BigQuery の監査ログ パイプラインを活用した使用状況分析
Google Cloud Japan Team
※この投稿は米国時間 2021 年 12 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery スポットライト シリーズでは、モニタリングについてお話ししました。このブログ投稿では、監査ログを使用した詳細なモニタリングについてご紹介します。BigQuery の監査ログは Google Cloud のログを集めたもので、BigQuery を使用したオペレーションに関する分析情報を提供します。監査ログからは豊富な情報を入手できます。Cloud Logging がキャプチャするさまざまなイベントからは、「誰」が「どのような」操作を行い、システムが「どのように」動作したかがわかります。
BigQuery 監査ログの概要
Google Cloud 監査ログの機能は次のとおりです。

監査ログは、BigQuery のユースケースのうち INFORMATION_SCHEMA や BigQuery 管理パネルなどでは実現が難しい、特定のユースケースのモニタリングに活用できます。利用可能なモニタリング オプション全般について詳しくは、こちらのブログをご覧ください。以下は、BigQuery をモニタリングするために監査ログを活用できる重要なユースケースです。
データ侵害などのセキュリティ インシデントを特定し、対処する
ユーザーのデータ アクセス パターンを把握する(列アクセス情報など)
ユーザー行動を分析する
IP アドレス分析により、複数リージョンにわたって不正な行為者を特定する
BigQuery の監査ログメッセージには、以下の 3 種類があります。
AuditData - API 呼び出しをレポートする旧バージョンのログ
BigQueryAuditMetadata - テーブルの読み込み、テーブルの期限切れなど、リソースのインタラクションをレポートする
AuditLogs - BigQuery Reservations と BigQuery Connections がリクエストのレポート時に使用するログ
BigQuery の監査ログは、以下のストリームに分類されます。
管理アクティビティ ログ: PatchDataset、UpdateTable、DeleteTable、PatchTable などのイベント
データ アクセス ログ: Query、TableDataChange、TableDataRead などのイベント
システム イベント: 内部テーブルの期限切れなどのイベント
ポリシー拒否ログ: BigQuery の権限に関連するイベント
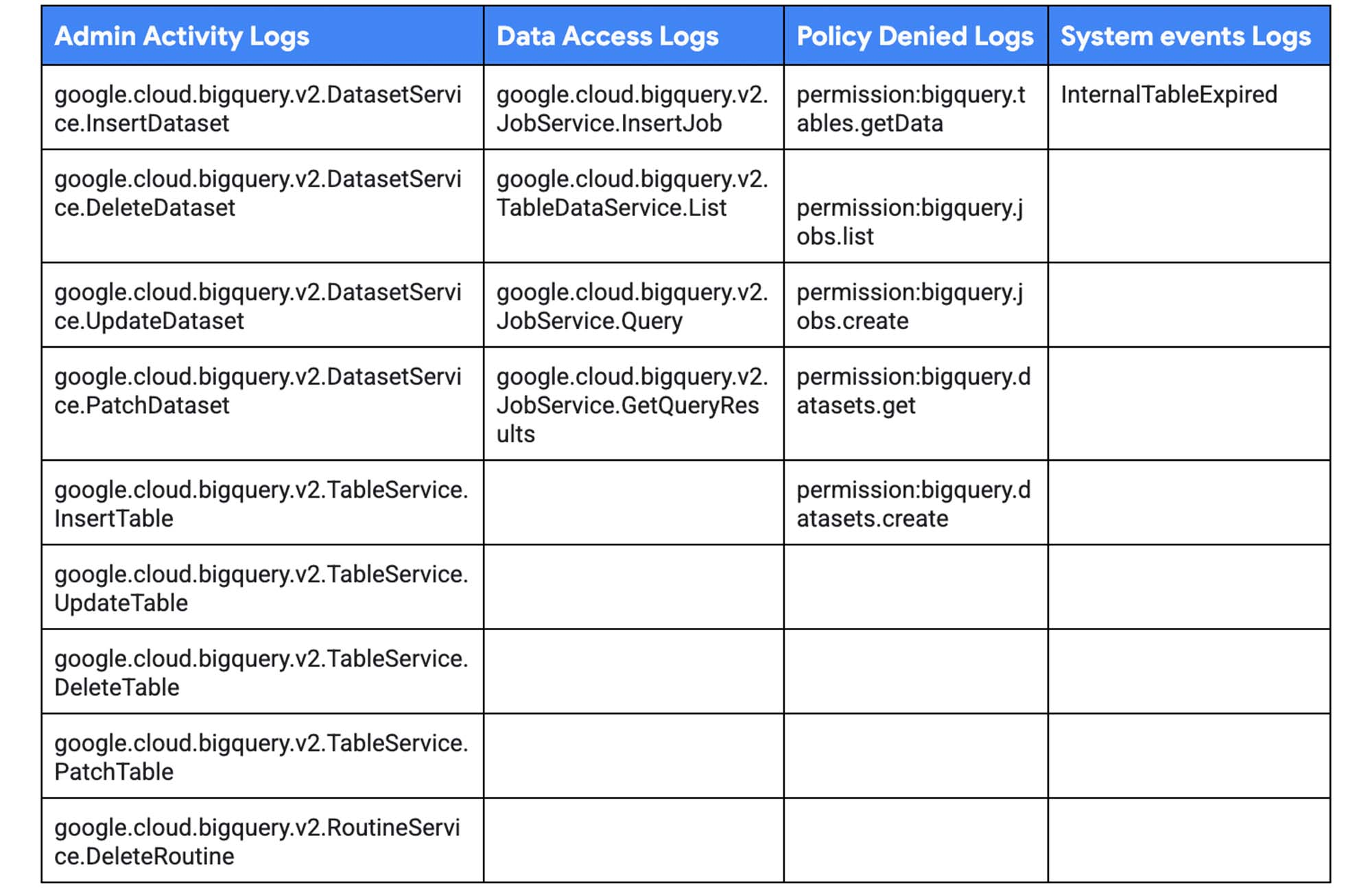
BigQuery のログイベントの種類
新しいワークロードには、新バージョンのログイベントのみを使用します。新しいログイベントは google.cloud.bigquery.v2 という接頭辞で始まります。旧バージョンのログイベントは無視してもかまいません。これには datasetservice、tabledataservice などが該当します。
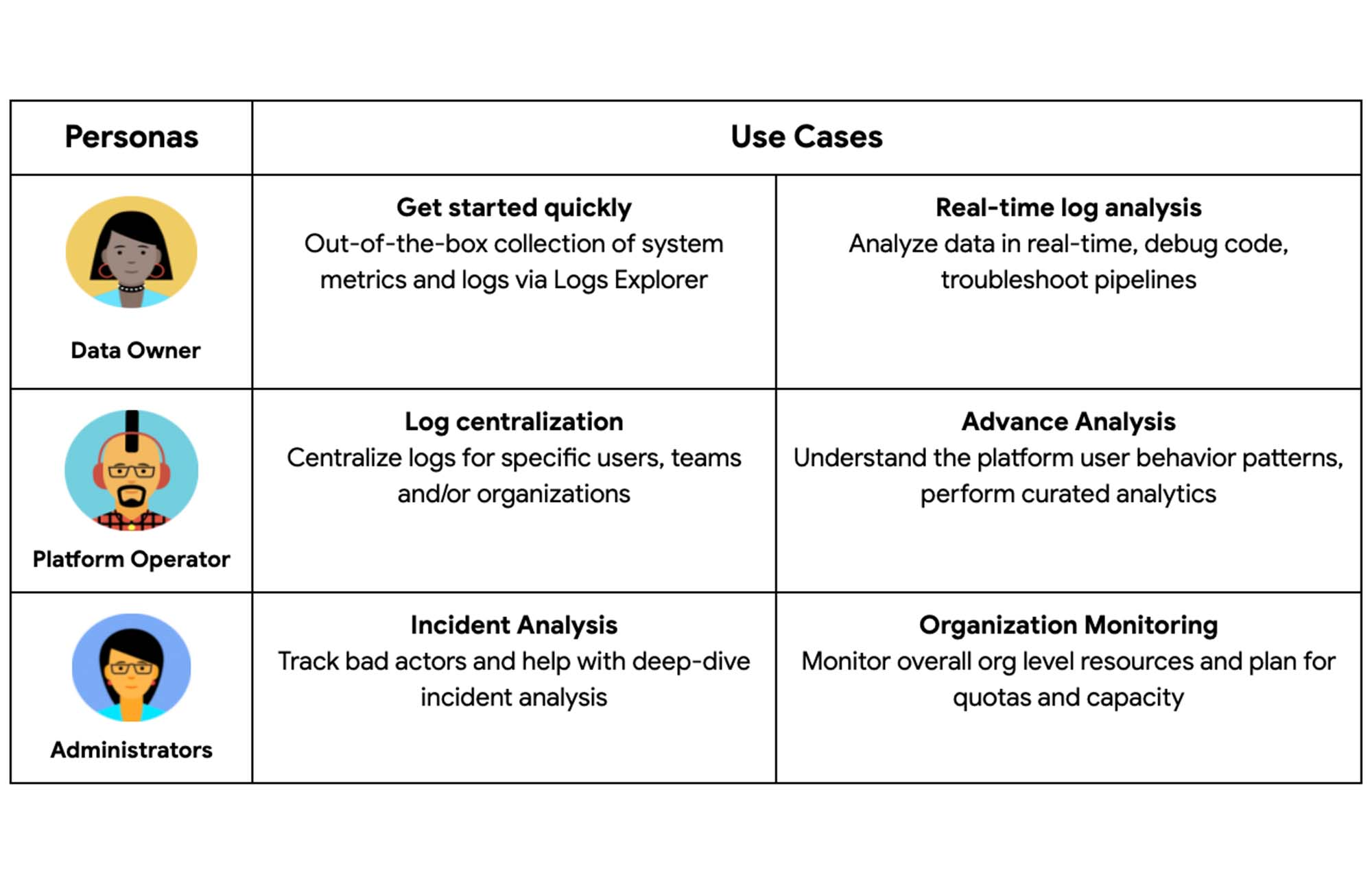
ペルソナとユースケース
ペルソナとユースケースは、BigQuery 監査ログを使用したモニタリングの分析要件とアクセスレベルを理解するために非常に重要です。以下は、一般的なペルソナとユースケースの一部です。
データオーナー / ユーザー - アプリケーションの開発と運用を行い、ソースデータを生成するシステムを管理します。このペルソナが関わるのは、ほとんどの場合、自分に固有のワークロードに限定されます。例: デベロッパー
プラットフォーム オペレーター - 多くの場合、社内の顧客に対応するプラットフォームを運用します。例: データ プラットフォーム リード
管理者 - セキュアな運用と、リソースの GCP フリートの健全性を主に管理します。例: SRE
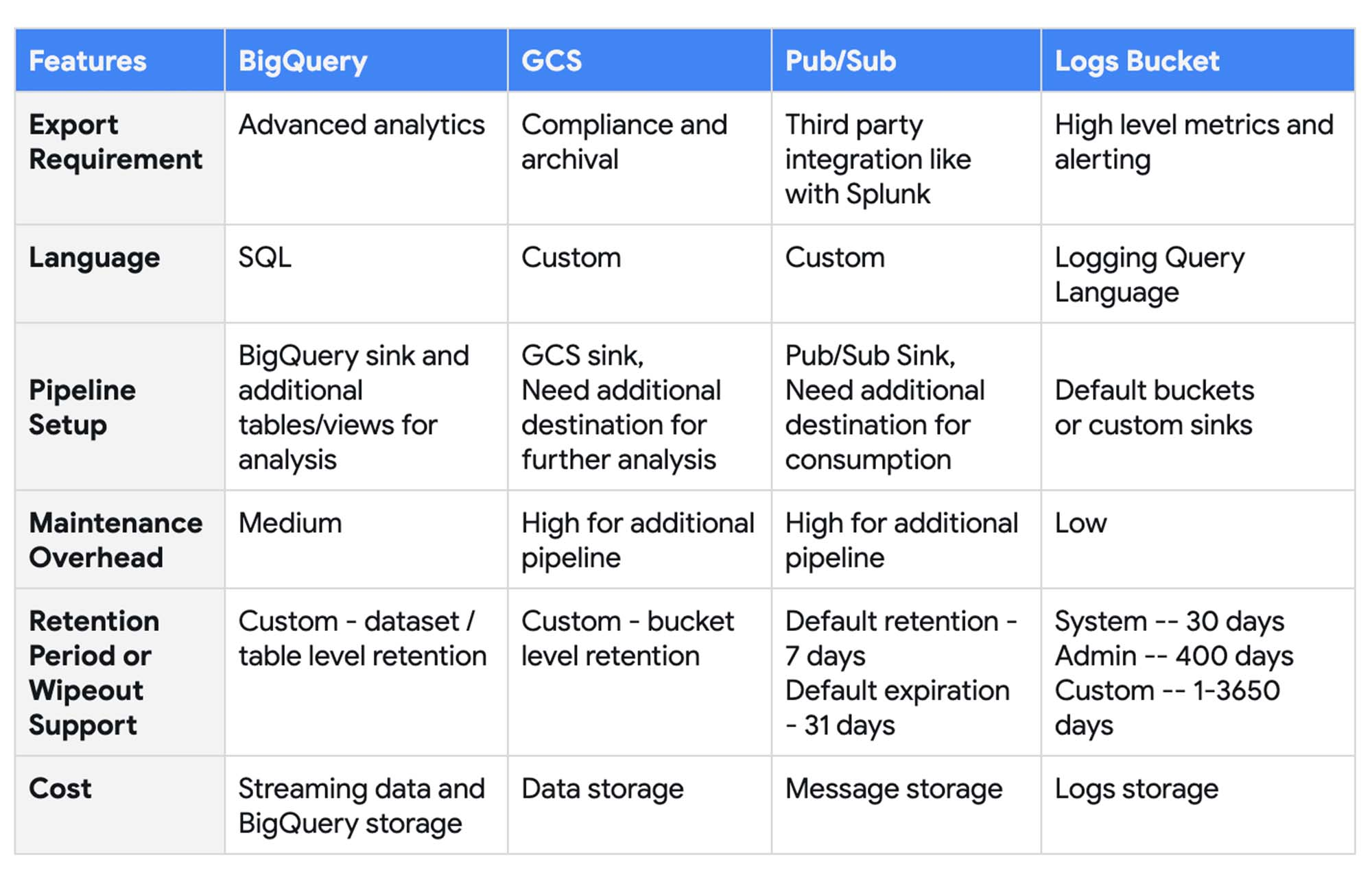
BigQuery 監査ログのエクスポート オプション
上記のペルソナとユースケースに対応するために、ログをログ エクスプローラ以外のさまざまな出力先にエクスポートできます。以下の出力先がサポートされています。
Cloud Storage - GCS バケットに保存される JSON 形式のファイル
BigQuery - BigQuery データセットに作成されるログテーブル
Pub/Sub - Pub/Sub トピックに配信される JSON メッセージ
ログバケット - Cloud Monitoring で詳細な分析が可能な JSON 形式のログ
モニタリング用に BigQuery のログの適切なエクスポート先を選択する際には、以下の項目を考慮します。
エクスポート要件 - 異なる出力先に応じたさまざまなユースケース
言語 - BigQuery 監査ログの分析に必要な言語のサポート
パイプライン設定 - エクスポート パイプラインの設定で使用できるオプション
メンテナンスのオーバーヘッド - エクスポート パイプラインの維持と管理に必要な作業
保持期間 / 消去サポート - データの保持と有効期限に関するポリシーのサポート
パイプラインの設定
集約シンクの使用
ほとんどの企業は、数多くのプロジェクトに取り組んでいるため、さまざまなログがまとまりなく増えていきます。プラットフォーム事業者や管理者の方には、管理プロジェクトを一元化し、集約シンクを使用して、監査ログを組織レベルでエクスポートすることをおすすめします。データオーナーの場合は、集約シンクを使用して、プロジェクト レベルのログをエクスポートすることもできます。
Logging サービス アカウント
Cloud Logging はデフォルトのサービス アカウントを使用して、ログデータをリアルタイムで作成およびエクスポートします。VPC Service Controls を使用している場合は、制約のためにこのサービス アカウントをアクセスレベルに追加してから、出力先のサービス境界に割り当てる必要があります。詳細については、VPC Service Controls: Cloud Logging をご覧ください。
エクスポート オプション
Logging のクエリ言語で記述されたさまざまなフィルタを使用してログをエクスポートしたり、さまざまな出力先を選択したりできます。以下のサンプル アーキテクチャ図では、さまざまなユースケースに応じて、ログ エクスポートを特定の出力先に設定しています。
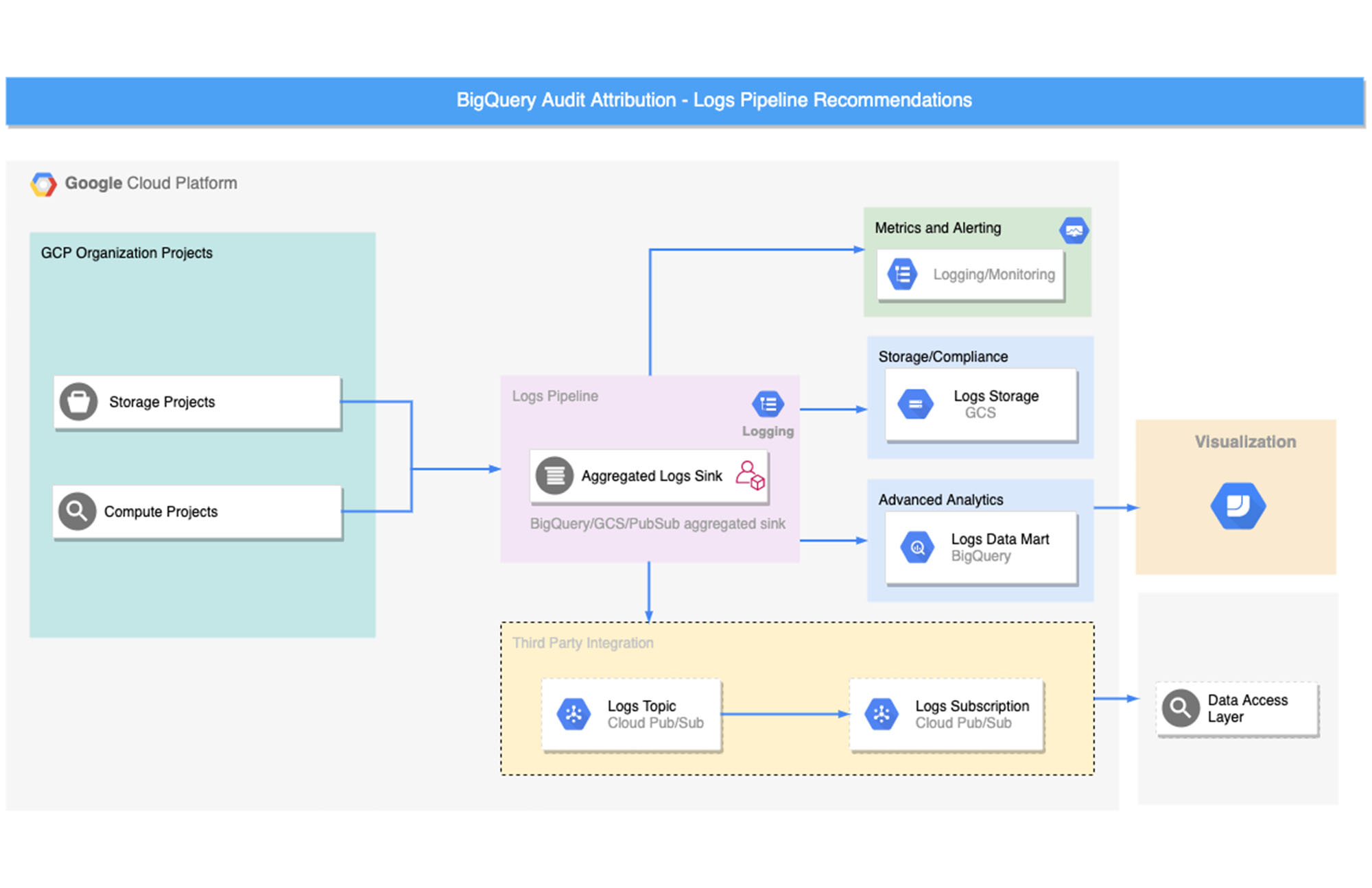
出力先ごとのパイプラインの設定手順を詳しく見ていきましょう。
BigQuery へのエクスポート
BigQuery へのエクスポートでは、読み込みジョブを使用する代わりに、ログデータが一度に 1 レコードずつ BigQuery にストリームされます。この方法では、データのクエリを BigQuery でほぼリアルタイムで実行でき、読み込みジョブの実行やデータ取り込みパイプラインのメンテナンスによる遅延が発生することはありません。
シンクを作成して、ログを BigQuery にエクスポートする場合は、日付別シャーディング テーブルまたはパーティション分割テーブルを使用できます。どちらのテーブルタイプも、ログエントリのタイムスタンプ フィールドに基づいてログデータを分割します。デフォルトでは、日付別シャーディング テーブルが選択されていますが、アクセスと管理が容易でパフォーマンスが高い、パーティション分割テーブルを使用する方法をおすすめします。
集約シンクを選択すると、対応するイベントタイプに応じて、BigQuery 内に以下の監査ログテーブルが作成されます。
cloudaudit_googleapis_com_system_event
cloudaudit_googleapis_com_policy
cloudaudit_googleapis_com_data_access
cloudaudit_googleapis_com_activity
設定手順
ステップ 1: 組織レベルで集約シンクを作成し、BigQuery シンクにログを転送する
その他のフィルタ:
ステップ 2: サービス アカウントにアクセス権を付与する
出力先の BigQuery データセットで、BigQuery データ編集者のロールをデフォルトの Logging サービス アカウントに付与します。
ステップ 3: 保持ポリシーを設定する
テーブルの作成時にパーティションの有効期限を設定して、ロギングのエクスポートに使用するストレージのサイズを制限します。
ステップ 4: 派生テーブルや派生ビューを作成して詳細な分析に活用する
以下は、アクセスを行ったユーザー、ユーザーがアクセスしたデータセット / テーブル / 列、ユーザーがアクセスにあたり持っていた権限の詳細を提供する SQL クエリの例です。
以下は、データセットの読み取り、作成、削除などのさまざまなデータセット アクティビティを行ったユーザーと、アクティビティの実行方法の詳細を提供するクエリの例です。
以下は、期限切れテーブルの詳細を提供するクエリの例です。
Google Cloud Storage へのエクスポート
Google Cloud Storage では、ログを低コストで長期保存できます。ログを Nearline または Coldline に移動してから削除すると、ログの維持に必要な運用コストを管理できます。これらのログをエクスポートして詳細な分析を行う場合は、JSON 形式のログファイルを BigQuery に読み込むか、GCS のログデータに対する外部テーブルを作成します。
設定手順
ステップ 1: 組織レベルで集約シンクを作成して、ログを GCS シンクに転送する
ステップ 2: サービス アカウントにアクセス権を付与する
バケットに書き込みを行えるよう、Logging のデフォルト サービス アカウントに Storage オブジェクト作成者のロールを付与します。
ステップ 3: 保持ポリシーを設定する
GCS でオブジェクトのライフサイクル管理を使用して保持ポリシーを構成します。
ステップ 4: 外部テーブル
GCS に保存された監査ログデータにクエリを行う必要がある場合、BigQuery で外部テーブルを使用すると、データをさらに詳細に確認できます。ただし、外部テーブルへのクエリは、ネイティブの BigQuery テーブルへのクエリよりパフォーマンスが低下します。
ステップ 4.1: 外部テーブルを作成する
ステップ 4.2: クエリ用のビューを作成する
Pub/Sub 経由のエクスポート
Pub/Sub シンクを使用して、ログを Cloud Logging から Splunk などのサードパーティ ツールにリアルタイムでエクスポートできます。Splunk を使用すると、オンプレミスとクラウドのデプロイメントから収集したログ、イベント、指標を検索、分析、可視化し、IT とセキュリティのモニタリングを行うことができます。また、Pub/Sub から BigQuery への Dataflow パイプラインを作成して変換と集約を行い、その結果を BigQuery に読み込んでデータ分析に使用できます。
設定手順
ステップ 1: 組織レベルで集約シンクを作成して、ログを Pub/Sub シンクに転送する
ステップ 2: サービス アカウントにアクセス権を付与する
トピックに対する Pub/Sub パブリッシャーのロールをデフォルトの Logging サービス アカウントに付与します。
ステップ 3: 作成したトピックからログメッセージを pull できるよう、サブスクリプションを設定する
コマンドラインを使用して、Pub/Sub サブスクリプション pull 経由でメッセージを pull します。または、簡単なサブスクライバーを実装することもできます。詳しくは、こちらのコードサンプルをご覧ください。
ステップ 4: サードパーティ統合の設定を行う
Dataflow を使用するか、Google Cloud Platform 用の Splunk アドオンでログを直接 pull して、ログメッセージを Splunk のようなサードパーティ製ツールに取り込むことができます。
Cloud Monitoring
Cloud Monitoring は、Cloud Logging および Cloud Monitoring フレームワークの一部です。ログバケットのログ情報は、Cloud Monitoring ワークスペースに自動的に同期され、概要分析に使用できます。また、大まかなログ指標やアラート機能を備えています。
ただし、高度な分析要件のためのカスタマイズはできません。また、Monitoring ワークスペースで、権限やアクセス制御レベルをきめ細かく構成することは困難です。
パイプラインの自動化
Terraform を使用すると、パイプライン設定手順の自動化、バージョン コントロール、管理を簡単に行えます。以下は、BigQuery に集約シンクを設定する Terraform スクリプトの例です。
次のステップ
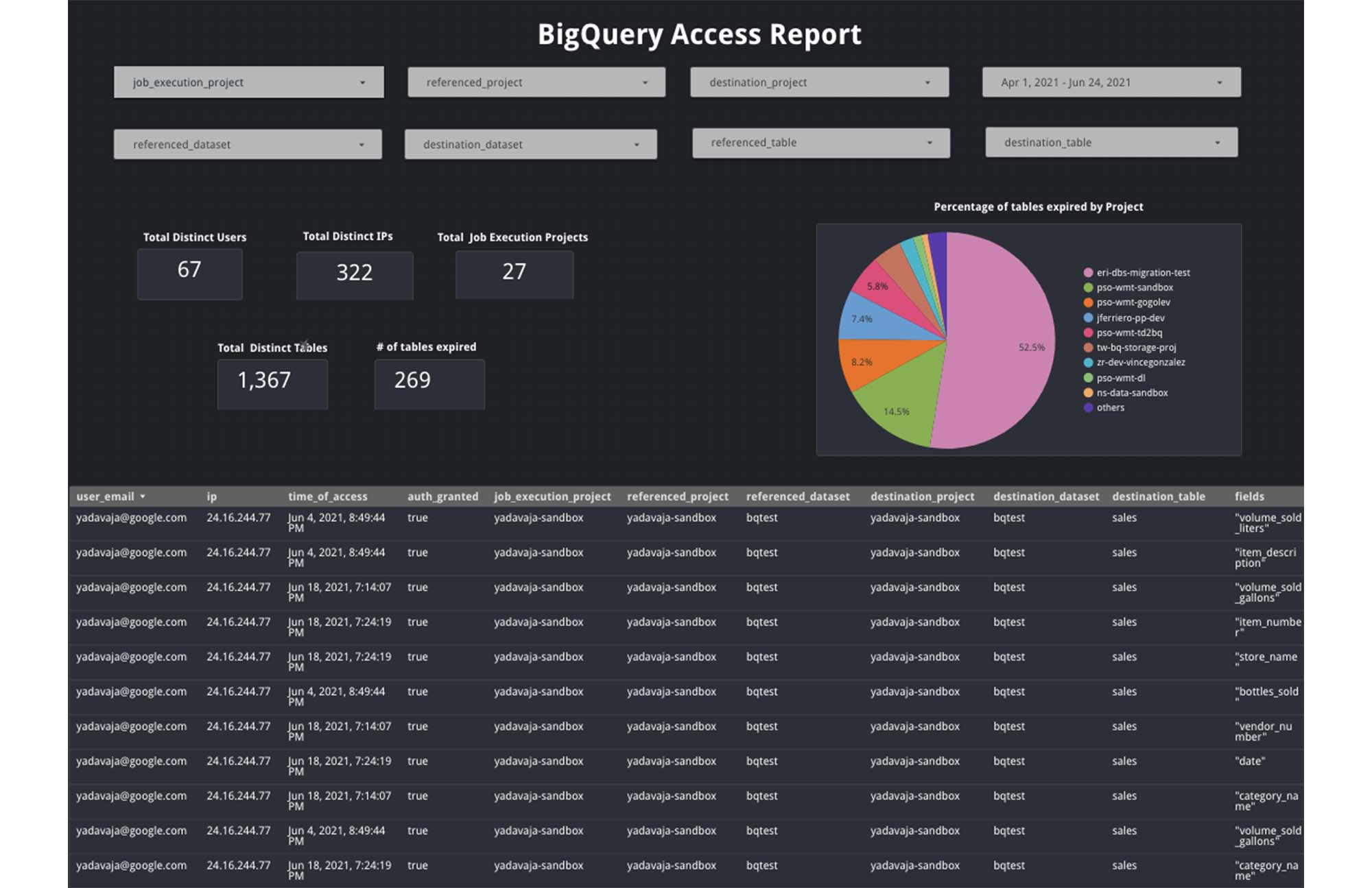
BigQuery シンク内の監査ログデータを活用し、データポータルや Looker で高度な分析ダッシュボードを作成できます。以下は、監査ログを使用して BigQuery をモニタリングするユースケースの例です。
プロジェクト オーナー向けアクセス レポート
プロジェクト オーナーにとって、プロジェクト内のどのデータセットに、いつ、誰がアクセスしたかといった情報は重要です。たとえば、特定のデータセットに、誰がどのロケーションからアクセスしているかという情報を得ることで、異常を特定して、アクセスに関する事象を積極的にレポートできます。データオーナー向け使用状況レポート
データオーナーにとって、プロジェクトのデータセットやテーブルの詳しい使用状況に関する情報は重要です。たとえば、特定のテーブル内のある列に対するアクセス頻度、アクセスしたユーザー、期限切れになるテーブル数といった情報を確認します。
以下は、データポータルを使用するサンプル ダッシュボードの例です。
こちらの GitHub リポジトリから、BigQuery 内のログの情報を照会する SQL スクリプトや、ログ エクスポート パイプラインの自動化全般に関する Terraform スクリプトをご覧ください。
- データ分析担当戦略クラウド エンジニア Vrishali Shah
- データ分析担当クラウド コンサルタント Namita Sharma




