この先 10 年の AI 時代を見据えた Google Cloud のコンテナ プラットフォーム

Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
AI は、そこかしこで盛り上がりを見せています。この世界を形作る変革の最中で、Google Cloud のマネージド コンテナがきわめて重要な役割を今後担うことになるというのは喜ばしいことですが、これは必然であるとも感じています。また、AI アプリケーション開発の加速、AI ワークロードの効率性の改善に役立つ、Google のコンテナ プラットフォームに関する発表を共有できることを喜ばしく思います。AI によりもたらされるとされる価値を最大限に発揮して、同時にモダナイゼーションの取り組みを推進できるようになるはずです。
機会: AI とコンテナ
AI の先見者たちは可能性の限界を押し広げ、プラットフォーム ビルダーは自分たちのビジョンを目に見える現実のものとしています。成功への道筋は、これまで培ってきた専門性やインフラストラクチャをベースとして構築するべきであり、これまで培ったノウハウは捨てられるべきではありません。このような新しいワークロードがプラットフォームに要求するものは大きく、以下のような領域で要求に応える必要があります。
-
スピード: リーダーたちによって AI が検討される段階から導入される段階への移行が急速に進んでいます。製品化までの時間は、これまでにないほどに重要になっています。
-
スケール: 現代のシステムの多くは、スケーラビリティに関する特定の課題を念頭に置いて設計されていました。大規模なモデルを構築しているのであれ、特定のビジネスニーズに合わせて小規模なモデルのチューニングを検討しているのであれ、これまでとは考え方が大きく変わっています。
-
効率性の目標: AI は本質的に流動的です。モデルサイズの変更やハードウェア ニーズの変化などが発生するため、これに応じるようにトレーニングとサービングの費用やパフォーマンスに関しての考え方が変化しつつあります。企業は、詳細に計画、測定を行う必要があります。VM ごとの費用ではなく、トークンごとの費用を追跡する必要があります。測定を行い、こうした新しい要件に対応できるチームが、市場をけん引することになります。
コンテナで AI 独自のニーズを満たすことが可能
Google は、長年の歳月を要して培ったインサイト、ベスト プラクティスを Google Cloud のマネージド コンテナ プラットフォームに注ぎ込んでおり、破壊的テクノロジーの飛躍の難局をこれまでいくつも乗り越えてきました。そして、上記で説明した AI ワークロードが要求するものを考慮すると、Cloud Run および Google Kubernetes Engine(GKE)の 2 つのプラットフォームは、AI の機会をつかむためには理想的であると言えます。以下はその理由です。
-
インフラストラクチャの複雑さを軽減: インフラストラクチャがコンピューティングから GPU タイム シェアリング、TPU へと移行されるに従い、コンテナにより実現される新しい機能を既存のプラットフォームで使用できるようになりました。
-
ワークロードのオーケストレーション: ステートレス ワークロードの実行のみに用途が限られていた、コンテナ初期の時代から多くのことが変わっています。現代のコンテナは多種多様なワークロードに合わせて最適化されており、ユーザーおよびプラットフォーム ビルダーの両方に対して複雑さが隠蔽された状態になっています。Google は、Vertex AI などの独自の画期的 AI プロダクト向けに GKE を使用しており、Deepmind で次世代の AI イノベーションを実現しようとしています。
-
拡張機能のサポート: Kubernetes の拡張機能はその成功を後押ししてきたものであり、豊かなエコシステムの繁栄、ユーザーの選択肢のサポート、継続的なイノベーションの実現へとつながっています。このような特徴は、現代のユーザーが AI 時代に求める急速なイノベーションと柔軟性に対応しています。
Cloud Run と GKE は Google のプロダクトで役立てられているのみではありません。Anthropic、Assembly AI、Cohere、Salesforce などの大手の AI 企業の多くが Google のコンテナ プラットフォームを導入し、信頼性、セキュリティ、スケーラビリティを確保しています。
Google のマネージド コンテナ プラットフォームは、実装への移行をサポートする 3 つのアプローチを提供します。
-
AI プロジェクトを迅速に進めるためのソリューション
-
お客様の AI ワークロードを GKE にデプロイする機能
-
エンタープライズ デプロイ全体での Day 2(2 日目からの)運用の効率化
AI の取り組みの開始点として Cloud Run を活用
Cloud Run はこれまで、エンタープライズ グレードのセキュリティや可視性を犠牲にすることなく、迅速に開始し、プラットフォーム チームの運用上の負担を軽減し、スケーラブルでデプロイが容易なリソースをデベロッパーに提供するための優れたソリューションとして役立てられてきました。
このたび、Cloud Run アプリケーションを生成、変更、デプロイするために設計された、Cloud Run アプリケーション キャンバスをご紹介できることを喜ばしく思います。Vertex AI などのサービスにインテグレーション機能が追加され、Cloud Run サービスから数回のクリックを行うだけで Vertex AI の生成 API を簡単に利用できるようにプロセスが簡素化されました。Firestore、Memorystore、Cloud SQL とのインテグレーションもあり、ロード バランシングも利用できます。また、さらに機能強化を進め、クラウドチームによるアプリケーション ライフサイクルの設計、運用、最適化を支援する AI アシスタントとして機能する、Gemini Cloud Assist も統合しました。Cloud Run アプリケーション キャンバスの Gemini を使用してデプロイしたいアプリケーションの種類を自然言語で説明するだけで、Cloud Run が、そのリソースの作成や更新を数分で実行します。
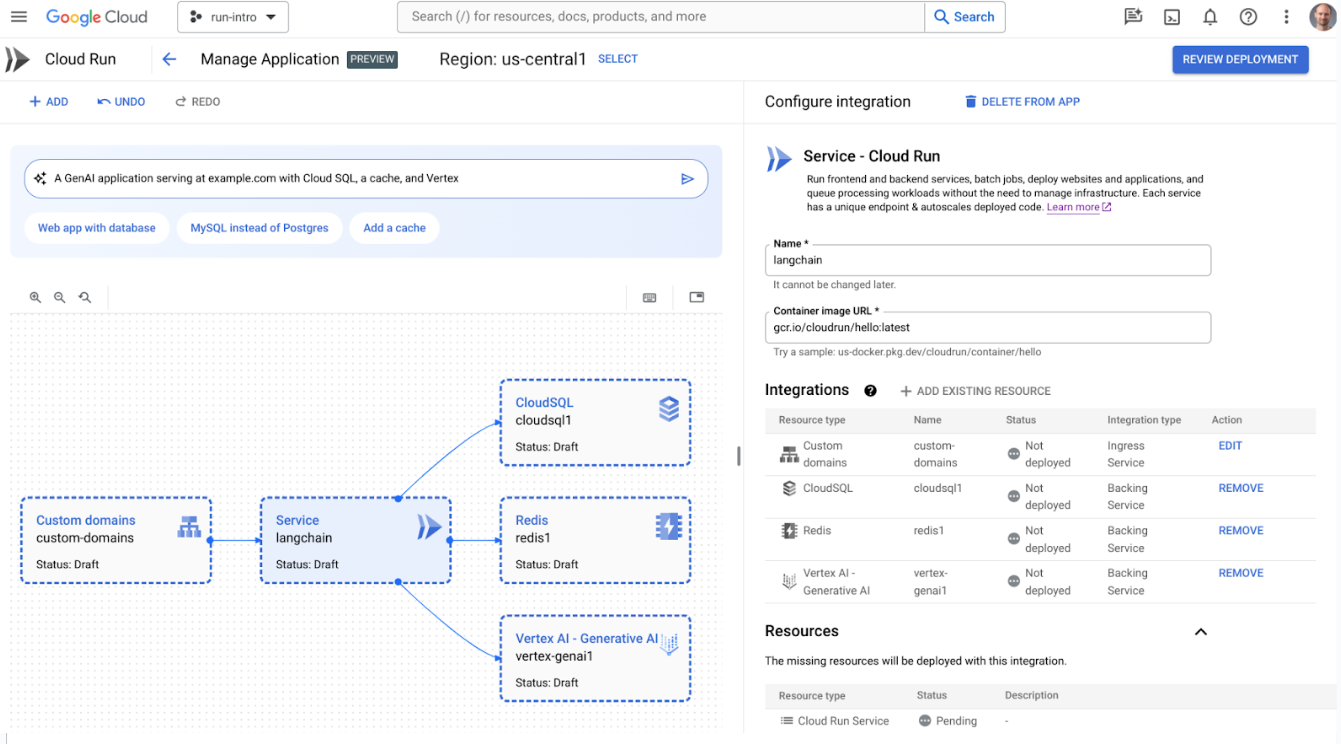
生成 AI アプリケーションを表示する Cloud Run のアプリケーション キャンバス
スピード、規模、効率性を達成できる Cloud Run は、AI ワークロードの構築に最適なオプションです。今回、AI アプリケーションの市場投入までにかかる時間をさらに短縮することを目的とした、LLM ベースのアプリケーション構築のための強力なオープンソース フレームワークである LangChain との Cloud Run の統合のサポートを発表できることを喜ばしく思います。Cloud Run は、LangChain アプリをデプロイ、スケーリングするための最も簡単な、デベロッパーにとって扱いやすい手段となるはずです。
「私たちは代替手段を調査しましたが、Cloud Run がアプリを本番環境で実行する最も簡単かつ最速の方法です。」- LangChain、創設者エンジニア、Nuno Campos 氏

LangChain アプリケーションを作成して Cloud Run にデプロイする
トレーニングと推論のための GKE
AI ワークロード用の、オープン、ポータブル、クラウドネイティブでカスタマイズ可能なプラットフォームを求めるお客様にとって、GKE は理想的です。AI の導入が飛躍的に進んでいることは、Google のプロダクトの利用方法にも反映されています。昨年は、Google Kubernetes Engine における GPU と TPU の使用量が 900% 以上伸びています。
Google は、AI を活用したビジネスの変革に取り組んでいるお客様のニーズにさらに応えるために、きわめて大規模な AI ワークロードのトレーニングとサービングを費用対効果の高いシームレスな手法で行うための、革新的ソリューションを構築しました。スケール、費用対効果、使いやすさの 3 つについて、それぞれの詳細を確認してみましょう。
大規模な AI ワークロード
最近の AI モデルの多くで優れた機能が実現されていますが、きわめて大規模なサイズを達成できていることがその要因のひとつになっています。AI モデルが大規模になるに従い、巨大な AI モデルのトレーニングとサービングを処理できるように構築されたプラットフォームが必要になってきます。Google は、GKE をお客様の大規模 AI モデルのための理想的な実行場所とするべく、アクセラレータ最適化ハードウェアの限界を押し広げることに取り組んでいます。
-
Cloud TPU v5p(12 月に発表、現在は一般提供)は、Google の現時点で最も強力でスケーラブルな TPU アクセラレータです。Google Cloud のお客様である Lightricks は GKE で TPU v5p を活用して、text-to-image および text-to-video のモデルのトレーニングで 2.5 倍ものスピードアップ(TPU v4 との比較)を実現しました。
-
A3 Mega(本日発表)では NVIDIA の H100 GPU が使用されており、GPU 間のネットワーキング帯域幅が A3 と比較して 2 倍になっています。これを利用することで、最大規模の AI モデルの GKE でのトレーニングにかかる時間を加速できます。A3 Mega は、今後数週間のうちに一般提供される予定です。
大規模な AI モデルをトレーニングするために、単一の物理 TPU をはるかに超えた規模にスケーリングする必要性が生じることがしばしばあります。Google は昨年、連続的なスケーリングを行えるようにすることを目的として、GKE のマルチスライス トレーニングを発表しました。これはすでに一般提供されており、フルスタックで費用対効果に優れた大規模トレーニングを行って、最大で数万単位の TPU チップを線形に近い形でスケールアップできます。Google は、50,000 以上の数の TPU v5e チップを使用しての単一の AI モデルのトレーニングを、理想に近いスケーリング パフォーマンスを維持しつつ行うことが可能であることを実際に確認しています。
費用対効果に優れた AI ワークロード
AI モデルの成長に応じて、ユーザーは費用対効果に優れた手法でのスケーリングに関する多くの課題に直面することになります。たとえば、AI コンテナ イメージは巨大になることがあり、その場合はコールド スタートに時間を要することになります。AI 推論のレイテンシを低く抑えるためには、想定外の負荷に対応する目的でオーバープロビジョニングを行う必要性が生じます。コールド スタートに時間がかかる場合には、オーバープロビジョニングをさらに行いこれを補う必要があります。このようなものはすべて、利用不足や不必要な費用につながります。
GKE でコンテナとモデルのプリロードがサポートされるようになり、ワークロードのコールド スタートにかかる時間を短縮できるようになりました。これにより、AI 推論のレイテンシを低く抑えつつ、GPU 使用率を改善して費用を削減することが可能になります。GKE ノードプールの作成時に、コンテナ イメージやモデルデータを新しいノードでプリロードできるようになったため、ワークロード デプロイ、自動スケーリング、メンテナンス イベントなどに伴う停止からの復元をより迅速に実行できます。GKE 上に構築された Vertex AI の予測サービスの場合で、コンテナのプリロードでコンテナの起動時間が大幅に短縮されることがわかっています。
「Vertex AI の予測サービス内のコンテナ イメージには、その規模がきわめて大規模になるものがあります。GKE コンテナ イメージのプリロードを有効にした後のテストでは、16GB のコンテナ イメージを最大で 29 倍の速度で pull することができました。」 – Vertex AI、ソフトウェア エンジニア、Shawn Ma 氏
ボリュームが少ない推論やノートブックなど、需要の変動がきわめて激しい AI ワークロードの場合、ほとんどの時間帯で GPU がアイドル状態になってしまう可能性があります。同一の GPU でさらに多くのワークロードを実行できるようにするために、GKE で NVIDIA Multi-Process Service(MPS)との GPU 共有がサポートされるようになりました。MPS を利用することで単一の GPU 上での同時処理を行えるようになり、GPU リソースの使用率が低いワークロードに使用することによる GPU の効率性の向上と費用の削減につなげることができます。
モデル トレーニング時に AI アクセラレータの費用対効果を最大限に高めるには、データ取得のためにアプリケーションが待機する時間を最低限に抑えることが重要です。GKE では、これを達成するための GCS FUSE 読み取りキャッシュのサポートが一般提供されました。GCS FUSE 読み取りキャッシュはローカル ディレクトリをキャッシュとして使用して、小規模でランダムな I/O の繰り返しを迅速に読み取って、データの読み込みを加速することで GPU と TPU の使用率を増加させます。これによりモデルのトレーニング時間が短縮され、最大で 11 倍のスループットを実現できます。
AI ワークロードの使いやすさ
GKE であれば、AI の規模と費用対効果の実現を簡単に達成できるはずです。GKE の Dynamic Workload Scheduler を使用して AI トレーニング ワークロード用の GPU の取得を簡単に行うことが可能であり、これは、Two Sigma のようなお客様に変革をもたらしています。
「Dynamic Workload Scheduler のおかげでオンデマンド GPU の取得可能性が 80% 向上し、研究者らによるテストのイテレーションのスピードアップにつながりました。組み込みの Kueue と GKE のインテグレーションを活用することで、Dynamic Workload Scheduler で新しい GPU の容量を迅速に活用できるようになり、これまで開発作業に要していた数か月単位の時間を節約することができました。」 – Two Sigma、ソフトウェア エンジニア Alex Hays 氏
フルマネージド運用モードの Kubernetes を必要とするお客様向けに、GKE Autopilot で NVIDIA H100 GPU、TPU、予約、Compute Engine 確約利用割引(CUD)がサポートされるようになりました。
これまでは、GPU を使用するためにノードごとに GPU ドライバをインストールしてドライバを管理する必要がありました。ですが、GKE で GPU ドライバのインストールと管理が自動的に行われるようになったため、これまでにないほどに簡単に GPU を使用できるようになりました。
将来を見据えたエンタープライズ プラットフォーム
Google Cloud のマネージド コンテナ プラットフォームを活用して AI ワークロードの取り組みを開始し、スケールアップすることができます。ただ、AI ワークロードは戦略的優先事項ではあるものの、重要度の高い管理および運用上の作業というのは、どのようなエンタープライズ環境でも依然として存在します。Google が、現代のあらゆるエンタープライズ ワークロードをサポートする革新的機能をリリースすることに継続的に取り組んでいるのはそのためです。
これは、AI を Google のクラウドに直接組み込むことから始まります。Gemini Cloud Assist を活用することで、以下のように Day 2(2 日目からの)運用を強化できます。
-
費用の最適化: Gemini は、実行されたままになっている開発 / テスト環境、テストで忘れ去られたクラスタ、過剰なリソースを持つクラスタの特定や対応に役立てることができます。
-
トラブルシューティング: Cloud Logging のログの解釈を自然言語で確認できます。
-
合成モニタリング: 自然言語を使用して、テストしたいターゲットとユーザー ジャーニー フローを説明できるようになりました。Gemini により生成されるカスタムのテスト スクリプトをデプロイしたり、必要に応じてさらに構成したりできます。
また、Gemini Cloud Assist が役立てられるのは Day 2(2 日目からの)運用だけではありません。3 層アーキテクチャ アプリのデプロイや Terraform スクリプトの解釈などもサポートされているため、設計とデプロイを大幅に簡素化できます。
AI によりもたらされる新たな可能性は魅力的です。ただ Google は、現代のエンタープライズに役立てられるコンテナ プラットフォームに不可欠な要素に取り組むという姿勢を忘れたわけではありません。クラウドネイティブ アプリケーションの安定性、セキュリティ、コンプライアンスの維持に不可欠な基礎的領域に対する取り組みに引き続き力を入れています。また、以下のプレビュー リリースをご紹介できることも喜ばしく感じています。
-
GKE Threat Detection。一般的なコンテナ ランタイム攻撃の検出、不審なコードの分析を行います。また、自然言語処理を使用して悪意のあるスクリプトを特定することも可能です。これらはすべて Security Command Center と統合されており、セキュリティに対する包括的で一貫性のあるアプローチを実現できます。
-
GKE compliance。フルマネージドのコンプライアンス サービスです。クラスタからコンテナまでのエンドツーエンドの範囲を自動でカバーして、最も重要なベンチマークと照らし合わせてのコンプライアンスのスキャンを実行します。準リアルタイムの分析情報を一元化されたダッシュボードでいつでも確認することが可能で、コンプライアンス レポートは自動的に作成されます。
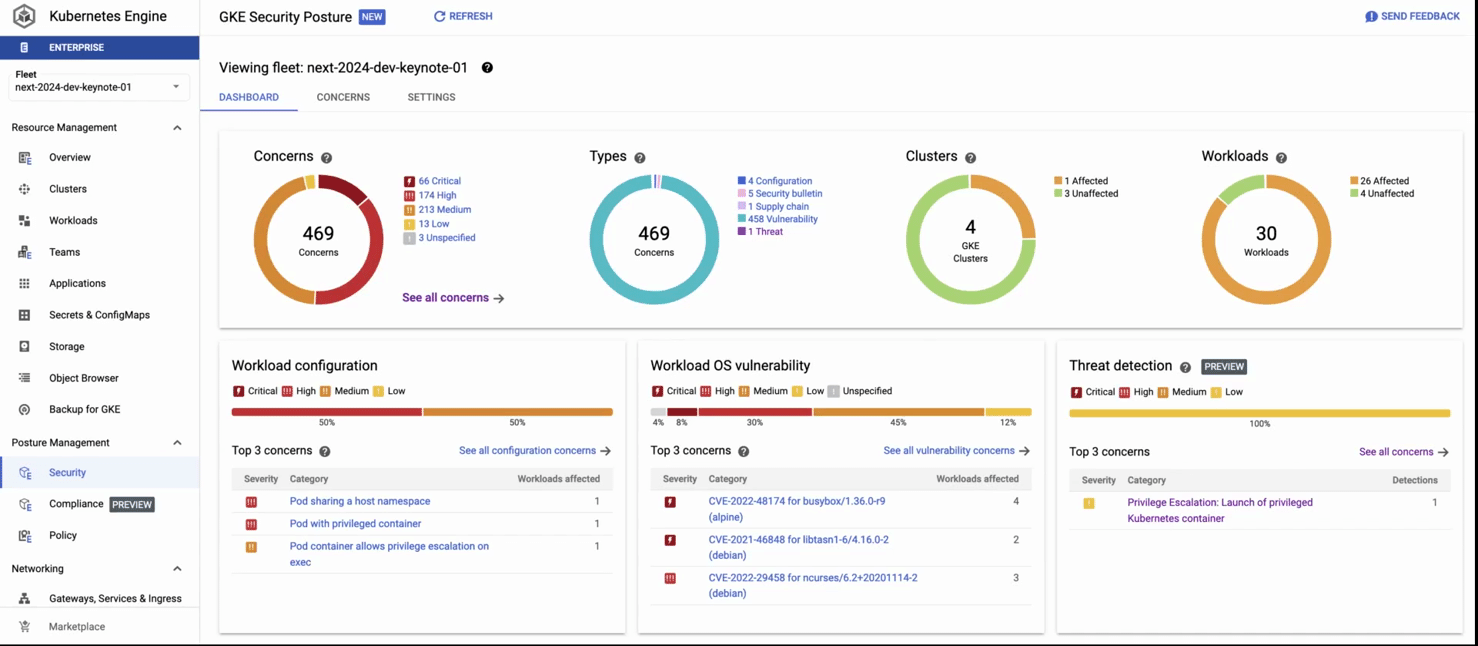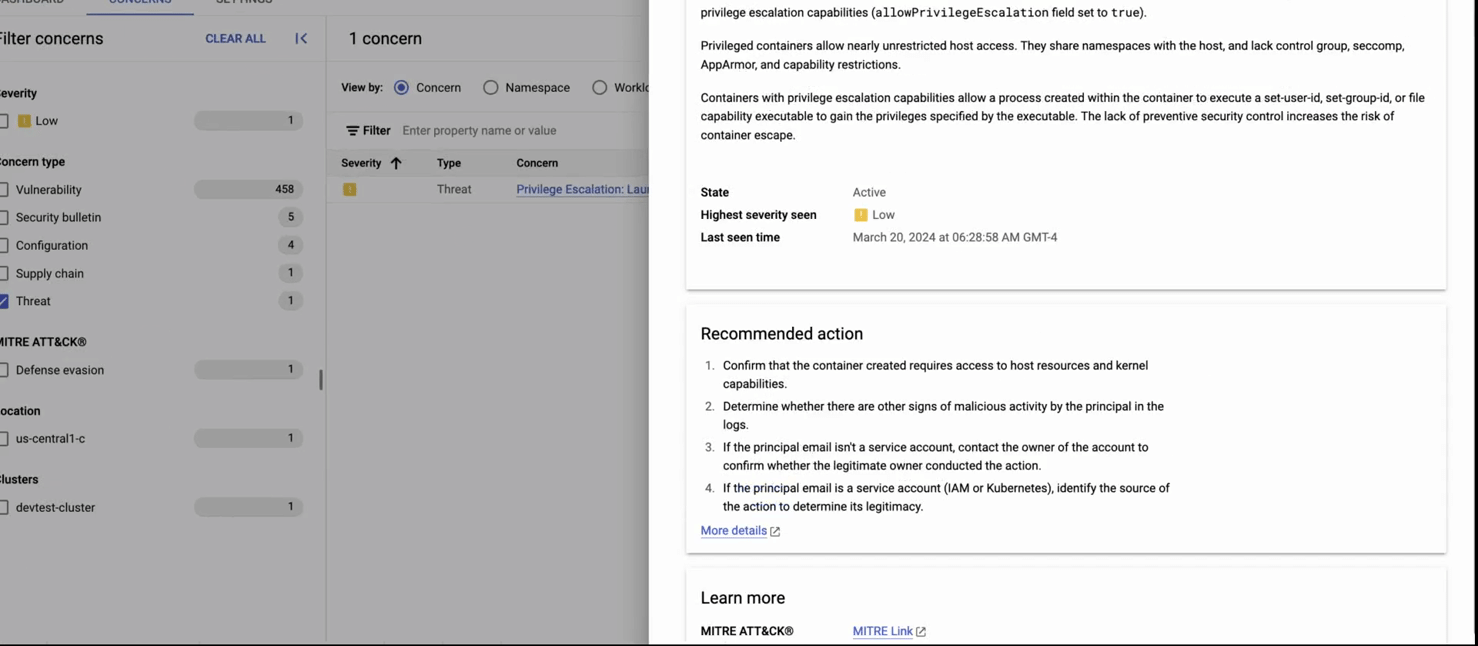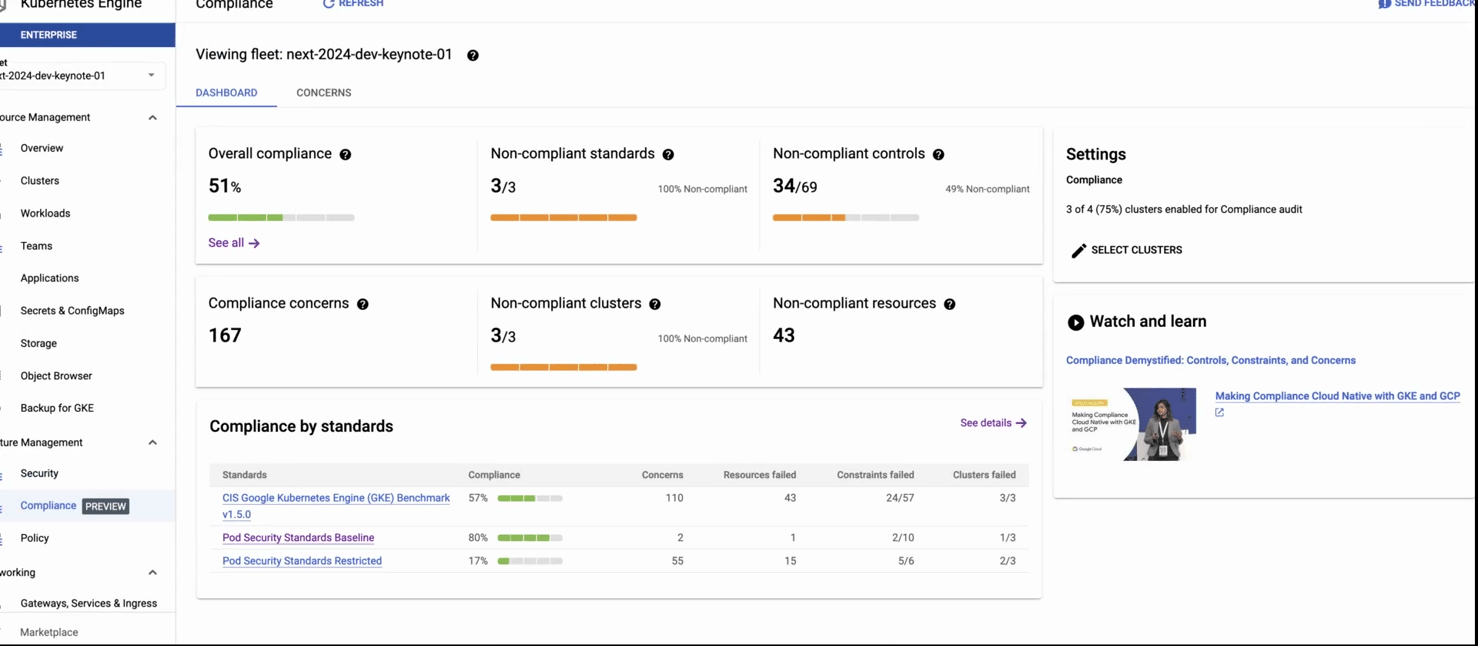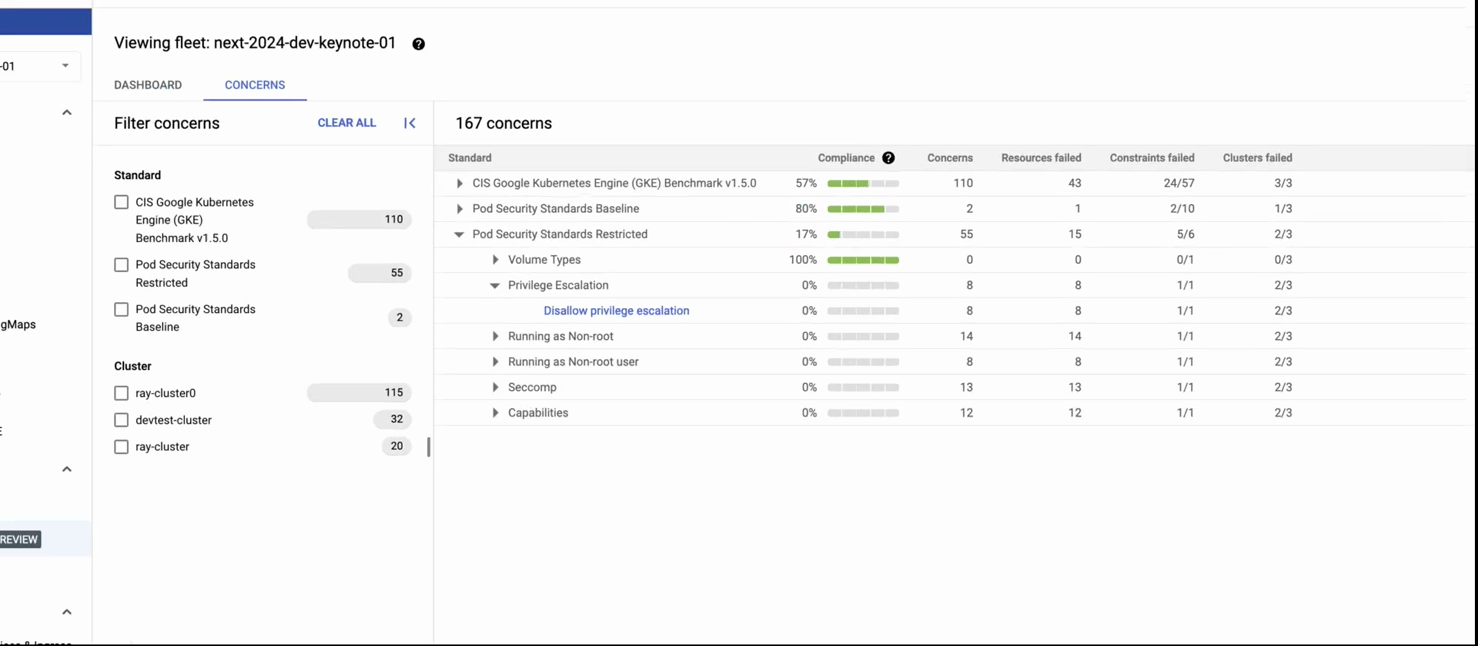
このレコードでは次の内容が示されています。1)GKE セキュリティ ポスチャー ダッシュボード、2)脅威検出パネルをクリック、3)検出された驚異(特権コンテナを含む Pod の作成)に関する詳細を取得。レコードの 2 番目のパートで、4)コンプライアンス ダッシュボードに移動して、業界標準に照らし合わせた包括的なコンプライアンス評価を表示。その後に 5)[concerns] タブをクリックして詳細なレポートを標準ごとに表示。6)最後に、コンプライアンス制約(チェック)の失敗(この場合は権限昇格)および推奨される修復の詳細を表示。
さっそく始めましょう
AI 時代の到来に伴い、緊急で対応すべき事項がテクノロジーのあらゆる側面に表れ始めています。そして、データ サイエンティスト、研究者、エンジニア、デベロッパーは、適切なリソースを与えてくれるプラットフォーム ビルダーを求めています。Google は、既存のエンタープライズにシームレスにフィットする、スケーラブルで効率性の高い安全なコンテナ リソースを提供し、お客様の成功に役立てられるようにしています。開始にあたって、3 つの手段を用意しています。
-
Google Cloud で最初の AI アプリケーションの構築に取り組むのであれば、Cloud Run と Vertex AI を試してみてください。
-
AI モデルのサービングを行う方法を学習するのであれば、Hugging Face TGI、vLLM、TensorRT-LLM を使用した Google の軽量オープンモデル ファミリーの Gemma のサービングを開始してみてください。
-
Ray などのオープンモデルや AI エコシステムの統合で検索拡張生成(RAG)パターンを使用して GKE AI を試す準備ができていれば、GKE クイック スタート ソリューションを試してみてください。
Google Container Engine がリリースされた 2015 年から、Google Cloud は、コンテナ型ワークロードを実行するための最も適した場所としての立ち位置を確立してきました。2024 年は、6 月に 10 周年を迎えるオープンソースの Kubernetes にとって節目の年となります。大きな成功に貢献してくれたコミュニティの方々に、敬意を表したいと思います。Cloud Native Computing Foundation(CNCF)によると、このプロジェクトでは 74,000 を超えるコントリビューターによって 314,000 を超えるコードが commit されています。コードを提供する組織の数もこの 10 年で増加し、その数は 1 から始まり今では 7,800 以上となっています。このようなコントリビューションのおかげで、また、Google Cloud のマネージド コンテナ プラットフォームが提供するエンタープライズ スケール、運用能力、アクセシビリティのおかげで、多くの組織にとってのコンテナと Kubernetes の有用性は継続的に拡大されてきました。将来の AI 時代に向けて、皆様と今後協力して構築に取り組めることを喜ばしく思います。
-GM & VP, Cloud Runtimes, Chen Goldberg
