GKE と Filestore により、AI / ML ワークロードのトレーニング時間を最大 37% 短縮
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
プロブレム ステートメントとユースケース
AI / ML ワークロードのトレーニングには多くのデータが必要で、しかもそれらのデータは多くの場合、多数の小さなファイルに分散して格納されています。たとえば、多数の画像データを使用して自動運転車をトレーニングする場合や、タンパク質分析を行う場合、トレーニング セットとして 100 KB~2 MB の小さなファイルが数多く使用されます。このようなユースケースでは、低レイテンシで高スループットの良好なパフォーマンスを手ごろな料金で提供する Google の Cloud Storage がツールとしてよく選ばれます。さらに、ポータビリティのためのファイル インターフェースとして FUSE が使用されることもあります。しかし、データセットが小さなファイルで構成されている場合、レイテンシが問題となります。トレーニング ワークロードでは、エポックあたり数万個にもおよぶ小さなファイルを使用し、複数のワーカーノードから Cloud Storage にアクセスすることもあります。
読み込み時間を短くするためには、このような状況でも低レイテンシで高スループットを実現するストレージが必要です。そこで、Filestore を「アクセラレータ」として使用することができます。Filestore は、高速アクセス可能なファイル ストレージを提供するとともに、複数の読み取り / 書き込みアクセスやネイティブな POSIX インターフェースといったメリットを備えています。Filestore をワーカーノードのための費用対効果が高く低レイテンシのデータアクセス手段として使用しつつ、メインのストレージ ソースとして引き続き Cloud Storage を使用することができます。
このブログ投稿では、AI / ML ワークロードのトレーニングにおいて Filestore が果たすことのできる重要な役割に焦点を当てて説明します。ワークロードのパフォーマンス向上を図るにあたり、十分な情報に基づき選択を行うためのお役に立てば幸いです。ペルソナや役割に応じてこのソリューションをどのように活用できるかご覧ください。
活用方法の詳細
以下のスクリーンショットは、AI / ML アプリケーションにおける GKE と Filestore の活用方法に焦点を当てて示しています。ソースコード全体については、こちらのリポジトリをご覧ください。
ペルソナ 1: データ サイエンティストが使用するために Filestore をステージングする Kubernetes プラットフォーム管理者
Kubernetes プラットフォーム管理者は、データ サイエンス チームが利用するインフラストラクチャ構築の役割を担います。この場合、プラットフォーム管理者は、Kubernetes 永続ボリュームを使用して Filestore をセットアップし、データ サイエンティストが Jupyter ノートブック環境、または複数のユーザーが存在する場合は JupyterHub を通してアクセスできるようにします。データ サイエンティストは、用意された環境でノートブックにアクセスしてコードを記述するだけです。
この例では、内部で動的に Filestore 基本 SSD インスタンスをプロビジョニングする、既製の premium-rwx GKE StorageClass を使用しています。Jupyter Pod の仕様では、GKE Filestore CSI ドライバを使用して、Filestore 共有を Pod にマウントする PersistentVolumeClaim(PVC)がプロビジョニングされています。マウントされたボリュームのパス(データおよびモデルのキャッシュ ディレクトリとなります)は、環境変数としてデータ サイエンティスト(ノートブック ユーザー)に公開されます。
スクリーンショット 1: Filestore ボリュームを使用した Tensorflow のデプロイ

スクリーンショット 2: Filestore 永続ボリューム クレーム

ペルソナ 2: Jupyter ノートブックからデータにアクセスするデータ サイエンティスト
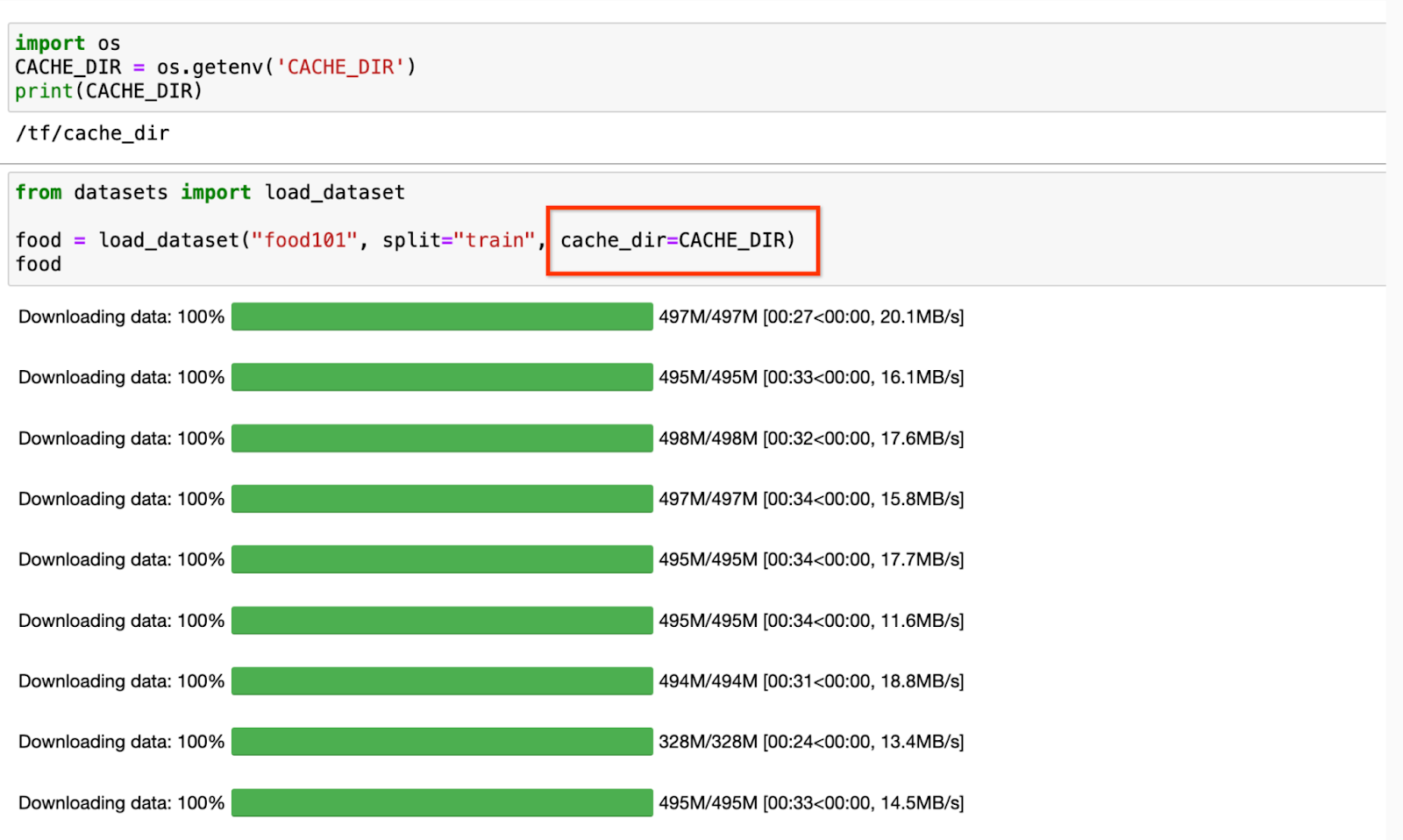
データ サイエンティストは、他の作業にわずらわされることなくテストの実施に集中できることを望んでいます。この例では、Google の Vision Transformer(ViT)モデルをトレーニングし、food101 データセットを Hugging Face から読み込みます。このデータセットは主に 10 万枚の画像で構成され、合計サイズは 5 GiB です。初回読み取りの後、ファイルシステム上のキャッシュにデータを自動的に保存する Hugging Face のキャッシュ機能を使用します。ファイルパスは、環境変数としてデータ サイエンティストのチームと共有する必要があります。Filestore のパスを環境変数として渡すことにより、データが Filestore 上のキャッシュに保存されます。データは、Cloud Storage から取得されるのではなくキャッシュに保存されるため、a2-highgpu-1g マシン上で 2 エポックのトレーニングを実施し、Cloud Storage から直接読み込んでトレーニングしたときの時間(ベースライン)と比較したところ、トレーニング時間を 37% 短縮することができました。
スクリーンショット 3: Hugging Face からデータセットを読み込み、キャッシュを有効化
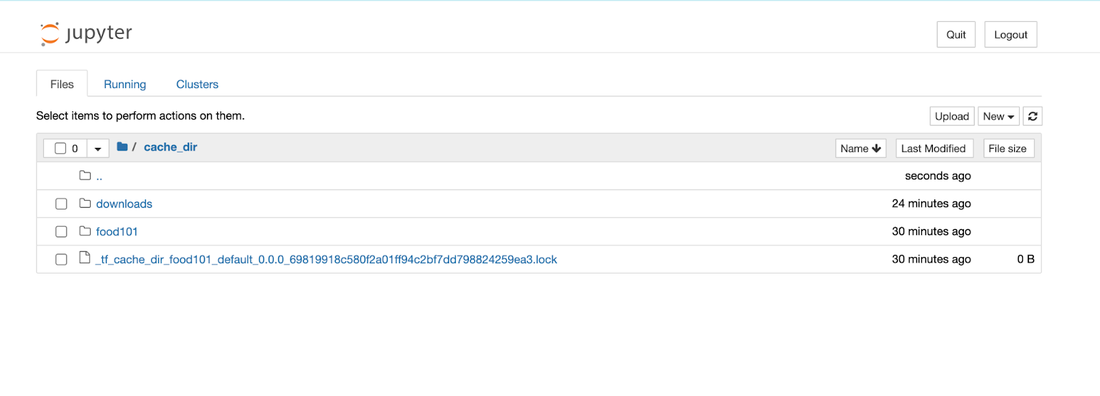
スクリーンショット 4: Jupyter ノートブック ファイル エクスプローラと、マウントされた Filestore ディレクトリ
スクリーンショット 5、6、7: モデルのダウンロード、トレーニングの開始、トレーニング時間の測定
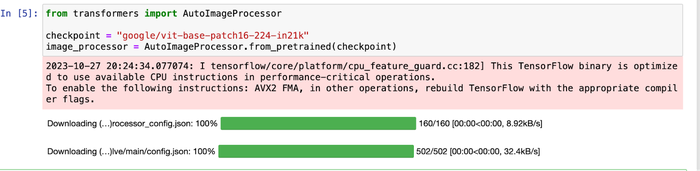
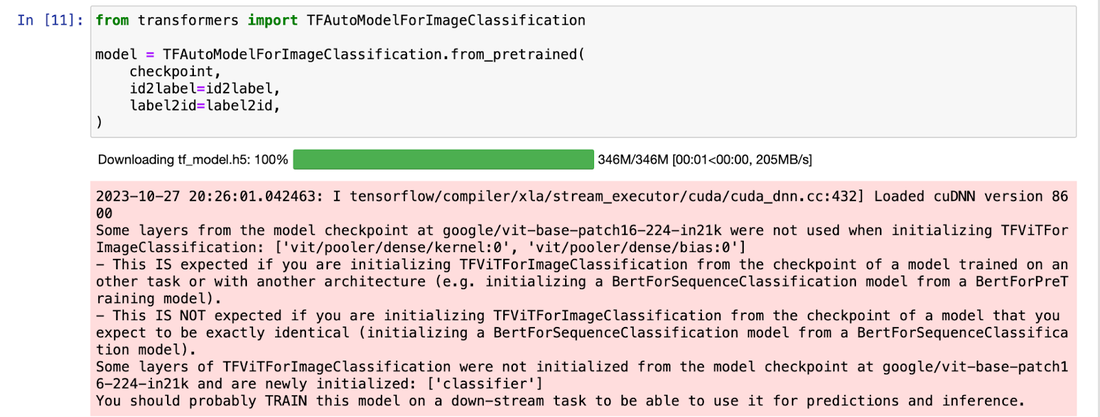
表 1. トレーニング結果
|
ストレージ オプション |
トレーニング時間(秒) |
改善 |
|
Cloud Storage |
4837 |
|
|
Filestore 基本 SSD(Filestore 高容量帯域のゾーンが望ましい) |
3006 |
37% |
活用に際しての考慮事項
このブログ記事では、特にデータセットが多数の小さなファイルで構成されている場合に、Cloud Storage の前面でアクセラレータとして Filestore を使用するメリットに焦点を当てて説明しました。Filestore インスタンスの料金が発生しますが、トレーニング時間を短縮でき、GPU リソース使用量を削減できるメリットを考慮すれば、ストレージの費用をかける価値が十分あります。ファイルのサイズが大きい場合は、Cloud Storage から直接データを読み込む方が適している可能性があります。ユースケースに応じて最適なアーキテクチャをお選びください。
-シニア ソフトウェア エンジニア Saikat Roychowdhury
-シニア プロダクト マネージャー Akshay Ram



