQuery へ列ファミリー、レコードのために複数のバージョンを返すかどうか、列エンコード、データ型などさまざまな情報を提供します。これは、Bigtable のスキーマがフレキシブルで、数千の列と多様なエンコードを持ち、バージョン履歴付きであるためです。また、こうした分析クエリを異なるクラスタへ再ルーティングしたり、CPU 使用率などの関連指標をトラッキングするようにアプリのプロファイルを個別に指定することもできます。
Bigtable データにアクセスするクエリの作成
Bigtable でサポートされた外部テーブルは、BigQuery 内のテーブルと同様にクエリできます。
クエリは Bigtable によって実行されるため、Bigtable の高スループットかつ低レイテンシなデータベース エンジンの恩恵を受けることができます。これにより、ペタバイト規模のデータセット内にある選択された行範囲の中でも、リクエストされた列や関連する行を迅速に識別できます。ただし、上記の例のような無制限のクエリの場合、大きなテーブル上では実行に長時間を要することがあります。レスポンス時間を短縮するには、WHERE 句の中で行キーフィルタを使用するようにしてください。
Bigtable でサポートされていないクエリ演算子は、BigQuery により実行され、要求データは BigQuery のデータベース エンジンへシームレスにストリーミングされます。
上記で作成した外部テーブルは、JDBC / ODBC ドライバとコネクタ(データポータル、Looker、Tableau など広く利用されているビジネス インテリジェンス、データのビジュアリゼーション ツール用)、AutoML Tables(機械学習のトレーニング モデル用)、BigQuery の Spark Connector(データ サイエンティストによるモデルの開発環境へのデータの読み込み用)などの BigQuery 機能も利用できます。
Spark でデータを利用するためには、下記の PySpark の例で示したような SQL クエリが必要です。ただし、Spark のセッションを作成するためのコードは簡略化のために省略されています。
Bigtable は NoSQL データベースであり、データ ストラクチャのネスト化が可能です。そのため、場合によってはビューを作成してデータをフラット テーブルに変換することを検討してください。
データが Bigtable セルに埋め込まれた JSON オブジェクトを含んでいる場合、BigQuery のJSON 関数を利用してオブジェクトのコンテンツを抽出できます。
さらに、ETL ジョブを記述するのではなく、外部テーブルを利用してデータを BigQuery へコピーすることもできます。たとえば、探索的データ分析のために、銘柄コード「GOOGL」の 1 日分のデータをエクスポートする場合、クエリは下記の例のようになります。
詳細
Bigtable の利用を開始するには、Qwiklab でお試しください。
Bigtable での BigQuery とクエリの連携について詳しくは、プロダクト ドキュメントをご覧ください。
- Cloud Bigtable グループ プロダクト マネージャー Bora Beran
- BigQuery シニア プロダクト マネージャー Gaurav Saxena