G4 VM の内部: マルチ GPU ワークロード向けのカスタムの高性能 P2P ファブリック
Cyrill Hug
Sr. Product Manager Accelerator Software, Google
Prashanth Prakash
Software Engineer, Google
※この投稿は米国時間 2025 年 10 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、NVIDIA RTX PRO 6000 Blackwell Server Edition GPU をベースとする G4 VM ファミリーの一般提供が開始されました。Google Cloud 独自のプラットフォーム最適化により、G4 VM は、300 億未満から 1,000 億を超えるパラメータまで、幅広いモデルで推論とファインチューニングを行うための、市販されている NVIDIA RTX PRO 6000 Blackwell GPU の中で最高のパフォーマンスを実現します。このブログでは、これらのプラットフォーム最適化の必要性、仕組み、および独自の環境での使用方法について説明します。
集団のコミュニケーションのパフォーマンスが重要
大規模言語モデル(LLM)は、パラメータ数によって特徴付けられるように、サイズが大きく異なります。小(約 70 億)、中(約 700 億)、大(約 3,500 億以上)です。LLM は、96 GB の GDDR7 メモリを搭載した NVIDIA RTX PRO 6000 Blackwell を含め、単一の GPU のメモリ容量を超えることがよくあります。一般的な解決策は、テンソル並列処理(TP)を使用することです。これは、個々のモデルレイヤを複数の GPU に分散することで機能します。これには、レイヤの重み行列をパーティショニングして、各 GPU が並列で部分的な計算を実行できるようにすることが含まれます。しかし、これらの部分的な結果を All-Gather や All-Reduce などの集団通信オペレーションを使用して結合する必要があるため、パフォーマンスのボトルネックが顕著になります。
G4 ファミリーの GPU 仮想マシンは、PCIe のみのインターコネクトを利用します。Google は、インフラストラクチャに関する豊富な専門知識を活用して、ピアツーピア(P2P)通信をサポートする高性能なソフトウェア定義の PCIe ファブリックを開発しました。重要なのは、G4 のプラットフォーム レベルの P2P 最適化により、マルチ GPU スケーリングを必要とするワークロードの集団通信が大幅に高速化されることです。これにより、LLM の推論とファインチューニングの両方が大幅に向上します。
G4 でマルチ GPU のパフォーマンスを加速する方法
マルチ GPU G4 VM シェイプは、カスタム ハードウェアとソフトウェアの両方を組み合わせることで、大幅に強化された PCIe P2P 機能を獲得します。この進歩により、GPU データ交換の管理のための All-to-All、All-Reduce、All-Gather コレクティブなどの集団通信が直接最適化されます。その結果、マルチ GPU 推論やファインチューニングなどの重要なワークロードでパフォーマンスが大幅に向上する、低レイテンシのデータパスが実現します。
実際、すべての主要なコレクティブで、強化された G4 P2P 機能により、コードやワークロードを変更することなく、最大 2.2 倍の高速化が実現しています。

G4 での P2P による推論パフォーマンスの向上
G4 インスタンスでは、強化されたピアツーピア通信により、特に vLLM を使用したテンソル並列推論において、マルチ GPU ワークロードのパフォーマンスが直接向上し、スループットが最大 168% 向上、トークン間レイテンシ(ITL)が最大 41% 低下 します。
モデル提供にテンソル並列処理を使用すると、特に標準の非 P2P サービスと比較して、こうした改善が見られます。

同時に、G4 はソフトウェア定義の PCIe と P2P イノベーションを組み合わせることで、推論スループットを大幅に向上させ、レイテンシを短縮します。これにより、ビジネスニーズに合わせて推論デプロイを最適化できます。

スループットまたは速度: P2P を使用する G4 で選択可能
G4 VM のプラットフォーム レベルの最適化は、柔軟で強力な競争上の優位性に直接つながります。ユーザー エクスペリエンスが最重要となるインタラクティブな生成 AI アプリケーションの場合、G4 の P2P テクノロジーにより、トークン間のレイテンシが最大 41% 削減されます。これは、レスポンスの各部分を生成する間の重要な遅延です。これにより、エンドユーザー エクスペリエンスが明らかに高速化され、応答性が向上し、AI アプリケーションに対する満足度が高まります。
また、バッチ推論など、スループットが優先されるワークロードの場合、P2P を使用した G4 では、同等のサービスよりも最大 168% 多くのリクエストを処理できます。つまり、各モデル インスタンスで処理できるユーザー数を増やすか、AI アプリケーションの応答性を大幅に向上させることができます。レイテンシの影響を受けやすいインタラクションに重点を置く場合でも、大容量のスループットに重点を置く場合でも、G4 は市場の他の NVIDIA RTX PRO 6000 製品よりも優れた投資収益率を実現します。
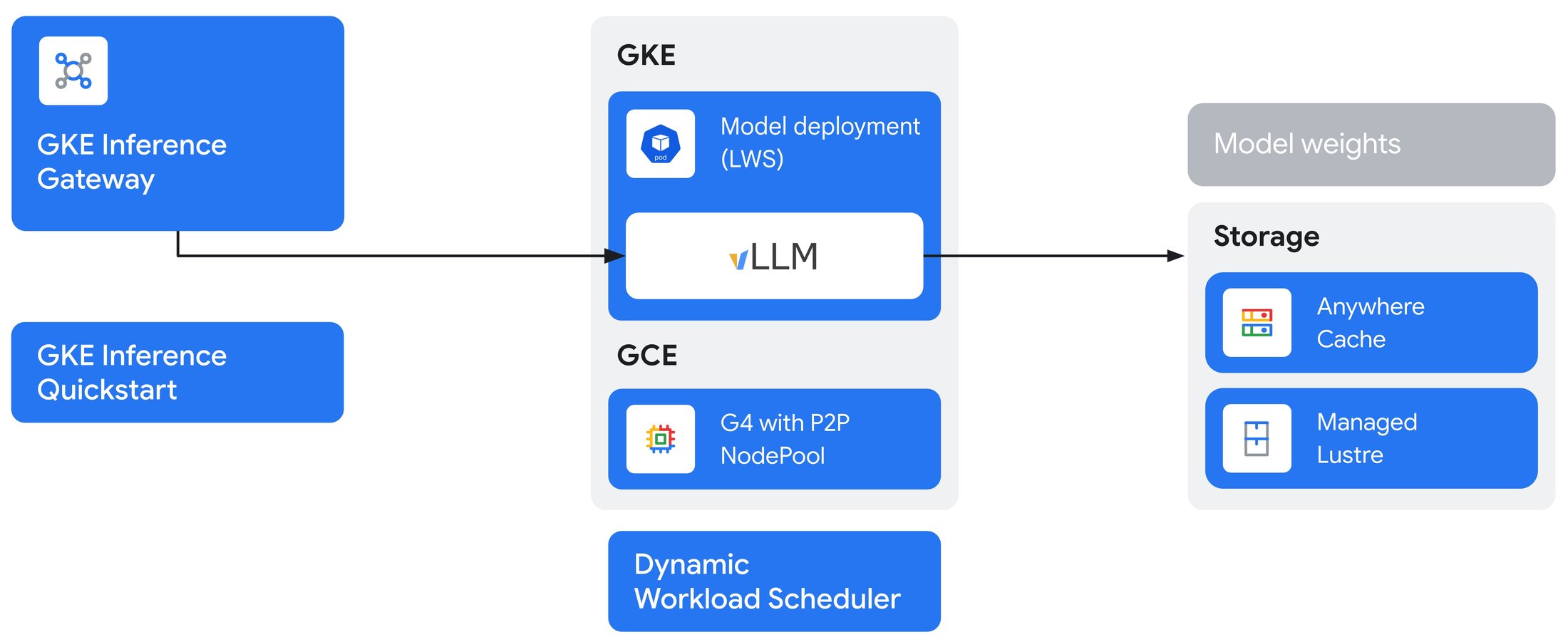
G4 と GKE Inference Gateway でさらに拡張
P2P は単一のモデルレプリカのパフォーマンスを最適化しますが、本番環境の需要を満たすためにスケールするには、多くの場合、複数のレプリカが必要になります。ここで GKE Inference Gateway が真価を発揮します。プレフィックス キャッシュ対応ルーティングやカスタム スケジューリングなどの高度な機能を使用して、モデルのインテリジェントなトラフィック マネージャーとして機能し、デプロイ全体でスループットを最大化し、レイテンシを大幅に削減します。
G4 の P2P の垂直スケーリングと推論ゲートウェイの水平スケーリングを組み合わせることで、最も要求の厳しい生成 AI アプリケーション向けに、非常に高いパフォーマンスと費用対効果を実現するエンドツーエンドのサービング ソリューションを構築できます。たとえば、G4 の P2P を使用すると、2 GPU の Llama-3.1-70B モデルレプリカを 66% 高いスループットで効率的に実行できます。その後、GKE Inference Gateway を使用して、これらのレプリカをインテリジェントに管理および自動スケーリングし、世界中のユーザーの需要に対応できます。
G4 P2P でサポートされる VM シェイプ
NVIDIA RTX PRO 6000 Blackwell のピアツーピア機能は、以下のマルチ GPU G4 VM シェイプで利用できます。
8 個未満の GPU を搭載した VM シェイプの場合、ソフトウェア定義の PCIe ファブリックにより、同じ物理マシン上の異なる VM に割り当てられた GPU 間のパスが分離されます。PCIe パスは VM の作成時に動的に作成され、VM シェイプに依存します。これにより、プラットフォーム スタックの複数のレベルで分離が確保され、同じ VM に割り当てられていない GPU 間の通信が防止されます。
Google Pixel 4 で P2P を使ってみる
G4 のピアツーピア機能はワークロードに対して透過的であり、アプリケーション コードや NVIDIA Collective Communications Library(NCCL)などのライブラリに変更を加える必要はありません。すべてのピアツーピア パスは、VM の作成時に自動的に設定されます。NCCL ベースのワークロードでピアツーピアを有効にする方法について詳しくは、G4 のドキュメントをご覧ください。
今すぐ Google Cloud コンソールから P2P を使用した Google Cloud G4 VM をお試しください。GKE Inference Gateway を使用して推論プラットフォームの構築を開始できます。詳細については、Google Cloud セールスチームまたは販売パートナーにお問い合わせください。
-Google、アクセラレータ ソフトウェア担当シニア プロダクト マネージャー、Cyrill Hug
-Google、ソフトウェア エンジニア Prashanth Prakash

