Google Cloud、50,000 個以上の TPU v5e チップにまたがる大規模言語モデルに対して世界最大の分散トレーニング ジョブを実証
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI のブームにより、基礎的な大規模言語モデル(LLM)のサイズは飛躍的に増大し、数千億のパラメータと数兆のトレーニング トークンが利用されるようになりました。
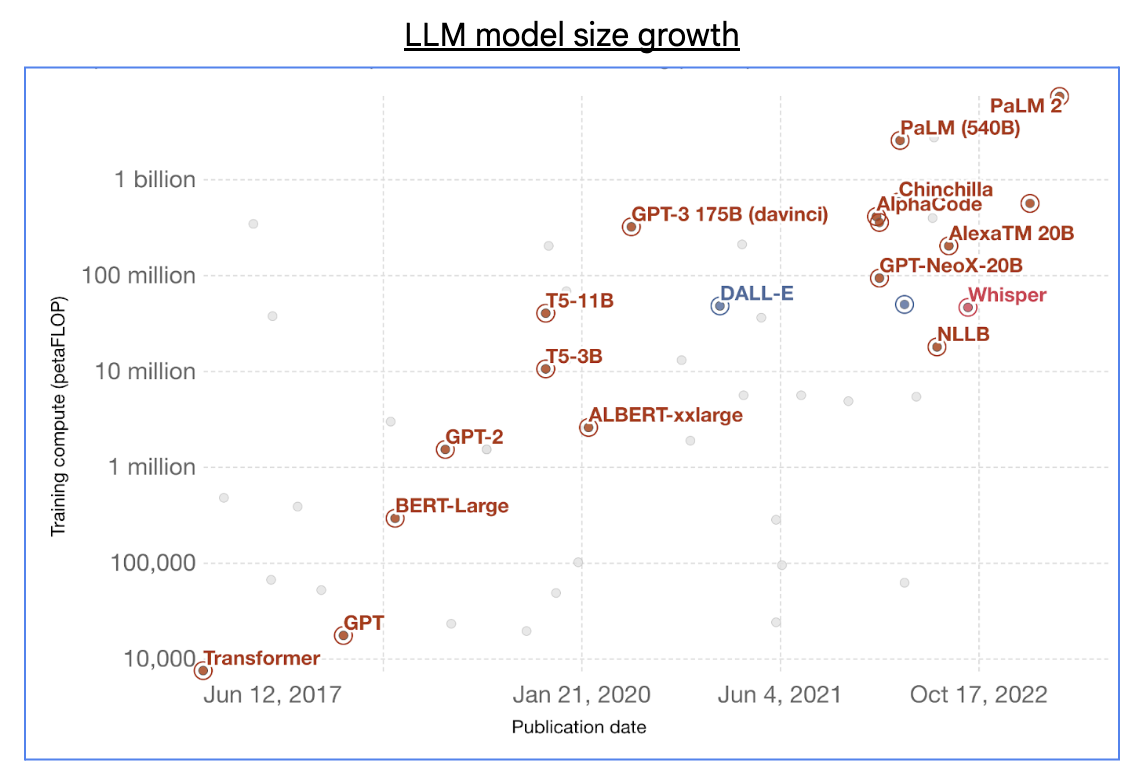
出典: 「注目すべきインテリジェンス システムのトレーニングに使用されるコンピューティング」、One World Data
この種の大規模な LLM のトレーニングには数十 EFLOP(10^18 FLOP)の AI スーパーコンピューティング能力が必要ですが、通常、この能力は数万個の AI アクセラレータ チップを含む大規模クラスタに分散されます。しかし、分散型 ML トレーニングに大規模クラスタを利用するには、共通する重要な技術的課題が多くあります。
- オーケストレーション: 分散トレーニングに使用されるソフトウェア スタックは、これらのチップをすべて管理し、可能な限り拡張することで、トレーニング時間を短縮する必要があります。また、トレーニングを確実に進行させるために、このスタックは高い信頼性とフォールト トレランス、レジリエンスを必要とします。
- コンパイル: トレーニングの進行中は、チップ間で発生するコンピューティングと通信を高性能コンパイラによって効率的に管理する必要があります。
- エンドツーエンドの最適化: 大規模な分散トレーニングでは、ストレージやコンピューティング、メモリやネットワーキングに至るまで、ML トレーニング スタックとエンドツーエンドの ML トレーニング ワークフローの両方にわたる深い専門知識が必要です。
Google Cloud TPU マルチスライス トレーニング
オーケストレーション、コンパイル、エンドツーエンドの最適化など、上述の分散トレーニングの各課題に対処するため、Google は本日、Cloud TPU マルチスライス トレーニングの一般提供を発表しました。TPU v4 および v5e をサポートするこのフルスタック トレーニング サービスは、ML トレーニングのエンドツーエンドの最適化のためにゼロから構築されており、スケーラブルで信頼性が高く、使いやすい仕様になっています。マルチスライスを使用すると、費用対効果、汎用性、スケーラビリティに優れた Google の Cloud TPU を活用して、ML モデルを効率的かつ大規模にトレーニングできます。

Cloud TPU マルチスライス トレーニングの主な機能は次のとおりです。
- 堅牢なオーケストレーションとスケーラビリティ: トレーニング ワークフロー全体にわたって、信頼性が高くフォールト トレラントな方法で、何万もの TPU チップに及ぶ大規模なモデルのトレーニングを実行できます。
- 高パフォーマンス コンパイル: XLA コンパイラを使用してコンピューティングと通信を自動的に管理し、パフォーマンスと効率を最大化します。
- エンドツーエンドのトレーニングのための柔軟なスタック: JAX や PyTorch などの一般的な ML フレームワークに対するトップクラスのサポート、使いやすいリファレンス実装とライブラリ、LLM、拡散モデル、DLRM を含む幅広いモデル アーキテクチャのサポートを提供します。
ここでは、マルチスライス トレーニング スタック全体の主要コンポーネントをいくつかご紹介します。その多くは、より広範な AI / ML コミュニティに貢献し続けるためにオープンソース化されています。
- Accelerated Processing Kit(XPK)は、ML ジョブのオーケストレーションを行うベスト プラクティスを標準化するために、Google Kubernetes Engine(GKE)向けに構築された ML クラスタとジョブのオーケストレーション ツールです。XPK は、ML エンジニア(MLE)がより簡単に使用、管理、デバッグできるように、ML トレーニング ジョブを作成、管理、実行するための ML セマンティクスに重点を置いています。XPK は個別の API によって、容量のプロビジョニングをジョブの実行から切り離します。
- MaxText は、パフォーマンス、スケーラビリティ、適応性に優れた JAX LLM 実装です。この実装は、Flax、Orbax、Optax などのオープンソースの JAX ライブラリ上に構築されています。MaxText は純粋な Python で書かれたデコーダ専用の LLM 実装であり、非常に簡単に MLE が理解、適応、変更できるようになります。また、MaxText は XLA コンパイラを多用しており、MLE はカスタム カーネルを構築しなくても、簡単に高いパフォーマンスを実現できます。OpenXLA による XLA は、TPU、GPU、CPU などのさまざまなハードウェア アクセラレータ用のオープンソース ML コンパイラです。
- Accurate Quantized Training(AQT)は Google が構築したトレーニング ライブラリで、16 ビットの浮動小数点数(BF16)の代わりに数値精度を落とした 8 ビットの整数(INT8)をトレーニングに使用します。AQT は、ML アクセラレータが INT8 演算と BF16 演算を使用した場合、演算速度が 2 倍になるという事実を利用しています。AQT のシンプルで柔軟な API を使用することで、MLE はトレーニング時の高いパフォーマンスと本番環境での高いモデル品質の両方を実現できます。
Google Cloud TPU、50,000 個以上の TPU v5e チップで LLM に世界最大の分散トレーニング ジョブを実行
マルチスライス トレーニングを使用して、公開されている中では(トレーニングに使用されるチップ数の点で)おそらく世界最大の LLM 分散トレーニング ジョブを実行しました。199 個の Cloud TPU v5e Pod にまたがる 50,944 個の Cloud TPU v5e チップからなるコンピューティング クラスタ上で実行され、10 EFLOP(16 ビット)または 20 EOP(8 ビット)の合計ピーク パフォーマンスを達成できます。規模の大きさをわかりやすく示すと、この Cloud TPU v5e チップのクラスタは、オークリッジ国立研究所の TOP1 Supercomputer Frontier(AMD M1250X GPU 37,888 基)よりも多くの AI アクセラレータを搭載しています。
Cloud TPU v5e での LLM 分散トレーニング ジョブのセットアップ
Cloud TPU v5e で Cloud TPU マルチスライス トレーニングを使用して、大規模な LLM 分散トレーニング ジョブを実行しました。Cloud TPU v5e Pod は、高速チップ間相互接続(ICI)を介して接続された 256 個のチップで構成されます。これらの Pod は Google の Jupiter データセンター ネットワーキング(DCN)を使用して接続され、通信します。XPK、GKE、MaxText、AQT、および JAX トレーニング スタックのその他のコンポーネントを利用して、この分散トレーニング ジョブを JAX フレームワーク上にセットアップしました。このブログの後半では、Cloud TPU マルチスライス トレーニングの JAX トレーニング スタック部分について説明します。
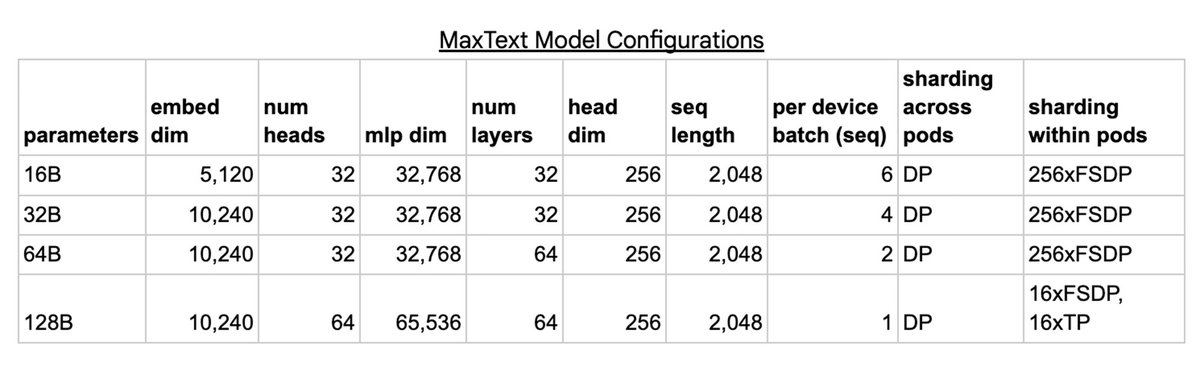
16B、32B、64B、128B のさまざまなサイズのパラメータで複数の MaxText モデルをトレーニングしました。モデルごとに、DCN 上の Pod 間のデータ並列処理(DP)を使用してトレーニングをスケーリングしました。各 Pod はモデルの独自のレプリカを保存します。次に、モデルの各レプリカは、16B、32B、64B 構成では完全にシャーディングされたデータ並列処理(FSDP)を、128B 構成では FSDP とテンソル並列処理(TP)を組み合わせて使用し、ICI を介して Pod 内のチップ間でシャーディングされます。
TPU のキャパシティは Google Kubernetes Engine(GKE)で管理し、ML ジョブのオーケストレーションには GKE 上で XPK を利用しました。XPK はクラスタの作成を処理し、必要に応じてクラスタのサイズを変更して、ジョブを JobSet として GKE Kueue システムに送信します。そして、それらの JobSet を管理してクラスタの状態を可視化します。
モデルのトレーニングを高速化するために、Accurate Quantized Training(AQT)ライブラリを使用して、量子化された INT8 でトレーニングしました。2023 年 10 月の時点で、このアプローチにより、BF16 でトレーニングされたモデルを INT8 に量子化する場合に通常伴う収束ギャップよりも小さなギャップしか生成しないものの、1 秒あたりのステップ数を 1.2 倍から 1.4 倍に加速できるようになっています。
最大規模の分散 LLM トレーニング ジョブをスケーリングした方法
TPU コンピューティング クラスタの規模拡大に伴い、スタックの限界に挑戦し始めました。
オーケストレーション
単一のトレーニング ジョブで動作する 50,000 個を超えるアクセラレータ チップを管理するには、クラスタ全体で実行される大規模なジョブをサポートするだけでなく、さまざまなユーザーがテスト用の小規模なジョブを送信できるように、適切に設計されたオーケストレーション ソリューションが必要です。この機能は、GKE の Jobset 機能と Kueue 機能を通じて提供されます。GKE が処理できる VM 数の限界に挑戦し続ける中で、内部 IP アドレスの管理と Docker イメージの事前キャッシュを最適化し、スケールに応じたクラスタを設計して、高スループットのスケジューリングを可能にしました。また、GKE を最適化して、Pod IP の枯渇、ドメイン名サービス(DNS)のスケーラビリティ、コントロール プレーン ノードの制限といった領域における VM スケーリングの制限も押し上げました。XPK とともにこれらのソリューションをパッケージ化し、文書化することで、このような大規模なトレーニングを行うお客様のために反復可能なプロセスを実現しました。
パフォーマンス
JAX は、コンパイラ ベースの線形代数実行エンジンである XLA(Accelerated Linear Algebra)を搭載しており、TPU や GPU のような ML アクセラレータのワークロードを最適化して、スーパーコンピュータのようなパフォーマンスを実現します。XLA を支える重要な並列化技術は SPMD(単一プログラム、複数データ)で、これは同じ計算を異なるデバイス上で並列に実行します。XLA は GSPMD を活用しています。GSPMD は、ユーザーが 1 つの巨大なスーパーコンピュータをプログラミングし、いくつかのユーザー注釈に基づいてデバイス間で計算を自動的に並列化できるようにして、SPMD プログラミングを簡素化します。大規模に実行することで、スライス数が多い場合にのみ最適化が必要になることが明らかになりました。たとえば、各ワーカー VM は、DCN を介して他のスライス内の同じランクのワーカー VM と通信する必要があります。当初はこのために、スライス数に比例して増加する過剰なデバイスからホストへの転送とホストからデバイスへの転送により、速度低下を引き起こしていました。XLA ランタイムを最適化することで、これらの転送がボトルネックになるのを防止できました。
ストレージ
永続ストレージとのやり取りは、トレーニングの重要な側面です。Google の 199 Pod クラスタは、Google Cloud Storage(GCS)への転送速度が 1 Tb/秒、スライス間 DCN が 1,270 Tb/秒、スライス内 ICI が 73,400 Tb/秒 でした。Docker イメージの読み込み、データの読み込み、チェックポイントの読み取り / 書き込み時に、永続ストレージとのやり取りを最適化しました。
大規模になると、64 Pod 以上では GCS からのデータ読み込みがパフォーマンスに影響し始めることがわかりました。それ以来、ホストのサブセットにデータを読み込ませることで GCS への負担を軽減する分散データ読み込み戦略により、この制限を緩和しています。
またチェックポイントによる制限も見つかりました。デフォルトでは、チェックポインティングにより、GCS から各データ並列レプリカに完全なチェックポイントが読み込まれます。Pod 間データ並列処理では、シャーディングされた 128B モデルのチェックポイント読み込みを検討してください。パラメータごとに 3 つの数値(4 バイト/数値)の従来のオプティマイザー状態の場合、これは、約 1.536 TB のサイズのチェックポイントを各 Pod(この場合は 199 Pod)に個別に読み込むことを意味します。この場合、199 Pod × 1.536 TB/Pod、つまり約 300 TB の帯域幅が必要になります。1 Tb/秒の永続ストレージから妥当なパフォーマンスを得るには、約 2,400 秒(40 分)が必要になります。しかし、起動や再起動の時間を大幅に短縮しなければならず、別のアプローチを採用する必要がありました。
この問題を軽減するために、1 つの Pod でチェックポイントを読み込み、それを他のレプリカにブロードキャストできる機能を追加しました。この機能により、1 つの Pod がチェックポイントを読み取り、JAX の柔軟性を活用して他の Pod にオプティマイザーの状態をブロードキャストできます。原理的には、チェックポイントの読み込みには 1.536 TB/1 Tb/秒 = 約 12 秒かかり、クラスタ全体でオプティマイザーの状態を収集するには(2 × 1.536 TB/Pod)/(64 VM/Pod × 100 Gb/秒/VM)= 約 4 秒かかります。合計で 16 秒となり、150 倍のスピードアップが実現します。同様に、チェックポイント データの書き込み時やトレーニング データの読み込み時にも最適化が必要です。書き込み時には、1 つのリーダー レプリカがチェックポイント全体を書き込み、GCS への過剰な QPS を回避できます。
トレーニングのパフォーマンスを測定した方法
トレーニングのパフォーマンスは、モデルの FLOP 使用率(MFU)とモデルの有効 FLOP 使用率(EMFU)で測定します。N パラメータ デコーダのみのモデルの場合、表示される各トークンには、学習可能な重みに 6N matmul FLOP が必要で、アテンションには 12LHQT matmul FLOP が必要です。ここで、L、H、Q、T はそれぞれレイヤ数、ヘッド数、ヘッドの次元、シーケンスの長さを意味します(詳細については、PaLM 論文の付録 B を参照してください)。各トークンに必要な TFLOP がわかれば、ステップのスループットを実測 TFLOP/チップ/秒として表せます。これは、各チップのステップで見られるすべてのトークンに必要な合計 TFLOP をステップ時間で割ったものとして計算されます。

次に、実測 TFLOP/チップ/秒をハードウェアのピーク TFLOP/チップ/秒(TPU v5e の場合は 197 TFLOP/チップ/秒)で割ることにより、MFU を計算できます。

EMFU は、実測 TFLOP/チップ/秒を実測 TOP/チップ/秒(テラ演算/チップ/秒)に拡張し、量子化演算と浮動小数点演算の両方をカプセル化します。ただし、量子化演算での実測 TOP/チップ/秒は、浮動小数点演算のピーク TFLOP/チップ/秒よりも大きくなる場合があるため、100% 以上の EMFU を達成する可能性もあります。

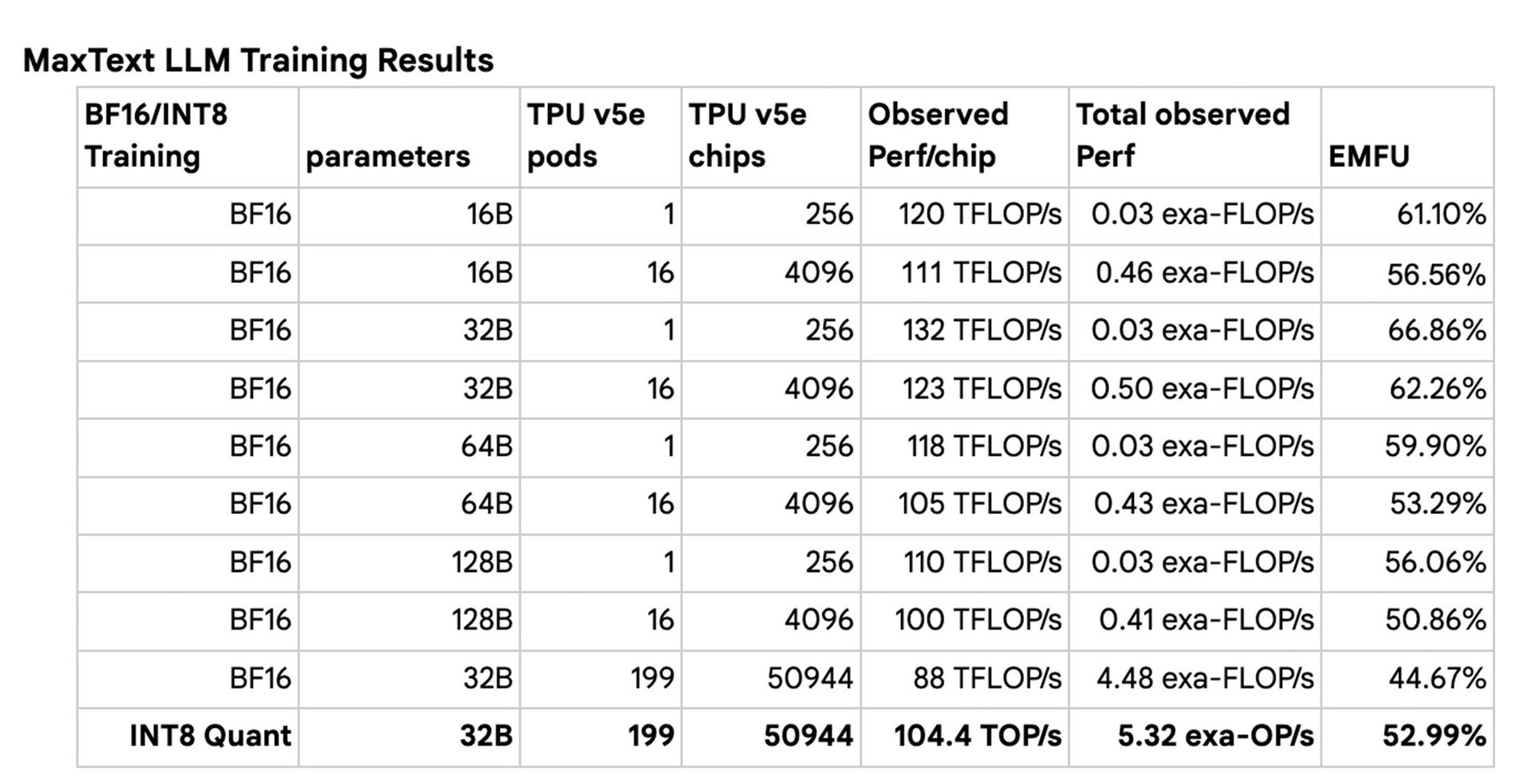
LLM 分散トレーニング ジョブの最大のスケーラビリティ結果
各モデルサイズ(16B、32B、64B、128B)に対して、TPU v5e Pod の数を 1 から 160 までスケーリングして、一連のトレーニング ジョブを実行しました。単一の TPU v5e Pod で BF16 トレーニングを行ったところ、66.86% という高い MFU が得られ、160 Pod まで拡張した場合には強力なスケーリング結果が得られました。また、BF16 トレーニングと INT8 量子化トレーニング(AQT を使用)の両方を使用して 199 Pod クラスタ全体のジョブを実行したところ、INT8 量子化トレーニングで 5.32 EOP/秒という驚異的な記録を達成しました。今回のスケーリング調査は、マルチスライス トレーニング JAX スタック全体で限られたソフトウェアの最適化に対してのみ行われました。私たちは今後もソフトウェア スタックの改善を続けていきます。
今後の可能性
ジョブの起動時間
トレーニング パフォーマンスの測定に加えて、クラスタ上の ML ジョブの起動時間も測定しました。これは、チップの数に応じてほぼ正比例で増加しました。
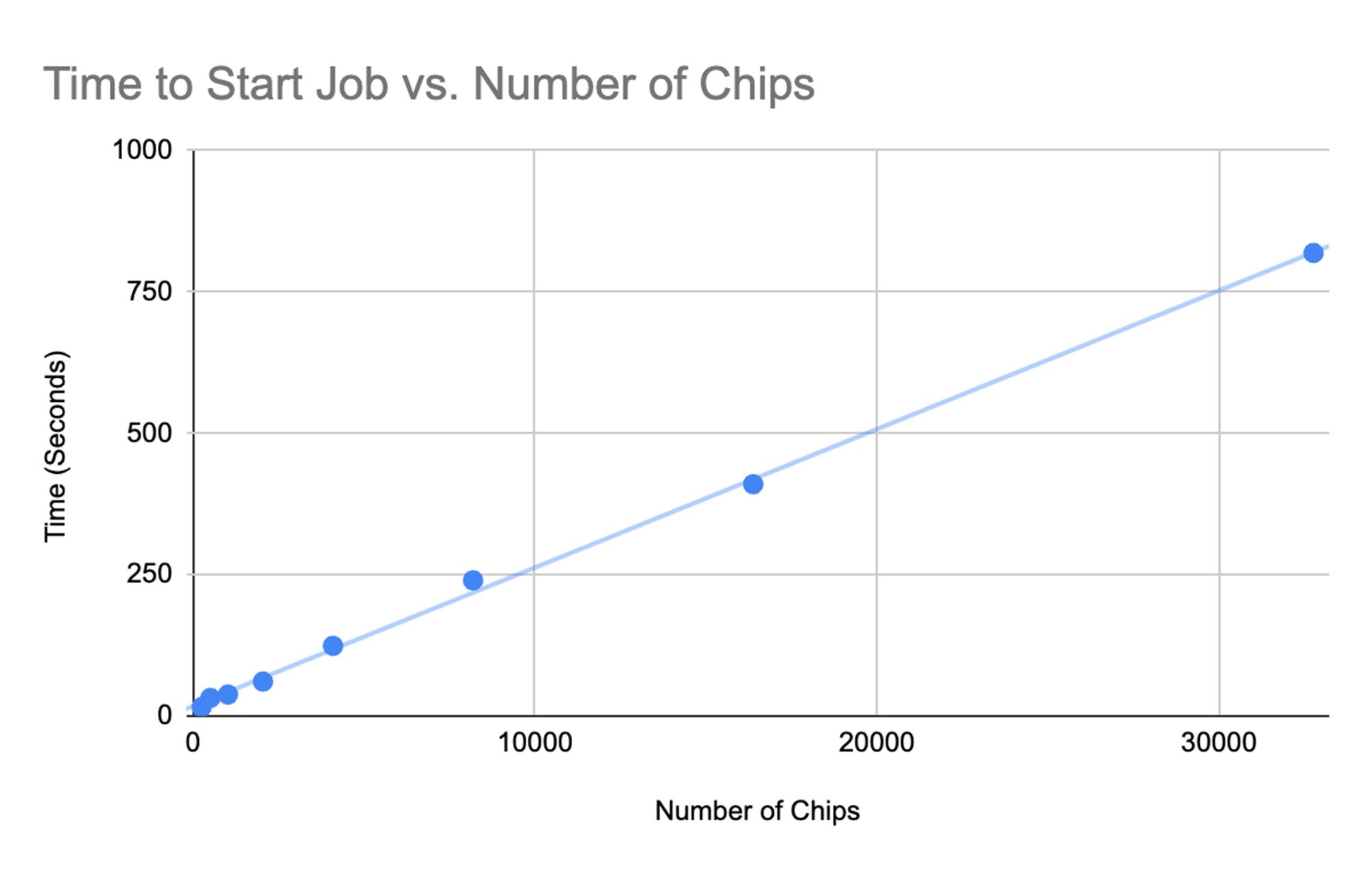
観測された起動時間は相当なものでしたが、これはさらに改善できると信じています。私たちは、GKE でスケジューリングを最適化してスループットを向上させる、あるいは MaxText で事前コンパイルを有効にしてクラスタ全体でのジャストインタイム コンパイルを回避するといった分野に取り組んでいます。
スケーリング効率
50,944 個の TPU v5e チップで優れたスケーリングを達成しましたが、これをさらに改善できると考えています。コンパイラと MaxText の変更点を特定し、大規模に安定性とパフォーマンスを向上させる取り組みを現在行っています。私たちは、階層型 DCN 集合などのスケーラブルなソリューションを検討し、マルチ Pod 方式でコンパイラ スケジューリングをさらに最適化しています。
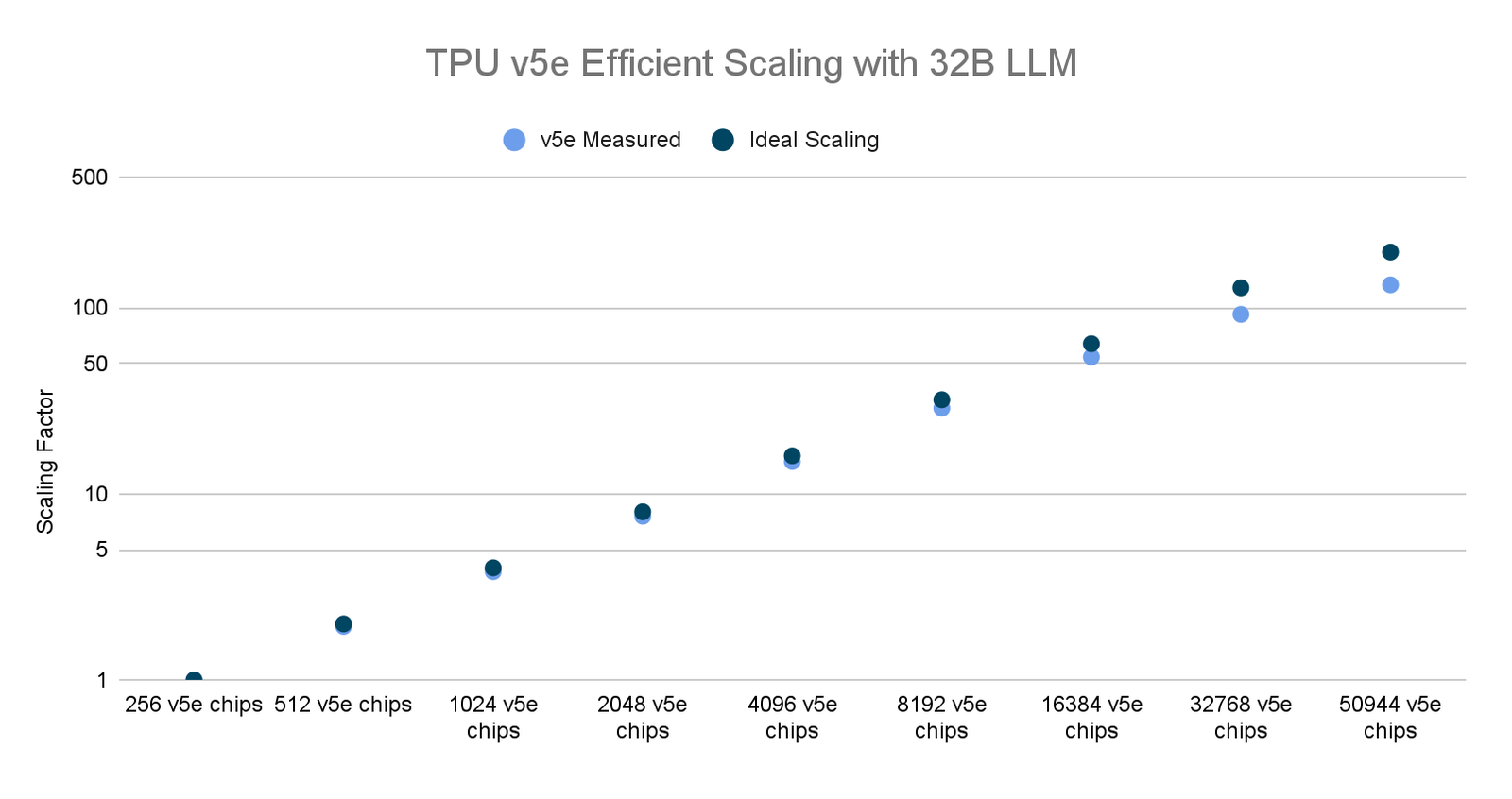
TPU v5e に関する Google 内部データ(2023 年 11 月現在): すべての数値はチップごとに正規化されています。MaxText を使用して実装された 320 億パラメータ デコーダのみの言語モデルの場合、seq-len=2048。*2
まとめ
Google Cloud TPU マルチスライス トレーニングは、オーケストレーション、コンパイル、エンドツーエンドの最適化における分散 ML トレーニングの課題に対処するために、ゼロから構築されました。私たちは、JAX ML フレームワーク上の 50,944 個の Cloud TPU v5e チップからなるコンピューティング クラスタで、BF16 トレーニングと INT8 量子化トレーニングの両方を利用して、公開されている中ではおそらく(トレーニングに使用されるチップ数の点で)世界最大の LLM 分散トレーニング ジョブを使用し、Cloud TPU マルチスライス トレーニングの利点を実証しました。
生成 AI により LLM がますます大規模化していく傾向にある中、Google はソフトウェア スタックのさらなる拡張と改善に必要なイノベーションの限界に挑戦し続けます。今回のプロジェクトで使用されているすべてのコードは、オープンソース化されています。MaxText、XPK、AQT、XLA のオープンソース リポジトリをご確認ください。Google Cloud TPU マルチスライス トレーニングの詳細と、それを Cloud TPU と組み合わせて使用することで生成 AI プロジェクトを加速する方法については、Google Cloud アカウント担当者にお問い合わせください。
この作業は、Google Cloud だけでなく、Google 社内の複数のチームが連携する大規模な取り組みでした。このプロジェクトを成功に導いたすべてのコンポーネントの開発に多大な貢献をしてくれた Raymond Zou、Rafi Witten、Lukasz Lew、Victor Barr、Andi Gavrilescu に深く感謝します。
-Cloud TPU、プロダクト管理リード、Rajesh Anantharaman

