Google Cloud の AI ハイパーコンピューター アーキテクチャの新機能

Google Cloud Japan Team
※この投稿は、2024 年 4 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
AI の進歩が、これまで不可能と考えられていたユースケースを可能にしています。より大規模で複雑な AI モデルは、テキスト、コード、画像、動画、音声、音楽を含むあらゆるアプリケーションで強力な機能を実現しています。その結果、人間の潜在能力と生産性を高める可能性を秘めた AI の活用は世界中の企業や組織にとって不可欠なイノベーションとなっています。
しかし、これらの優れたユースケースを支える AI ワークロードは、基盤となるコンピューティング、ネットワーク、ストレージのインフラストラクチャに信じられないほどの要求を課します。これはアーキテクチャの 1 つの側面にすぎず、お客様は、オープンソースのソフトウェア、フレームワーク、データ プラットフォームを統合しながら、リソース消費を最適化して AI の力をコスト効率よく活用するという課題にも直面しています。従来は、コンポーネント レベルの機能拡張を手動で組み合わせる必要があり、非効率さやボトルネックが発生する可能性がありました。
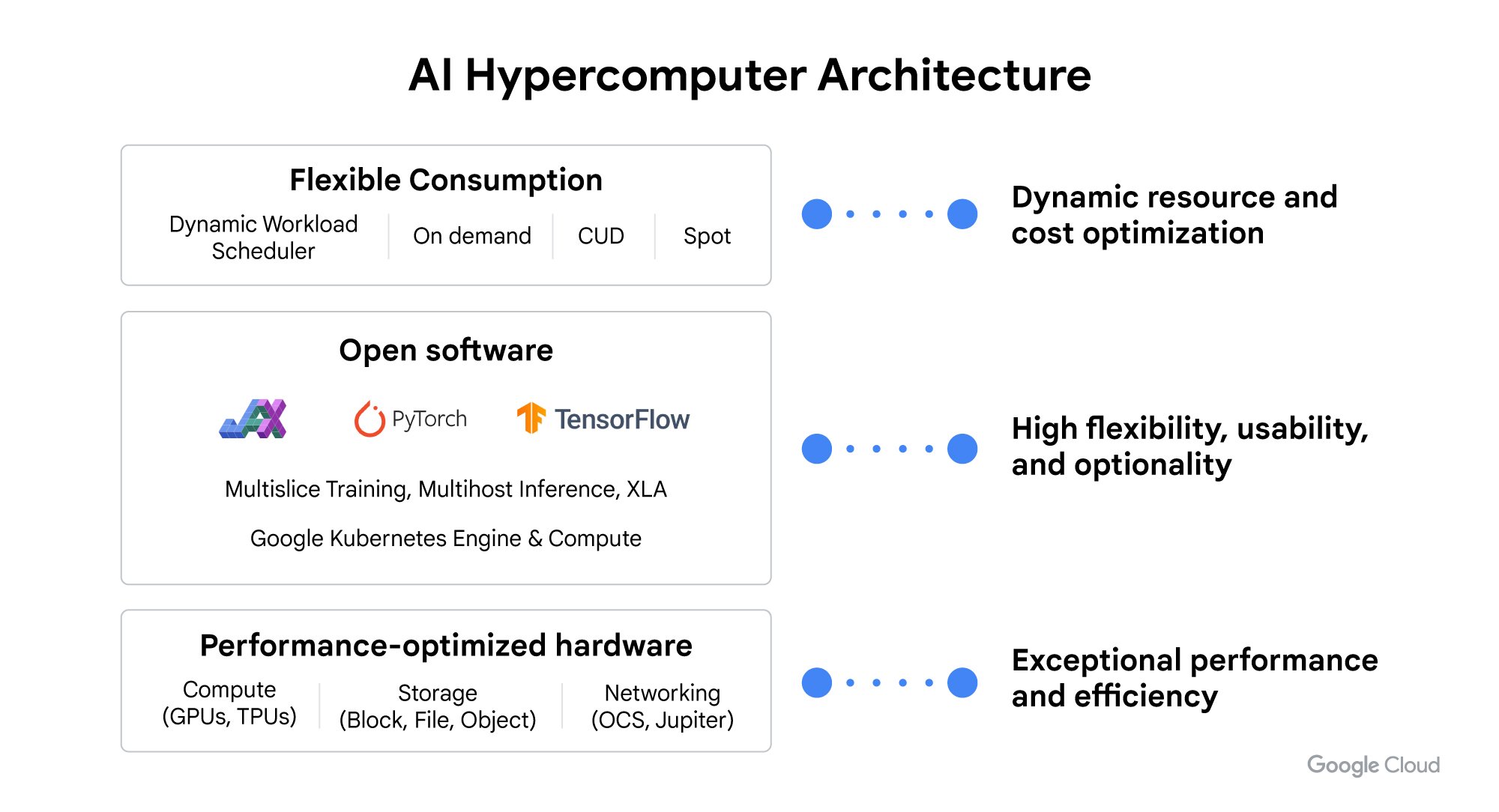
そのため、本日、AI ハイパーコンピューター アーキテクチャのあらゆるレイヤーにおける大幅な機能強化を発表します。このシステム レベルのアプローチにより、パフォーマンスが最適化されたハードウェア、オープン ソフトウェアとフレームワーク、柔軟な消費モデルを組み合わせて、システム全体がより高いパフォーマンスと効率で実行され、生成されたモデルがより効率的に提供されるため、開発者と企業の生産性が向上します。
実際、2024 年 3 月に Google は Forrester Research の「The Forrester Wave: AI Infrastructure Solutions, Q1 2024」1においてリーダーの 1 社に選出されました。同レポートの「現在のサービス」と「戦略」のどちらのカテゴリにおいても、評価対象となった全ベンダーの中で最高スコアを獲得しました。
本日の発表は、AI ハイパーコンピューター アーキテクチャのあらゆるレイヤーに及びます。
-
パフォーマンスが最適化されたハードウェアの機能強化:Cloud TPU v5p の一般提供や、強化されたネットワーキング機能とより高いパフォーマンスを備えた大規模トレーニング向け NVIDIA H100 Tensor Core GPU を搭載した A3 Mega VM が含まれます。
-
AI ワークロード向けのストレージ ポートフォリオの最適化:AI 推論 / サービング ワークロード向けに最適化された新しいブロック ストレージ サービスである Hyperdisk ML 、トレーニングと推論のスループットとレイテンシを改善する Cloud Storage FUSE、Parallelstore の新しいキャッシュ機能が含まれます。
-
オープンソフトウェアの進歩:Gemma 7B などのオープン モデルで 1 米ドル当たりのパフォーマンスを向上させる大規模言語モデル (LLM) 向けのスループットとメモリ最適化の推論エンジンであるJetStream の導入が含まれます。また、JAX および PyTorch/XLA リリースにより、Cloud TPU と NVIDIA GPU の両方でパフォーマンスを向上させます。
-
Dynamic Workload Scheduler による新しい柔軟な GPU リソースの活用: 開始時刻を保証するカレンダー モードや経済性を最適化するフレックス スタート モードが含まれます。
AI ハイパーコンピューターの詳細については、Google Cloud のデータセンターのビデオをご覧ください。

パフォーマンスが最適化されたハードウェアの進歩
Cloud TPU v5p GA
これまでで最も強力でスケーラブルな TPU である Cloud TPU v5p の一般提供を発表しました。TPU v5p は、最大規模で最も要求の厳しい生成 AI モデルのトレーニングに特化して構築された次世代アクセラレータです。1 つの TPU v5p ポッドでは、TPU v4 ポッドのチップの 2 倍以上の 8,960 個のチップが同時に実行されます。TPU v5p は、大きなスケールであるだけでなく、チップごとに 2 倍以上の FLOPS と 3 倍以上の高帯域幅メモリも提供します。また、お客様がより大きなスライスを使用することでスループットがほぼ直線的に向上します。スライス サイズが 12 倍(512 チップから 6144 チップへ)増加した場合、11.97 倍のスループットを達成します。
TPU v5p における包括的な GKE サポート
大規模な TPU クラスタ全体で、GKE 最大の AI モデルのトレーニングとサービングを可能にするために、本日、Google Kubernetes Engine (GKE) の Cloud TPU v5p サポートと GKE での TPU マルチホスト サービスの一般提供も開始したことを発表しました。GKE で TPU マルチホストを使用すると、複数のホストにデプロイされたモデル サーバーのグループを 1 つの論理ユニットとして管理でき、一元的な管理およびモニタリングが可能になります。
「Lightricks は Google Kubernetes Engine (GKE) で Google Cloud の TPU v5p を活用し、テキストから画像およびテキストから動画へのモデルのトレーニングにおいて、TPU v4 と比較して 2.5 倍の高速化を達成しました。GKE により、パフォーマンスの向上が必要な特定のトレーニング ジョブに TPU v5p をスムーズに活用できるようになります。」- Lightricks、コア生成 AI 研究チーム リード、PhD Yoav HaCohen 氏
A3 Mega の一般提供 と Confidential Computing で NVIDIA H100 GPU 機能を拡張
A3 VM ファミリーに A3 Mega が加わり、NVIDIA GPU 機能も拡張されます。NVIDIA H100 Tensor Core GPU を搭載した A3 Mega は 2024 年 5 月に一般提供予定で、従来の A3 VM の 2 倍の GPU 間ネットワーキング帯域幅を実現します。Confidential Computing は、2024 年後半にプレビュー版を A3 VM ファミリーに導入予定です。A3 VM ファミリーで Confidential Computing を有効にすることで、機密データと AI ワークロードの機密性と整合性を保護し、不正アクセスを軽減します。また、A3 VM ファミリーで Confidential Computing を有効にすると、コードを変更する必要なく保護された PCIe を介して Intel TDX 対応 CPU と NVIDIA H100 GPU 間のデータ転送が暗号化されます。
NVIDIA Blackwell GPU を Google Cloud に導入
先日、NVIDIA の最新 Blackwell プラットフォームを 2 つの構成で AI ハイパーコンピューター アーキテクチャに導入することを発表しました。Google Cloud のお客様は、NVIDIA HGX B200 GPU と GB200 NVL72 GPU の両方を搭載した VM にアクセスできるようになります。HGX B200 GPUを搭載した新しい VMは、最も要求の厳しい AI、データ分析、HPC ワークロード向けに設計されており、水冷 GB200 NVL72 GPU を搭載した VM は、リアルタイムの LLM 推論と 1 兆個のパラメータ スケール モデルに対する大規模なトレーニング パフォーマンスでコンピューティングの新時代をサポートします。
Google Cloud TPU と GPU ベースのサービスを活用しているお客様
Character.AI は、さまざまなキャラクターを簡単に作成して操作できる、消費者向けの強力な AI コンピューティング プラットフォームです。急速に成長するコミュニティのニーズを満たすために、GPU および TPU ベースのインフラストラクチャ全体で Google Cloud の AI ハイパーコンピューター アーキテクチャを採用しています。
「Character.AI は、Google Cloud の Tensor Processor Unit (TPU) と、NVIDIA H100 Tensor Core GPU 上で実行される A3 VM を使用して、LLM のトレーニングと推論をより高速かつ効率的に行っています。当社のサービスを利用する数百万人のユーザーに新しい機能を提供すべくスケールする際、強力な AI ファースト インフラストラクチャ上で実行される GPU と TPU の選択肢により、Google Cloud が最適な選択肢となっています。現在、H100 GPU を搭載した Google Cloud TPU v5e や A3 VM など、AI 環境全体において次世代アクセラレータのイノベーションが起きています。これらのプラットフォームはそれぞれ、前世代に比べて 2 倍以上のコスト効率の高いパフォーマンスを提供すると期待しています。」- Character AI、CEO Noam Shazeer 氏
AI/ML ワークロード向けに最適化されたストレージ
AI のトレーニング、ファインチューニング、推論のパフォーマンスを向上させるために、データをコンピュート インスタンスの近づけるキャッシュなど、ストレージ製品の多くの機能強化を追加し、トレーニングを大幅に高速化しました。また、これらの機能強化により、GPU と TPU の使用率も最大化され、エネルギー効率の向上とコストの最適化が実現します。
Cloud Storage FUSE (一般提供開始)は、Google Cloud Storage (GCS) 向けのファイルベース インターフェースです。高性能で低コストのクラウド ストレージ ソリューションへのファイル アクセスを提供することで、複雑な AI/ML アプリで Cloud Storage の機能を活用できます。本日、新しいキャッシュ機能の一般提供を開始しました。 Cloud Storage FUSE キャッシュにより、トレーニング スループットは 2.9 倍、独自の基盤モデルの 1 つのサービング パフォーマンスは 2.2 倍向上します。
Parallelstore にもキャッシュ機能が追加されました (現在プレビュー中)。 Parallelstore は、AI/ML および HPC ワークロード向けに最適化された高性能並列ファイル システムです。新しいキャッシュ機能により、ネイティブ ML フレームワーク データ ローダーと比較して、トレーニング時間が最大 3.9 倍短縮され、トレーニング スループットが最大 3.7 倍向上します。
Filestore (一般提供開始) は、低レイテンシのファイルベースのデータ アクセスを必要とする AI/ML モデル向けに最適化されています。ネットワーク ファイル システム ベースのアプローチにより、クラスタ内のすべての GPU と TPU が同じデータに同時にアクセスできるため、トレーニング時間が最大 56% 短縮され、AI ワークロードのパフォーマンスを最適化、最も要求の厳しい AI プロジェクトも加速します。
また、AI 推論/サービング ワークロード向けに最適化された次世代ブロック ストレージ サービスの Hyperdisk ML (現在プレビュー中) を発表しました。Hyperdisk ML は一般的なストレージサービスと比較して、モデルの読み込み時間を最大 12 倍高速化し、読み取り専用、マルチアタッチ、シン プロビジョニングを通じてコスト効率を実現します。最大 2,500 インスタンスが同じボリュームにアクセスでき、ボリュームあたり最大 1.2 TiB/ 秒の総スループットを達成、Microsoft Azure Ultra SSD や Amazon EBS io2 Block Express の 100 倍以上のパフォーマンスを実現します。
オープン ソフトウェアの進歩
フレームワークから、ソフトウェア スタック全体にわたるオープンソースの機能強化により、パフォーマンスとコスト効率を向上しつつ、開発者のエクスペリエンスを簡素化し、お客様がAI ワークロードの価値実現までの時間を短縮できるようにします。
JAX および高パフォーマンスのリファレンス実装拡散モデル向けの新しい高性能でスケーラブルなリファレンス実装の MaxDiffusionを発表しました。また、Cloud TPU および NVIDIA GPU の両方で、Gemma、GPT3、LLAMA2、Mistral などの新しい LLM モデルを MaxText に導入します。お客様は、これらのオープンソース実装を使用して AI モデルを開発を始め、ニーズに基づいてさらにカスタマイズできます。
MaxText モデルと MaxDiffusion モデルは、高性能数値計算と大規模機械学習のための最先端のフレームワークである JAX 上に構築されています。JAX は OpenXLA コンパイラと統合されており、数値関数を最適化し、大規模なパフォーマンスを提供するため、モデルビルダーは開発に注力し、ソフトウェアに最も効果的な実装を行うことができます。Google Cloud は、Cloud TPU で JAX および OpenXLA のパフォーマンスを大幅に最適化したほか、NVIDIA との連携を通して大規模な Cloud GPU クラスターの OpenXLA パフォーマンスを最適化しました。
PyTorch サポートの進歩
PyTorch への取り組みの一環として、 2024 年 4 月後半のアップストリーム リリースに続き、 PyTorch/XLA 2.3 のサポートを展開予定です。 PyTorch/XLA を使用すると、PyTorch 開発者は新しいフレームワークを学習せずに、TPU や GPU などの XLA デバイスから最高のパフォーマンスを得ることができます。また、今回のリリースにより、単一プログラム、複数データ (SPMD) の自動シャーディングや非同期分散チェックポイントなどの機能が導入され、分散トレーニング ジョブの実行がより簡単かつスケーラブルになります。
さらに、Hugging Face コミュニティの PyTorch ユーザー向けに、開発者が TPU で Hugging Face モデルを簡単にトレーニングしてサービングできる、パフォーマンスが最適化されたパッケージ Optimum TPU をHugging Face と協力し、公開しました。新しい LLM 推論エンジン JetstreamTPU をはじめとする XLA 向けのオープンソースのスループットとメモリ最適化の LLM 推論エンジンである Jetstream を導入し、Gemma 7B およびその他のオープン モデルで 1 米ドルあたり最大 3 倍のパフォーマンスを提供します。お客様は AI ワークロードを本番環境に移行を進めており、高いパフォーマンスを提供するコスト効率も高い推論スタックに対する需要が高まっています。Jetstream は、JAX と PyTorch/XLA の両方でトレーニングされたモデルのサポートを提供し、Llama 2 や Gemma などの一般的なオープン モデルも最適化します。
NVIDIA との協力によるオープン コミュニティ モデル
さらに、NVIDIA と Google のオープン コミュニティ モデルに関するコラボレーションの一環として、Google モデルは NVIDIA NIM 推論マイクロサービスとして提供され、開発者が好みのツールやフレームワークを使用してトレーニングとデプロイを行うためのオープンで柔軟なプラットフォームを提供します。
新しい Dynamic Workload Scheduler モード
Dynamic Workload Scheduler は、AI ワークロード向けに設計されたリソース管理およびジョブ スケジューリング サービスです。 Dynamic Workload Scheduler は、AI コンピューティング能力へのアクセスを改善し、必要なすべてのアクセラレータを同時に保証された期間にスケジュールすることで、AI ワークロードへのコストの最適化に貢献します。経済性を最適化し、取得性を向上させるフレックス スタート モード (プレビュー中) とジョブの開始時間と期間を予測できるカレンダー モード (プレビュー中) の 2 つのモードを提供します。
フレックス スタート ジョブは、リソースの可用性に基づいて、できるだけ早く実行するよう指示されるため、柔軟な開始時間を持つジョブ向けの TPU および GPU リソースを簡単に取得できます。フレックス スタート モードは、Google Kubernetes Engine (GKE) に加えて、Compute Engine マネージド インスタンス グループ、Batch、 および Vertex AI カスタム トレーニングに統合されています。フレックス スタートを使用することで、Google Cloud で提供されるさまざまな TPU および GPU タイプで数千の AI / ML ジョブを実行でき、取得性が向上しました。
カレンダー モードでは、AI に最適化されたコンピューティング能力への短期的な予約アクセスが提供されます。併置された GPU は最大 14 日間予約でき、最大 8 週間前から購入できます。この新しいモードは Compute Engine の「将来の予約」機能を拡張します。予約は空き状況に基づいて確認され、キャパシティは要求された開始日にプロジェクトに配信されます。その後、予約の全期にわたって容量ブロックを対象とする VM を簡単に作成できます。
「Dynamic Workload Scheduler により、オンデマンド GPU の取得性が 80% 向上し、研究者の実験の反復が高速化されました。ビルトイン Kueue と GKE の統合を活用することで、Dynamic Workload Scheduler の新しい GPU 容量を迅速に活用し、数か月の開発作業を迅速化することができました」 - Two Sigma、ソフトウェア エンジニア Alex Hays 氏
Google Distributed Cloud で、場所を選ばない AI を実現
企業による AI 導入の加速により、データの生成に近い場所でデータを処理または安全に分析するための柔軟な導入オプションの必要性が増しています。Google Distributed Cloud (GDC) は、Google のクラウド サービスのパワーを、企業のデータセンターやエッジなど必要な場所で活用できます。本日、Gemma 搭載の生成 AI 検索パッケージ ソリューション、パートナー ソリューションが拡張されたエコシステム、新しいコンプライアンス認定など、GDC の機能の強化を発表しました。詳しくは GDC で、どこでも AI を実行する方法をご覧ください。
Google AI インフラストラクチャで加速
Google Cloud Next ‘24 では、AI プラットフォームやモデル、Gemini for Google Cloud による AI 支援など、あらゆる驚異的な AI イノベーションを発表しています。これらはすべて、AI に最適化されたインフラストラクチャの基盤によって支えられており、こうしたイノベーションがお客様の事業を加速させています。実際、生成 AI ユニコーン企業の約 90%、資金提供を受けた生成 AI スタートアップの 60% 以上 が Google Cloud のお客様です。
「Runway のテキストから動画へのプラットフォームは AI ハイパーコンピューターにより強化されています。基盤に NVIDIA H100 GPU を搭載した A3 VM を活用したことで、トレーニングのパフォーマンスが A2 VM よりも大幅に向上し、Gen-2 モデルの大規模なトレーニングと推論が可能になりました。GKE を使用してトレーニング ジョブを調整することで、単一のファブリックで数千の H100 にスケールし、高まるお客様の需要に応えることができています。」
Runway、CTO兼共同創設者 Anastasis Germanidis 氏
「Google Cloud に移行し、NVIDIA L4 GPU と Triton Inference Server を搭載した G2 VM で AI ハイパーコンピューター アーキテクチャを活用することで、モデル推論のパフォーマンスが大幅に向上しました。同時に、Google Cloud が提供する柔軟性によって実現される新しい技術を使用し、ホスティング 費用を 15% 削減することができました。 」
-Palo Alto Networks、シニア スタッフ機械学習エンジニア Ashwin Kannan 氏
「Writer のプラットフォームは、NVIDIA H100 と L4 GPU を搭載した Google Cloud A3 および G2 VM を利用しています。GKE を使用することで、700億 を超えるパラメータまでスケールアップできる、17 を超える大規模言語モデル (LLM) を効率的にトレーニングおよび推論できています。また、NVIDIA NeMo フレームワークを活用して、毎月 1 兆回以上の API の呼び出しで毎秒 990,000 語を生成する産業用の強力なモデルを構築しています。当社がより大きなチームや予算を持つ企業のモデルを超える最高品質の推論モデルを提供できているのは、すべてGoogle と NVIDIA のパートナーシップによるものです。お客様が数か月や数年ではなく、数日で有意義な AI ワークフローを構築できるのは、この 2 社の AI 専門知識のおかげです。」
-Writer、共同創設者兼 CTO Wassem Alshikh 氏
AI ハイパーコンピューターの詳細についてはこちらをご覧いただくか、セールス スペシャリストにお問い合わせください。
1. Forrester Research「The Forrester Wave™: AI Infrastructure Solutions, Q1 2024」、Mike Gualtieri、Sudha Maheshwari、Sarah Morana、Jen Barton 著、2024 年 3 月 17 日
The Forrester Wave™ は Forrester Research, Inc. の著作権に帰属します。Forrester および Forrester Wave™ は、Forrester Research, Inc. の商標です。Forrester Wave は Forrester の市場に対する評価をグラフィカルに表現したものです。Forrester は Forrester Wave™ に記載された特定のベンダー、プロダクト、サービスを推奨することはありません。情報は、利用可能な最良のリソースに基づいています。評価はその時点での判断を反映したものであり、変更される可能性があります。

